

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Обзор подходов к краткосрочному и среднесрочному прогнозированию
Генетическое программирование
Генетическое программирование позволяет строить обобщенные нелинейные зависимости между различными переменными. Фактически, при соответствующем определении они могут аппроксимировать любую нелинейную функцию. Если между факторами существуют хоть какие-нибудь нелинейные соответствия, генетическое программирование может помочь их воссоздать, а построенный прогноз будет, по крайней мере, таким же точным как при использовании линейных индикаторных моделей.
Генетическое программирование можно рассматривать как расширение подхода, основанного на генетических алгоритмах: фиксированные битовые строки заменяются более гибкой структурой символьных выражений. В генетическом программировании частные решения задачи представляются как деревья с узлами и дугами. Узлы, не имеющие выходящих дуг (листы), содержат терминальные символы. Узлы с одной и более выходящей дугой содержат функции, действующие над пространством терминальных символов или других функций. Терминальные символы и функции являются важными составляющими генетической программы, т. к. они задают структуру (алфавит) генетической программы.
Множество терминальных символов обычно состоит из переменных и констант (чисел), множество функций – из различных математических функций (таких как сумма, разность, умножение, деление и др.). Размер, структура и форма решения не определены на начальном этапе и определяются посредством применения генетических операторов (кроссовер и мутация). Процесс решение задачи, таким образом, можно представить как поиск в пространстве всех возможных комбинаций символьных выражений, заданных программистом.
Кроссовер – оператор скрещивания пары особей в популяции. В генетическом программировании этот процесс представляется следующим образом: для каждой особи-дерева случайным образом выбирается поддерево, а затем под воздействием оператора особи меняются выбранными поддеревьями (см. рис. 1).
Мутация задает случайное изменение (модификацию) хромосомы. Когда говорят о генетическом программировании, то подразумевают, что в качестве хромосом выступают узлы дерева. Под воздействием мутации узел, имеющий выходящие дуги, заменяет функцию другую, случайно выбранную из алфавита, а узел без выходящих дуг меняет один терминальный символ (переменную ил и константу) на случайный другой.
Очень важным понятием в генетических алгоритмах считается функция приспособленности, иначе называемая функцией оценки. Она представляет меру приспособленности данной особи в популяции. Эта функция играет важнейшую роль, поскольку позволяет оценить степень приспособленности конкретных особей в популяции и выбрать из них наиболее приспособленные (т. е. имеющие наибольшие значения функции приспособленности) в соответствии с эволюционным принципом выживания «сильнейших» (лучше всего приспособившихся). Функция приспособленности также получила свое название непосредственно из генетики. Для задач прогнозирования часто используется функция, определяющая величину ошибки между прогнозными и фактическими данными. Поэтому в процессе работы алгоритма решается задача минимизации ошибки.
