

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Р={S®AB, A®x, A®y, B®w, B®z}.
Эти правила означают, что S можно заменить на последовательность нетерминальных символов AB. A®x, A® y означает, что А можно заменить на x или на y и т. д. Осуществляя эти замены, получаем цепочки w из терминальных символов, составляющих формальный язык L(G).
L(G)={xw, yw, xz, yz}.
Только эти четыре цепочки (слова) и составляют язык, описываемый заданной грамматикой G.
2. 6 Расширенные грамматики
Существуют т. н. расширенные грамматики. Они порождают те же языки, что и рассмотренные выше грамматики, но являются более наглядными.
Расширенные грамматики задаются парами
Ai ® ri,
где Ai ЄN – i-й нетерминальный символ.
ri – i-е регулярное выражение в алфавите NUT.
Нетерминальный символ первой пары является ГЛАВНЫМ (стартовым)для вывода цепочек.
Например, расширенная грамматика, эквивалентная описанной в примере выше, имеет вид:
S®AB ,
A®x|y,
B®w|z.
Напомним, что вертикальная черта читается как “или”. То есть А может быть заменена на x или y, а В – на w или z.
2. 7 Задачи анализа
Даны цепочка символов (слов) и грамматика. Нужно узнать, принадлежит ли это слово формальному языку, определяемому этой грамматикой. Для решения этой задачи обычно используются алгоритмы анализа слева направо, которые просматривают в этом направлении символы цепочки.
Например, цепочка [[x]] принадлежит языку L(G2), описанному грамматикой G2.
G2=(T2, N2, P2, A), где
T2 = {х, +, [, ]},
N2 ={А, В},
P2 = {А®х, А®[В], В®А, В®В+А}.
Действительно, заданную цепочку можно получить, применив последовательно по одному из правил вывода, заданному в Р2.
АÞ [В]Þ [А]Þ [[В]]Þ [[А]]Þ [[х]].
Следовательно, цепочка [[х]] принадлежит формальному языку L(G2).
Различают две стратегии: стратегия анализа сверху вниз и снизу вверх. При анализе сверху вниз для построения вывода заданной цепочки начинают с ГЛАВНОГО нетерминального символа и выбирают правила из заданного множества так, чтобы прийти к заданной цепочке w.
В примере [[х]] в грамматике G2 главных нетерминальных символов А среди заданного множества правил вывода для А есть два: А ® х и А®[В]. Первое из них не дает возможности вывести [[х]]. Берем А ® [В], то есть А заменяем на [В]. Теперь нужно выбирать из двух правил вывода для В.
В ® А и В ® В+А.
Выбираем В ® А, заменяем в [В] В на А и получаем [А]. Вновь из двух правил вывода для А выбираем А ® [В]. Заменяем в [А] А на [В]. Получаем [[В]]. Вновь из двух правил для вывода В выбираем В® А и заменяем в [[В]] В на А. Получим [[А]]. И, наконец, из двух правил вывода для А выбираем А®х. Заменяем в [[А]] А на х и получаем требуемую цепочку [[х]]. Таким образом, доказано, что заданная цепочка действительно принадлежит языку, определяемому грамматикой G2.
При анализе сверху вниз основная проблема в определении необходимого правила V ® ai для построения следующего шага вывода цепочки w, когда в найденной части А Þ* nVb известны левый нетерминальный символ V и n правил вывода V ® a1 , V ®a2, …V ® an с левой частью V. Решение этой проблемы, в частности, возможно с помощью алгоритма лексического <А(1) – анализа, который определяет необходимое правило V ® ai в зависимости от первого, еще не распознанного символа х в цепочке w.
Для многих грамматик LA(1) – анализ. Осуществляется LA(1) – анализ путем создания для нетерминалов процедур анализа. Эти процедуры, как правило, оказываются взаимно рекурсивными и часто неэффективными.
Для многих грамматик LA(1) – анализ в таком виде не используется. Тогда приходят к расширенным грамматикам или к синтаксическим диаграммам (графикам).
2. 8 Синтаксические диаграммы
Это ориентированный граф с двумя фиксированными вершинами: входной, из которой дуги только выходят, и выходной, в которую дуги только входят.
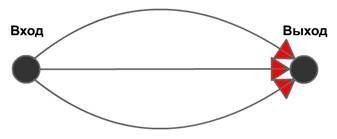
Дуги этого графа могут быть помечены терминальными и нетерминальными символами. В расширенной диаграмме с терминальным Т и нетерминальным N алфавитами каждому нетерминалу А и его правилу вывода А ® a, где a - регулярное выражение в алфавите TUN, отвечает одна синтаксическая диаграмма. При обозначении дуг помеченными терминальными символами условились эти символы писать строчными буквами и заключать в окружность. Нетерминальные символы условились писать заглавными буквами и размещать в прямоугольнике. Регулярное выражение будет обозначаться греческими буквами внутри ромба.
На рисунке 2 показаны примеры изображения дуг, помеченных терминальным символом а, нетерминальным – А и регулярным выражением – a.
