
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
б) когда сопоставляются два эмпирических распределения, и количество разрядов признака равно 2, т. е. и количество строк k=2, и количество столбцов с=2, и ν=(k—l)*(c—1)=1.
Вариант "а": поправка на непрерывность при сопоставлении эмпирического распределения с равномерным. Это тот случай сопоставлений, когда мы, говоря простым языком, проверяем, поровну ли распределились частоты между двумя значениями признака.
Пример с поправкой на непрерывность.
В исследовании порогов социального атома[10] профессиональных психологов просили определить, с какой частотой встречаются в их записной книжке мужские и женские имена коллег-психологов. Попытаемся определить, отличается ли распределение, полученное по записной книжке женщины-психолога X, от равномерного распределения. Эмпирические частоты представлены в Табл. 4.9
Таблица 4.9
Эмпирические частоты встречаемости имен мужчин и женщин в записной книжке психолога X
![]()
Сформулируем гипотезы.
Н0: Распределение мужских и женских имён в записной книжке X не отличается от равномерного распределения.
H1: Распределение мужских и женских имен в записной книжке X отличается от равномерного распределения.
Количество наблюдений n=67; количество значений признака k=2. Рассчитаем теоретическую частоту:
Число степеней свободы ν=k -1=1.
Далее все расчеты производим по известному алгоритму, но с одним добавлением: перед возведением в квадрат разности частот мы должны уменьшить абсолютную величину этой разности на 0,5 (см. Табл. 4.10, четвертый столбец).
Таблица 4.10
Расчет критерия % при сопоставлении эмпирического распределения имен с теоретическим равномерным распределением
Разряды – принадлежность к тому или иному полу | Эмпирическая частота взгляда (fэj) | Теоретическая частота (fт) | (fэj-fт) | (fэj-fт-0,5) | (fэj-fт-0,5)2 | (fэj-fт-0,5)2/ fт | |
1 2 | Мужчины Женщины | 22 45 | 33,5 33,5 | -11,5 +11,5 | 11 11 | 121 121 | 3,61 3,61 |
Суммы | 67 | 67 | 0 | 7,22 | |||
Для ν=l определяем по Табл. IX Приложения 1 критические значения:
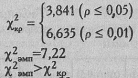
Ответ: Н0 отклоняется, принимается Н1. Распределение мужских и женских имен в записной книжке психолога X отличается от равномерного распределения (р<0,01).
Вариант "б": поправка на непрерывность при сопоставлении двух эмпирических распределений
Попытаемся определить, различаются ли распределения мужских и женских имен у психолога X и психолога С, тоже женщины. Эмпирические частоты приведены в Табл. 4.11.
Таблица 4.11
Эмпирические частоты встречаемости имен мужчин и женщин в записных книжках психолога X. и психолога С.
Мужчин | Женщин | Всего человек | |
22 А 59 В | 45 Б 109 Г | 67 168 | |
Суммы | 81 | 154 | 235 |
Сформулируем гипотезы. H0: Распределения мужских и женских имен в двух записных книжках
не различаются.
H1: Распределения мужских и женских имен в двух записных книжках различаются между собой. Теоретические частоты рассчитываем по уже известной формуле:
![]()
А именно, для разных ячеек таблицы эмпирических частот,
fА теор=67*81/235=23,09
fб теор =67*154/235=43.91
fВ теор=168*81/235=57,91
fГ теор=168*154/235=110,09
Число степеней свободы ν=(k—1)*(с—1)=1 Все дальнейшие расчеты проводим по алгоритму (Табл. 4.12)
Таблица 4.12
Расчет критерия при сопоставлении двух эмпирических распределений мужских и женских имен
Ячейки таблицы эмпирических частот | Эмпирическая частота взгляда (fэj) | Теоретическая частота (fт) | (fэj-fт) | (fэj-fт-0,5) | (fэj-fт-0,5)2 | (fэj-fт-0,5)2/ fт | |
1 2 3 4 | А Б В Г | 22 45 59 109 | 23,09 43,91 57,91 110,09 | -1,09 +1,09 +1,09 -1,09 | 0,59 0,59 0,59 0,59 | 0,35 0,35 0,35 0,35 | 0,015 0,008 0,006 0,003 |
Суммы | 235 | 235,00 | 0 | 0,032 | |||
Критические значения χ2 при ν=l нам известны по предыдущему примеру:
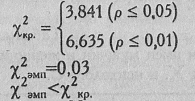
Ответ: Н0 принимается. Распределения мужских и женских имен в записных книжка двух психологов совпадают.
