


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Второй подход основан на использовании подграфовой метрики. На множестве графов задается мера, которая позволяет оценить, насколько те или иные структуры «похожи» друг на друга. В зарубежной литературе это направление получило название «graph matching». Среди способов количественной оценки сходства графов можно выделить следующие:
- Мера на основе наибольшего общего подграфа:
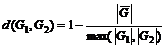 ,
,
где ![]() – максимальный общий подграф графов
– максимальный общий подграф графов ![]() и
и ![]() , а
, а ![]() – число вершин графа
– число вершин графа ![]() .
.
- Мера на основе минимального общего надграфа:
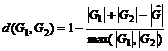 ,
,
где ![]() – минимальный общий надграф графов
– минимальный общий надграф графов ![]() и
и ![]() .
.
- Мера на основе операций редактирования (вставка, удаление и переименование вершин и ребер). Расстояние определяется как наименьшая последовательность ![]() операций редактирования, которые преобразуют один граф в другой с минимальным суммарным весом
операций редактирования, которые преобразуют один граф в другой с минимальным суммарным весом ![]() :
:
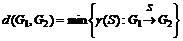 .
.
Однако для того чтобы учитывать порядок появления вершин и ребер некоторого графа ![]() , который отражает развитие структуры во времени, требуется модифицировать существующие меры. Пусть
, который отражает развитие структуры во времени, требуется модифицировать существующие меры. Пусть ![]() – это множество графов без изолированных вершин с
– это множество графов без изолированных вершин с ![]() упорядоченными ребрами. Для
упорядоченными ребрами. Для ![]() рассмотрим цепочку порождающих его графов
рассмотрим цепочку порождающих его графов 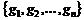 , где граф
, где граф ![]() – это подграф
– это подграф ![]() , который содержит ребра с номерами от 1 до
, который содержит ребра с номерами от 1 до ![]() и все вершины, инцидентные этим ребрам.
и все вершины, инцидентные этим ребрам.
Тогда расстояние между графами ![]() можно определить следующим образом:
можно определить следующим образом:
1. 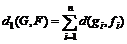 .
.
2. 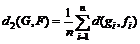 .
.
3. 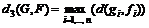 .
.
На множестве ![]() расстояния
расстояния ![]() удовлетворяют всем свойствам метрики. В общем случае мера между произвольными графами
удовлетворяют всем свойствам метрики. В общем случае мера между произвольными графами ![]() и
и ![]() с
с ![]() и
и ![]() ребрами соответственно находится следующим образом (пусть для определенности
ребрами соответственно находится следующим образом (пусть для определенности ![]() ):
):
1. 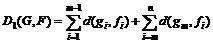 .
.
2. 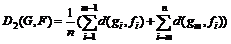 .
.
3. 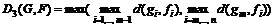 .
.
В диссертации показано, что расстояние ![]() удовлетворяет всем свойствам метрики.
удовлетворяет всем свойствам метрики.
В 3 главе описана информационная система по исследованию фольклорных коллекций с теоретико-графовой формализацией текстов, разработанная в среде визуального программирования Delphi 7.0.
При создании системы были поставлены следующие цели:
1. Разработка инструмента для ввода, хранения и исследования фольклорных коллекций с теоретико-графовой формализацией текстов.
2. Апробация предложенных математических методов анализа графов.
3. Проведение исследований по конкретным фольклорным коллекциям.
Для этого необходимо решить следующие задачи:
1. Разработать структуру базы данных для хранения текстов и соответствующих им графов.
2. Автоматизировать процесс построения теоретико-графовых моделей.
3. Реализовать методы двух - и трехмерной визуализации графов.
4. Реализовать алгоритмы аппроксимации графов.
5. Реализовать методы сравнения графов при помощи метрик на основе операций редактирования и общих подграфов.
6. Разработать удобный интерфейс и средства помощи.
Общая структура созданной программы представлена на рис. 2.
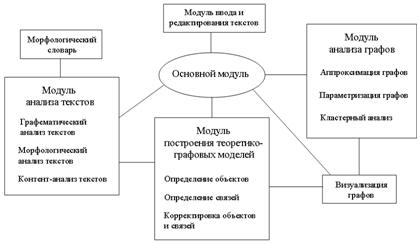
Рис. 2. Общая структура программы
Главный модуль системы предназначен для ознакомления с коллекцией и является связующим звеном между остальными частями программы. Модуль анализа текстов включает процедуры графематического, морфологического и контент-анализа текстов.
