
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Сравним полученный результат с оптимизируемым критерием в методе максимума правдоподобия при аддитивной помехе. Приведем примеры оптимальных функций потерь и их производных.
1. Нормальная (гауссова) плотность распределения помех:
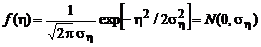 .
.
Функция потерь, согласно (2.1.18), будет иметь вид:
![]() ,
, ![]() . (2.1.63)
. (2.1.63)
Поскольку положение экстремума не зависит от постоянных слагаемых и множителей, то можно записать следующий оптимизируемый критерий:
![]()
или в векторной форме: 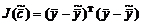 .
.
Таким образом, при нормальном законе распределения использование оптимальной функции потерь эквивалентно применению метода наименьших квадратов.
2. Экспоненциальная (лапласова) плотность распределения помех
![]() .
.
Для функции потерь получаем:
![]() ,
, ![]() . (2.1.64)
. (2.1.64)
В данном случае получили модульную функцию потерь. Использование метода наименьших квадратов дает худшие асимптотические свойства оценок.
3. Дробная (Коши) плотность распределения помех:
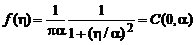 .
.
В этом случае имеем:
![]() ,
, ![]() . (2.1.65)
. (2.1.65)
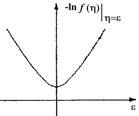
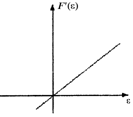
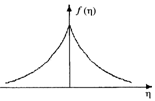
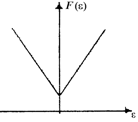
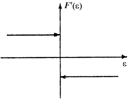
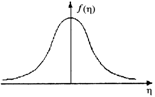
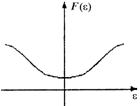
Эти и некоторые другие виды функций потерь и их производные приведены в табл.2.1.1 [3].
Таблица 2.1.1
Оптимальные функции потерь и их производные
Плотность распределения f(h) | Функция потерь F(e) | Производная функции потерь F¢(e) |
|
|
|
|
|
|
|
|
|
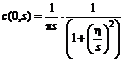
2.1.6. АМКО при оптимальной функции потерь
Найдем, чему равна асимптотическая матрица ковариаций при оптимально выбранной функции потерь, т. е.
![]() . (2.1.66)
. (2.1.66)
Подставив выражение (2.1.66) для оптимальной функции потерь в формулу для АМКО (2.1.53), получим:
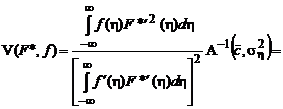
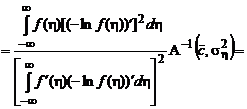
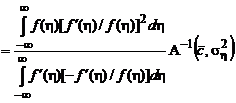 .
.
Приводя подобные члены, окончательно получаем:
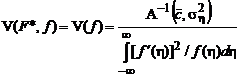 . (2.1.67)
. (2.1.67)
Выражение, стоящее в знамена, называется фишеровской информацией:
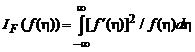 . (2.1.68)
. (2.1.68)
Очевидно, справедливо следующее неравенство:
![]() , (2.1.69а)
, (2.1.69а)
где 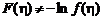 ,
, 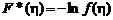 . Или, раскрывая
. Или, раскрывая ![]() и
и 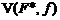 , получим:
, получим:
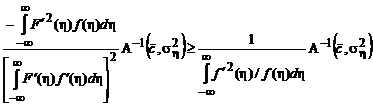 . (2.1.69б)
. (2.1.69б)
Важно отметить, что, если нормированная асимптотическая матрица не зависит от ![]() и
и ![]() (регрессионный объект), то неравенство (2.1.69б) можно упростить:
(регрессионный объект), то неравенство (2.1.69б) можно упростить:
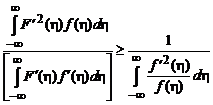 . (2.1.70)
. (2.1.70)
Получившееся значение АМКО совпадает с нижним пределом, которое устанавливается неравенством Крамера — Рао:
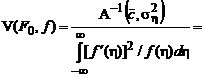
![]() ,
,
где 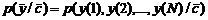 — совместная плотность распределения выходов объекта, имеющего вектор параметров
— совместная плотность распределения выходов объекта, имеющего вектор параметров ![]() .
.
Таким образом, знание плотности распределения помехи ![]() позволяет определить оптимальную функцию потерь. При этом оценка
позволяет определить оптимальную функцию потерь. При этом оценка ![]() обладает максимальной асимптотической скоростью сходимости.
обладает максимальной асимптотической скоростью сходимости.
2.1.7. Абсолютно оптимальные рекуррентные алгоритмы
Запишем абсолютно оптимальный рекуррентный алгоритм для нелинейного объекта
![]() .
.
Для этого подставим в рекуррентные соотношения (2.1.55), (2.1.57) оптимальную функцию потерь (2.1.62), а именно:
![]() . (2.1.71)
. (2.1.71)
Тогда получим:
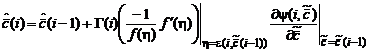 , (2.1.72а)
, (2.1.72а)
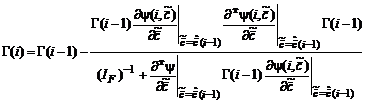 ,(2.1.72б)
,(2.1.72б)
![]() ,
, ![]() ,
, ![]() ,
, ![]() — любой вектор соответствующей размерности,
— любой вектор соответствующей размерности, ![]() — фишеровская информация, рассчитываемая по формуле:
— фишеровская информация, рассчитываемая по формуле:
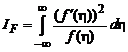 . (2.1.73)
. (2.1.73)
В табл.2.1.2 приведены значения фишеровской информации для наиболее распространенных распределений.