Поправки на непрерывность и всех остальных подсчетов можно избежать, если использовать по отношению к подобного рода задачам метод φ* Фишера (см. параграф 5.4).
Особый случай 2: укрупнение разрядов признака, который варьирует в широком диапазоне значений
Если признак варьирует в широком диапазоне значений, например, от 10 до 140 сек или от 0 до 100 мм и т. п., то вряд ли мы сможем принимать каждое значение признака за самостоятельный разряд:
10 сек, И сек, 12 сек и т. д. до 100 сек. Одно из ограничений критерия χ2 состоит в том, что теоретически на каждый разряд должно приходиться не менее 5 наблюдений: fтеор>5. Если у признака 90 значений, и каждое из них принимается за самостоятельный разряд, то необходимо иметь не менее 5*90=450 наблюдений! Если же наблюдений меньше 450, то придется укрупнять разряды до тех пор, пока на каждый разряд не будет приходиться по 5 наблюдений. Это не означает, что в ка-ждом разряде реально должно быть 5 наблюдений; это означает, что теоретически на каждый разряд их приходится по 5. Рассмотрим это на примере.
Пример с укрупнением разрядов признака
Тест Мюнстерберга для измерения избирательности перцептивного внимания в адаптированном варианте (1976) предъявлялся студентам факультета психологии Ленинградского университета (n1=156) и артистам балета Мариинского театра (n2=85). Материал методики состоит из бланка с набором букв русского алфавита, в случайном порядке перемежающихся. Среди этого фона скрыто 24 слова разной степени сложности: "факт", "хоккей", "любовь", "конкурс", "психиатрия" и т. п. Задача испытуемого возможно быстрее отыскать их и подчеркнуть (, 1976, с. 124). Совпадают ли распределения количества ошибок (пропусков слов) в двух выборках (Табл. 4.13)?
Таблица 4.13
Эмпирические частоты пропуска слов в тесте Мюнстерберга в двух выборках испытуемых (по данным , , 1973)
разряды | Эмпирические частоты пропуска слов | ||
В группе студентов (n1=156) | В группе артистов балета (n2=85) | Суммы | |
I. 0 пропусков II. 1 пропуск III. 2 пропуска IV. 3 пропуска V. 4 пропуска VI. 5 пропусков VII. 6 пропусков VIII. 7 пропусков IX. 8 пропусков X. 9 пропусков | 93 27 11 15 5 3 2 0 0 0 | 22 20 16 4 3 11 3 3 2 1 | 115 47 27 19 8 14 5 3 2 1 |
Суммы | 156 | 85 | 241 |
Сформулируем гипотезы.
Н0: Распределения ошибок (пропусков слов) в выборках студентов и артистов балета не различаются между собой.
H1: Распределения ошибок (пропусков слов) в выборках студентов и артистов балета различаются между собой.
Прежде чем перейти к расчету теоретических частот, обратим внимание на последние 4 значения признака, от 6 пропусков и ниже. Очевидно, что fтеор для любой из ячеек последних 4 строк таблицы будет меньше 5. Например, для ячейки, отмеченной кружком:
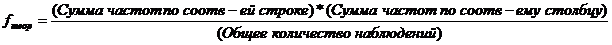 fтеор=5*85/241=1,763
fтеор=5*85/241=1,763
Полученная теоретическая частота меньше 5.
Для того, чтобы решить, какие разряды нам следует укрупнить, чтобы fтеор была не меньше 5, выведем формулу расчета минимальной суммы частот по строке по формуле:
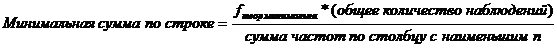
В данном случае столбцом с наименьшим количеством наблюдений является столбец, относящийся к выборке артистов балета (n=85). Определим минимальную сумму частот для каждой строки: Минимальная сумма по строке =5*241/85=14,16 Мы видим, что для получения такой суммы нам недостаточно объединения последних 4 строк Табл. 4.13, так как сумма частот по ним меньше 14 (5+3+2+1=11), а нам необходима сумма частот, превышающая 14. Следовательно, придется объединять в один разряд пять нижних строк Табл. 4.13: теперь любое количество пропусков от 5 до 9 будет составлять один разряд.
Однако это еще не все. Мы видим, далее, что в строке "4 пропуска" сумма составляет всего 8. Значит, ее необходимо объединить со следующей строкой. Теперь и 3, и 4 пропуска будут входить в один разряд. Все остальные суммы по строкам больше 14, поэтому мы не нуждаемся в дальнейшем укрупнении разрядов.
Эмпирические частоты по укрупненным разрядам представлены в Табл. 4.14.
Таблица 4.14

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
