

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
n Таблица БД PCL2 содержит следующие области данных:
B2 результаты расчета времени
CU кластерный каталог CDM
PS сгенерированная схема
PT тексты к сгенерированной схеме
RX результаты расчета зарплаты (международного)
xy результаты расчета зарплаты (для отдельной страны), причем xy
представляет из себя идентификатор отношений, который состоит
либо из Rn (n = код страны в HR), либо из кода ISO согласно таблице T500L
ZL личный график рабочего времени

n Для управления таблицами импорта/экспорта PCLn используются ABAP-команды IMPORT и EXPORT.
n С помощью этих команд можно вводить в базу данных любые объекты данных, то есть поля, строки полей или внутренние таблицы, а также считывать их из базы данных.
n Для считывания и записи данных используется однозначный (уникальный) ключ.
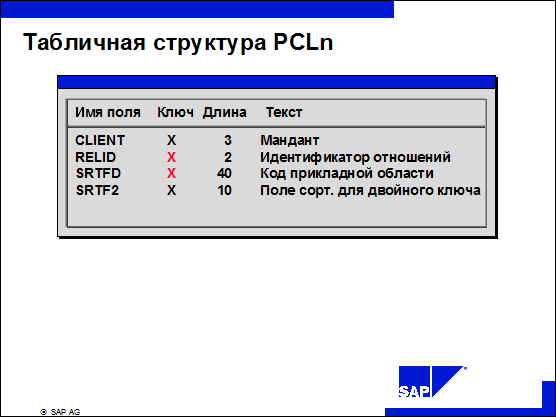
n Структура таблиц базы данных PCLn обеспечивает основу для отдельных подобластей.
n Каждой подобласти нужно присвоить двузначное имя кластера или идентификатор отношений.
n Дополнительно необходимо определить структуру ключа. Для этого используется поле SRTFD, длина которого 40 байт.
n При экспортировании записи в PCLn поле RELID заполняется идентификатором кластера, а поле SRTFD - значением ключа.

n Определения данных прикладной области записаны в отдельных программах, имена которых подчиняются твердому правилу.
n Они определены как INCLUDE-программы и названы RPCnxxy0; при этом действует следующее правило присвоения имен:
n = 1 для PCL1 или 2 для PCL2
xx = кластер, например RX
y = 0 для международных кластеров, или
y = код страны согласно T500L для отдельных стран.
n Структура ключа кластера записана в строке полей xy-KEY, причем первым компонентом является табельный номер.
n Объектам данных имена присваиваются отдельно по каждому кластеру.

n Определение кластера интегрировано с оператором INCLUDЕ.
n С помощью команды EXPORT один или несколько объектов данных с ключом xy-KEY записывается в кластер xy.
n При успешном экспорте код возврата будет равен 0.

