


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
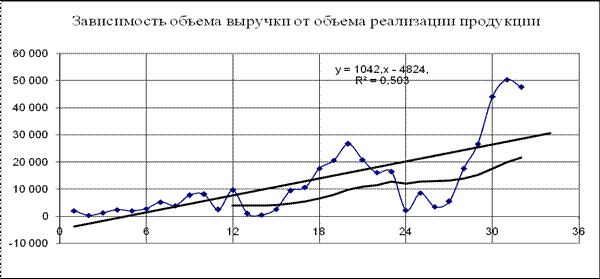
Рис. 1. Модель прогнозирования объема выручки (линейный тренд)
Но по мере насыщения рынка темпы роста объема продаж уменьшаются. Чтобы это учесть, воспользуемся более сложной зависимостью (например, логарифмической) y = 9261,l n(x) – 11232; здесь величина аппроксимации R² = 0,330 (см. рис. 2)
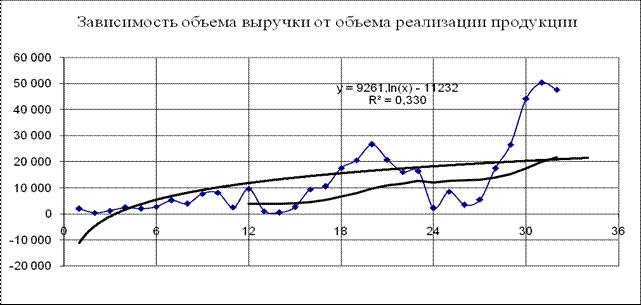
Рис.2. Модель прогнозирования объема выручки (логарифмический тренд)
На предприятии чаше всего используют при прогнозировании метод экстраполяции – определения вида зависимости на основе прошлых данных и переноса этих зависимостей на будущее. Если объемы продаж ежегодно растут на 10 % - 15 %, то предполагается, что и в 2008 году рост будет таким же. Однако, что при таком прогнозировании не учитываются текущие тенденции рынка. Поэтому экстраполяция годится только в качестве инструмента "заготовки" прогнозных значений, в том числе она используется для вычисления сезонных колебаний спроса и цены.
Известно, что зимой в любом случае строительные работы не проводятся и эта продукция становится просто невостребованной, поэтому объем производства кратковременно падает. Тем не менее, в течение последних двух лет на рынке наблюдается рост объема продаж.
Отбор показателей, с помощью которых впоследствии будет анализироваться исполнение прогноза, начинается еще во время прогнозирования и планирования выручки – тогда определяются необходимая доля рынка, цены, физический объем продаж, производительность труда, материалоемкость и т. п. На последующем этапе эти показатели корректируются и дополняются параметрами, от которых будет зависеть финансовый результат – то есть торговая наценка, оборачиваемость дебиторской задолженности, доля транспортных расходов, рентабельность и т. д. В процессе реализации прогноза эти параметры нужно постоянно отслеживать, так как их устойчивое изменение в положительную или отрицательную сторону от плановых значений будет свидетельствовать о реализации одного из прогнозных вариантов. Своевременно получая эти данные, предприятие получит возможность корректировать свои действия в соответствии с заранее разработанным прогнозом.
Чтобы прогнозирование было результативным, данные об исполнении прогноза должны использоваться для принятия решений по текущей ситуации, а не по итогам прошлого. Для этого, необходимо приобрести специализированную программу, которая позволит собирать данные, планировать их и анализировать, проводить анализ план-факт до конца отчетного периода. Иначе никакой оперативности не будет, и любой прогноз потеряет смысл, так как все возможности по его реализации будут потеряны.
Использовать при прогнозировании только математические методы, пусть даже самые сложные, неправильно, так как в этом случае не учитывается экономический смысл событий.
Как и в любой работе в прогнозировании встречаются ошибки, связаны с неправильным определением входящих параметров прогнозной модели. Так же встречаются ошибки при попытке учесть будущие изменения внешней и внутренней среды компании. Зачастую релевантные факторы выбирают упрощенно и принижают как отдельное, так и совокупное влияние таких факторов.
Построение прогнозной модели осуществлялось в несколько этапов:
1. Определялся тренд, наилучшим образом аппроксимирующий фактические данные. Критерием выбора лучшей модели выступал коэффициент детерминации, чем больше значение этого коэффициента, тем более высоким признается качество модели.
Результаты исследований показали, что значения объёма выручки имеют выраженный сезонный характер с возрастающим трендом (см. рис.3).
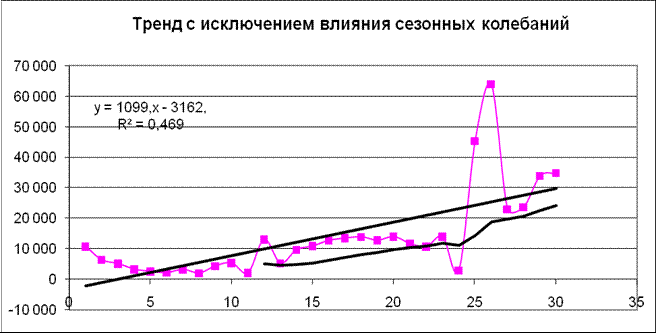
Рис.3. Модель, построенная с исключением сезонных колебаний
Применение других типов тренда (экспоненциальный, полиномиальный линейный, логарифмический) позволил получить следующую информацию (см. табл. 2 и рис. 5-8)
Таблица 2
№ п/п | Вид тренда | Уравнение модели | Коэффициент детерминации |
1. | Степенной | y = 44600x1,111 | R2 =0,589 |
1. | Экспоненциальный | y = 2E+06e0,085x | R2 =0,571 |
2 | Полиномиальный | y=31493x2-17483x+4E +06 | R2=0,505 |
3 | Линейный | y = 1E+06x - 4E+06 | R2 =0,465 |
4 | Логарифмический | y=1E+07ln(x)-1E+ 07 | R2 = 0,334 |
Более высоким качеством обладает модель с использованием степенного тренда (большее значение коэффициента детерминации R2 =0,589) (см. рис.4).
