


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Для изучения сетевых структур используется аппарат теории графов. В настоящий момент интерес к классическим случайным графам, имеющим случайное распределение дуг между фиксированным числом вершин, ослаб. На практике наблюдения за реальными объектами (например, WWW) проявился иной характер распределения степеней1 вершин графа (степенной, а не подчиненный распределению Пуассона; сами же сети получили название сетей без масштаба) в результате наличия узлов, имеющих очень большое число связей. Было обнаружено и другое интересное свойство, получившее название концепции тесного мира. Она состоит в том, что требуется сравнительно небольшое число шагов, чтобы из данной вершины добраться до случайно выбранной конечной вершины. Подобный эффект достигается по причине того, что добавление хотя бы одной дуги между сильно удаленными друг от друга вершинами значительно уменьшает длину среднего кратчайшего пути графа. Например, для сети знакомств такая длина равна всего 6, для сети WWW – 19 [3].
Рассматриваемые сетевые структуры объединяет весьма впечатляющее свойство необычной устойчивости к ошибкам и случайным повреждениям. Стремление к образованию сетей с упомянутыми свойствами является следствием их самоорганизации, а не искусственным навязываем подобной архитектуры. Рост сети происходит по принципу: чем больше связей вершина уже имеет, тем вероятнее, что на следующем шаге новая вершина будет присоединена именно к ней. Такое предпочтение более «популярных» вершин другим может принимать различные формы, отчего будет меняться и структура конкретной сети. Поэтому биологические и коммуникационные сети в природе строятся именно по таким законам.
С точки зрения теории графов, сеть рассматривается как множество вершин, соединенных между собой ребрами. Число связей данной вершины принято называть ее степенью (k).
Одной из самых простых статистических характеристик графа является функция распределения. Не все вершины сети имеют одинаковое количество ребер. Распределение количества ребер вершины, то есть степень вершины, характеризуется функцией P(k), которая определяет вероятность того, что случайно выбранная вершина будет иметь ровно k ребер. Примерами такой функции могут быть:
- распределение Пуассона
- экспоненциальное распределение мультифрактальное распределение и др.
Графы разбиваются на кластеры. Для социальных сетей, например, это выражается в том, что внутри такого кластера каждый знаком с каждым. Коэффициент кластеризации определяет плотность связей ближайшего окружения вершины. Если данный коэффициент для сети не приближается к нулю, то это будет значить, что между вершинами такой сети будут существовать взаимодействия. Таким образом, для полностью связанной сети коэффициент кластеризации будет равен 1.
1.1.3 Структура сетиСтруктура сети описывается в терминах теории протекания, основные идеи которой были сформулированы в работе Бродбента и Хаммерсли [2], основанной на исследовании применений угля для разработки противогазов для шахтёров. «Явления, связанные с теорией протекания, характеризуются наличием критической точки, в которой определенные свойства системы резко меняются. Физика всех критических явлений очень своеобразна и имеет общие черты, самая важная из которых состоит в том, что вблизи критической точки система как бы распадается на блоки с отличающимися свойствами, причем размер отдельных блоков неограниченно растет при приближении к критической точке».
В соответствии с рисунком 1 [3], обычно сеть состоит из связанных компонентов. Самый большой – это гигантский слабо связанный компонент (GWCC), который включает в себя гигантский связанный компонент (GSCC), вершины которого соединены в обоих направлениях: то есть из каждой вершины можно достичь любой другой вершины этого компонента. GWCC включает в себя еще два больших компонента – гигантский выходной (GOUT) и входной компоненты (GIN) (из всех его вершин можно попасть в GWCC), которые целиком содержат в себе GSCC. Остальные составляющие GWCC не имеют доступа в GSCC. За пределами GWCC лежат несвязанные компоненты (DC).
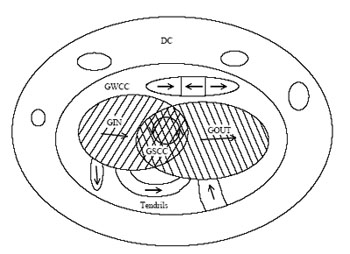
Рисунок 1 – Структура сети
1.1.4 Сети и естественный языкЯзык фактически можно представить в виде формулы: Язык = Словарь + Грамматика. Тексты конкретного языка представляют собой довольно удобный материал для сбора статистики, о чем свидетельствует длинная история исследований в этой области. Но если ранее подобные работы концентрировались на выявлении частотности появления отдельных слов в тексте, что не позволяло составить полную картину языка, то сейчас появился статистический подход обнаружения смежности и взаимодействия отдельных слов в предложении. На основе Британского Национального Корпуса (электронной коллекции текстов разговорного и письменного английского языка) была построена сеть Word Web, в которой вершинами служили отдельные слова, а дугами отмечался факт взаимодействия пар слов. При этом два слова считались взаимодействующими, если они были ближайшими соседями в предложении. В результате сбора статистических данных, выяснилось, что язык подчиняется концепции тесных миров и имеет среднюю длину пути всего 2.65 [3].