Второй модуль программы используется для автоматизированного построения теоретико-графовых моделей текстов. В системе реализована следующая пошаговая процедура:
Шаг 1: Выбор параметров построения графа.
Шаг 2: Определение объектов в тексте.
Шаг 3: Разбиение объектов на группы.
Шаг 4: Определение связей в тексте.
Шаг 5: Разбиение связей на группы.
Пользователь может в любой момент скорректировать полученный граф (например, удалить или добавить связи и объекты, изменить их свойства и т. д.).
Третий модуль программы предназначен для анализа теоретико-графовых моделей текстов. В системе реализованы следующие методы:
1. Методы визуализации графов (в том числе метод поуровневого изображения деревьев, методы двухмерной и трехмерной визуализации теоретико-графовых моделей фольклорных песен).
2. Методы аппроксимации графов (алгоритм И. Б. Мучника и алгоритм В. Л. Куперштоха – В. А. Трофимова, модифицированные для аппроксимации графов с упорядоченными вершинами и ребрами).
3. Методы сравнения и классификации графов при помощи параметризации (по степени связности графов, распределению объектов и связей на группы, ранговому распределению объектов по количеству связей и т. д.).
4. Методы сравнения и классификации графов при помощи метрик на основе общих подграфов и операций редактирования.
В настоящее время ведется работа над реализацией системы в виде специализированного Интернет-ресурса по представлению и анализу фольклорных коллекций. Основными целями этого проекта являются:
1. Публикация информации о проекте и предоставление коллекций текстов.
2. Демонстрация применения математических методов для анализа текстов.
3. Обеспечение удаленного доступа к информационной системе для потенциальных пользователей, предоставление им возможности работы в системе со своими материалами.
4. Разработка и апробация методики создания подобного наукоемкого ресурса, изучение его функциональности и полезности для научного сообщества.
4 глава посвящена применению теоретико-графовых моделей для исследования коллекции бесёдных песен Заонежья XIX – начала XX века. Свойства графов анализировались при помощи следующих параметров:
· Параметры размерности графов. По числу вершин и ребер были выделены три группы песен:
1 группа: 62% песен (число вершин ![]() , а ребер
, а ребер ![]() ). В эту группу попали все песни на темы «свадьба» и «игра». Также сюда вошли все медленные песни, где число объектов примерно 8-10.
). В эту группу попали все песни на темы «свадьба» и «игра». Также сюда вошли все медленные песни, где число объектов примерно 8-10.
2 группа: 28% песен (число вершин ![]() , а число ребер
, а число ребер ![]() ). В группу вошли любовные и семейные песни, которые исполняются в быстром темпе.
). В группу вошли любовные и семейные песни, которые исполняются в быстром темпе.
3 группа: 10% песен (число вершин ![]() , число ребер
, число ребер ![]() ). В эту группу вошли любовные и семейные песни с большим числом объектов и связей.
). В эту группу вошли любовные и семейные песни с большим числом объектов и связей.
· Параметры связности текстов. Для анализа связности фольклорных песен введем понятие графа связности мотивов ![]() . Пусть
. Пусть ![]() – это подграф графа
– это подграф графа ![]() , соответствующий
, соответствующий ![]() мотиву. Два мотива
мотиву. Два мотива ![]() и
и ![]() будем считать связанными, если существует вершина
будем считать связанными, если существует вершина ![]() , такая что
, такая что ![]() и
и ![]() , или между некоторыми вершинами
, или между некоторыми вершинами ![]() и
и ![]() существует глобальное отношение. Тогда параметр связности мотивов
существует глобальное отношение. Тогда параметр связности мотивов ![]() определим по следующей формуле:
определим по следующей формуле:
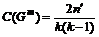 ,
,
где ![]() - это число мотивов, а
- это число мотивов, а ![]() – число пар мотивов, связанных между собой. Параметр
– число пар мотивов, связанных между собой. Параметр ![]() принимает значения на отрезке от 0 до 1. При этом
принимает значения на отрезке от 0 до 1. При этом 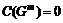 соответствует нуль-графу, а
соответствует нуль-графу, а ![]() – полному графу.
– полному графу.
