


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ОБ ОДНОЙ МАТЕМАТИЧЕСКОЙ МОДЕЛИ ЭКОНОМИЧЕСКОЙ СИСТЕМЫ ВО ВЬЕТНАМЕ.
Нгуен Ван Дык
Иркутский государственный технический университет, г. Иркутск
Научный руководитель –
Быстрое и стабильное экономическое развитие всех стран – это их задачи, решения которых может решить много проблем: увеличение уровни жизнеобеспечения, снижения бедности и безработицы, повышение благосостояния народа. Экономическое развитие Вьетнама – это необходимое условие для того, чтобы Вьетнам будет стать промышленной страной в 2020г. и стремится к уровню мировой экономике.
После исследования экономической системы многих стран можно сказать, что бы хорошо анализировать и прогнозировать её необходимо построить математическую модель экономики своей страны.
Наиболее перспективным направлением математического моделирования, отвечающим сформулированным выше требованиям, как в теоретическом, так и в практическом аспектах, является имитационное моделирование, которое обеспечивает возможности наиболее адекватного отображения процессов функционирования и развития как отдельных экономических подсистем, так и экономических систем в целом.
Известно, что применение математико-статистических методов в различного рода технико-экономических исследованиях открывает возможности для более глубокого экономического анализа и решения сложных задач. В частности, в процессе моделирования все чаще используются математико-статистические методы отбора значимых переменных (факторов).
В настоящее время в литературе отсутствует общепризнанная классификация математико-статистических методов отбора значимых переменных, но условно их можно разделить на следующие группы:
Одним из возможных путей решения задачи может быть использование метода регрессионного анализа и метод наименьших квадратов. Применение данных методов позволит объяснять зависимость среднего значения какой либо случайной величины от некоторой другой величины или нескольких величин. Степень тесноты этой зависимости можно определить по коэффициенту корреляции в случае линейной связи и по корреляционному отношению в случае криволинейной связи.
Множественная регрессия имеет уравнение вида:
![]()
![]() (1)
(1)
где ![]()
![]() – свободный коэффициент;
– свободный коэффициент;
![]()
![]() – коэффициент наклона регрессии;
– коэффициент наклона регрессии;
Y – функция отклика или объясняемая переменная;
![]()
![]() – объясняющие переменные.
– объясняющие переменные.
Значения ![]()
![]() – неизвестны и оцениваются на основе имеющейся информации в виде рядов
– неизвестны и оцениваются на основе имеющейся информации в виде рядов ![]()
![]() и
и ![]()
![]() . Оценка коэффициентов регрессии находятся по методу наименьших квадратов. По определению оценки, методом наименьших квадратов минимизируют сумму квадратов отклонений.
. Оценка коэффициентов регрессии находятся по методу наименьших квадратов. По определению оценки, методом наименьших квадратов минимизируют сумму квадратов отклонений.
![]()
![]() (2)
(2)
Используя в нашей задаче получается, что
X1 – Население (тысяча человек);
X2 – Инвестиция (миллиард донгов);
X3 – Количество выпускников из вузов (тысяча человек);
Y – ВВП (миллиард донгов).
(1) => ![]()
![]() (3)
(3)
(2) => ![]()
![]() (4)
(4)
Информация имеет вид матрицы:
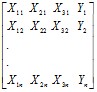
n – число измерений.
Можно найти ![]()
![]() путем решения системы уравнения.
путем решения системы уравнения.
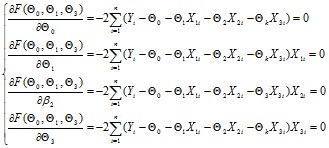 (5)
(5)
?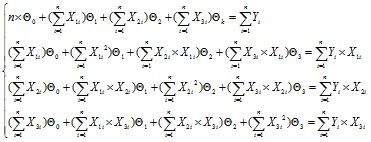 (6)
(6)
Это линейная система уравнения первого порядка с ![]()
![]() .
.
Как характеристику адекватности регрессии данным используют следующие коэффициенты
- коэффициент детерминации
При статистике получается таблица данных, показана на таблице 1:
Видно, что факторы X1, X2, X3 состоят в разных единицах (X1(тысяча человек) , X2(миллиард донгов), X3(тысяча человек)). Поэтому, в частности обычно не работают с истинными значениями факторов, а проводят предварительно операцию кодирования факторов, представляющую собой линейное преобразование факторного пространства.
