
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Тогда матрица коэффициентов усиления ![]() примет вид:
примет вид:
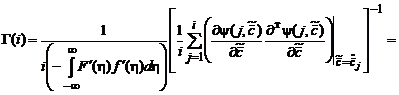
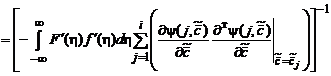 .
.
Воспользуемся леммой об обращении квадратных матриц. Если квадратная матрица имеет вид
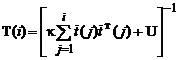 ,
,
где k — скаляр, ![]() — вектор, U — постоянная симметричная матрица той же размерности, то справедливо следующее рекуррентное соотношение:
— вектор, U — постоянная симметричная матрица той же размерности, то справедливо следующее рекуррентное соотношение:
![]() ,
,
![]() .
.
Полагая 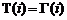 ;
; 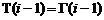 ;
;
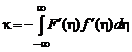 ; ,
; ,![]() ,
,
получим для коэффициента усиления:
![]()
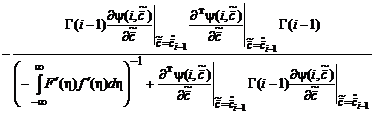 .(2.1.55)
.(2.1.55)
В качестве начального приближения принимают матрицу
![]() , (2.1.56)
, (2.1.56)
где n — большое число.
Таким образом, оптимальный рекуррентный алгоритм будет состоять из двух вычисляемых формул
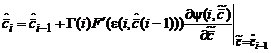 , (2.1.57)
, (2.1.57)
где ![]() вычисляется на каждом шаге рекуррентного процесса по формуле (2.1.53) при начальных условиях (2.1.56). Начальное приближение
вычисляется на каждом шаге рекуррентного процесса по формуле (2.1.53) при начальных условиях (2.1.56). Начальное приближение ![]() может быть задано любым вектором соответствующей размерности.
может быть задано любым вектором соответствующей размерности.
В заключение данного раздела запишем рекуррентный оптимальный алгоритм для линейного динамического объекта:
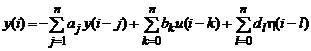 .
.
Как известно, оптимальная настраиваемая модель, соответствующая данному объекту, имеет вид:
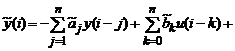
![]()
или, используя введенные в части I обозначения (1.42),
![]() .
.
Тогда
![]() . (2.1.58)
. (2.1.58)
Подставляя (2.1.58) в рекуррентные соотношения (2.1.55), (2.1.57), получим:
![]() ; (2.1.59а)
; (2.1.59а)
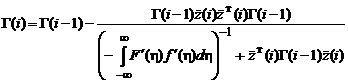 ,
,
![]() , (2.1.59б)
, (2.1.59б)
где ![]() — любой вектор,
— любой вектор, ![]() , l — большое число.
, l — большое число.
2.1.5. Оптимальная функция потерь
В предыдущем разделе получили формулу для АМКО (2.1.53), оптимальной по матрице В:
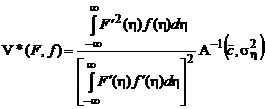 .
.
Будем считать, что плотность распределения ошибок измерений известна. Тогда поставим задачу подобрать такую функцию потерь ![]() , которая обеспечит минимальное значение АМКО. Для решения этой задачи рассмотрим изменение АМКО при варьировании оптимальной функции потерь
, которая обеспечит минимальное значение АМКО. Для решения этой задачи рассмотрим изменение АМКО при варьировании оптимальной функции потерь ![]() :
:
![]() ,
,
где l — параметр, dF — произвольная вариация функции потерь.
Условие экстремума АМКО имеет вид:
![]() .
.
Рассмотрим, что представляет собой матрица j(l):
![]()
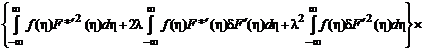
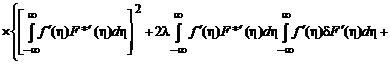
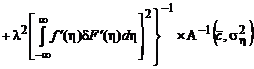 .