В результате, по структуре мотивов песни разделились на следующие группы: 48% имеют монолитную структуру (![]() превышает значение 0,8), 34% песен имеют незамкнутую цепочечную или кусочно-линейную структуру, 12% представлены несвязными графами (
превышает значение 0,8), 34% песен имеют незамкнутую цепочечную или кусочно-линейную структуру, 12% представлены несвязными графами (![]() не превышает 0,33). Радиальные и кольцевые структуры в бесёдных песнях практически не встречаются.
не превышает 0,33). Радиальные и кольцевые структуры в бесёдных песнях практически не встречаются.
· Значимость объектов в песнях. Для определения этой характеристики использовались следующие параметры:
- Максимальная степень вершины ![]() .
.
- Функциональный вес вершины ![]() .
.
- Параметры аппроксимации рангового распределения объектов по числу их связей гиперболической кривой.
При этом были обнаружены следующие закономерности. Песни, где значение ![]() превышает 10, исполняются «довольно бегло» «с тихой пляской-шеном». Это, как правило, хороводные песни. Для песен вида «бесёдная», «свадебная бесёдная» и «плясовая» в среднем значение
превышает 10, исполняются «довольно бегло» «с тихой пляской-шеном». Это, как правило, хороводные песни. Для песен вида «бесёдная», «свадебная бесёдная» и «плясовая» в среднем значение ![]() равно 6,5 и не превышает 10. Для песен «в кругу-круговая» и «пляска в кругу» этот параметр в среднем равняется 10,5 с достаточно большим разбросом (
равно 6,5 и не превышает 10. Для песен «в кругу-круговая» и «пляска в кругу» этот параметр в среднем равняется 10,5 с достаточно большим разбросом (![]() =10,7).
=10,7).
· Распределение объектов и связей на группы. Согласно А. Т. Хроленко, объекты песен делятся на следующие группы: «люди», «части человеческого тела», «проявление качеств человека», «одежда и украшения», «жилище», «пища, питье», «животный мир», «растительный мир», «земля и воды», «явления природы» и «разные предметы». На наш взгляд, к этому разбиению необходимо добавить еще две группы: «конструкции» и «обычаи, традиции».
В результате оказалось, что в любовных песнях чаще, чем в остальных, встречаются объекты групп «части человеческого тела», «проявление качеств человека» и «земля и воды». Для семейных песен характерны объекты группы «разные предметы» и «конструкции». В свадебных песнях ярко выраженных групп не выделяется. Объекты из других групп встречаются в текстах в приблизительно одинаковой пропорции.
Для классификации песен введем понятие графа распределения связей по группам. Вершинами графа являются группы объектов, а связи характеризуют частоту локальных связей между ними. Для определения сходства таких графов можно использовать коэффициент Роджерса-Танимото:
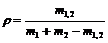 ,
,
где ![]() и
и ![]() – число вершин в графах, а
– число вершин в графах, а ![]() – число общих вершин. При помощи этой меры были выделены наиболее типичные песни заданной «темы».
– число общих вершин. При помощи этой меры были выделены наиболее типичные песни заданной «темы».
· Параметры, позволяющие сравнивать семантическую структуру бесёдных песен. В качестве меры сходства на множестве графов рассмотрено расстояние на основе операций редактирования. При определении данной меры были использованы графы основных потоков связей с небольшим числом вершин и ребер. Оказалось, что для бесёдных песен подобные графы имеют вид дерева. По числу вершин их можно разбить на четыре группы.
Полученные методы и закономерности могут быть использованы для решения вопросов классификации фольклорных песен.
В приложении 1 представлено свидетельство об официальной регистрации программы для ЭВМ в Федеральной службе по интеллектуальной собственности, патентам и товарным знакам (Роспатенте).
В приложении 2 содержатся примеры теоретико-графовых моделей фольклорных песен («Уж ты Ванюша, Иван», «Широкая борода», «Девушка в горенке сидела», «Тропинкой шла» и «Как назябло, навеяло лицо»).
В приложении 3 представлено DTD-описание языка TextGML 1.0 и пример формализации бесёдной песни «Все мужовья до жон добры».
В приложении 4 приводится описание нескольких алгоритмов, реализованных в информационной системе «Фольклор».
