


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
с использованием методов регрессионного анализа»
Многие важные связи в экономике являются нелинейными. Примерами такого рода регрессионных моделей являются производственные функции (зависимости, существующие между объемом произведенной продукции и основными факторами производства), функции спроса (зависимости, существующие между спросом на какой-либо вид товара или услуг и доходом или ценами). Если в результате анализа предметной области эконометрист пришел к выводу, что регрессионная зависимость E[y] = f (x1, x2,…,xm;и)
носит нелинейный характер, то он вначале пытается подобрать такие преобразования анализируемых переменных y, x1, x2,,…,xm, которые позволили бы представить искомую зависимость в виде линейного соотношения между преобразованными переменными.
Пример [2]. Достаточно широкий класс экономических показателей характеризуется приблизительно постоянным темпом относительного прироста по времени. Этому соответствует следующая форма зависимости этого показателя (y) от времени (x): ![]() . Если пренебречь влиянием случайного остаточного компонента е (т. е. положить е = 0), то непосредственные расчеты дают:
. Если пренебречь влиянием случайного остаточного компонента е (т. е. положить е = 0), то непосредственные расчеты дают: ![]() , так что относительный прирост y за единицу времени определяется выражением
, так что относительный прирост y за единицу времени определяется выражением![]() (в долях y). Переход к новой переменной
(в долях y). Переход к новой переменной ![]() позволяет свести исследуемую зависимость к линейному виду:
позволяет свести исследуемую зависимость к линейному виду: ![]() , где
, где ![]() . Располагая наблюдениями
. Располагая наблюдениями ![]() Т и формируя вектор
Т и формируя вектор ![]() Т, с помощью МНК можно построить оценки
Т, с помощью МНК можно построить оценки ![]() и
и ![]() параметров
параметров ![]() и
и ![]() , а затем получить оценку
, а затем получить оценку ![]() для параметра
для параметра ![]() исходного уравнения.
исходного уравнения.
Подбор линеаризующего преобразования можно производить методом Бокса-Кокса либо действуя методом «проб и ошибок»: последовательно построить по имеющимся статистическим данным набор линеаризуемых моделей, а затем выбрать из них наилучшую в смысле некоторого критерия качества (например, коэффициента детерминации) [2].
В данной работе, будем использовать только линейные по параметрам регрессионные модели, которые в общем виде описываются уравнением:
Y=Xи + е, (2.1)
где Y – N-вектор значений отклика,
N – количество проведенных экспериментов;
yi – значение отклика в i-ом эксперименте;
и – r-вектор неизвестных параметров;
X – (N x r)-матрица значений регрессоров ранга r ;
е - вектор ошибок, е ~ N (0, у2I).
Регрессором может быть аддитивная постоянная, экзогенная переменная (фактор), некоторая детерминированная известная функция от одного или нескольких факторов, временной лаг от фактора. Примеры моделей линейных по параметрам:
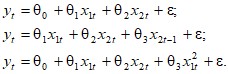
Для вычисления оценок вектора параметров методом наименьших квадратов необходимо решить задачу:![]() , что приводит к системе нормальных уравнений:
, что приводит к системе нормальных уравнений: ![]() .
.
Решение данной системы позволяет найти МНК-оценку вектора параметров ![]() , которая является несмещенной и имеет минимальную дисперсию среди других оценок.
, которая является несмещенной и имеет минимальную дисперсию среди других оценок.
Линейные регрессионные модели с переменной структурой рассматриваются в ситуациях, когда в ходе сбора исходных статистических данных имеет место косвенное воздействие (во времени или пространстве) некоторых качественных факторов (сопутствующих переменных), в результате которого происходят скачкообразные сдвиги в структуре анализируемых линейных связей. Прием введения в анализируемую линейную модель регрессии так называемых фиктивных переменных (“переменных - манекенов”), отражающих влияние на исследуемый результирующий показатель Y сопутствующих качественных переменных, используется обычно при работе с неоднородными (в регрессионном смысле) исходными статистическими данными. Например, исследуются расходы на приобретение одежды в зависимости от сезона (сопутствующая качественная переменная – сезон). Введение фиктивных переменных оказывается удобным и выгодным по меньшей мере в двух отношениях:
- статистическая надежность (точность) получаемых при этом оценок искомых параметров будет выше той, которую мы бы имели, оценивая эти коэффициенты отдельно по каждой однородной выборке; в ходе построения регрессионной модели с фиктивными переменными мы получаем возможность одновременно проверять гипотезы о наличии или отсутствии статистически значимого влияния сопутствующих переменных на структуру анализируемой модели.