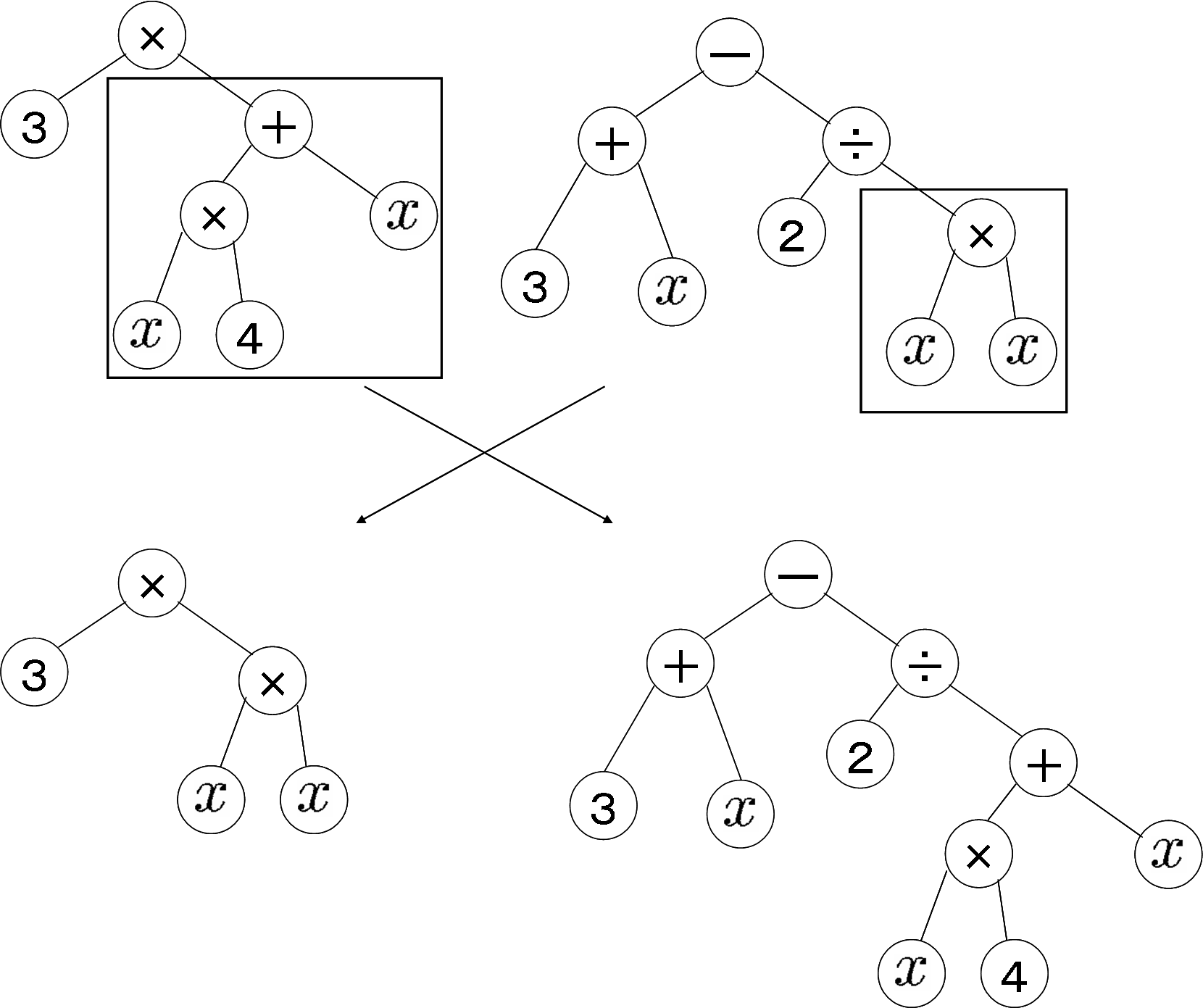
Рисунок 1. Оператор скрещивания
Пример: прогноз роста ВВП ( 2007)
В 2006 году группа исследователей из технологического университета г. Вухань построила генетический алгоритм для прогнозирования роста ВВП США, Японии и Китая. За основу они взяли данные с сайта www.econstats.com c 1980 по 2000 гг., а в качестве проверочного множества – с 2001 по 2006 год.
По каждой из стран было 10 запусков алгоритма со следующими параметрами:
- Величина популяции: 20 Максимальная глубина дерева на этапе инициализации: 4 Максимальная глубина дерева при воздействии операторов кроссовера и мутации: 10 Вероятность скрещивания: 0.9 Вероятность мутации: 0.3 Лаг по времени: 4 Метод создания начальной популяции: генерация Множество функций:
После проведения эксперимента исследователи выбрали лучшие символьные выражения, описывающие рост ВВП:
ВВП Китая (величина измерялась в долларах США):![]()
Результаты прогнозирования оказались следующими:
Таблица 1. Прогнозируемые и исходные значения ВВП Китая в млрд. долл. США по годам (2001-2006 гг.)