Заключение
В заключении сформулируем основные результаты работы:
1. Разработана теоретико-графовая модель семантической структуры фольклорных песен.
2. Предложен метод визуализации теоретико-графовых моделей фольклорных песен.
3. Предложен метод аппроксимации графов с упорядоченными вершинами.
4. Предложен метод сравнения текстов, основанный на модификации метрик для графов с упорядоченными ребрами.
5. Разработан язык теоретико-графовой разметки текстов TextGML на основе XML, предназначенный для описания теоретико-графовых моделей.
6. Создана информационная система по исследованию фольклорных коллекций с теоретико-графовой формализацией текстов на языке визуального программирования Delphi 7.0.
Данное исследование может быть продолжено дальнейшей модификацией методов сравнения и аппроксимации графов (например, с учетом иерархической организации текста и экспериментального характера построенных графов), разработкой новых методов анализа текстов на основе теоретико-графовых моделей (например, восстановление структуры графов, что может пригодиться при реконструкции текстов), апробацией рассмотренных методов на примере коллекций других фольклорных жанров: духовных стихов, сказок, причитаний и т. д.
Публикации по теме диссертации
1. Москин Н. Д. Авторское свидетельство об официальной регистрации программы для ЭВМ «Информационная система по исследованию фольклорных коллекций с теоретико-графовой формализацией текстов» № 2006612744. Федеральная служба по интеллектуальной собственности, патентам и товарным знакам (Роспатент), 03.08.2006.
2. Варфоломеев А. Г., Кравцов И. В., Москин Н. Д. Информационная система по фольклорным песням Заонежья как инструмент формализации и классификации песен // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: Труды IV Всероссийской научной конференции RCDL'2002. Т. 2. – Дубна, 2002. – С. 143-147.
3. , Москин система по фольклорным песням Заонежья конца XIX – начала XX века с формальным представлением структуры текста // Daugavpils Universi-tātes Humanitārās fakultātes XII Zinātnisko lasījumu materiāli. Vesture. VI(I). – Daugavpils: Saule, 2003. – С. 126-131.
4. , О применении компьютерных технологий в исследовании фольклорных песен // Материалы IV Международной научной конференции «Рябининские чтения»: Локальные традиции в народной культуре Русского Севера. – Петрозаводск, 2003. – С. 424-427.
5. Варфоломеев А. Г., Кравцов И. В., Москин Н. Д. Проект специализированного Интернет-ресурса для представления и анализа фольклорных песен // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: Труды V Всероссийской научной конференции RCDL'2003. – Санкт-Петербург, 2003.– С. 339-343.
6. Варфоломеев А. Г., Москин Н. Д. Об электронной коллекции фольклорных песен с теоретико-графовой формализацией текстов // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: Сборник аннотаций стендовых докладов III Всероссийской научной конференции RCDL'2001. – Петрозаводск, 2001. – С. 20.
7. Варфоломеев А. Г., Москин Н. Д. Проект информационной системы для представления и анализа текстов фольклорных песен // VII ежегодная конференция АДИТ-2003 «Информационные технологии: доступ к культурному наследию». Тезисы докладов. – Пушкинские Горы, 2003. – С. 101-103.
8. Москин Н. Д. К вопросу об изучении фольклорного наследия при помощи компьютерных технологий // Международная школа молодых фольклористов. Тезисы докладов. – Пушкин, 2003. – С. 16.
9. Москин Н. Д., Петров А. М. Духовный стих и былина: математические методы исследования специфики фольклорного жанра // Русская и сопоставительная филология: состояние и перспективы: Труды и материалы Международной научной конференции, посвященной 200-летию Казанского университета. – Казань, 2004. – С. 296-297.
10. Москин Н. Д. Применение контент-анализа для исследования коллекции текстов о народных святых Нижегородского края // Информационный бюллетень Ассоциации «История и компьютер». № 34. Материалы Х конференции АИК. – Москва, 2006. – С. 79-80.
Подписано в печать 18.09.06. Формат 60х84 1/16.
Бумага офсетная. Офсетная печать.
1 уч.-изд. л. Тираж 100 экз. Изд. № 213.
Государственное образовательное учреждение высшего
профессионального образования
ПЕТРОЗАВОДСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Отпечатано в типографии Издательства ПетрГУ.
185910, г. Петрозаводск, пр. Ленина, 33

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