n С помощью команды IMPORT из таблицы БД импорта/экспорта считываются объекты данных с заданными значениями ключа.
n При успешном считывании записи код возврата будет равен 0, в противном случае - 4.
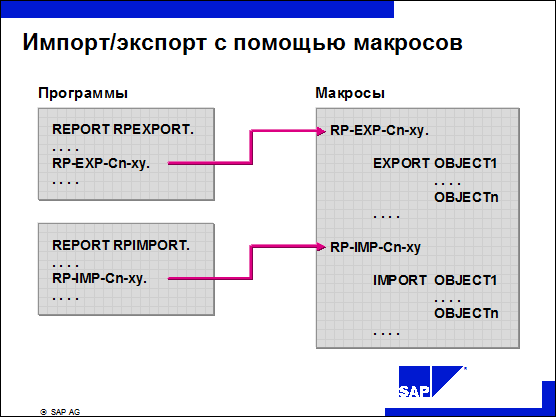
n Команды IMPORT/EXPORT определены как макросы, что дает возможность поддерживать согласованность импорта и экспорта данных.
n Это гарантирует, что все экспортированные объекты могут быть снова импортированы.
n Правило присвоения имен для макросов следующее: RP-EXP-Cn-xy и RP-IMP-Cn-xy, где n обозначает имя файла, xy – имя кластера.
n Эти макросы определены в Include RPCXRxy0 драйвера расчета посредством языкового элемента DEFINE.
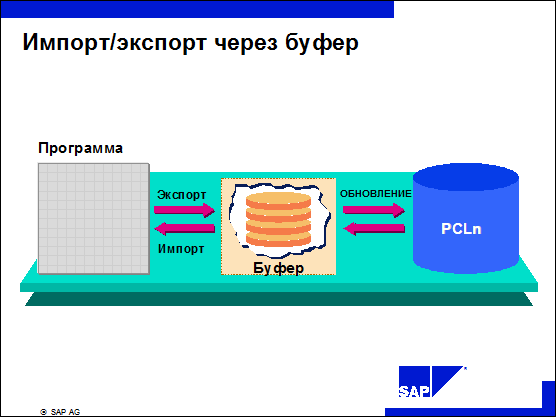
n Чтобы свести до минимума количество обращений к базе данных, импортируемые и экспортируемые данные накапливаются в буфере оперативной памяти.
n При успешном экспорте устанавливается код возврата RP-IMP-xy-SUBRC=0.
n При тестовом расчете база данных не обновляется. Поскольку результаты расчета предыдущего месяца являются основой для расчета результатов следующего месяца, при тестовом расчете на период в несколько месяцев результат реального расчета будет отличаться от тестового.
n Использование буфера обеспечивает простой доступ к требуемым результатам предыдущего месяца.
n Подпрограммы управления буфером выполняют две задачи:
Ÿ буферизация данных,
Ÿ проверка полномочий на кластер.
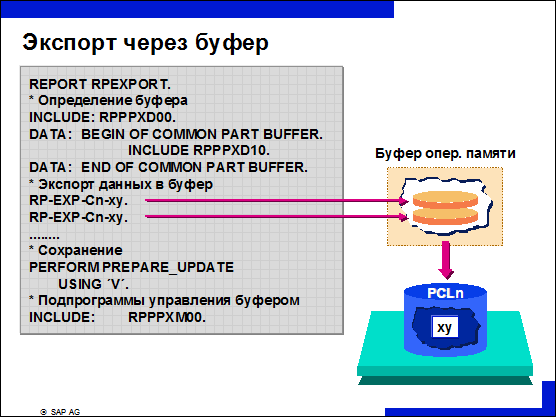
n При экспорте данных с помощью макросов данные записываются не напрямую в базу данных, а в буфер оперативной памяти. Эта переадресация данных осуществляется через параметр USING в операторе EXPORT, который вызывает подпрограмму управления буфером.
n Если экспорт проходит успешно, то устанавливается код возврата RP-IMP-xy-SUBRC = 0.
n В конце программы накопленные в буфере записи должны быть сохранены в базе данных PCLn.
n Для сохранения данных вызывается подпрограмма PREPARE_UPDATE с параметром USING V.
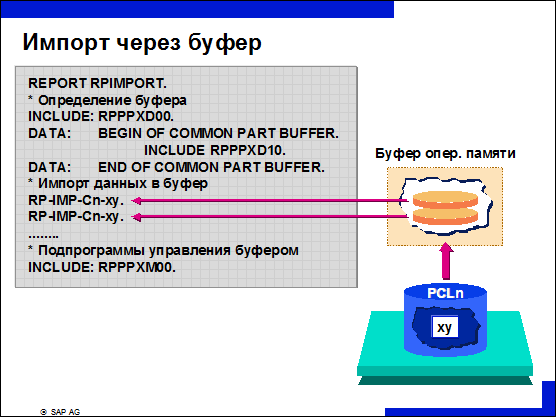
n Если данные импортируются с помощью макросов, то записи данных не считываются непосредственно из таблицы PCLn. Вместо этого производится проверка в каталоге буфера. При этом проверяется, есть ли уже в оперативной памяти запись с таким же ключом. Если такой записи там нет, то она считывается из таблицы PCLn в буфер, а оттуда она становится доступной для отчета.
n При успешном импорте устанавливается код возврата RP-IMP-xy-SUBRC = 0.
