

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Министерство образования и науки РФ
Федеральное государственное бюджетное образовательное учреждение
высшего профессионального образования
«Вятский государственный гуманитарный университет»
ФАКУЛЬТЕТ ИНФОРМАТИКИ, МАТЕМАТИКИ И ФИЗИКИ
Кафедра прикладной математики и информатики
КУРСОВАЯ РАБОТА
Анализ тональности текстов
на основе ДСМ-метода
Выполнил
студент 4 курса группы ПМ-41
____________________/подпись/
Научный руководитель
канд. тех. наук, доцент
___________________/подпись/
Киров
2013
Содержание
Введение
Глава 1. Задача анализа тональности текстов
1.1. Понятие анализа тональности текста
1.1.1. Определение
1.1.2. История
1.1.3. Постановка задачи
1.1.4. Применение
1.2. ДСМ-метод
1.2.1. Схема метода
1.2.2. Описание метода
1.2.3. Алгоритм поиска пересечений
1.3. N-кратный скользящий контроль
1.4. Метрики качества
1.4.1. Правильность и ошибочность
1.4.2. Точность и полнота
1.4.3. F1-мера
Глава 2. Практическое исследование ДСМ-метода
2.1. Программная реализация
2.1.1. Пользовательский интерфейс
2.1.2. Входные данные
2.1.3. Выходные данные
2.1.4. Диаграмма классов и структуры данных
2.2. Текстовая коллекция
2.3. Эксперименты и результаты
2.3.1. Оценка качества анализа тональности
2.3.2. Оценка времени работы программы
Заключение
Библиографический список
Приложение
Введение
В сети Интернет содержится огромное количество разнообразных текстов, авторами которых являются обычные пользователи. Это могут быть статьи в блогах, отзывы на продукты, сообщения в социальных сетях и т. п. В этом контенте содержится большое количество ценной информации.
В компьютерной лингвистике существует отдельное направление обработки естественно-языковых текстов – анализ тональности текстов (sentiment analysis). Тональностью называется эмоциональная оценка, которая выражена в тексте. Актуальность задачи определения тональности заключается в том, что на основе текстовой информации можно оценить отношение общества к какому-либо продукту или событию. Например, с помощью данного анализа можно оценить успешность рекламной кампании, политических и экономических реформ; выявить отношение прессы и СМИ к определенной персоне, к организации, к событию; определить, как относятся потребители к определенной продукции, к услугам, к организации. Такая информация представляет значительный интерес для маркетологов, социологов, экономистов, политологов и всех тех специалистов, деятельность которых зависит от мнений людей.
Существуют два основных подхода к решению задачи анализа тональности текста: на основе словарей и на основе машинного обучения. В первом подходе используются словари, содержащие слова и предложения, для которых известна оценка выраженной в них тональности. Этот подход эффективен при использовании больших словарей, но процесс их составления весьма трудоемкий. Второй подход заключается в создании автоматического классификатора, который использует коллекцию обучающих текстов. В основе этого подхода лежат статистические методы. Подход эффективен при наличии большой коллекции обучающих текстов.
Одним из логических методов анализа тональности текстов является ДСМ-метод автоматического порождения гипотез. В [9] отмечается, что преимуществом ДСМ-метода по сравнению со статистическими методами является прозрачность и корректность процесса логического вывода, хорошая интерпретируемость генерируемых гипотез, отсутствие необходимости большого числа примеров для обучения.
Целью настоящей курсовой работы является применение ДСМ-метода для определения тональности текстов. Обозначенная цель достигается за счет решения следующих задач:
· изучение области анализа тональности текстов;
· описание ДСМ-метода автоматического порождения гипотез;
· программная реализация ДСМ-метода;
· проведение экспериментов по определению тональности текстов;
· анализ результатов влияния компонентов ДСМ-метода на качество определения тональности.