Учет влияния сопутствующих переменных на структуру модели осуществляют путем введения в правую часть регрессионного уравнения переменных, которые могут принимать значения 0 или 1 аналогично тому, как это делается в дисперсионном анализе. Модель с сопутствующими переменными в матричных обозначениях имеет вид (ковариационная модель [11]):
Y = X в + Z г + е, (2.2)
где X – (N x m)- матрица исследуемых регрессоров,
Z – (N x k)- матрица сопутствующих переменных,
е - вектор ошибок, е ~ N (0, у2I).
Для анализа модели (2.2) можно предложить два варианта использования метода наименьших квадратов:
1.Чтобы воспользоваться пакетом для дисперсионного анализа необходимо m регрессоров представить как m факторов с числом уровней равным 1. Сопутствующие переменные рассматриваются как обычные качественные факторы.
2. Матрицу сопутствующих переменных Z заменяем матрицей полного столбцового ранга ![]() , используя подходящий метод репараметризации: (а) вычеркиваем линейно зависимые столбцы из подмножества столбцов, относящихся к одному качественному фактору; (б) заменить столбцы, относящиеся к одному качественному фактору, коэффициентами при параметрах линейно независимых функций, допускающих оценку. Далее имеем дело с матрицей полного столбцового ранга [X |
, используя подходящий метод репараметризации: (а) вычеркиваем линейно зависимые столбцы из подмножества столбцов, относящихся к одному качественному фактору; (б) заменить столбцы, относящиеся к одному качественному фактору, коэффициентами при параметрах линейно независимых функций, допускающих оценку. Далее имеем дело с матрицей полного столбцового ранга [X | ![]() ]. Модель
]. Модель
Y = [X | ![]() ] [в Т |
] [в Т | ![]() Т]Т + е (2.3)
Т]Т + е (2.3)
является обычной регрессионной моделью, где ![]() – преобразованный вектор параметров, соответствующий сопутствующим переменным (ФДО). Для анализа модели (2.3) можно использовать любой пакет программ для регрессионного анализа.
– преобразованный вектор параметров, соответствующий сопутствующим переменным (ФДО). Для анализа модели (2.3) можно использовать любой пакет программ для регрессионного анализа.
Пример. Исследовали протребление некоего напитка (в литрах) в зависимости от дохода (в рублях) и пола. Собранные данные о пяти потребителях представлены в табл. 2.
Таблица 2
Сведения о потреблении напитка
Номер потребителя | Пол потребителя | Доход потребителя | Объем потребления |
1 | мужчина | 2000 | 20 |
2 | мужчина | 1050 | 21 |
3 | женщина | 900 | 15 |
4 | мужчина | 5000 | 10 |
5 | женщина | 10000 | 4 |
Матрицы в уравнениях (2.2) и (2.3) имеют вид:
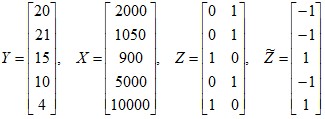 ,
, 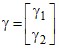 .
.
Вектор в состоит из одного элемента, фиктивная переменная изменяется на двух уровнях, для репараметризации была использована ФДО ![]() .
.
Вернемся к рассмотрению регрессионной модели вида (2.1).
Проверка гипотез. В общем виде проверяемая гипотеза записывается следующим образом: H0: KT и = b0, где KT - (k x r)-матрица полного строчного ранга k. F-статистика вычисляется по формуле:
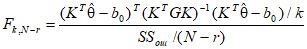 ,
,

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