Таблица 2.1.2
Фишеровская информация
№ | Распределение | Фишеровская информация |
1 | Нормальное |
|
2 | Лапласа |
|
3 | Коши |
|
В случае линейного РАР объекта ![]() определяется формулой (2.1.58), а именно:
определяется формулой (2.1.58), а именно: ![]() .
.
Тогда, подставляя последнее выражение в рекуррентные соотношения (2.1.72а, б), получим:
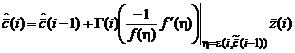 , (2.1.74а)
, (2.1.74а)
![]() , (2.1.74б)
, (2.1.74б)
![]() ,
, ![]() ,
, ![]() .
.
В заключение настоящего раздела запишем оптимальные рекуррентные алгоритмы для различных плотностей распределения, приведенных в табл.2.1.2.
1. Нормальная плотность распределения помехи:
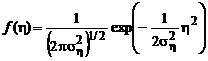 .
.
Введем обозначения: 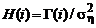 .
.
Тогда в новых обозначениях рекуррентный алгоритм для нормального распределения запишем в виде
![]() , (2.1.75а)
, (2.1.75а)
![]() ;
;
![]() , (2.1.75б)
, (2.1.75б)
![]() ,
, ![]() .
.
Сравнивая (2.1.75а, б) с рекуррентными соотношениями (2.64), (2.67), (2.68), можно сделать вывод, что рекуррентная форма метода наименьших квадратов полностью совпадает с абсолютно оптимальным алгоритмом для нормального распределения помехи.
Алгоритм (2.1.75а) называется линейным алгоритмом. Как видим, линейный оптимальный алгоритм не зависит от дисперсии помехи.
2. Лапласова плотность распределения помехи.
Принимая во внимание значение плотности распределения Лапласа и соответствующую фишеровскую информацию (см. табл.2.1.2), оптимальный рекуррентный алгоритм (2.1.74а, б) запишем в виде:
![]() , (2.1.76а)
, (2.1.76а)
![]() ;
;
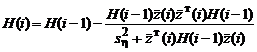 , (2.1.76б)
, (2.1.76б)
![]() ,
, ![]() ,
, ![]() .
.
Данный алгоритм называется релейным.
3. Плотность распределения помехи Коши.
В этом случае, подставляя в формулы (2.1.74а, б) плотность распределения и фишеровскую информацию (см. табл.2.1.2), соответствующие распределению Коши, получим нелинейный оптимальный алгоритм:
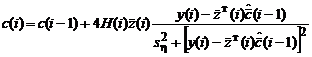 , (2.1.77а)
, (2.1.77а)
![]() ;
;
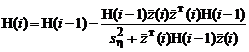 , (2.1.77б)
, (2.1.77б)
![]() .
.
Приведенные абсолютно оптимальные алгоритмы идентификации РАР — объектов с простой помехой, как было показано в предыдущем разделе, обладают предельно возможной скоростью сходимости, определяемой нижней границей неравенства Крамера — Рао. Их АМКО равна:
![]() , (2.1.78)
, (2.1.78)
где 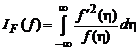 — фишеровская информация,
— фишеровская информация, ![]() — нормированная информационная матрица системы.
— нормированная информационная матрица системы.
2.1.8. Пример использования абсолютно оптимальных
рекуррентных алгоритмов для идентификации параметров
линейного регрессионного объекта
Для оценки эффективности использования абсолютно оптимальных алгоритмов рассмотрим задачу идентификации параметров линейного регрессионного объекта вида
![]() . (2.1.79)
. (2.1.79)
Шум измерений h(i) имеет распределение Коши:
![]() .
.
Для оценки эффективности абсолютно оптимальных рекуррентных алгоритмов проводилось сравнение нелинейного (абсолютно оптимального алгоритма) и линейного алгоритмов для идентификации линейного регрессионного объекта вида (2.1.79) при различных значениях параметра распределения Коши — s.
На рис.2.1.3, 2.1.4 приведены графики интегральной скользящей ошибки оценки, вычисляемой по формуле:
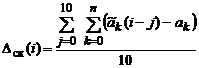 ;
; ![]() .
.
в зависимости от номера измерений i.
Из рисунков видно, что использование абсолютно оптимального алгоритма обеспечивает существенно меньшую ошибку оценки даже при больших значениях параметра распределения — s.
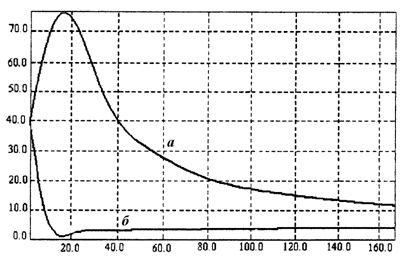
Рис.2.1.3. График зависимости сглаженной ошибки оценки от номера измерений при использовании линейного (а) и абсолютно оптимального (б) алгоритмов при s = 2
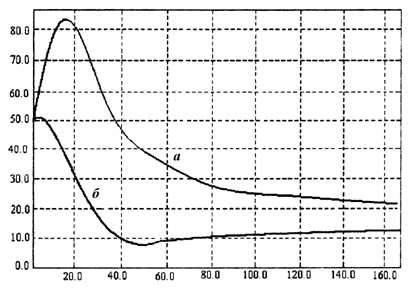
Рис.2.1.4. График зависимости сглаженной ошибки оценки от номера измерений при использовании линейного (а) и абсолютно оптимального (б) алгоритмов при s = 7

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