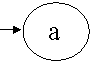


Рисунок 2
Алгоритм лексического анализа может быть применен при условиях, что в синтаксических диаграммах нет непомеченных дуг от входной вершины до выходной и в каждом разветвлении ветки начинаются с неодинаковых последующих терминальных символов. По синтаксической диаграмме строится функция анализа выводимых из нетерминала цепочек символов ![]() . Прохождению дуги, помеченной терминальным символом а, отвечает распознавание этого символа (т. е. а) в предъявленном для анализа слове и сдвиг на следующий символ в этом слове (чтение очередного символа из слова).
. Прохождению дуги, помеченной терминальным символом а, отвечает распознавание этого символа (т. е. а) в предъявленном для анализа слове и сдвиг на следующий символ в этом слове (чтение очередного символа из слова).
Прохождению дуги, помеченной нетерминальным символом А, отвечает вызов функции распознавания цепочек, которые выводятся из А. Перед вызовом этой функции предварительно должен быть прочитан первый терминальный символ х, который выводят из А, т. е. ![]() . Функция успешно анализирует цепочку
. Функция успешно анализирует цепочку ![]() , выводимую из нетерминала А, если в соответствии с синтаксической диаграммой, прочитав посимвольно всю цепочку
, выводимую из нетерминала А, если в соответствии с синтаксической диаграммой, прочитав посимвольно всю цепочку ![]() , удается попасть из входной вершины в выходную.
, удается попасть из входной вершины в выходную.
2. 9 Введение в компиляцию
Все изложенные выше сведения о грамматических и формальных языках необходимы для создания трансляторов.
Транслятором называется компьютерная программа, которая осуществляет переход программы на входном языке (например, алгоритмическом) на эквивалентную ей объектную программу. Если входной язык высокого уровня (алгоритмические языки Паскаль, Си и др.), а выходной – машинные коды или АССЕМБЛЕР (т. е. машинно-ориентированный язык), то такой транслятор называется компилятором.
Интерпретатор - разновидность транслятора, который переводит программу на язык простых промежуточных команд и выполняет их.
Препроцессор – транслятор, осуществляющий перевод с одного языка высокого уровня на другой язык тоже высокого уровня.
Итак, транслятор – компьютерная программа, которая читает последовательно символ за символом текст некоторой другой компьютерной программы на каком-то алгоритмическом языке и осуществляет перевод этой программы на другой (выходной) язык. В случае, если транслятором является программа-компилятор, после перевода с алгоритмического языка будет получена компьютерная программа или на ассемблере или в виде последовательности машинных команд в кодах (объектный модуль). Один или нескольких объектных модулей обрабатываются программой - компоновщиком. В результате создается готовая к исполнению программа. Компилятор осуществляет перевод программы на алгоритмическом языке в программу, состоящую из последовательности некоторых промежуточных команд. Сразу же после окончания перевода интерпретатор в отличие от компилятора выполняет полученную программу.
2. 10 Структура компилятора
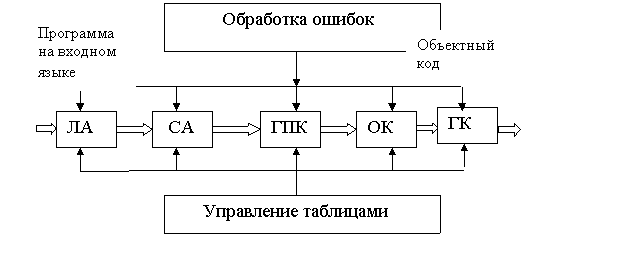
Здесь:
ЛА – лексический анализ;
СА – синтаксический анализ;
ГПК – генерация промежуточного кода;
ОК – оптимизация кода;
ГК – генерация кода.
На всех этапах осуществляется обработка ошибок и происходит заполнение различных таблиц. Рассмотрим более подробно некоторые этапы обработки исходной программы на алгоритмическом языке.
ЛА – лексический анализ. Лексема – это один или несколько символов, имеющих некоторый самостоятельный смысл. В процессе лексического анализа считываемые последовательно из программы на выходном (алгоритмическом) языке символы объединяются в лексемы. Различаются следующие лексемы:
· служебные слова;
· идентификаторы;
· знаки для обозначения операций, а также другие специальные символы;
· числа;
· признак конца считываемого файла.
Служебные (зарезервированные) слова нельзя использовать в программе на алгоритмическом языке в качестве идентификаторов для обозначения переменных и функций. Например, для языка Си это if, do, while, for, return, goto, char, int, float и др. Поэтому программа-транслятор должна “уметь” отличить эти зарезервированные служебные слова. На следующем этапе происходит построение из лексем синтаксических структур, которые могут быть составляющими других. На всех этапах осуществляются обнаружение ошибок в тексте транслируемой программы, а также заполнение таблиц. Конкретно заполняются таблица идентификаторов переменных и функций, таблица объектов, которые обрабатываются (константы, глобальные и локальные переменные), таблица функций (главная функция main и др.), таблица команд.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