Год | Исходный ВВП | Прогнозируемый ВВП | Относительная ошибка (%) |
2001 | 1175.72 | 1176.43 | 0.06 |
2002 | 1270.67 | 1272.42 | 0.14 |
2003 | 1416.6 | 1370.96 | 3.22 |
2004 | 1649.39 | 1528.85 | 7.31 |
2005 | 1843.12 | 1772.03 | 3.86 |
2006 | 2040.33 | 1963.02 | 3.79 |
Таблица 2. Прогнозируемые и исходные значения ВВП США в млрд. долл. США по годам (2001-2006 гг.)
Год | Исходный ВВП | Прогнозируемый ВВП | Относительная ошибка (%) |
2001 | 10128 | 10299.55 | 1.69 |
2002 | 10487 | 10636.39 | 1.42 |
2003 | 11004 | 11022.07 | 0.16 |
2004 | 11733.5 | 11552.57 | 1.54 |
2005 | 12438.9 | 12299.59 | 1.12 |
2006 | 13152.7 | 13030.67 | 0.93 |
Таблица 3. Прогнозируемые и исходные значения ВВП Японии в млрд. долл. США по годам (2001-2006 гг.)
Год | Исходный ВВП | Прогнозируемый ВВП | Относительная ошибка (%) |
2001 | 4165.4 | 4406.41 | 5.79 |
2002 | 3978.9 | 3942.19 | 0.92 |
2003 | 4299.7 | 3775.58 | 12.19 |
2004 | 4668.4 | 3921.95 | 15.99 |
2005 | 4799.1 | 4696.4 | 2.14 |
2006 | 4897.4 | 4972.43 | 1.53 |
Помимо всего прочего исследователи заметили интересную тенденцию: в то время как функции ВВП Китая и США с течением времени показывают монотонный рост, функция ВВП Японии имеет периодические колебания на том же временном промежутке.
Литература
J. R. Koza. Genetic Programming: On the programming of Computers by Means of Natural Selection, MA, Kluwer, Boston, 2002.
http://www. /weo/V019.htm
M. Santini, A. Tettamazzi. Genetic Programming for Financial Time Series Prediction. Proceeding of EuroGP 2001, 361-370.
L. Meifang, L. Guoxin, Z. Yongxiang. Forecasting GDP Growth Using Genetic Programming. Proceedings of the Third International Conference on Natural Computation – Volume 04, IEEE Computer Society Washington DC, 2007.
Оптимизации с помощью роя частиц и машина опорных векторов
Машина опорных векторов
Метод аппроксимации функций с помощью опорных векторов является прикладным методом, основанным на теории статистического машинного обучения. Рассмотрим множество данных ![]() , где
, где ![]() - вектор входов модели,
- вектор входов модели, ![]() - фактическое значение (скалярный выход) и n – это число образцов данных. Для решения задачи нелинейной аппроксимации в терминах машины опорных векторов входы сначала с помощью нелинейных функций отображаются на пространство характеристик высокой размерности F, в котором они линейно коррелируют с выходными данными. Функция регрессии аппроксимируется следующей функцией:
- фактическое значение (скалярный выход) и n – это число образцов данных. Для решения задачи нелинейной аппроксимации в терминах машины опорных векторов входы сначала с помощью нелинейных функций отображаются на пространство характеристик высокой размерности F, в котором они линейно коррелируют с выходными данными. Функция регрессии аппроксимируется следующей функцией:
![]() (1),
(1),
Где w – вектор весов, b – константа, ![]() - обозначает функцию отображения из пространства характеристик. Задача нелинейной регрессии для пространства входов небольшой размерности преобразуется в задачу линейной регрессии в пространстве характеристик высокой размерности F.
- обозначает функцию отображения из пространства характеристик. Задача нелинейной регрессии для пространства входов небольшой размерности преобразуется в задачу линейной регрессии в пространстве характеристик высокой размерности F.
Вектор весов w и константу b из уравнения (1) можно оценить путем минимизации функции регуляризованного риска:
![]() (2)
(2)
Где 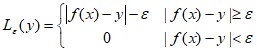 .
.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