.
Тогда
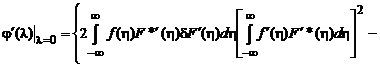
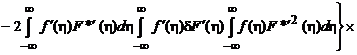
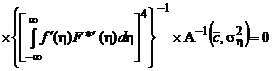 .
.
Откуда следует, что
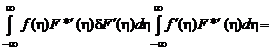
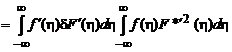 .
.
Преобразуя последнее выражение, получаем:
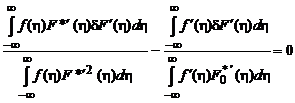 .
.
Так как ![]() может быть любой функцией, то
может быть любой функцией, то
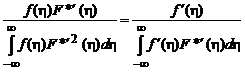 , (2.1.60)
, (2.1.60)
или, после умножения обеих частей (2.1.60) на ![]() :
:
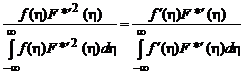 . (2.1.61)
. (2.1.61)
Нетрудно заметить, что (2.1.61) представляет собой равенство нормированных функций. Это равенство справедливо только в том случае, если сами функции пропорциональны. Таким образом, получаем:
![]() ,
,
где ![]() — коэффициент пропорциональности. Отсюда следует, что
— коэффициент пропорциональности. Отсюда следует, что
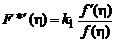 ,
,
т. е.
![]() .
.
И, следовательно, оптимальная функция потерь определяется соотношением:
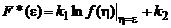 .
.
В последнем выражении неопределенными оказываются коэффициенты ![]() и
и ![]() . Для их определения рассмотрим графики (рис.2.1.1) плотности распределения и логарифма плотности распределения шума h.
. Для их определения рассмотрим графики (рис.2.1.1) плотности распределения и логарифма плотности распределения шума h.
|
|
а | б |
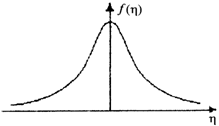
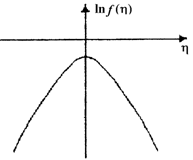
Рис.2.1.1. Типичный вид плотности распределения (а)
и логарифма плотности распределения шума h (б)
Как правило, это уже не раз использовалось, плотность распределения ![]() является четной функцией, а логарифм плотности распределения — четная убывающая функция, имеющая максимальное значение при h = 0. Таким образом, для того, чтобы
является четной функцией, а логарифм плотности распределения — четная убывающая функция, имеющая максимальное значение при h = 0. Таким образом, для того, чтобы 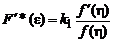 имела смысл функции потерь, т. е. имела минимум при e = 0, необходимо условие
имела смысл функции потерь, т. е. имела минимум при e = 0, необходимо условие ![]() (рис.2.1.2).
(рис.2.1.2).
Рис.2.1.2. График зависимости функции потерь от невязок e при |
|
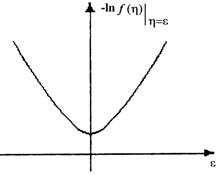
Что же касается параметра ![]() , то он определяет минимальное значение
, то он определяет минимальное значение ![]() . При
. При ![]() всегда выполняется неравенство
всегда выполняется неравенство ![]() .
.
Таким образом, оптимальная функция потерь не единственна, а зависит от параметров ![]() и
и ![]() . Этот факт является следствием того, что АМКО зависит не от
. Этот факт является следствием того, что АМКО зависит не от ![]() , а от
, а от ![]() .
.
Для задач идентификации конкретные значения этих параметров несущественны. Удобно принять ![]() , а
, а ![]() . Таким образом, оптимальная функция потерь равна логарифму плотности распределения помех с обратным знаком:
. Таким образом, оптимальная функция потерь равна логарифму плотности распределения помех с обратным знаком:
![]() . (2.1.62)
. (2.1.62)

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
