

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2) DCONST ® constl CONS (‘,’ CONS)* ‘;’.
Описание констант должно начинаться со служебного слова const, которому соответствует лексема constl в регулярном выражении. За лексемой должен быть нетерминальный символ CONS. Затем через запятую могут быть еще нуль и больше констант. В конце описания констант должна быть ‘;’.
3) CONS ® iden ‘=’ [‘+’ | ‘-‘] numb.
Константа являет собой идентификатор, за которым следует ‘=’, а за ним – число с необязательным знаком.
Для лучшего понимания 2-го и 3-го регулярных выражений вспомним, как описываются константы в программе на языке SPL.
Например, const k=4, m=-5, q=125;
4) DVARB → intl iden (‘,’ iden) * ‘;’.
Перед описанием переменных должно быть служебное слово int. Ему соответствует в регулярном выражении лексема intl. Далее должен следовать идентификатор. Через запятые могут быть еще идентификаторы. В конце описания ставится ‘;’.
5) DFUNC → iden PARAN BODY.
Вначале следует имя функции, а за ним – описание параметров и тело функции.
6) PARAM → ‘(‘ [iden (‘,’ iden) *] ‘)’.
При описании параметров обязательно должны быть круглые скобки. В них необязательно может быть идентификатор или последовательность идентификаторов через запятую.
7) BODY → beginl (DVARB | DCONST)*STML endl.
Тело функции начинается служебным словом begin, которому соответствует лексема beginl. Далее могут следовать нуль и еще (много раз) описание переменных или констант. Затем – последовательность операторов и служебное слово end (лексема endl).
8) STML → STAT (‘,’ STAT)*.
Последовательность операторов может состоять из одного или их последовательности через ‘,’.
9) STAT → iden ‘=’ EXPR |
readl iden |
printl EXPR |
retrl EXPR |
ifl EXPR thenl STML endl |
whilel EXPR dol STML endl.
Операторы в языке SPL следующие:
1 Оператор присвоения, когда переменной присваивается результат вычисления выражения.
2 Чтение переменной.
3 Вывод на печать результата вычисления.
4 Возврат из функции результата вычисления.
5 Оператор условной передачи управления. Проверяется результат вычисления выражения. Если он больше нуля, то вычисляется последовательность операторов, расположенная между ключевыми словами then и end.
6 Оператор цикла. Последовательность операторов, расположенная между служебными (ключевыми) словами do и end, выполняется в цикле до тех пор, пока результат вычисления выражения после while больше нуля.
10) EXPR → [‘,’ | ‘-‘] TERM ((‘+’ | ‘-‘) TERM)*.
Выражение представляет собой слагаемое, перед которым необязательно может стоять знак. Через знаки „+” или „-” могут также быть и другие слагаемые.
11) TERM → FACT ((‘*’ | ‘/’ | ‘%’) FACT)*.
Слагаемое может состоять из одного множителя или через знаки „*” или „/”, или „%” следовать другие сомножители.
12) FACT → ‘(‘ EXPR ‘)’ | numb | iden [‘(‘[FCTL]’)’].
Множитель – это или выражение в круглых скобках, или число, или идентификатор. Последний может быть идентификатором переменной или же функции. Тогда за идентификатором следуют круглые скобки. Внутри них – необязательная последовательность выражений.
13) FCTL → EXPR (‘,’ EXPR)*.
Это одно или несколько выражений через запятую.
5. 2 Синтаксические диаграммы и функции распознавания цепочек для нетерминальных символов
Приведенные выше регулярные выражения, как уже говорилось, описывают полный синтаксис языка SPL. Теперь необходимо написать такую программу на языке Си, которая читала бы символ за символом слева направо такой программы на языке SPL и осуществляла синтаксический анализ текста программы. Рассматривая весь текст программы на SPL как одну цепочку символов, программа синтаксического анализа должна решить, принадлежит ли эта цепочка (программа на SPL) языку, описываемому грамматикой, представленной тринадцатью регулярными выражениями. В случае наличия синтаксической ошибки программа должна выдать сообщение о том, в какой строке программ на SPL имеется ошибка, какая лексема и с какой не совпадает. После чего анализ прекращается. В случае отсутствия ошибок должно появиться сообщение, что ошибок нет.
Перед тем как изучить последующий материал, следует повторить материал по синтаксическим диаграммам: что это такое и зачем, как обозначаются дуги и правила прохождения дуг, помеченных терминальными и нетерминальными символами. Суть в том, что по каждому регулярному выражению изображается соответствующая синтаксическая диаграмма, а по ней пишется текст функции на Си для распознавания цепочек, выводимых для рассматриваемого нетерминального символа. В этих функциях часто вызывается функция get ( ), которая возвращает лексему lex с ожидаемой lx. Для этого служит функция exam ( ). В случае совпадения lex и lx считывается новая лексема (вызывается get ( )). При несовпадении выдается сообщение и прекращается работа программы. Такая функция exam ( ) приводится ниже.
void exam (int lx)
{
if (lex!=lx)
{
printf (“Не совпадают лексемы lex=%i и lx=%i в строке nst=%i \n”, lex, lx, nst);
exit (1);
}
get ( );
return;
}
Текст программы part2.c на Си, которая осуществляет лексический и синтаксический анализы, приведен в главе 6. В эту программу полностью входит рассмотренная ранее программа лексического анализа part1.c, однако в ней имеются одно дополнение и одно изменение. В функции main( ) после вызова get( ) следует также вызвать функцию вывода для главного нетерминального символа prog( ).
Изменение внесено в самом начале функции get( ). Вместо
while (nch!=EOF)
{ …
…
}
следует
if (nch = = EOF)
{
lex = EOF;
return;
}
………
Таким образом, функцией get( ) при каждом обращении к ней выдается только одна очередная лексема.
Кроме того, part2.c отличается от part1.c наличием функций, соответствующих каждому нетерминальному символу. Как уже сказано выше, для их написания используются синтаксические диаграммы, полученные в строгом соответствии с регулярными выражениями. Ниже рассмотрим, как это делается конкретно. Первым должен рассматриваться главный нетерминальный символ PROG.
1 PROG → (DCONST |DVARB |DFUNK) * eof
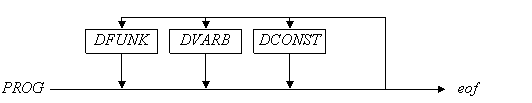
void prog( )
{
while (lex!=EOF)
{
switch (lex)
{
case IDEN: dfunc( ); break;
case INTL: dvarb( ); break;
case CONSTL: dconst( ); break;
default: printf(“Ошибка синтаксиса в строке nst=%i. Лексема lex=%i \n”, nst, lex);
}
}
return;
}
По диаграмме видно, что если lex!=EOF, то реализуется разветвление по нескольким ветвям в зависимости от lex. Лексема lex может быть IDEN, если описывается функция, INTL при описании переменных и CONSTL – констант. Естественно производится вызов одной из функций dfunc( ), dvarb( ), dconst( ).
2 DCONST → constl CONS (‘,’ CONS)* ‘;’
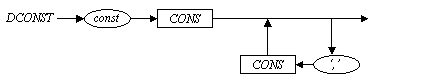
void dconst( )
{
// Нет неиспользованной “свежей” лексемы
// Ее нужно получить, вызвав get( );
do
{
get( );
cons( );
} while (lex = = ‘,’);
exam (‘;’);
return;
}
Вначале проходная дуга, помеченная терминальным символом constl. Проверка того, что лексема lex была равна constl, осуществляется в функции prog( ). Именно там по switch (lex) в случае case CONSL была вызвана функция dconst( ). Перед прохождением следующей дуги, обозначенной нетерминальным символом CONS, согласно правилу прохождения дуг синтаксической диаграммы должен быть прочитан очередной терминальный символ (лексема). Напомним, что лексема constl уже использована. “Свежей” лексемы нет. Поэтому в функции dconstl перво-наперво считывается новая лексема ( вызов get( )), а затем уже вызывается функция cons( ), соответствующая нетерминальному символу CONS. Цикл осуществляется пока lex = =’,’. В случае выхода из цикла проверяется условие, что lex==’;’. Для этого вызывается exam (‘;’). Если это условие выполняется, то функция exam( ) в конце вызывает get( ) и, таким образом, поставляет “свежую” лексему, необходимую для дальнейшего синтаксического анализа.
3 CONS → iden ’=’ [‘+’|’-’] numb

