


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Имитационно-компьютерные системы экспериментирования
Важные средства анализа качества построенных моделей, точности получаемых с их помощью прогнозов, решения задачи выбора наилучшей модели предоставляют исследователю различные имитационно-компьютерные системы экспериментирования [2]. Среди них следует выделить метод Монте-Карло, бутстреп-метод, а также схему перекрестного анализа дееспособности модели. Сущность метода статистических испытаний (метод Монте-Карло) заключается в следующем. В компьютер закладываются все параметры анализируемой стохастической модели. Компьютер с помощью специальных датчиков случайных чисел генерирует требуемое число выборок заданного объема, которые, соответственно, интерпретируются как наблюдения, произведенные над данной моделью. Затем эти выборки используются в той статистической процедуре (в статистическом оценивании параметров анализируемой модели, в построении прогнозов), качество которой мы хотим исследовать. Наличие большого числа сгенерированных выборок заданного объема позволяет исследовать поведение интересующих выходных характеристик (оценок параметров, прогнозов), оценить их смещение и среднеквадратическую ошибку.
Бутстреп метод «тиражирования» наблюдений получил распространение в задачах статистического анализа, основанного на относительно малых выборках. Метод предлагает тиражировать уже имеющиеся в распоряжении наблюдения, генерируя их, как и в методе Монте-Карло, с помощью датчиков случайных чисел. В бутстреп-процедурах «настройка» датчиков определяется структурой и спецификой имеющейся в нашем распоряжении выборки. По имеющейся выборке строится некоторая оценка (параметрическая или непараметрическая) закона распределения анализируемой генеральной совокупности, а затем генерируются в необходимом количестве наблюдения, подчиняющиеся этому закону распределения вероятности.
Перекрестный анализ дееспособности модели состоит в реализации двух этапов:1) Все имеющиеся наблюдения Х (исходные статистические данные, результаты эксперимента) случайным образом разбиваются на две части Хоб и Хэкз. «Обучающая выборка» Хоб используется для подбора модели. 2) Каждый из вычисленных на предыдущем этапе вариантов модели верифицируется с помощью подходящего критерия на данных «экзаменующей выборки» Хэкз.
Интерпретация результатов
Интерпретация результатов статистического анализа и формулировка на их основе практических рекомендаций является важнейшим неформализованным этапом экономико–социологического исследования. Правильное и грамотное проведение этого завершающего этапа исследований характеризует профессионализм и «классность» специалиста.
Лабораторная работа №1
«Исследование экономической или социологической системы
с использованием методов дисперсионного анализа»
Фактор – это источник изменения (вариации) исследуемой величины (отклика). Основная задача дисперсионного анализа состоит в получении модели, включающей возможно большее количество значимых факторов, значимых взаимодействий факторов, и не включающей лишних (незначимых) факторов [5]. Исходная модель составляется на основе априорных знаний об объекте исследования. Затем оценивается значимость факторов, незначимые факторы исключаются. Возможно добавление новых факторов, взаимодействий, изменение количества и значений уровней факторов и т. д. Методы дисперсионного анализа применимы только для объектов, для которых все факторы качественные, то есть каждый фактор может принимать только фиксированное число значений. Возможное значение фактора называется уровнем фактора. Уровни можно пронумеровать (начиная с 1). Таким образом, описывая эксперимент, можно указать на каком уровне находился каждый фактор. Модель дисперсионного анализа в общем виде описывается уравнением:
y=Xи + е, (1.1)
где y – N-вектор значений отклика,
N – количество проведенных экспериментов;
yi – значение отклика в i-ом эксперименте;
и – p-вектор неизвестных параметров;
X – (N x p)-матрица планирования экспериментов ранга r ;
е - вектор ошибок, имеющий нормальное распределение с нулевым математическим ожиданием и дисперсионной матрицей у2I : е ~ N (0, у 2I).
Матрица планирования X состоит из нулей и единиц: i-му эксперименту соответствует i-ая строка матрицы X. Обозначим число уровней j-го фактора Ij. Если в модели не учитываются взаимодействия между факторами, то p=1+I1+I2+…+Im. , где m - количество факторов. Ранг матрицы X равен r=1+(I1-1)+(I2-1)+…+(Im -1).