В первой главе приводится постановка задачи анализа тональности текстов и примеры областей деятельности, в которых применяется анализ тональности, рассматриваются теоретические аспекты ДСМ-метода автоматического порождения гипотез, дается описание показателей, на основе которых будет сделано заключение о качестве работы метода.
Во второй главе дается описание практической реализации ДСМ-метода, приводятся результаты тестирования разработанной программы-анализатора в виде таблиц и графиков.
В заключение работы приводится общий вывод по полученным результатам и список использованной литературы.
Глава 1. Задача анализа тональности текстов
1.1. Понятие анализа тональности текста
1.1.1. Определение
Анализ тональности текста (англ. sentiment analysis, opinion mining, sentiment classification) – это область компьютерной лингвистики, которая занимается изучением мнений и эмоций в текстовых документах. Анализ тональности представляет собой текстовую классификацию, т. е. процесс присвоения естественно-язычным текстам тематической категории из определенного набора.
Под мнением (тональностью) понимают выраженное в тексте эмоциональное отношение некоторого субъекта к определенному объекту [9]. Тональность может иметь одномерное или многомерное эмотивное пространство. В одномерном пространстве существует одно измерение (одна шкала), в котором может быть несколько значений – классов (двухбалльная, трехбалльная, n-балльная шкалы). В многомерном пространстве несколько ортогональных измерений, например, базовые эмоции – радость, счастье, страх, гнев и т. д.
1.1.2. История
В [5] отмечается, что автоматическая классификация текстов имеет длительную историю, уходящую в начало 1960-х гг. Вплоть до конца 1980-х гг. наиболее популярным подходом к классификации документов была инженерия знаний (knowledge engineering), заключающаяся в ручном определении правил, содержащих знания экспертов о том, как определить, к какой категории относится документ. В 1990-х гг. с бурным развитием производства и доступности онлайн документов интерес к автоматической классификации усилился. Новая тенденция, основанная на машинном обучении, вытеснила предыдущий подход. Эта тенденция заключалась в том, что на основе индуктивного процесса автоматически создается классификатор путем обучения с помощью набора предварительно классифицированных документов, характеризующихся одной или более категориями. Преимуществом является высокая эффективность и значительное сохранение опыта экспертов.
Проблема автоматического распознавания мнений в тексте оказалась предметом активных исследований за рубежом сравнительно недавно – в 2000-х гг. В России таких работ до последнего времени было крайне мало; только в 2012 году оценка тональности текста была выбрана одной из главных тем конференции по компьютерной лингвистике «Диалог–2012» [10].
1.1.3. Постановка задачи
Целью анализа тональности является нахождение мнений в тексте и определение их свойств. Существуют разные задачи в зависимости от исследуемых свойств текстов, например, определение автора мнения, т. е. кому принадлежит это мнение; определение темы, т. е. о чем говорится во мнении; определение тональности, т. е. позиция автора относительно объекта, о котором говорится во мнении.
Перед тем, как сформулировать обобщенную постановку задачи анализа тональности, формально определим понятие мнения. В соответствии с [3] мнение обозначим множеством вида
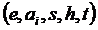 , (1)
, (1)
где ![]() (entity) – сущность (объект), по отношению к аспектам которой выражается мнение;
(entity) – сущность (объект), по отношению к аспектам которой выражается мнение;
![]() (aspect) – i-й аспект сущности (свойство объекта), по отношению которому выражается мнение;
(aspect) – i-й аспект сущности (свойство объекта), по отношению которому выражается мнение;
![]() (sentiment) – тональность мнения по отношению к i-му аспекту сущности
(sentiment) – тональность мнения по отношению к i-му аспекту сущности ![]() ;
;
![]() (holder) – выразитель мнения (субъект);
(holder) – выразитель мнения (субъект);
![]() (time) – время выражения мнения.
(time) – время выражения мнения.
Если мнение выражается по отношению к сущности в целом, а не к отдельному её аспекту, то устанавливается ![]() .
.
