
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Затем инженер по знаниям на основании своей модели знаний М2 и информации, почерпнутой из текста Т, интерпретирует знания эксперта. На процесс понимания (интерпретации) I и на модель М2 влияют следующие компоненты: М2 = [(a, b, g, d, q)', v, e, j], где (a, b, g, d, q)' — экстракт компонентов, почерпнутый из текста Т; v — предварительные знания аналитика о предметной области; e — общенаучная эрудиция инженера по знаниям; j — личный опыт аналитика.
Схема процесса извлечения знаний из текста показывает, что смысл Мь заложенный автором книги, отличается от смысла М2, который постигает читатель (инженер по знаниям).
Простейший алгоритм извлечения знаний из текстов включает следующие шаги:
1. Составить «базовый» список литературы для ознакомления с предметной областью.
2. Выбрать текст для извлечения знаний.
3. Беглое знакомство с текстом. Провести консультации со специалистами для определения значений незнакомых слов.
4. Сформировать первую гипотезу о макроструктуре текста.
5. Внимательно прочитать текст и выписать ключевые слова и выражения, определив тем самым «смысловые вехи».
6. Определить связи между ключевыми словами, разработать макроструктуры текста в форме графа или реферата.
7. Сформировать новое представление знаний на основании макроструктуры текста.
5. Выявление «скрытых» структур знаний
Скрытые (имплицитные) знания служат основой интуитивного мышления. Интуиция позволяет человеку быстро принимать правильные решения в сложных ситуациях при недостаточной информации.
Психосемантика позволяет исследовать структуры сознания через моделирование индивидуальной системы знаний человека и выявлять элементы знаний, которые могут им не осознаваться (латентные, скрытые, имплицитные).
Основным методом психосемантики является построение субъективных семантических пространств, для чего, как правило, применяются статистические процедуры, а именно: многомерное шкалирование, репертуарные решетки, факторный и кластерный анализ. Эти методы позволяют сгруппировать отдельные описательные признаки в более емкие категории-факторы. Алгоритм построения семантического пространства включает три главных этапа:
1. Выбор и применение метода оценки семантического сходства признаков, предъявляемых испытуемому.
2. Построение структуры семантического пространства на основании математического анализа полученной матрицы сходства. При этом происходит уменьшение числа исследуемых понятий за счет обобщения.
3. Идентификация и интерпретация выделенных факторных структур, кластеров, групп объектов, осей и т. д.
Методы многомерного шкалирования основаны на статистических методах обработки экспертных оценок сходства между анализируемыми объектами, которые выбираются из определенной шкалы. Результаты обработки представляются в виде точек некоторого координатного пространства. Шкалированием называют поиск подпространства, для которого величина |Dm – Dn| имеет минимальное значение. Здесь Dm, Dn - матрицы расстояний между объектами (признаками) в исходном пространстве Dm и в искомом подпространстве Dn, m и n - размерности соответствующих пространств. Значения расстояний в матрицах D могут выбираться экспертом из предложенной шкалы либо вычисляться по совокупности признаков, описывающих объект. Во втором случае расстояния можно вычислить разными способами. Одной из самых популярных метрик является евклидово расстояние.
В шкалировании отыскиваются не новые признаки, а новые пространства, поэтому его результаты следует интерпретировать как восстановленную структуру расположения точек.
Метафорический подход. Он ориентирован на выявление скрытых составляющих практического опыта эксперта и основан на сравнении объектов предметной области с абстрактными объектами из мира метафор, в результате чего можно выявить новые свойства анализируемых объектов и определить отношение эксперта к ним.
Метод репертуарных решеток. Репертуарная решетка представляет собой матрицу, которая заполняется экспертом. Столбцам матрицы соответствуют определенные группы объектов (элементов). Строки матрицы соответствуют конструктам, которые представляют собой биполярные признаки, параметры, шкалы, отношения или способы поведения. Иными словами, конструкты — это признаки, которые могут использоваться для обобщения и разделения объектов на классы.
Конструкты могут быть заданы аналитиком либо подбираются самим экспертом. Примерами конструктов могут быть «умный — глупый», «мужской — женский», «хороший — плохой».
Слово репертуарная означает, что анализируемые объекты выбираются по специальным правилам, так, чтобы они были связаны определенным контекстом аналогично репертуару ролей в пьесе.
Для выявления конструктов используются: последовательный метод, а также методы минимального контекста, самоидентификации и ролевой персонификации. В соответствии с методом минимального контекста эксперту предъявляются произвольные «тройки» объектов и предлагается определить свойства, отличающие один объект от двух других. В результате определяются не только значения характеристик, но и сами характеристики.
