

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
n Например, для записи отсутствия число дней отсутствия вычисляется на основании периода отсутствия.
n В ракурсах образуются новые неполные периоды, но при этом не происходит изменения данных инфо-типа. Для временных инфо-типов это привело бы к неправильным результатам, поскольку данные зависят от периода действия.
n Поэтому для временных инфо-типов оператор PROVIDE не используется.
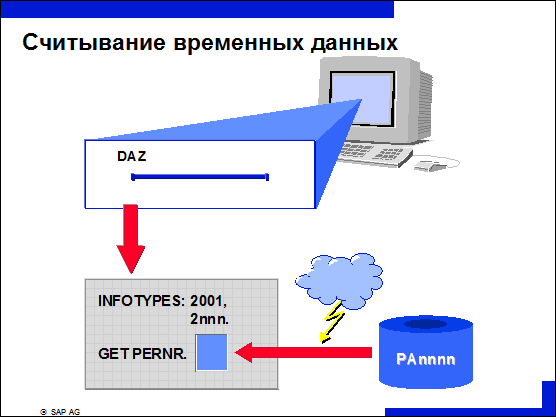
n Один из принципов логической базы данных состоит в том, что в момент GET PERNR считываются все записи инфо-типов между самой ранней и самой поздней датой системы, независимо от периода выбора данных.
n В связи с большим количеством временных записей это может привести к проблемам оперативной памяти и снизить производительность системы.
n В особенности это касается систем положительного учета времени. При их использовании оперативная память была бы быстро перегружена записями инфо-типов.

n Чтобы контролировать по времени процесс считывания временных инфо-типов, при определении эти инфо-типы снабжаются дополнением MODE N. Это приводит к тому, что в момент GET PERNR таблицы инфо-типов не заполняются.
n Таблицы временных инфо-типов впоследствии заполняются с помощью макроса RP-READ-ALL-TIME-ITY, но только в заданном интервале времени.
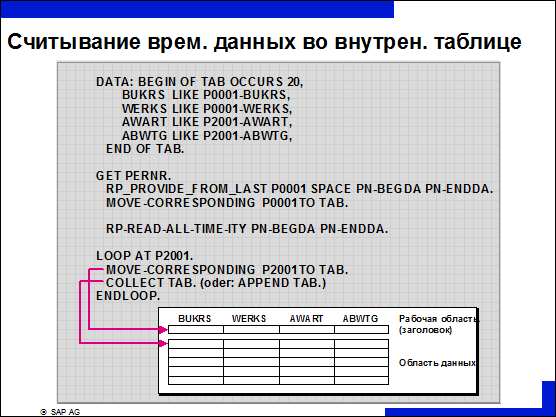
n Для анализа данных об отсутствии по организационным единицам целесообразно использовать внутреннюю таблицу.
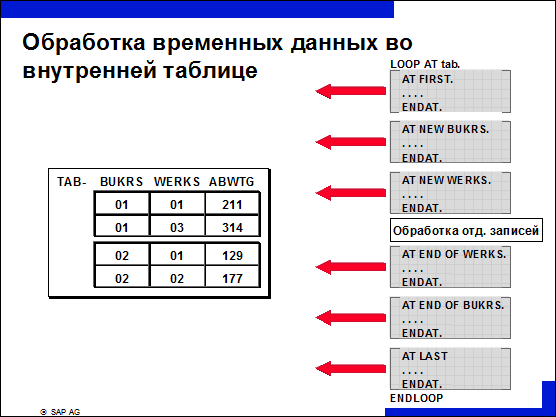
n Самая простая форма обработки внутренней таблицы - это использование оператора LOOP/ENDLOOP по аналогии с оператором SQL-SELECT для таблиц баз данных.
n При обработке внутренней таблице с уровнями иерархии групп можно обработать как начало, так и конец группы. Суммирование (SUM) может быть выполнено в начале или в конце группы.
n При работе с внутренними таблицами необходимо учитывать, что сначала производится обработка начала группы, затем – отдельных записей, и, наконец, конца группы.




n В некоторых масках ввода инфо-типа данные вводятся в табличной форме.
n Например, для количества отпускных дней можно определить до шести различных видов отпусков с полагающимися для них отпускными днями. Столбцы Затребовано и Остаток отпуска ведутся автоматически.
n В основополагающей структуре инфо-типа названы и определены все поля этой табличной структуры.
n Повторяющиеся группы полей можно распознать по текущему номеру в конце имени поля (Pnnnn-XYZ-nn).
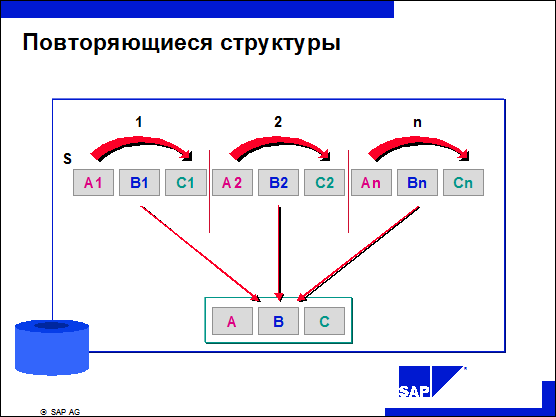
n Данные, которые вводятся в маске инфо-типа в табличной форме, в базе данных хранятся в линейной структуре.
n В базу данных строки таблицы закладываются последовательно одна за другой. Для однозначности имена полей содержат номера строк.
n Для анализа такой повторяющейся структуры необходимо определить начальную точку S, инкремент, количество строк таблицы n и рабочую область, содержащую определение поля строки таблицы.