Обобщенную задачу анализа тональности можно сформулировать в следующем виде: в заданном тексте ![]() найти все мнения вида (1).
найти все мнения вида (1).
Приведем несколько основных вариантов задач анализа тональности, описанных в работе [9].
1. Определение исключительно тональности текста.
Данная формулировка задачи анализа тональности является наиболее простой. Рассматривается только тональность ![]() мнения, которое выражено в тексте (часто предполагается, что оно единственное); при этом остальные компоненты множества (1) не выделяются или считаются известными. Выражение (1) в этом случае принимает вид:
мнения, которое выражено в тексте (часто предполагается, что оно единственное); при этом остальные компоненты множества (1) не выделяются или считаются известными. Выражение (1) в этом случае принимает вид:
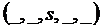 .
.
Обычно тональность ![]() представлена определенной шкалой. Выделяют следующие типы шкал:
представлена определенной шкалой. Выделяют следующие типы шкал:
1) Двухзначная шкала. Шкала тональности имеет только два значения –положительная тональность и отрицательная.
2) Трехзначная шкала. К предыдущим двум вариантам добавляется третье значение – нейтральное, которое может обозначать либо отсутствие тональности, либо одновременное наличие как положительной, так и отрицательной тональности.
3) Многозначная шкала. Шкала тональности имеет более 3 значений. Существует множество вариантов таких шкал, отличающихся количеством значений тональности и наличием нейтрального значения.
2. Определение тональности, субъекта и объекта
В данном варианте задачи кроме тональности ![]() мнения определяется выразитель
мнения определяется выразитель ![]() мнения, субъект и объект
мнения, субъект и объект ![]() , по отношению к которому выражается мнение. Выражение (1) в данном случае принимает вид:
, по отношению к которому выражается мнение. Выражение (1) в данном случае принимает вид:
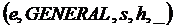 .
.
Для решения задачи в такой постановке кроме методов определения тональности требуется также применение методов извлечения сущностей из текста.
3. Определение мнения в целом
Мнение рассматривается как полное выражение (1), т. е. по сравнению с предыдущим вариантом кроме выделения сущности ![]() (объекта мнения) требуется определение её аспектов
(объекта мнения) требуется определение её аспектов ![]() .
.
1.1.4. Применение
Анализ тональности текста является одним из перспективных направлений компьютерной лингвистики. Это направление искусственного интеллекта позволяет извлекать разнообразную информацию, находящуюся в форме текста на естественном языке.
Автоматическое распознавание тональности текстов находит широкое применение в различных сферах деятельности человека. Приведем несколько примеров из работы [9].
1. Маркетинговые исследования. Проводятся для разнообразных целей, включая изучение потребительских предпочтений, измерение степени удовлетворения потребностей потребителей, определение эффективности распространения продуктов или услуг.
2. Финансовые рынки. В работе [1] говорится, что о каждом акционерном обществе существуют многочисленные публикации новостей, статьи, блоги и сообщения в Твиттере. Система анализа тональности может использовать эти источники для нахождения статей, в которых обсуждаются такие общества, и извлекать отзывы, что позволит создать автоматическую торговую систему. Одной из таких систем является «The Stock Sonar» (http://www. ). Система показывает графически ежедневные позитивные и негативные настроения о каждой акции рядом с графиком цены акции. По настроениям предсказывается дальнейший рост или падение цены акции.
3. Рекомендательные системы. Анализируются отзывы и обзоры различных продуктов с целью помощи покупателям при выборе товара. Например, система не будет рекомендовать продукт, если он получил много отрицательных отзывов.
4. Анализ новостных сообщений. Анализируются новостные ресурсы на предмет тональности сообщений относительно различных персон и событий.
5. Политологические исследования. Собираются данные о политических взглядах населения. Это может иметь существенное значение для кандидатов, выступающих от разных партий. Такой подход применяется организаторами предвыборной кампании для выявления того, что думают избиратели в отношении различных проблем, и как они связывают эти проблемы со словами и действиями кандидатов [1].
