


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
По мере нахождения очередного типа морфем, заполнялись поля объекта WordParts:
WordParts: make object!
[
preff: "" ; префикс слова
word: "" ; само слово
suff: "" ; суффикс слова
end: "" ; окончание слова
]
Процедура деления на морфемы применяется к каждому предложению исходного текста, после чего начинается построение графа составляющих.
3.2 Построение графа составляющихПостроение графа происходит следующим образом:
- берется очередное предложение N, слова которого разбиты на ММЕ проверяется, есть ли уже узел графа, в который занесено слово, совпадающее с текущим рассматриваемым словом предложения N если слова не совпадают, то создается новый узел графа – объект, имеющий следующую структуру:
Mme: make object!
[
text: "" ; морфема
prev*: [] ; предыдущая морфема
next*: [] ; последующая морфема
word_statistics: [] ; информация об индексах морфемы
x: 1 ; координата x
y: 1 ; координата y
]
WordInSentence: make object!
[
sentence_id: 1 ; номер предложения, к которому относится
морфема
word_id: 1 ; порядковый номер морфемы в предложении
]
- если же слова совпадают, то в найденном, повторяющем данное слово узле, массивы prev* и next*, дополняются предыдущим и следующим для данного слова словами после создания графа добавляются еще два узла, носящие названия «start» и «end» (все предложения, из которых образован рассматриваемый граф составляющих, начинаются в узле «start» и заканчиваются в узле «end»)
В результате выполнения описанных выше операций образуется структура следующего вида (для предложений «Прекрасный день. Прекрасный человек.», разбитых на «пре кра сн ый де нь. пре кра сн ый челове к»):
text: "пре"
prev*: ["start"]
next*: ["кра"]
word_statistics: [make object! [
sentence_id: 1
word_id: 1
] make object! [
sentence_id: 2
word_id: 1
]]
x: 525
y: 280
text: "кра"
prev*: ["пре"]
next*: ["сн"]
word_statistics: [make object! [
sentence_id: 1
word_id: 2
]]
x: 1
y: 1
text: "ый"
prev*: ["сн"]
next*: ["де" "челове"]
word_statistics: [make object! [
sentence_id: 1
word_id: 4
] make object! [
sentence_id: 2
word_id: 3
]]
x: 1
y: 1
Алгоритм ADIOS представляет собой итеративный процесс извлечения из текста значимых шаблонов, обнаружения новых классов эквивалентности и образования новых узлов в графе составляющих.
Процедура выделения значимых шаблонов в пределах одной итерации ADIOS применяется к каждому пути в графе составляющих (изначально каждый такой путь просто совпадает с исходными предложениями) для обнаружения шаблонов-кандидатов (на то, чтобы оказаться значимыми). Под шаблоном-кандидатом понимается набор узлов графа составляющих (последовательность слов в рамках одного предложения), в пределах которых некоторое количество предложений дословно совпадает, например, в соответствии с рисунком 7, шаблоном-кандидатом может стать подпуть e2→e3→e4 рассматриваемого предложения, изображенного черным цветом.
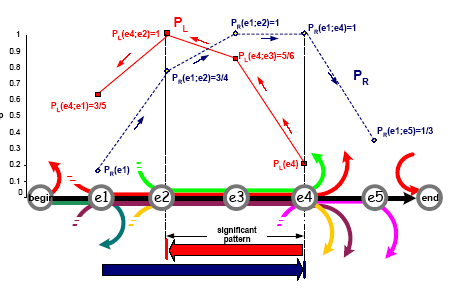
Рисунок 7 - Выделение шаблона-кандидата
Таким образом, если вдоль рассматриваемого пути обнаруживается последовательность вершин, в течение которой достаточно много других путей присоединяются к текущему, а за ее пределами достаточно много путей ее покидают, и при этом количество узлов в такой последовательности является достаточным, то эту последовательность можно рассматривать как шаблон-кандидат.
Для выделения подобных последовательностей вершин, по каждому пути в графе строятся две вероятностные функции – Pr [9] (отношение числа путей, проходящих сквозь набор вершин слева направо вдоль рассматриваемого пути к числу путей, входящих в этот набор) и Pl (то же, что и Pr, только путь просматривается справа налево):
![]()
![]()
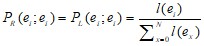
где l(ei;ej) – число подпутей (ei;ej), встречающихся в графе составляющих, а N – число узлов в графе.
