

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Определение 2. Если ![]() не может быть редуцировано на
не может быть редуцировано на ![]() , то отношение эквивалентности
, то отношение эквивалентности ![]() является независимым, в противном случае
является независимым, в противном случае ![]() является взаимосвязанным.
является взаимосвязанным.
Определение 3. Пусть ![]() - информационная система. Если
- информационная система. Если ![]() удовлетворяет условию
удовлетворяет условию ![]() , и
, и ![]() - независимое, то
- независимое, то ![]() называется редукцией R.
называется редукцией R.
Верхняя, нижняя аппроксимации и границы неточного множества
Определение 4. База знаний ![]() , записанная как
, записанная как ![]() - установленная нижняя аппроксимация
- установленная нижняя аппроксимация ![]() , а
, а ![]() - положительная область определения R,
- положительная область определения R, ![]() , которая состоит из элементов
, которая состоит из элементов ![]() , полностью принадлежащих
, полностью принадлежащих ![]() . То есть, элементы
. То есть, элементы ![]() , которые является положительной областью определения R могут быть корректно классифицированы.
, которые является положительной областью определения R могут быть корректно классифицированы.
Определение 5. База знаний ![]() , записанная как
, записанная как ![]() - верхняя аппроксимация
- верхняя аппроксимация ![]() .
. ![]() это также некоторая коллекция, которая составлена из элементов U, которые могут содержатся в X. Она составлена из элементов, классы эквивалентности которых для
это также некоторая коллекция, которая составлена из элементов U, которые могут содержатся в X. Она составлена из элементов, классы эквивалентности которых для ![]() Ш пересекаются с
Ш пересекаются с ![]() .
.
Для ![]() , x должен находится в одном из
, x должен находится в одном из ![]() классах эквивалентности
классах эквивалентности ![]() . Когда
. Когда ![]() Ш, некоторые элементы
Ш, некоторые элементы ![]() лежат в
лежат в ![]() . Тогда
. Тогда ![]() может быть элементом
может быть элементом ![]() , что означает -
, что означает - ![]() является элементом
является элементом ![]() . Таким образом
. Таким образом ![]() обозначает коллекцию всех возможных элементов
обозначает коллекцию всех возможных элементов ![]() в наборе
в наборе ![]() . Это c большой вероятностью будут правильно классифицированные элементы.
. Это c большой вероятностью будут правильно классифицированные элементы.
Пример: прогнозирование спроса на уголь
Таблица 5. Факторы, влияющие на спрос угля
Рост ВВП |
Цена покупки горючего |
Скорость притока населения из сельской местности в города |
Доля угля в потреблении энергии |
Производство угля |
Повышение или понижение спроса на импортный уголь |
Число рабочих, занятых в угольной промышленности |
Уровень заработной платы в угольной промышленности в пересчете на одного рабочего |
Инвестиции в основные средства угольной промышленности |
Рост потребления угля |
Эластичность спроса на уголь |
Потребление угля |
Скорость роста численности населения |
Уровень образования населения |
После применения метода редукции факторов, основанного на неточных множествах, оказалось что 14 факторов, указанные выше, содержат избыточную информацию, взаимно влияют друг на друга, и некоторые из них можно устранить. На следующей таблице показано 11 оставшихся факторов.
Таблица 6. Факторы, влияющие на спрос угля, после редуцирования
Рост ВВП |
Цена покупки горючего |
Скорость роста располагаемого дохода |
Доля угля в потреблении энергии |
Производство угля |
Уровень заработной платы в угольной промышленности в пересчете на одного рабочего |
Инвестиции в основные средства угольной промышленности |
Рост потребления угля |
Эластичность спроса на уголь |
Потребление угля |
Таблица 7. Результаты прогнозирования на 4 года (в млн. тонн)
Годы | 2008 | 2009 | 2010 | 2011 |
Прогнозное значение | 274472 | 281352 | 285210 | 288560 |
Литература
Р. Каллан. Основные концепции нейронных сетей. – М.: «Вильямс», 2001 – 287 с.
Z. Pawlak. Rough sets. International Journal of Parallel Programming. – 1982, 11 (5): pp. 341–356.
W. L. Charles. Training feedforward neural networks: an algorithm, giving improved generalization. Neural Networks, 1997, 10 (1): pp. 61-68.
Z. Cai, X. Ma. The forecast of coal demand based on RoughSet and BP neural network model.// Proceedings of Management and Service Science (MASS) 2010 International Conference. pp. 1-4.
Метод Бокса-Дженкинса (ARIMA)
В середине 90-х годов прошлого века был разработан принципиально новый и достаточно мощный класс алгоритмов для прогнозирования временных рядов. Большую часть работы по исследованию методологии и проверке моделей была проведена двумя статистиками, Г. (G. E.P. Box) и (G. M. Jenkins). С тех пор построение подобных моделей и получение на их основе прогнозов иногда называться методами Бокса-Дженкинса. В это семейство входит несколько алгоритмов, самым известным и используемым из них является алгоритм ARIMA. Он встроен практически в любой специализированный пакет для прогнозирования. В классическом варианте ARIMA не используются независимые переменные. Модели опираются только на информацию, содержащуюся в предыстории прогнозируемых рядов, что ограничивает возможности алгоритма. В методологии ARIMA не предполагается какой-либо четкой модели для прогнозирования данной временной серии. Задается лишь общий класс моделей, описывающих временной ряд и позволяющих как-то выражать текущее значение переменной через ее предыдущие значения. Затем алгоритм, подстраивая внутренние параметры, сам выбирает наиболее подходящую модель прогнозирования.
Часто модель записывается как ARIMA(p, d, q), где p, d и q обозначают порядки соответствующих подмоделей: авторегрессионную модель порядка p, интегрированную модель порядка d и модель со скользящим средним порядка q.
Пусть задана серия временных данных ![]() , где t – числовой индекс, и
, где t – числовой индекс, и ![]() - вещественный ряд.
- вещественный ряд.
Тогда модель ARIMA будет иметь вид:
![]() ,
,
где L – это оператор временного лага(или смещения), ![]() - параметры авторегрессионной части модели,
- параметры авторегрессионной части модели, ![]() - параметры скользящего среднего и
- параметры скользящего среднего и ![]() - значения ошибки (остаточные члены).
- значения ошибки (остаточные члены). ![]() являются независимыми, имеющими одинаковое распределение переменными, выраженное нормальным распределением с нулевым средним.
являются независимыми, имеющими одинаковое распределение переменными, выраженное нормальным распределением с нулевым средним.
Положим, что 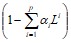 имеет унитарный корень кратности d. Тогда выражение можно переписать как:
имеет унитарный корень кратности d. Тогда выражение можно переписать как:
![]() .
.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