n Рабочая область - это строка полей.
n По структуре она идентична строке соответствующей таблицы инфо-типа.

n Макрос загружает запись инфо-типа полагающихся отпускных дней c повторяющейся структурой в рабочую область P0005.
n Цикл DO сегментирует повторяющуюся структуру и представляет ее в рабочей области VACATION в виде блоков.
n FROM <имя поля> определяет начальную точку в оперативной памяти.
n NEXT <имя поля> определяет инкремент для следующей точки.
n Aльтернативный синтаксис: WHILE... (условие) VARY VACATION
FROM P0005-UAR01
NEXT P0005-UAR02.
ENDWHILE.
n Если неупакованные данные включить в поля рабочей области, определенные как упакованные, то происходит прерывание. Это может случиться, если число прогонов цикла больше, чем число повторяющихся строк, или если неправильно определен инкремент.

n Этот функциональный модуль обеспечивает представление одноуровневых списков. При этом для представления можно на выбор использовать стандартную презентацию GUI или экранную таблицу. Переходить от одной формы представления к другой можно с помощью кнопок экрана. Если в качестве фронтального компьютера используется ПК с Windows, то из экранной таблицы можно вызвать перенос данных в этот ПК. Число столбцов не должно превышать 20.
n Кроме этого, в представлении экранной таблицы доступны следующие опции:
Ÿ сортировка по восходящей (по любому количеству столбцов)/сортировка по нисходящей;
Ÿ выключение или показ строк/столбцов, изменение ширины столбцов;
Ÿ печать;
Ÿ поиск;
Ÿ перенос данных в MS Excel и представление данных в MS Excel;
Ÿ вызов MS Word, при этом данные доступны в качестве полей стандартных писем;
Ÿ перенос данных в ПК в различных форматах;
Ÿ 4 динамические кнопки в строке меню (интерактивное программирование списков);
Ÿ отправка списков по почте;
Ÿ просмотр и печать журнала выбора.
n В особых ситуациях (EXCEPTIONS) значение SY-SUBRC устанавливается на определенную величину. Например, если таблица данных, переданная в функциональный модуль, пустая, то значение SY-SUBRC будет равно 2.
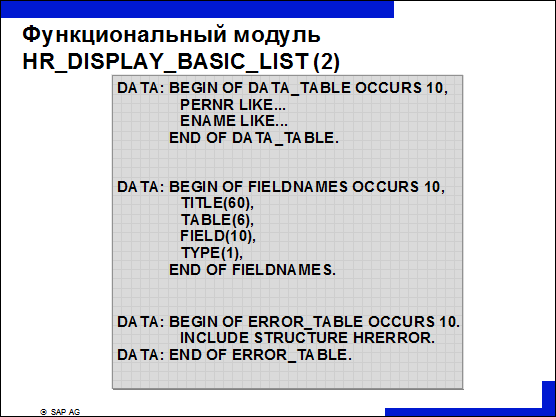
n Таблица DATA_TABLE содержит те данные, которые должны быть представлены. Для данного функционального модуля эта таблица не должна иметь никакой специальной структуры. Тем не менее, следует иметь в виду, что длина отдельных полей не должна превышать 60 знаков, и что эта таблица может содержать максимум 20 столбцов.
n Если используется внутренняя таблица, то следует самостоятельно заполнить таблицу FIELDNAMES.
n Сообщение об ошибках собираются в таблице ERROR_TABLE и передаются в функциональный модуль.

n Первая запись в таблице FIELDNAMES соответствует заголовку первого столбца, вторая запись – заголовку второго столбца и так далее.
n Если Вы хотите иметь в экранной таблице возможность обращения к справке F1, то поле TABLE должно содержать название таблицы словаря, а поле FIELD – имя поля. После этого в поле TITLE вносится заголовок из ABAP-словаря. В поле TYPE следует ввести ‚X‘, если речь идет о поле ключа.

n При каждой возникшей ошибке в таблице ошибок делается запись. При этом используются следующие параметры:
Ÿ PERNR: табельный номер;
Ÿ ARBGB: класс сообщений в таблице T100;
Ÿ MSGTY: тип сообщения (I, W, E и т. д.);
Ÿ MSGNO: номер сообщения.





n Таблицы базы данных PAnnnn содержат все данные персонала, упорядоченные в соответствии с инфо-типами. Они составляют базис данных для масок ввода инфо-типов и анализируются с помощью логической базы данных HR.
n Таблицы базы данных PCL1, PCL2 и PCL3 составляют либо базис данных для последующих программ, таких как расчеты или аналитические отчеты, либо базис данных отдельных областей НR, таких как командировочные расходы и набор новых сотрудников.
n Таблицы базы данных PCLn относятся к типу таблиц импорта/экспорта.
n Таблицы базы данных HR/Планирование и развитие персонала называются HRPnnnn.

n Таблицы БД, относящиеся к типу PCLn, делятся на подобласти (так называемые кластеры данных).
n Кластеры данных обозначаются двузначными идентификаторами.
n Каждая область HR имеет свой cобственный кластер.
n Для каждой области определен свой собственный ключ данных.

n Таблица базы данных PCL1 содержит, помимо прочего, следующие области данных:
B1 временные события/сбор производственных данных (СПД)
G1 групповая сдельная зарплата
L1 индивидуальная сдельная зарплата
PC личный календарь
TE командировочные расходы/результаты расчета
TS командировочные расходы/основные данные (только до версии 3.1)
TX тексты к инфо-типам
ZI интерфейс СПД -> Учет затрат/Управление материальными потоками


|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