В данном разделе приведена статистическая информация, относящаяся к анализу реальных сетей, существующих в современном мире (таблица 1).
Таблица 1 – Статистика сетей [3]
Число вершин | Число дуг | Кластерный коэффициент | Средняя длина пути | |
Сеть WWW | 2.711x108 | 2.130x109 | – | 16 |
Internet | 150000 | 200000 | – | 10 |
WordWeb (Британский национальный корпус) | 470000 | 17000000 | 0.69/0.44 | 2.65 |
Телефонные сети | 47x106 | 8x107 | – | – |
Энергетические сети | 4196 | 87219 | 0.073 | 2.32 |
1.2 Алгоритм ADIOS 1.2.1 Общие сведения
Создавая алгоритм ADIOS [1,4,5,6,7,9,10,11,12], его разработчики затрагивали проблему, фундаментальную для лингвистики, биоинформатики и др. Они ставили перед собой задачу выявить внутренние правила, по которым строится поток текстовых данных. В то время, как в общем авторы придерживались концепции обучения машины, все же они не следовали ему целиком. Такое обучение может быть двух видов: управляемое (для программы сначала подготавливается набор обучающих данных, которые представляют собой примеры входных данных и соответствующих им выходов; программа учится находить связь между первыми и вторыми) и неуправляемое (на вход подаются данные, содержащие только значения входных переменных, а алгоритм программы построен так, чтобы искать решения, которые исследователь сочтет правильными). Из набора построенных моделей не выбиралась та, которая бы лучшим образом отражала входные текстовые данные, а сами текстовые данные порождали модели.
Обычно модели обучения используют два подхода: порождают синтаксические конструкции или же используют всевозможные статистические методы. Создатели ADIOS предполагали объединить оба эти подхода для получения более эффективных результатов при использовании преимуществ обоих подходов.
Алгоритм состоит из двух стадий:
- построение графа, отражающего структуру учебного корпуса обнаружение значимых шаблонов, во время которого ADIOS обучается
Пусть есть корпус, состоящий из N предложений.
1.2.2.1 Создание графаПрежде всего необходимо в соответствии с рисунком 2 [1] построить направленный граф (допускаются петли и множественные дуги), вершинами которого будут все слова исходного корпуса и еще два специальных узла, обозначающих начало и конец предложения. Каждое слово помечено номером предложения и относительным индексом внутри этого предложения, определяющего отдельный путь в графе. Под словом здесь понимается минимальная морфологическая составляющая (возможно, выделенная формально и искусственно, например - ed в словах walked и bed).
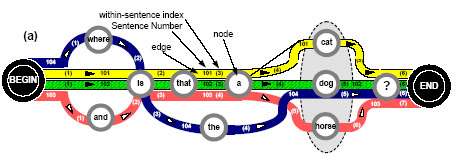
Рисунок 2 – Построение направленного графа
1.2.2.2 Обнаружение значимых шаблоновЕсли цепочка вершин является общей для нескольких путей графа (нескольких предложений), то она становится потенциальным претендентом на то, чтобы оказаться значимым шаблоном.

Рисунок 3 – Алгоритм выявления значимого шаблона
Под шаблоном понимается последовательность, состоящая из:
- ненулевого префикса (цепочка вершин) класса эквивалентности вершины ненулевого суффикса (другой цепочки вершин)
Таким образом, ADIOS рекурсивно пытается выявить все новые шаблоны, следуя алгоритму в соответствии с рисунком 3 [1].
Критерием значимости шаблона I' выступает следующее выражение, названное «критерием высокой взаимной информации» [5]:
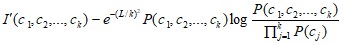
где L – это длина стандартного шаблона, ожидаемого системой, k – длина шаблона-кандидата, с1…ck – вероятности, полученные на основании частотности (их величину можно получить прямо из построенного графа: исходящее число дуг вершины пропорционально безусловной вероятности ck).
Данный критерий отражает два противоположных индикатора для образования шаблона:
- длину шаблона количество примеров, подтверждающих существование данного шаблона
Для определения значимости шаблона высчитываются вероятностные функции прохода слева направо (PR) и справа налево (PL) для каждой вершины пути, претендующего на признание значимым. Смысл, например, выражения PR(c1, ck) состоит в том, чтобы найти, количество путей, вышедших из c1 и дошедших до ck к числу путей, вышедших из c1 и дошедших до ck-1. Пока выполняется соотношение PR(c1, ck) >= ηPR(c1, ck-1) [6], последовательность рассматриваемых вершин будет входить в шаблон, а если оно перестает выполняться, то последняя вершина отсекается. Те же действия повторяются при проходе справа налево. В итоге получается шаблон, от которого справа и слева отсечены лишние вершины. η в рассмотренных работах полагалось равным 0.33.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
