

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Алфавитный подход к понятию информация.
Алфавитный подход основан на том, что всякое сообщение можно закодировать с помощью конечной последовательности символов некоторого алфавита. С позиций computer science носителями информации являются любые последовательности символов, которые хранятся, передаются и обрабатываются с помощью компьютера. Согласно Колмогорову, информативность последовательности символов не зависит от содержания сообщения, а определяется минимально необходимым количеством символов для ее кодирования. Алфавитный подход является объективным, т. е. он не зависит от субъекта, воспринимающего сообщение. Смысл сообщения учитывается на этапе выбора алфавита кодирования либо не учитывается вообще. На первый взгляд определения Шеннона и Колмогорова кажутся разными, тем не менее, они хорошо согласуются при выборе единиц измерения.
Количество информации - это мера уменьшения неопределенности.
1 БИТ – такое кол-во информации, которое содержит сообщение, уменьшающее неопределенность знаний в два раза. БИТ - это наименьшая единица измерения информации
Единицы измерения информации:
1байт = 8 бит
1Кб (килобайт) = 210 байт = 1024 байт
1Мб (мегабайт) = 210 Кб = 1024 Кб
1Гб (гигабайт) = 210 Мб = 1024 Мб
Рассмотрим, как можно подсчитать количество информации в сообщении, используя содержательный подход.
Пусть в некотором сообщении содержатся сведения о том, что произошло одно из N равновероятных событий. Тогда количество информации х, заключенное в этом сообщении, и число событий N связаны формулой: 2x = N. Решение такого уравнения с неизвестной х имеет вид: x=log2N. То есть именно такое количество информации необходимо для устранения неопределенности из N равнозначных вариантов. Эта формула носит название формулы Хартли. Получена она в 1928 г. американским инженером Р. Хартли. Процесс получения информации он формулировал примерно так: если в заданном множестве, содержащем N равнозначных элементов, выделен некоторый элемент x, о котором известно лишь, что он принадлежит этому множеству, то, чтобы найти x, необходимо получить количество информации, равное log2N.
Если N равно целой степени двойки (2, 4, 8, 16 и т. д.), то вычисления легко произвести "в уме". В противном случае количество информации становится нецелой величиной, и для решения задачи придется воспользоваться таблицей логарифмов либо определять значение логарифма приблизительно (ближайшее целое число, большее ).
При вычислении двоичных логарифмов чисел от 1 до 64 по формуле x=log2N поможет следующая таблица.
N | x | N | x | N | x | N | x |
1 | 0,00000 | 17 | 4,08746 | 33 | 5,04439 | 49 | 5,61471 |
2 | 1,00000 | 18 | 4,16993 | 34 | 5,08746 | 50 | 5,64386 |
3 | 1,58496 | 19 | 4,24793 | 35 | 5,12928 | 51 | 5,67243 |
4 | 2,00000 | 20 | 4,32193 | 36 | 5,16993 | 52 | 5,70044 |
5 | 2,32193 | 21 | 4,39232 | 37 | 5,20945 | 53 | 5,72792 |
6 | 2,58496 | 22 | 4,45943 | 38 | 5,24793 | 54 | 5,75489 |
7 | 2,80735 | 23 | 4,52356 | 39 | 5,28540 | 55 | 5,78136 |
8 | 3,00000 | 24 | 4,58496 | 40 | 5,32193 | 56 | 5,80735 |
9 | 3,16993 | 25 | 4,64386 | 41 | 5,35755 | 57 | 5,83289 |
10 | 3,32193 | 26 | 4,70044 | 42 | 5,39232 | 58 | 5,85798 |
11 | 3,45943 | 27 | 4,75489 | 43 | 5,42626 | 59 | 5,88264 |
12 | 3,58496 | 28 | 4,80735 | 44 | 5,45943 | 60 | 5,90689 |
13 | 3,70044 | 29 | 4,85798 | 45 | 5,49185 | 61 | 5,93074 |
14 | 3,80735 | 30 | 4,90689 | 46 | 5,52356 | 62 | 5,95420 |
15 | 3,90689 | 31 | 4,95420 | 47 | 5,55459 | 63 | 5,97728 |
16 | 4,00000 | 32 | 5,00000 | 48 | 5,58496 | 64 | 6,00000 |
При алфавитном подходе, если допустить, что все символы алфавита встречаются в тексте с одинаковой частотой (равновероятно), то количество информации, которое несет каждый символ (информационный вес одного символа), вычисляется по формуле: x=log2N, где N - мощность алфавита (полное количество символов, составляющих алфавит выбранного кодирования). В алфавите, который состоит из двух символов (двоичное кодирование), каждый символ несет 1 бит (21) информации; из четырех символов - каждый символ несет 2 бита информации(22); из восьми символов - 3 бита (23) и т. д. Один символ из алфавита мощностью 256 (28) несет в тексте 8 битов информации. Как мы уже выяснили, такое количество информации называется байт. Алфавит из 256 символов используется для представления текстов в компьютере. Один байт информации можно передать с помощью одного символа кодировки ASCII. Если весь текст состоит из K символов, то при алфавитном подходе размер содержащейся в нем информации I определяется по формуле: ![]() , где x - информационный вес одного символа в используемом алфавите.