n Если данные считываются из буфера, то производится проверка полномочий на кластер. Стандартные программы импорта можно найти по правилу присвоения имен RPCLSTxy (xy = имя кластера).
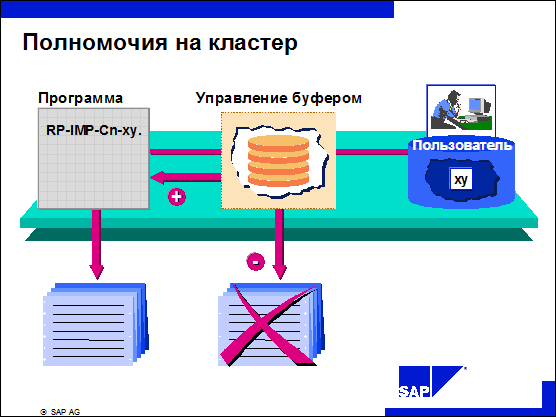
n Простой оператор EXPORT/IMPORT не выполняет проверку полномочий на кластеры.
n При экспорте/импорте данных через буфер подпрограмма управления буфером проверяет полномочия на кластеры.
n Полномочия на кластеры определяются в основной записи пользователя.
n В поле Уровень полномочий задается разрешенный вид доступа:
значение R разрешает считывание, U - считывание и запись, S - экспорт данных в буфер PCLx без изменения базы данных (моделирование расчета).
n В поле Идентификатор отношений перечисляются кластеры, на которые пользователь имеет полномочия.
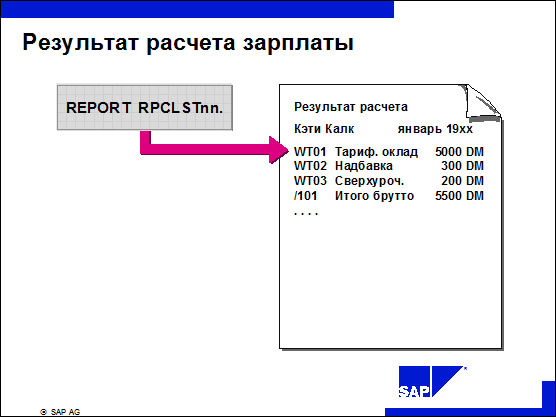
n Результаты расчета заработной платы можно просмотреть при помощи стандартных отчетов RPCLSTxy.
n Результаты расчета закладываются в базу данных в виде внутренних таблиц и строк полей.
n Каждый результат расчета имеет индикатор актуальности:
Ÿ A = актуальный результат
Ÿ P = предыдущий результат
Ÿ O = все остальные результаты.
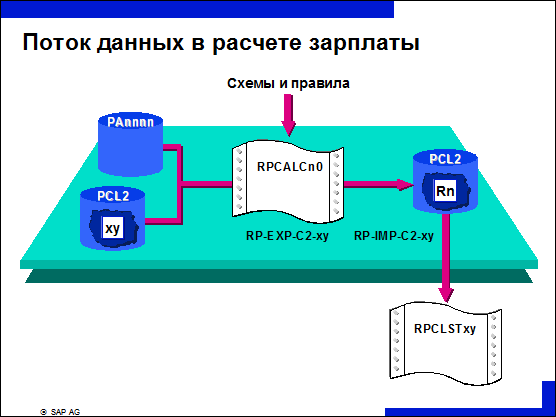
n На основании данных персонала и результатов последнего расчета драйвер расчета создает расчет за заданный период.
n Результат расчета записывается в кластере nn таблицы БД PCL2.
n Стандартные аналитические отчеты считывают результаты из кластера xy. Отчет RPCLSTxy выводит полный список результатов расчета, отчет RPCEDTn0 выводит отформатированный список результатов в форме расчетной ведомости (n = код страны в HR из таблицы T500L).
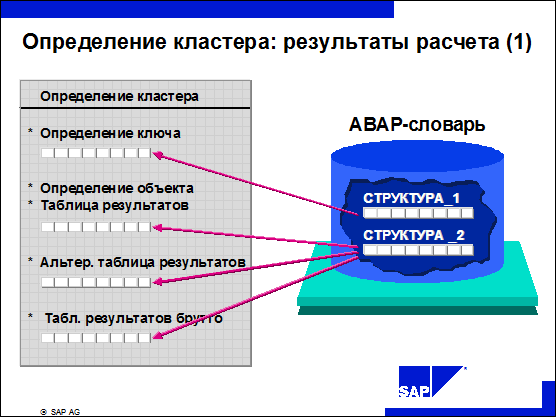
n Определение кластера результатов расчета подчиняется действующим правилам присвоения имен. Они записаны в INCLUDE-отчетах RPC2xyz0, где z - это код страны в HR.
n Ключ кластера находится в строке полей RX-KEY.
n Все поля ключа и объектов данных определены в структурах ABAP-словаря.
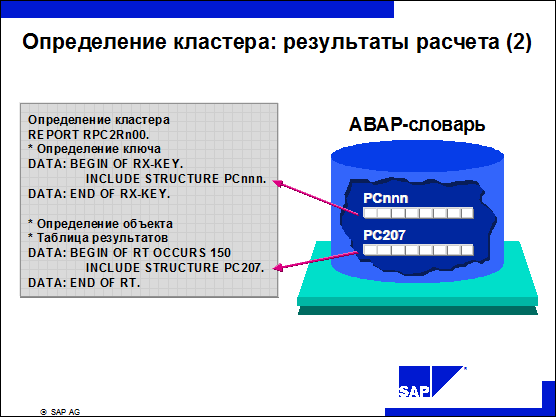
n Поля ключа и объектов определены в структурах ABAP-словаря. Благодаря этому их можно использовать многократно. В то же время это гарантирует их согласованность и непротиворечивость.
n Структуры для определения кластера подчиняются правилу присвоения имен PCnnn, где nnn - это любой буквенно-цифровой набор символов.
n Структура PC200 содержит определение ключа кластеров результатов, она состоит из двух полей: PERNR (табельный номер) и SEQNO (порядковый номер).
n Определения данных результатов международного расчета записаны в Include-отчетах RPC2RX00 и RPC2RXX0.