Часто бывает удобно обозначить параметры, относящиеся в разным факторам разными буквами: б s (s=1,…, I1) – параметры, отражающие влияние уровней первого фактора; в s (s=1,…, I2) – параметры, отражающие влияние уровней второго фактора и. т.д; м – параметр, отражающий влияние аддитивной постоянной.
Предположим, что в эксперименте участвуют 2 фактора. Указывая в уравнении только те элементы матрицы X, которые соответствуют уровням факторов данного эксперимента, получаем двухфакторную модель следующего вида: ![]() ,
,
где i=1,…, I1; j=1,…, I2; k=1,…, K (число повторных экспериментов в ячейке плана).
Для вычисления оценок вектора параметров методом наименьших квадратов необходимо решить задачу:![]() , что приводит к системе нормальных уравнений:
, что приводит к системе нормальных уравнений: ![]() .
.
Решение данной системы позволяет найти МНК-оценку вектора параметров в общем виде ![]() , где
, где ![]() , z – произвольный вектор,
, z – произвольный вектор, ![]() - обобщенная обратная матрица. Данная оценка является смещенной.
- обобщенная обратная матрица. Данная оценка является смещенной.
Функции, допускающие оценку. Функция ![]() , где q - произвольный вектор, называется функцией, допускающей оценку (ФДО), поскольку ее оценка будет несмещенной.
, где q - произвольный вектор, называется функцией, допускающей оценку (ФДО), поскольку ее оценка будет несмещенной.
Проверка гипотез.
Гипотеза о незначимости j-го фактора записывается следующим образом: H0: иd+1 = иd+2 =… =Обозначим: Щ – исходные предположения о модели;
щ – к исходным предположениям добавилась гипотеза H0, то есть получили модель y= Xщ ищ + ещ. Матрица Xщ получена из матрицы X исключением столбцов, соответствующих j-му фактору, ранг Xщ обозначим rщ. F-статистика вычисляется по формуле:
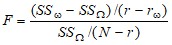 , (1.2)
, (1.2)
где ![]() ; (1.3)
; (1.3)
![]() . (1.4)
. (1.4)
Если вычисленное значение F-статистики оказывается больше табличного значения F-распределения ![]() (г1= r - rщ, г2 = N - r ), то гипотеза отвергается – фактор считается значимым.
(г1= r - rщ, г2 = N - r ), то гипотеза отвергается – фактор считается значимым.
2) В общем виде проверяемая гипотеза записывается следующим образом: H0: KTи = b0, где KT - (kxp)-матрица полного строчного ранга k. KTи - вектор, состоящий из ФДО. F-статистика вычисляется по формуле:
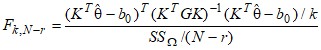 ,
,
где ![]() . Если вычисленное значение F-статистики оказывается больше табличного значения F-распределения
. Если вычисленное значение F-статистики оказывается больше табличного значения F-распределения ![]() , то гипотеза отвергается. Данный метод можно использовать для определения значимости ФДО.
, то гипотеза отвергается. Данный метод можно использовать для определения значимости ФДО.
3) S-метод множественного сравнения. Если описанный выше метод 2 показал, что гипотеза не принимается, т. е. ФДО значимы, то можно проверить, какая (какие) из них значимы).
Обозначим: ![]() – одна из ФДО, проверявшихся методом 2. Проверим гипотезу
– одна из ФДО, проверявшихся методом 2. Проверим гипотезу ![]() . Вычислим границы интервала:
. Вычислим границы интервала:
![]() , где
, где ![]() - оценка ФДО;
- оценка ФДО; ![]() ;
; 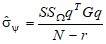 .
.
Если 0 попадает в этот интервал, то гипотеза H0 не отвергается.
Подобные вычисления можно провести для каждой из k ФДО.
Проверка адекватности модели.
Для экспериментов с повторными наблюдениями в ячейках плана целесообразно проводить проверку гипотезы об адекватности выбранной модели исследуемой совокупности экспериментальных данных. Оценку дисперсии ошибки опыта проводят по повторным опытам. Сумму квадратов SSЩ представляют в виде

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