//“Свежая” лексема есть
void cons( )
{
exam (IDEN);
exam (‘=’);
if (lex = = ‘+’ || lex = = ‘-‘)
get( );
exam (NUMB);
return;
}
При прохождении дуги, помеченной терминальным символом, проверяется совпадение имеющейся лексемы lex с той, которая должна быть. Это делает функция exam( ). При совпадении происходит чтение следующей лексемы и т. д. Здесь проверяется, чтобы была лексема IDEN, затем ‘=’. Далее необязательный знак ‘+’ или ‘-‘ и в конце – NUNB.
4 DVARB → intl iden (‘,’ iden) * ‘;’
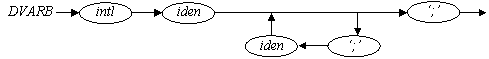
// “Свежей” лексемы нет. Лексема INTL была использована в функции prog( ) в // switch (lex). По ней была вызвана функция dvarb( ).
void dvarb( )
{
do
{
get( );
exam(IDEN);
} while(lex = = ‘,’);
exam(‘;’);
return;
}
В связи с отсутствием “свежей” лексемы необходимо вызвать get( ). Затем проверяется, является ли полученная лексема IDEN. В случае совпадения в конце функции exam( ) следует вызов get( ). Если будет прочитана лексема ”запятая”, то вновь в цикле do while повторяются get( ) и exam(IDEN). После того как очередная лексема не будет равной ‘,’ , происходит выход из цикла и проверяется наличие ‘;’.
5 DFUNK → iden PARAM BODY
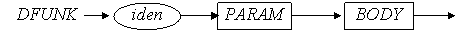
// Лексема IDEN была использована в функции prog( ) в switch(lex). Нужно //вызвать get( ) для получения новой лексемы.
void dfunc( )
{
get( ); // получение новой лексемы
param( );
body( );
return;
}
6 PARAM → ‘(’ [iden (‘,’ iden)*] ‘)’

Перед вызовом функции param( ) из dfunc( ) был вызов get( ). Следовательно, “свежая” лексема имеется.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