Для осуществления операции кодирования необходимо прежде всего выбрать исходную область экспериментирования, т. е. задать верхние и нижние пределы изменения каждого фактора в ходе эксперимента Xiмакс, Xiмин. Тогда операция кодирования сводиться к переносу начала координат факторного пространства в точку с координатами X1ср, X2 ср, X3ср, где:
Таблица 1 – Данные факторов и отклика
Год | Население | Инвестиция (Миллиард донгов) | Количество выпускников из вузов (тыс.) | ВВП (Миллиард донгов) |
1995 | 71995,5 | 72447 | 58,5 | 228892 |
1996 | 73156,7 | 87394 | 78,5 | 272036 |
1997 | 74306,9 | 108370 | 74,1 | 313623 |
1998 | 75456,3 | 117134 | 103,4 | 361017 |
1999 | 76596,7 | 131171 | 113,6 | 399942 |
2000 | 77635,4 | 151183 | 162,5 | 441646 |
2001 | 78685,8 | 170496 | 168,9 | 481295 |
2002 | 79727,4 | 200145 | 166,8 | 535762 |
2003 | 80902,4 | 239246 | 165,7 | 613443 |
2004 | 82031,7 | 290927 | 195,6 | 713071 |
2005 | 82749,2 | 343135 | 210,9 | 914000 |
2006 | 83311,2 | 404712 | 232,5 | 1061600 |
2007 | 84218,5 | 532093 | 234,0 | 1246800 |
2008 | 85118,7 | 616735 | 222,7 | 1616000 |
2009 | 86025 | 708826 | 246,6 | 1809100 |
2010 | 86932,5 | 830278 | 318,4 | 2157800 |
2011 | 87840 | 877850 | 398,2 | 2779900 |
2012 | 88772,9 | 989300 | 490 | 3245400 |
![]() , (9)
, (9)
и выбору для каждого фактора нового масштаба, такого, что значению Xiмин будет соответствовать -1, а Xiмакс - +1. Факторы в новом масштабе xi, или, как мы их будем дальше называть, кодированные значения факторов, связаны с факторами в исходном натуральном масштабе (с истинными значениями факторов) очевидными соотношениями.
![]()
![]() (10)
(10)
После кодирования данные получаются как на таблице 2:
С помощью метода наименьших квадратов получается регрессионная модель.
С оригинальной информацией:
![]()
![]() (11)
(11)
- R2: 0.9945 Ошибка аппроксимации = 6%
Таблица 2 – Кодированные данные
Год | Население | Инвестиция | Количество выпускников из вузов | ВВП (Миллиард донгов) |
1995 | -1.00000000 | -1.000000000 | -1.0000000 | 228892 |
1996 | -0.86157569 | -0.967394991 | -0.9013220 | 272036 |
1997 | -0.72446267 | -0.921638474 | -0.9159585 | 313623 |
1998 | -0.58744502 | -0.902520906 | -0.7771483 | 361017 |
1999 | -0.45150023 | -0.871901166 | -0.7190746 | 399942 |
2000 | -0.32767890 | -0.828247276 | -0.5462701 | 441646 |
2001 | -0.20246284 | -0.786118385 | -0.5160529 | 481295 |
2002 | -0.07829580 | -0.721442805 | -0.5259679 | 535762 |
2003 | 0.06177358 | -0.636148870 | -0.5311615 | 613443 |
2004 | 0.19639515 | -0.523413241 | -0.3899906 | 713071 |
2005 | 0.28192688 | -0.409528027 | -0.3177526 | 914000 |
2006 | 0.34892176 | -0.275205513 | -0.2157696 | 1061600 |
2007 | 0.45707917 | 0.002660187 | -0.2086874 | 1246800 |
2008 | 0.56439019 | 0.187296110 | -0.2620397 | 1616000 |
2009 | 0.67242839 | 0.388181093 | -0.1491974 | 1809100 |
2010 | 0.78060963 | 0.653113422 | 0.1898017 | 2157800 |
2011 | 0.88879087 | 0.756885782 | 0.5665722 | 2779900 |
2012 | 1.00000000 | 1.000000000 | 1.0000000 | 3245400 |
С кодированной информацией
![]()
![]() (12)
(12)
- R2: 0.9945 Ошибка аппроксимации = 6%
Зависимость между ВВП и входными переменными показана на рисунке 1
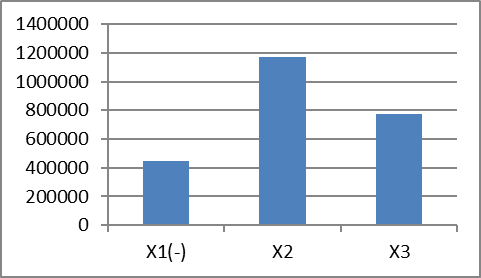
Рисунок 1 – Зависимость между ВВП и входными переменными
Из таблиц 1, 2 и рисунка 1 можно сделать вывод того, что на ВВП согласно выявлено, что наиболее существенным фактором для улучшения ВВП является фактором 2 (инвестиции).
В настоящей статье представлена математическая модель экономической системы Вьетнама. Дальнейшее исследование предполагает многооткликовые регрессионные модели. Изложим вначале некоторые известные результаты для случая одновременного измерения нескольких выходных величин.
Список литературы:
татистический анализ временных рядов / Т. Андерсон. – М.: Мир, 1976. – 760 с. Браверман Э. М., Мучник методы обработки эмпириче-ских данных. – М.: Наука, 1985. – 464 с. Имитационное моделирование развития систем энергетики / -цев [и др.]. – Иркутск : Изд-во СЭИ СО АН СССР, 1988. – 196 с. Лоули Д. Факторный анализ как статистический метод / Д. Лоули, А. Максвелл. – М.: Мир, 1966. – 144 с Статистические методы планирования экстремальных экспериментов / , . – М.: Наука, 1965. – 340 с. Линейные статистические методы и их применения / С. Рао. – М.: Наука, 1968. – 548 с.