

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
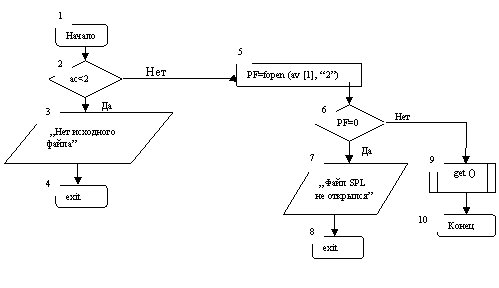
В av [1] следует занести самостоятельно имя файла с текстом программы на языке SPL. Например, var2.s Для этого необходимо, находясь в среде Borland C++ , вызвать в главном меню Run/arguments и в появившееся диалоговое окно ввести требуемое имя файла на SPL. В данном примере – это var2.s. Предполагается, что var2.s находится в текущей директории. Чтобы обеспечить обращение к этому файлу при запуске Borland C++ из другой директории, надо ввести полный путь, например, C:\\USER\\SPL\\var2.s part1.s ¿.
Для лучшего понимания работы лексического анализа part1.c предлагается рассмотреть блок-схемы отдельных его функций.
Вначале проверяется количество параметров ac. Должно быть не меньше двух, например, part1.exe в av[0] и var2.s в av [1]. Если параметров меньше двух, происходит остановка работы программы. Иначе открывается файл для чтения с текстом на SPL. В примере это – var2.s и его имя находится в av [1]. Если файл открылся, то происходит вызов функции get ( ), которая является “поставщиком” лексем.
4. 1 Блок-схема функции void main (int ac, char * av [ ])
В функции get () блок №1 в интерпретаторе должен быть if(nch==EOF)
{ lex=EOF;
.-.-.-.-.-.-.-.-
return;
}
Однако программа part1.c предназначена только лишь для того, чтобы прочитать текст программы на SPL, распознать лексемы, а идентификаторы занести в специальную таблицу идентификаторов char TNM [400]. Поэтому в данной программе в функции get ( ) блок №1 являет собой цикл while (nch!=EOF). Он позволяет прочитать весь текст программы на SPL до конца файла. Далее идет цикл while (isspace(nch)), позволяющий пропускать символы пробела, табуляции, перехода на новую строку и на новую страницу.
Если символ nch, прочитанный из файла с помощью функции get (), не является одним из перечисленных выше, то происходит его распознавание с вызовом функции number( ) или word( ).
Если nch является одним из перечисленных специальных символов, например, ‘(’, ‘)’, ‘+’ и т. д., то лексема получает соответствующее значение, считывается новый символ и происходит возврат в цикл (блок №1). В противном случае выдается сообщение о недопустимом символе и происходит выход из программы.
4. 2 Блок-схема функции void number ()
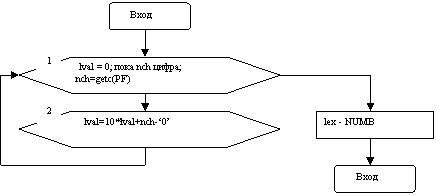

Блок №1 представляет собой цикл for ( ). В нем значение лексемы lval вначале определяется. Затем проверяется, что nch – цифра. Если это так, то происходит вычисление нового значения lval в блоке №2. Старое значение lval умножается на 10. К нему прибавляется результат вычитания из кода прочитанной цифры (nch) кода нуля. В таблице кодов ASCII код нуля в “10” системе равен 48, код “1” – 49, код “2” – 50 и т. д. Соответственно в “16”-ричной системе – (30)16, (31)16, (32)16 и т. д.
Таким образом, разница кодов позволяет получить прочитанную цифру. Предположим, из программы на SPL считывается константа 541. По первой цифре “5” будет вызвана функция number (). lval=0. nch содержит код цифры “5”, т. е. (35)16. Итак, условие – является ли содержимое nch кодом цифры, дает положительный ответ. В результате происходит переход к блоку №2. В нем вычисляем lval=10*0+(35)16 – (30)16 =5. После этого происходит возврат в циклы, считывается из файла новое значение nch. Это код (34)16 цифры “4”.
Теперь в блоке №2 lval=10*5+(34)16 – (30)16 =54.
После считывания кода цифры “1” lval=10*54+(31)16 – (30)16=541.
После того как очередной прочитанный символ окажется не цифрой, происходит выход из цикла. Лексема получает значение NUMB, и происходит выход из функции.
4. 3 Блок-схема функции void word ()
П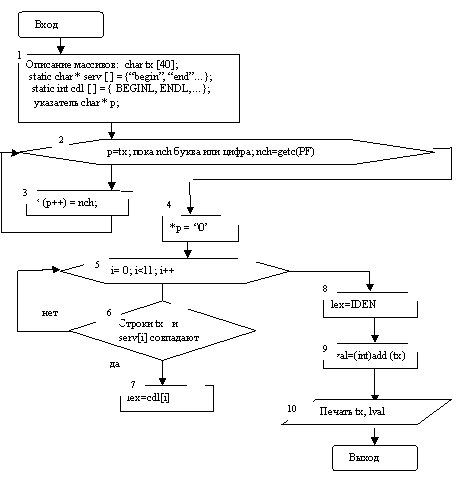