, где x - информационный вес одного символа в используемом алфавите.
Например, книга содержит 100 страниц; на каждой странице - 35 строк, в каждой строке - 50 символов. Рассчитаем объем информации, содержащийся в книге.
Страница содержит 35 x 50 = 1750 байт информации. Объем всей информации в книге (в разных единицах):
1750 x 100 = 175000 байт.
175000 / 1024 = 170,8984 Кбайт.
170,8984 / 1024 = 0,166893 Мбайт.
Вероятностный подход к измерению информации
Формулу для вычисления количества информации, учитывающую неодинаковую вероятность событий, предложил К. Шеннон в 1948 году. Количественная зависимость между вероятностью события р и количеством информации в сообщении о нем x выражается формулой: x=log2 (1/p). Качественную связь между вероятностью события и количеством информации в сообщении об этом событии можно выразить следующим образом - чем меньше вероятность некоторого события, тем больше информации содержит сообщение об этом событии.
Рассмотрим некоторую ситуацию. В коробке имеется 50 шаров. Из них 40 белых и 10 черных. Очевидно, вероятность того, что при вытаскивании "не глядя" попадется белый шар больше, чем вероятность попадания черного. Можно сделать заключение о вероятности события, которые интуитивно понятны. Проведем количественную оценку вероятности для каждой ситуации. Обозначим pч - вероятность попадания при вытаскивании черного шара, рб - вероятность попадания белого шара. Тогда: рч=10/50=0,2; рб40/50=0,8. Заметим, что вероятность попадания белого шара в 4 раза больше, чем черного. Делаем вывод: если N - это общее число возможных исходов какого-то процесса (вытаскивание шара), и из них интересующее нас событие (вытаскивание белого шара) может произойти K раз, то вероятность этого события равна K/N. Вероятность выражается в долях единицы. Вероятность достоверного события равна 1 (из 50 белых шаров вытащен белый шар). Вероятность невозможного события равна нулю (из 50 белых шаров вытащен черный шар).
Количественная зависимость между вероятностью события р и количеством информации в сообщении о нем x выражается формулой: ![]() . В задаче о шарах количество информации в сообщении о попадании белого шара и черного шара получится:
. В задаче о шарах количество информации в сообщении о попадании белого шара и черного шара получится: ![]() .
.
Рассмотрим некоторый алфавит из m символов: ![]() и вероятность выбора из этого алфавита какой-то i-й буквы для описания (кодирования) некоторого состояния объекта. Каждый такой выбор уменьшит степень неопределенности в сведениях об объекте и, следовательно, увеличит количество информации о нем. Для определения среднего значения количества информации, приходящейся в данном случае на один символ алфавита, применяется формула
и вероятность выбора из этого алфавита какой-то i-й буквы для описания (кодирования) некоторого состояния объекта. Каждый такой выбор уменьшит степень неопределенности в сведениях об объекте и, следовательно, увеличит количество информации о нем. Для определения среднего значения количества информации, приходящейся в данном случае на один символ алфавита, применяется формула ![]() .
.
Пример. Пусть при бросании несимметричной четырехгранной пирамидки вероятности выпадения граней будут следующими: p1=1/2, p2=1/4, p3=1/8, p4=1/8, тогда количество информации, получаемое после броска, можно рассчитать по формуле:
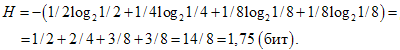
Для симметричной четырехгранной пирамидки количество информации будет: H=log24=2(бит).
Заметим, что для симметричной пирамидки количество информации оказалось больше, чем для несимметричной пирамидки. Максимальное значение количества информации достигается для равновероятных событий.
Задача1: Какое количество информации будет содержать зрительное сообщение о цвете вынутого шарика, если в непрозрачном мешочке находится 50 белых, 25красных, 25 синих шариков
1) всего шаров 50+25+25=100

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