В рамках построенных таким образом функций можно определить шаблоны-кандидаты. Постепенный рост функции означает присоединение все большего числа путей к рассматриваемому пути, внезапное падение означает, что достаточно большое число путей покинуло текущий. Падение Pr после роста сигнализирует об окончании шаблона-кандидата, а падение Pl – о начале. Чтобы определить скорость падения Pr и Pl, вводятся две дополнительные функции – Dr и Dl:
![]()
![]()
На обе последние функции накладывается условие быть меньше порогового параметра з = 0.33. Данное условие можно пояснить следующим образом: если после прохождения какой-то определенной вершины рассматриваемый шаблон-кандидат покидает в два раза больше путей, чем остается, то такую вершину можно считать границей шаблона.
Функции Pl и Pr считаются вдоль рассматриваемого пути, начиная с каждой возможной его вершины. В результате для каждого пути графа S строится матрица вида:
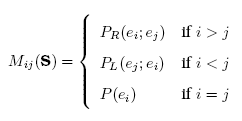
Сформированные на основе Dl и Dr шаблоны-кандидаты далее должны быть оценены на предмет того, являют ли они собой некоторую статистически выявленную закономерность или же это результат случайных флуктуаций вследствие недостаточно обширной выборки:
![]() (1)
(1)
На вход алгоритму MEX в цикле подается текущий путь в графе для выявления на нем значимого шаблона. По количеству узлов этого пути инициализируется матрица для отображения количества подпутей между всеми вершинами данного пути:
graph_matrix: array/initial reduce [ len len ] ( copy [] )
Далее с помощью функции *makeConnectMatrix эта матрица заполняется в каждой ячейке номерами предложений, ведущими из одной вершины в другую:
for i 1 len_sent 1
[
word_i: pick sent i
for j i len_sent 1
[
either i == j
[
*change matrix i j reduce [ ( *getPathsAmount word_i ) ]
]
[
either j == ( i + 1 )
[
*change matrix i j ( pick f_block i )
]
[
intersec: intersect ( pick f_block ( j - 1 ) ) ( *pick matrix i ( j - 1 ) )
*change matrix i j intersec
]
]
]
]
На основе полученной матрицы строится новая, отражающая значения Pl и Pr, а также Dl и Dr, по приведенным выше формулам. В результате образуется один или несколько шаблонов-кандидатов. По критерию оценки (1) выбирается значимый шаблон:
paths_num_cur2: length? ( *pick matrix end/x end/y )
either ( end/x + 1 ) == end/y
[
paths_num_prev2: first *pick matrix ( end/x + 1 ) end/y
]
[
paths_num_prev2: length? ( *pick matrix ( end/x + 1 ) end/y )
]
P2: *pick block_P end/x end/x
*calcB paths_num_cur2 paths_num_prev2 P2
В результате шаблон-кандидат, удовлетворительно прошедший оценку (1), определяется как значимый и возвращается на выходе из процедуры MEX.
3.4 Выявление классов эквивалентности
Параллельно с поиском значимого пути программа пытается обнаружить во время прохождения вдоль путей графа составляющих классы эквивалентности. Под классом эквивалентности понимается набор вершин, которые являются взаимозаменяемыми в данном контексте (на разных путях есть последовательность вершин, имеющая одинаковый префикс, суффикс и отличающаяся только одним словом – слотом). В соответствии с рисунком 8, определяется окно длины L и в некоторой позиции этого окна – слот – позиция, в которой несколько путей могут ветвиться на разные вершины.
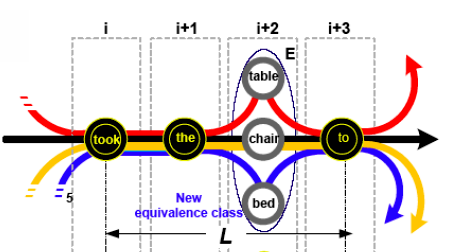
Рисунок 8 - Определение класса эквивалентности
В качестве тестового материала были взяты предложения из корпуса CHILDES, представляющего собой детские высказывания и реплики, адресованные родителями детям, вида «Cindy thinks that George thinks that to read is tough. Cindy thinks that George thinks that to read is tough. That the bird is eager to read bothers the dog…», а также фрагменты текстов Национального корпуса русского литературного языка и корпуса газетных статей.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