Блок №2 реализуется в виде цикла for. В указатель p заносится адрес tx[0]. Затем проверяется условие, что nch – буква или цифра. Если это так, то реализуется блок №3. По адресу в указателе p, т. е. в tx[0], заносится символ nch. После этого значение p увеличивается на 1, то есть в р находится адрес tx [1]. Происходит возвращение в цикл. Считывается новое значение nch. Если он буква или цифра, вновь выполняется блок №2. теперь уже символ nch заносится в tx [1], после чего в р заносится адрес tx [2] и т. д. Если прочитанный символ nch – не буква и не цифра, происходит выход из цикла. В очередной элемент массива tx заносится ‘\0’ – признак конца строки символов. В tx сформирована некая последовательность букв или букв и цифр. Теперь предстоит проверить, что собой она представляет. Это может быть одно из служебных (зарезервированных) слов, перечисленных в массиве char*serv [] .
Проверка выполняется в цикле (блоки №5 и №6). В случае совпадения строки символов tx и одного из служебных слов lex получает значение соответствующего элемента из массива int cdl [ ].
Например, если в tx находится строка символов end, то она совпадает с элементом end из seev [1] и лексема lex=ENDL, т. е. lex=258 (см. enum={BEGINL=257, ENDL…};).
Если содержимое tx не совпало ни с одним служебным словом, значит, - это идентификатор переменной или функции. В этом случае lex=IDEN, т. е. 269, и его необходимо занести в таблицу идентификаторов char TNM [400]. Для этого вызывается функция add (tx). Она возвращает указатель char*. Поэтому, чтобы присвоить возвращаемый адрес переменной целого типа int lval, применяется явное преобразование типа
lval=(int) add (tx).
4. 4 Блок-схема функции char*add(char*nm)
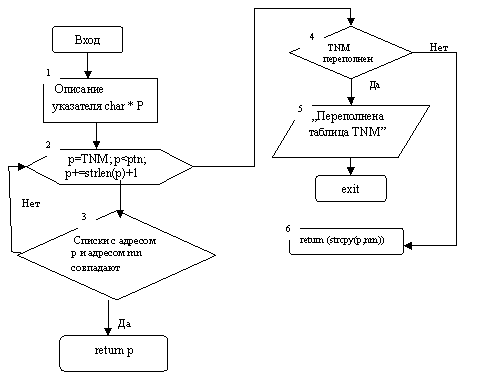

При вызове функции add (char*nm) вместо формального параметра nm передается фактический параметр tx (последовательность символов - идентификатор). В блоках №2 и №3 в цикле осуществляется проверка – не был ли ранее занесен в TNM этот идентификатор. Для этого используется указатель char*p. В блоке №2 вначале в p заносится TNM, т. е. адрес TNM [0]. Затем проверяется условие p<ptn. Следует вспомнить, что char*ptn был описан выше в качестве глобального указателя на первый свободный элемент в таблице идентификаторов TNM. Если p<ptn, то выполняется сравнение строк, прочитанных из TNM. В случае совпадения происходит возвращение адреса, где этот идентификатор был ранее записан. При несовпадении происходит изменение адреса на длину строки только что сравниваемого из TNM идентификатора плюс один символ на ‘\0’. p+=strlen (p) +1.
После этого вновь проверяется условие p<ptn и т. д. Если условие p<ptn не выполнилось, это означает, что проверены все ранее записанные в TNM идентификаторы. Тогда нужно изменить значение указателя ptn на количество символов заносимого в таблицу идентификатора плюс один.
ptn+=strlen(nm)+1.
Кроме того, нужно проверить, не выйдет ли новое значение ptn за пределы таблицы TNM. Все это оформлено в виде оператора
if ((ptn+=strlen(nm)+1)>TNM+400)
{
puts(“Переполнение таблицы TNM”);
exit (1);
}
return (strcpy(p, nm));
Если переполнения нет, то вызывается функция копирования строк strcpy( ), которая строку nm скопирует в р и адрес вернет в функцию word( ).
5 Полный синтаксис языка SPL
Из структурной схемы компилятора видно, что после лексического анализа следует фаза синтаксического анализа. То же самое имеет место и для идентификатора. Для ее реализации нужно знать основные конструкции языка SPL. Эти конструкции обозначаются нетерминальными символами, для каждого из которых имеется правило вывода. Терминальными символами являются лексемы.
Как уже говорилось выше, язык SPL, как и любой другой формальный язык, описывается грамматикой. Конкретно, его полный синтаксис ниже представлен расширенной грамматикой в виде последовательности регулярных выражений. Для каждого нетерминального символа имеется отдельное регулярное выражение. Условимся нетерминальные символы в регулярных выражениях обозначать заглавными буквами, а терминальные (лексемы) – строчными. Помимо символов ‘*’, ‘,’, ‘\’ в регулярных выражениях также будут использованы квадратные скобки ‘[‘, ‘]’ для выделения необязательных цепочек символов.
5. 1 Алфавит нетерминальных символов
1) PROG – программа;
2) DCONST – описание констант;
3) CONS – константа;
4) DVARB – описание переменных;
5) DFUNC – описание функций;
6) PARAM – параметры функции;
7) BODY – тело функции;
8) STML – последовательность операторов;
9) STAT – оператор;
10)EXPR – выражение;
11)TERM – слагаемое;
12)FACT – множимое;
13)FCTL – последовательность выражений.
Ниже приводятся 13 регулярных выражений, представляющих полный синтаксис языка SPL. Первое из них – для главного (стартового) нетерминального символа PROG.
1) PROG ® (DCONST | DFUNC | DVARB)* eof.
Здесь показано, что программа – это описание констант или описание функции, или описание переменных. Причем все эти описания заключены в круглые скобки, после которых стоит звездочка. Напомним, это означает, что эти описания могут повторяться нуль и больше раз. То есть может случиться, что ни одного из них нет. А за этими описаниями обязательно должна быть лексема eof – признак конца файла. Таким образом, в принципе программа может состоять только из признака конца файла.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