6. Социологические исследования. Анализируются данные из социальных сетей, например для выявления религиозных взглядов или различия между мужчинами и женщинами в употреблении эмоционально-окрашенных слов в сообщениях.
7. Поддержка поисковых систем (search engines) и систем извлечения информации (information extracting systems). В таких системах анализ тональности может служить для отделения фактов от мнений.
8. Анализ обратной связи от пользователей (consumer feedback analysis). При диалоге с пользователем система распознает его эмоции, и при помощи обратной связи может реагировать в соответствии с ними (например, в случае отрицательных эмоций переключать связь на оператора-человека).
9. Анализ экстремистских ресурсов. Анализируются Интернет-ресурсы экстремистского содержания на предмет подозрительной активности.
10. Психологические исследования. Определение депрессии у пользователей социальных сетей.
1.2. ДСМ-метод
1.2.1. Схема метода
На рис. 1 изображена схема ДСМ-метода классификации текстов.
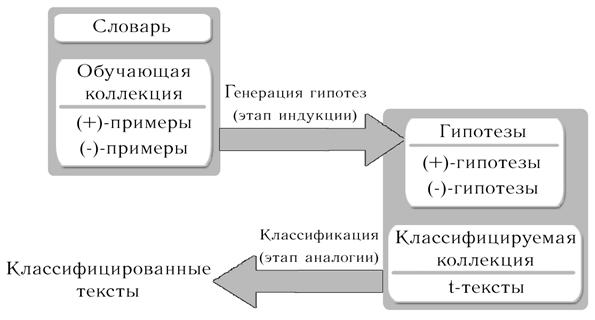
Рис. 1 – Схема ДСМ-метода классификации текстов
Для реализации ДСМ-метода используются три основных компонента: словарь, обучающая коллекция текстов и классифицируемые тексты. Словарь и обучающая коллекция используются для формирования множества гипотез, характеризующих принадлежность текста к определенному классу. Гипотезы сравниваются с фрагментами классифицируемых текстов на предмет совпадения. По результатам сравнения делается заключение об эмоциональной категории этих текстов.
Словарь может быть сформирован как автоматически (содержит без исключения все слова из обучающей коллекции), так и вручную (содержит только слова, имеющие явно выраженную эмоциональную окраску).
Обучающая коллекция составляется из текстов, тональность которых известна. Классифицируемая коллекция содержит тексты, тональность которых неизвестна и ее требуется определить.
1.2.2. Описание метода
ДСМ-метод – это метод автоматического порождения гипотез. Был предложен в конце 1970-х гг. Свое название метод получил от инициалов известного английского философа, логика и экономиста Джона Стюарта Милля. ДСМ-метод представляет собой формализацию правдоподобных рассуждений, которая позволяет на основе анализа имеющихся данных формировать гипотезы о том, какими свойствами могут обладать рассматриваемые объекты. ДСМ-метод – это синтез трех познавательных процедур – эмпирической индукции, структурной аналогии и абдукции. В данной работе мы рассмотрим только два этапа этого метода – этапы индукции и аналогии.
В соответствии с [8] будем использовать следующие условные обозначения: О – множество объектов предметной области, Р – множество свойств этих объектов, С – множество характеристик объектов, являющихся возможными причинами свойств, V – множество истинностных оценок объектов.
На вход ДСМ-метод подается множество изучаемых объектов и информация о наличии или отсутствии у них определенных свойств. Кроме того, имеется ряд целевых признаков, каждый из которых разбивает исходное множество объектов на четыре непересекающихся подмножества:
– объекты, про которые известно, что они обладают данным признаком,
– объекты, про которые известно, что они не обладают данным признаком,
– объекты, для которых существуют аргументы как за, так и против того, что они обладают данным признаком,
– объекты, о которых неизвестно, обладают они этим признаком или нет.
