

εi от εi-1
2. Коэффициент автокорреляции.
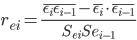
Если коэффициент автокорреляции rei < 0.5, то есть основания утверждать, что автокорреляция отсутствует.
3. Критерий Дарбина-Уотсона.
Этот критерий является наиболее известным для обнаружения автокорреляции.
При статистическом анализе уравнения регрессии на начальном этапе часто проверяют выполнимость одной предпосылки: условия статистической независимости отклонений между собой. При этом проверяется некоррелированность соседних величин ei.
y | y(x) | ei = y-y(x) | e2 | (ei - ei-1)2 |
1278.6 | 1306.74 | -28.14 | 791.73 | 0 |
1318.3 | 1301.54 | 16.76 | 280.92 | 2015.86 |
1313.5 | 1296.34 | 17.16 | 294.43 | 0.16 |
1293.9 | 1291.14 | 2.76 | 7.6 | 207.41 |
1273.7 | 1285.94 | -12.24 | 149.93 | 225.05 |
1285.6 | 1280.75 | 4.85 | 23.56 | 292.35 |
1287.1 | 1275.55 | 11.55 | 133.45 | 44.87 |
1272.7 | 1270.35 | 2.35 | 5.53 | 84.67 |
1250.1 | 1265.15 | -15.05 | 226.54 | 302.82 |
1913.68 | 3173.19 |
Для анализа коррелированности отклонений используют статистику Дарбина-Уотсона:
![]()
![]()
Критические значения d1 и d2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n = 9 и количества
объясняющих переменных m=1.
Автокорреляция отсутствует, если выполняется следующее условие:
d1 < DW и d2 < DW < 4 - d2.
Не обращаясь к таблицам, можно пользоваться приблизительным правилом и считать, что автокорреляция остатков отсутствует, если 1.5 < DW < 2.5. Поскольку 1.5 < 1.66 < 2.5, то автокорреляция остатков отсутствует.
Для более надежного вывода целесообразно обращаться к табличным значениям.
По таблице Дарбина-Уотсона для n=9 и k=1 (уровень значимости 5%) находим:
d1 = 1.08; d2 = 1.36.
Поскольку 1.08 < 1.66 и 1.36 < 1.66 < 4 - 1.36, то автокорреляция остатков отсутствует.
Проверка наличия гетероскедастичности.
1) Методом графического анализа остатков.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X, а по оси ординат либо отклонения ei, либо их квадраты e2i.
Если имеется определенная связь между отклонениями, то гетероскедастичность имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии гетероскедастичности.
2) При помощи теста ранговой корреляции Спирмена.
Коэффициент ранговой корреляции Спирмена.
Присвоим ранги признаку ei и фактору X.
X | ei | ранг X, dx | ранг ei, dy |
1 | 28.14 | 1 | 9 |
2 | 16.76 | 2 | 7 |
3 | 17.16 | 3 | 8 |
4 | 2.76 | 4 | 2 |
5 | 12.24 | 5 | 5 |
6 | 4.85 | 6 | 3 |
7 | 11.55 | 7 | 4 |
8 | 2.35 | 8 | 1 |
9 | 15.05 | 9 | 6 |
Матрица рангов.
ранг X, dx | ранг ei, dy | (dx - dy)2 |
1 | 9 | 64 |
2 | 7 | 25 |
3 | 8 | 25 |
4 | 2 | 4 |
5 | 5 | 0 |
6 | 3 | 9 |
7 | 4 | 9 |
8 | 1 | 49 |
9 | 6 | 9 |
45 | 45 | 194 |
Проверка правильности составления матрицы на основе исчисления контрольной суммы:![]()
Сумма по столбцам матрицы равны между собой и контрольной суммы, значит,
матрица составлена правильно.
По формуле вычислим коэффициент ранговой корреляции Спирмена.![]()
![]()
Связь между признаком ei и фактором X умеренная и обратная
Оценка коэффициента ранговой корреляции Спирмена.
Значимость коэффициента ранговой корреляции Спирмена
Для того чтобы при уровне значимости α проверить нулевую гипотезу о равенстве
нулю генерального коэффициента ранговой корреляции Спирмена при конкурирующей гипотезе Hi. p ≠ 0, надо вычислить критическую точку:![]()
где n - объем выборки; p - выборочный коэффициент ранговой корреляции Спирмена: t(α, к) - критическая точка двусторонней критической области, которую находят по таблице критических точек распределения Стьюдента, по уровню значимости α и числу степеней свободы k = n-2.