n Таблица RGDIR содержит каталог всех результатов расчета по одному сотруднику.
n Функциональный модуль CU_READ_RGDIR считывает таблицу RGDIR из кластера CU. Функциональному модулю передается тот табельный номер, для которого необходимо считать результаты расчета.

n Этот функциональный модуль заполняет таблицу EVPDIR (периоды анализа) данными результатов расчета, рассчитанными за выбранный период. В таблицу EVPDIR вставляются описательные данные текущего (A) и предыдущего (P) результатов.
n Параметр периода определяет временной интервал, в котором выполняется расчет для единицы расчета. Каждой единице расчета присваивается только один параметр периода. Для каждого параметра периода определяются соответствующие периоды расчета.
n В-период: период, в котором был создан результат расчета.
n Тип расчета: индикатор "Вид результата расчета” (согласно таблице T52BX)
Ÿ " " = регулярный результат расчета (результат расчета для периода расчета)
Ÿ "A" = расчет бонуса (передается дата бонуса)
Ÿ "B" = корректировочный расчет
Ÿ "C" = проверка вручную
n Идентификатор расчета: индикатор, предназначенный для различения нескольких особых расчетов, созданных в один день.
n Кроме этого, можно использовать следующие функциональные модули:
CD_READ_PREVIOUS (предоставляет для записи расчета соответствующую предыдущую запись);
CD_READ_PREVIOUS_ORIGINAL (предоставляет для результата исходного расчета предыдущий исходный результат).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