В задаче определения тональности текста с двумя эмоциональными категориями множество О содержит исследуемые тексты; множество Р состоит из одного элемента (свойства) ![]() , обозначающего положительную тональность текста (отсутствие этого свойства означает, что тональность текста отрицательна); множество С включает характеристики, отвечающие за представление текстов, например характеристика может быть отдельным словом или словосочетанием; множество
, обозначающего положительную тональность текста (отсутствие этого свойства означает, что тональность текста отрицательна); множество С включает характеристики, отвечающие за представление текстов, например характеристика может быть отдельным словом или словосочетанием; множество ![]() , где +1 означает, что объект обладает свойством
, где +1 означает, что объект обладает свойством ![]() , –1 означает, что объект не обладает свойством
, –1 означает, что объект не обладает свойством ![]() , 0 – наличие противоречия (т. е. имеются аргументы как за, так и против того, что объект обладает свойством
, 0 – наличие противоречия (т. е. имеются аргументы как за, так и против того, что объект обладает свойством ![]() ),
), ![]() – отсутствие информации о свойстве
– отсутствие информации о свойстве ![]() ) [9].
) [9].
Множество текстов О состоит из трех подмножеств: тексты положительной тональности (+1), тексты отрицательной тональности (–1) и тексты, тональность которых требуется определить (![]() -тексты). Первые два подмножества образуют обучающую коллекцию текстов, третье подмножество – тестовую коллекцию.
-тексты). Первые два подмножества образуют обучающую коллекцию текстов, третье подмножество – тестовую коллекцию.
Идея ДСМ-метода заключается в следующем. Сначала составляется коллекция текстов, для которых точно известна эмоциональная окраска. На основе имеющейся коллекции производится обучение классификатора. Оно заключается в формировании гипотез (этап индукции). Гипотеза представляет собой пересечение текстов коллекции. С помощью соответствующего алгоритма находят всевозможные пересечения текстов. Для каждой эмоциональной категории формируется отдельное множество гипотез.
Далее следует этап аналогии. Сформированные гипотезы поочередно сравниваются в ![]() -текстами. Если гипотеза содержатся в обрабатываемом тексте, то она помечается каким-либо образом. После того, как все гипотезы проверены на совпадение с текстом, можно выделить множество помеченных гипотез. Такое множество выделяется в каждой эмоциональной категории.
-текстами. Если гипотеза содержатся в обрабатываемом тексте, то она помечается каким-либо образом. После того, как все гипотезы проверены на совпадение с текстом, можно выделить множество помеченных гипотез. Такое множество выделяется в каждой эмоциональной категории.
На последнем этапе остается сделать заключение, к какому классу отнести ![]() -текст. В задаче определения тональности текста используется достаточно большое количество характеристик объектов (порядка 104) и порожденных гипотез (порядка 104–106) [9]. Вследствие этого происходят многочисленные совпадения характеристик как положительных гипотез, так и отрицательных с
-текст. В задаче определения тональности текста используется достаточно большое количество характеристик объектов (порядка 104) и порожденных гипотез (порядка 104–106) [9]. Вследствие этого происходят многочисленные совпадения характеристик как положительных гипотез, так и отрицательных с ![]() -текстами, т. е. имеют место множественные конфликты. Для выхода из этой ситуации используется функция разрешения конфликтов. В качестве критериев, позволяющих присвоить тональность
-текстами, т. е. имеют место множественные конфликты. Для выхода из этой ситуации используется функция разрешения конфликтов. В качестве критериев, позволяющих присвоить тональность ![]() -текстам, можно рассматривать:
-текстам, можно рассматривать:
а) суммарное количество гипотез
![]() ,
, ![]() , (2)
, (2)
где ![]() ,
, ![]() – положительные и отрицательные гипотезы соответственно;
– положительные и отрицательные гипотезы соответственно;
![]() – коэффициент, учитывающий дисбаланс количества положительных и отрицательных текстов,
– коэффициент, учитывающий дисбаланс количества положительных и отрицательных текстов,

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 |
