

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
,
НГТУ им.
ИСПОЛЬЗОВАНИЕ СВЕРХОПЕРАТИВНОЙ ПАМЯТИ ДЛЯ РЕШЕНИЯ СИСТЕМЫ АЛГЕБРАИЧЕСКИХ УРАВНЕНИЙ МЕТОДОМ ПЕРЕМЕННЫХ НАПРАВЛЕНИЙ
Для решении задач теплопроводности удобно использовать метод Патанкара. Метод решения системы уравнений, предложенный профессором С. Патанкаром основывается на очень эффективном алгоритме, известным как TDMA (TriDiagonal-Matrix Algorithm). Название TDMA происходит из свойства матрицы коэффициентов дискретных аналогов: в этой матрице ненулевые элементы располагаются только на трех смежных диагоналях.
Рассмотрим уравнение теплопроводности:
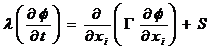 . (1)
. (1)
Выражение для его дискретного аналога будет иметь следующий вид:
![]() , (2)
, (2)
где: P – индекс расчетной точки, E – индекс соседней справа точки, W – индекс соседней слева точки, N – индекс соседней сверху точки, S – индекс соседней снизу точки.
Как легко заметить, при расчете очередной точки, используются значения четырех соседних точек. Если быть точнее: используются значения коэффициентов четырех соседних точек, а также значения четырех соседних ![]() . Иными словами, при реализации данного алгоритма в качестве программы для вычислительной системы, мы имеем дело с одновременным обращением к четырем ячейкам памяти, выполнении нескольких простых арифметических действий и записью результата в пятую ячейку памяти (ОЗУ).
. Иными словами, при реализации данного алгоритма в качестве программы для вычислительной системы, мы имеем дело с одновременным обращением к четырем ячейкам памяти, выполнении нескольких простых арифметических действий и записью результата в пятую ячейку памяти (ОЗУ).
Известно, что в силу определенных обстоятельств (сложность изготовления, а следовательно, и высокая стоимость оперативной памяти, работающей на той же частоте, что и процессор) оперативная память работает на достаточно низкой, по сравнению с процессорной, частоте. Отсюда вытекает и большое время доступа к ячейкам оперативной памяти, составляющее несколько десятков и даже сотен тактов процессорного времени. К счастью существует память с более низким временем доступа и работающая на той же частоте, что и процессор. Объем ее достаточно скромен и составляет порядка 16-128 Кб. Данная память получила название «сверхоперативной» или КЭШ (cache). Ее основная задача состоит в том, чтобы хранить те данные, с которыми оперирует процессор в данный момент.
Копирование данных из КЭШа в ОЗУ и обратно происходит пакетами, размером в 32-128 байт, называемым кэш-линией. Т. е. при чтении любой ячейки из памяти, происходит чтение и копирование в кэш целой КЭШ-линии. После чего, если следующая затребованная ячейка оказывается в этой же КЭШ-линии, процессор берет ее уже из КЭШа. Доступ к данным, находящимся в КЭШе происходит на 1-2 порядка быстрее. Поэтому наиболее выгодно обращаться к ячейкам в таком порядке, чтобы они все были в одной и той же КЭШ-линии. Заметим, что при полностью заполненном КЭШе происходит замещение КЭШ-линии на новую. Существуют различные алгоритмы выбора замещаемой КЭШ-линии, однако в нашем случае это не важно. Важно то, что мы должны свести к минимуму операции замещения КЭШ-линий.
В предложенном программном комплексе CONDUCT (профессора С. Патанкара) автор предлагает размещать коэффициенты дискретного аналога в отдельные массивы. Таким образом при решении системы уравнений мы обращаемся к ячейкам памяти, находящимся в разных массивах, и как следствие, не могущих находится рядом друг с другом. В предложенной реализации используется восемь массивов коэффициентов. И ко всем им мы обращаемся одновременно, что, конечно же, приводит к постоянному замещению КЭШ-линий разных массивов. Это связано с тем, что для увеличения скорости работы поделен на несколько банков (чаще всего на 4), состоящих из нескольких КЭШ-линий. Количество банков определяет ассоциативность КЭШа. И в каждом банке каждая строка закреплена за определенными адресами ОЗУ, кратными количеству КЭШ-линий в банке. Т. е. если мы имеем 4 банка по 64 КЭШ-линии размером 64 байта (полный объем равен 4*64*64 = 16 кб), то каждому блоку в 64 байта ОЗУ могут соответствовать 4 КЭШ-линии (по одной из каждого банка), а каждая N-ая КЭШ-линия КЭШа соответствует каждому N-ому блоку в 64 байт ОЗУ.