Решетка формируется следующим образом. По одной из ее осей располагаются значимые конкретные объекты, а по другой – разряды (типы, роли), к которым они относятся. Распределив объекты по типам, эксперт заполняет первый ряд матрицы под колонками, обозначив три объекта кружочками. При этом он должен подобрать характеристику, которая обеспечивает сходство двух объектов и отличает их от третьего. Кружочки, соответствующие сходным объектам, перечеркиваются. В столбец с именем «полюс конструкта» записывается наименование признака, обеспечивающего сходство двух объектов, в столбец «противоположный полюс» — имя признака, отличающего третий объект от двух сходных. Затем проводится анализ оставшихся в первом ряду объектов по выделенному положительному конструкту и галочками отмечаются объекты, обладающие этим свойством. Традиционная решетка должна быть квадратной, т. е. в матрице заполняют число строк, равное числу объектов (типов). В общем случае это условие не является обязательным.
Самым распространенным и простым методом анализа репертуарной решетки является кластерный анализ. Иерархическая кластеризация осуществляется на основе выбора элементов матриц, имеющих наибольшее число связей. Кроме того, конструкты могут быть представлены как точки многомерного пространства, плоскости которого определяются числом связанных с конструктами элементов. Факторный анализ пространства конструктов позволяет судить об их значимости, а корреляционный анализ — выявлять значимые связи между ними.
6. Индуктивное обучение
Выводы по индукции позволяют на основе обобщения частных фактов получить общие (для некоторого множества объектов) закономерности. В процессе индуктивного обучения формируются новые правила, теории и структуры. Индуктивные выводы возможны в том случае, когда представление результата частично определяется на основе входной информации. Диапазон представлений, порождаемых в процессе индуктивного вывода, шире, чем диапазон, заданный изначально.
Пусть Р - множество известных фактов, имеющихся в БЗ, а H — некоторая гипотеза (направленная на обобщение этих фактов). Если Р выводится из H, то будем считать гипотезу H истинной. Это можно записать в виде
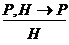 .
.
Выдвижение гипотезы H зачастую состоит в замене некоторых однотипных констант в однотипных умозаключениях на обобщающую переменную и во введения квантора всеобщности по этой переменной в формулировке гипотезы H. Это позволяет расширить множество P. За счет расширения множества Р появляется возможность вывести новые заключения. Однако при расширении класса объектов всегда есть возможность совершить ошибку. Если возникает такая ситуация, то это означает, что обобщение Н является слишком широким в данном случае. Попытаемся сузить его, ограничив количество объектов. Пусть ![]() , что можно интерпретировать фразой «гипотеза Н истинна, если подмножество Р2 множества Р можно вывести из гипотезы Н и оставшегося подмножества Р1». При необходимости диапазон объектов подстановки в гипотезу H необходимо сделать еще уже и т. д., пока не будем получать правдоподобные выводы.
, что можно интерпретировать фразой «гипотеза Н истинна, если подмножество Р2 множества Р можно вывести из гипотезы Н и оставшегося подмножества Р1». При необходимости диапазон объектов подстановки в гипотезу H необходимо сделать еще уже и т. д., пока не будем получать правдоподобные выводы.
Традиционный метод обобщения состоит в выборе гипотезы минимального обобщения среди большого числа возможных гипотез, в которых объекты из заданного множества фактов (Р2) заменяются переменной и которые расширяют диапазон применения исходных логических формул. Для того чтобы формализовать процесс минимального обобщения, необходимо иметь правила, с помощью которых можно выбрать ту или иную гипотезу.
Если такие правила сформулированы в системе, то процесс замены констант на переменные не представляет особых трудностей. Удаление из БЗ фактов, противоречащих установленным правилам, обычно не вызывает осложнений. Трудной проблемой является создание новых предикатов, поскольку эта операция не-формализуема.
Таким образом, индуктивный вывод — это построение объясняющего правила на основе заданных данных. В системах с индуктивными выводами на каждом шаге необходимо объяснять все данные, полученные к заданному моменту времени. Данные, полученные на последующих шагах, могут не удовлетворять ранее полученным объяснениям. В этом случае следует корректировать полученные ранее объясняющие правила (гипотезы). Следовательно, процесс индуктивного обучения может оказаться весьма длительным.
Для реализации индуктивного вывода необходимо:
• сформулировать множество правил — объектов вывода;
• выбрать формальный метод представления правил;
• определить способ получения информации извне (показ примеров);
• задать формальный метод вывода;
• сформулировать критерий правильности вывода.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