Если |p| < Тkp - нет оснований отвергнуть нулевую гипотезу. Ранговая корреляционная связь между качественными признаками не значима. Если |p| > Tkp - нулевую гипотезу отвергают. Между качественными признаками существует значимая ранговая корреляционная связь.
По таблице Стьюдента находим t(α/2, k) = (0.05/2;7) = 2.365
![]()
Поскольку Tkp > p, то принимаем гипотезу о равенстве 0 коэффициента ранговой корреляции Спирмена. Другими словами, коэффициент ранговой корреляции статистически - не значим и ранговая корреляционная связь между оценками по двум тестам незначимая.
Проверим гипотезу H0: гетероскедастичность отсутсвует.
Поскольку 2.365 > 0.7, то гипотеза об отсутствии гетероскедастичности принимается.
3. Тест Голдфелда-Квандта.
В данном случае предполагается, что стандартное отклонение σi = σ(εi) пропорционально значению xiпеременной X в этом наблюдении, т. е. σ2i = σ2x2i , i = 1,2,…,n.
Тест Голдфелда-Квандта состоит в следующем:
1. Все n наблюдений упорядочиваются по величине X.
2. Вся упорядоченная выборка после этого разбивается на три подвыборки размерностей k,(n-2k),k.
4. Оцениваются отдельные регрессии для первой подвыборки (k первых наблюдений) и для третьей подвыборки (k последних наблюдений).
4. Для сравнения соответствующих дисперсий строится соответствующая F-статистика:
F = S3/S1
Построенная F-статистика имеет распределение Фишера с числом степеней свободы v1 = v2 = (n – c - 2m)/2.
5. Если F > Fkp, то гипотеза об отсутствии гетероскедастичности отклоняется.
Этот же тест может использоваться при предположении об обратной пропорциональности между σi и значениями объясняющей переменной. При этом статистика Фишера имеет вид:
F = S1/S3
1. Упорядочим все значения по величине X.
2. Находим размер подвыборки k = (9 - 2)/2 = 4.
где c = 4n/15 = 4*9/15 = 2
3. Оценим регрессию для первой подвыборки.
Находим параметры уравнения методом наименьших квадратов.
Система уравнений МНК:
a0n + a1∑t = ∑y
a0∑t + a1∑t2 = ∑y•t
Для наших данных система уравнений имеет вид:
4a0 + 10a1 = 5204.3
10a0 + 30a1 = 13031.3
Из первого уравнения выражаем а0 и подставим во второе уравнение
Получаем a0 = 4.11, a1 = 1290.8
x | y | x2 | y2 | x • y | y(x) | (y-y(x))2 |
1 | 1278.6 | 1 | 1634817.96 | 1278.6 | 1294.91 | 266.02 |
2 | 1318.3 | 4 | 1737914.89 | 2636.6 | 1299.02 | 371.72 |
3 | 1313.5 | 9 | 1725282.25 | 3940.5 | 1303.13 | 107.54 |
4 | 1293.9 | 16 | 1674177.21 | 5175.6 | 1307.24 | 177.96 |
10 | 5204.3 | 30 | 6772192.31 | 13031.3 | 5204.3 | 923.23 |
Здесь S1 = 923.23
Оценим регрессию для третьей подвыборки.
Находим параметры уравнения методом наименьших квадратов.
Система уравнений МНК:
a0n + a1∑t = ∑y
a0∑t + a1∑t2 = ∑y•t
Для наших данных система уравнений имеет вид:
4a0 + 30a1 = 5095.5
30a0 + 230a1 = 38155.8
Из первого уравнения выражаем а0 и подставим во второе уравнение
Получаем a0 = -12.09, a1 = 1364.55
x | y | x2 | y2 | x • y | y(x) | (y-y(x))2 |
6 | 1285.6 | 36 | 1652767.36 | 7713.6 | 1292.01 | 41.09 |
7 | 1287.1 | 49 | 1656626.41 | 9009.7 | 1279.92 | 51.55 |
8 | 1272.7 | 64 | 1619765.29 | 10181.6 | 1267.83 | 23.72 |
9 | 1250.1 | 81 | 1562750.01 | 11250.9 | 1255.74 | 31.81 |
30 | 5095.5 | 230 | 6491909.07 | 38155.8 | 5095.5 | 148.17 |
Здесь S3 = 148.17
Число степеней свободы v1 = v2 = (n – c - 2m)/2 = (9 - 2 - 2*1)/2 = 2.5
Fkp(2.5,2.5) = 10.1
Строим обратную F-статистику:
F = 923.23/148.17 = 6.23
Поскольку F < Fkp = 10.1, то гипотеза об отсутствии гетероскедастичности принимается.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