Как легко убедиться, если запрашиваемые ячейки будут находиться в 64-байтных блоках ОЗУ с кратными номерами. (имеется в виду остаток от деления общего объема ОЗУ на размер КЭШ-банка) и их количество превысит величину ассоциативности КЭШа, то КЭШ-линии будут постоянно перезатираться новыми данными, что приведет к падению производительности.
Для исключения подобной ситуации нам необходимо расположить данные в памяти таким образом, чтобы работать с ячейками, находящимся в одной КЭШ-линии (в идеале, на практике – свести к минимуму одновременно затребованных КЭШ-линий).
Предлагается организовать один массив, элементом которого является структура из восьми коэффициентов, ранее располагавшихся в совершенно разных массивах.
С помощью такой организации данных нам понадобится одновременно запросить максимум 4 КЭШ-линии, а чаще всего только 3, т. к. коэффициенты точек E, P и W располагаются в ОЗУ рядом и будут лежать в одной КЭШ-линии (или в двух соседних), еще две КЭШ-линии потребуются для коэффициентов точек S и N.
Был проведен анализ «странного» поведения первоначальной версии программного комплекса CONDUCT (рис. 1).
На рисунке отчетливо видны 10 пиков, которые указывают на двукратноеувеличение времени счета, связанного именно с обсуждаемой проблемой. Это как раз те «критические» случаи, когда КЭШ работал в холостую, постоянно перезатирая одни и те же КЭШ-линии.
Так же в CONDUCT’е использовались массивы с однобайтовыми элементами, что приводило к снижению общей производительности. Связано это с архитектурными особенностями микропроцессоров семейства x86, для которых чтение одного байта занимает больше времени чем четырех, т. к. в любом случае считываются 4 байта, выровненных на 4 байтовую границу. И уже после этого тратится несколько тактов процессорного времени на «выборку» нужного байта и помещения его в регистр. Поэтому выгоднее привести все однобайтовые массивы к четырехбайтовым. Благо в программе их нашлось порядка 5 штук, и они были все одномерными, что не сильно увеличило объем потребляемой памяти.
После осуществления всех вышеперечисленных оптимизаций мы получили ускорение порядка 15%-20% (рис. 2) и избавились от «аномально» высоких пиков в графике временных затрат! (рис. 1)
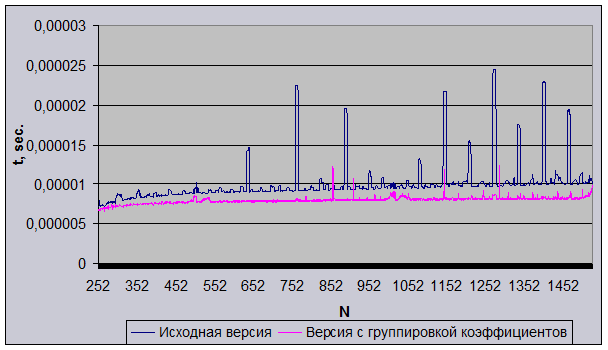
Рис. 1. Время выполнения расчета одной точки при различных размерностях массива NxN.
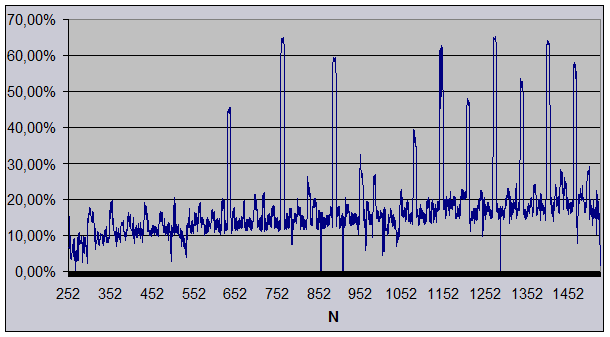
Рис. 2. Ускорение вычислений при различных размерностях массива NxN.
Литература:
1. Техника оптимизации программ. Эффективное использование памяти. - СПб.: БХВ-Петербург, 2003. - 464 с.: ил.
2. Архитектура компьютера. - СПб.: Питер, 2003. - 698 с.: ил.
3. , Молчанов программное обеспечение. - СПб.: Питер, 2003. - 736 с.: ил.
4. Язык программирования С++. Специальное издание. Пер. с англ. - М.: ООО "Бином-Пресс", 2005. - 1104 с.: ил.