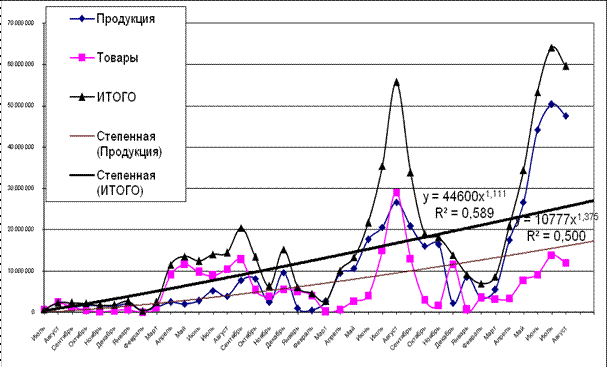
Рис. 4. Модель, построенная с использованием степенной линии тренда
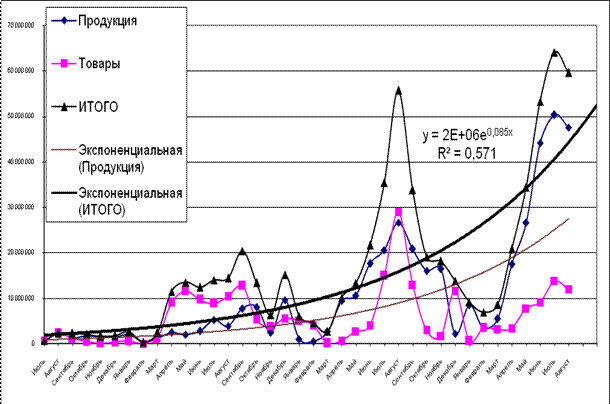
Рис. 5. Модель, построенная с использованием экспоненциальной линии тренда
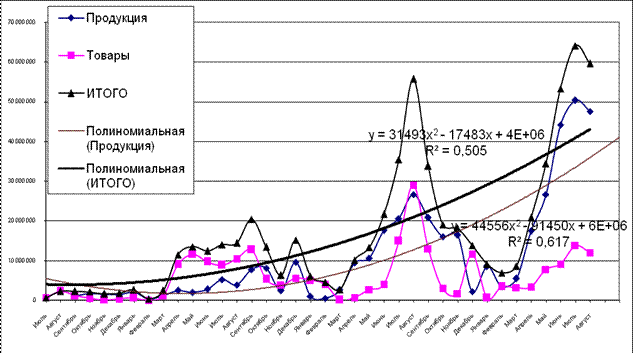
Рис. 6. Модель, построенная с использованием полиномиальной линии тренда
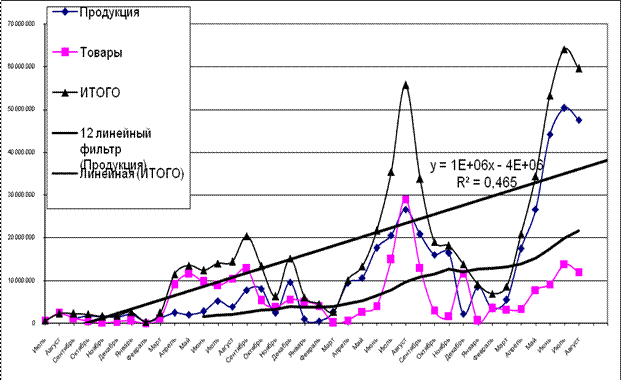
Рис. 7. Модель, построенная с использованием линейного тренда
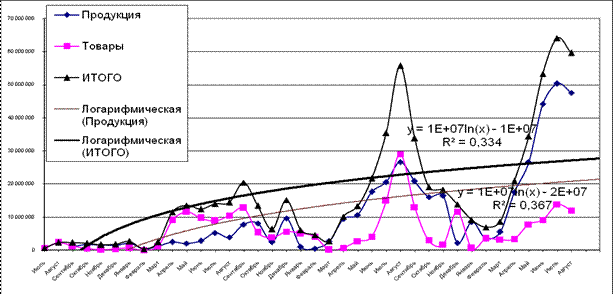
Рис. 8. Модель, построенная с использованием логарифмического тренда
Для учёта новых экономических тенденций можно порекомендовать регулярно, уточнять модель на основе мониторинга фактически полученных объёмов продаж, добавляя их или заменяя ими данные статистической базы, на основе которой строится модель. Кроме того, для повышения надёжности прогноза необходимо строить все возможные сценарии прогноза и рассчитывать доверительный интервал прогноза.
Таким образом, можно сделать следующий вывод:
- при моделировании хозяйственного процесса всегда необходимо строить несколько моделей, чтобы сравнить результаты; необходим дополнительный анализ внешней среды для построения более адекватной модели.
- тактический и стратегический анализ сильно отличаются. И если при построении прогноза на 1 год можно воспользоваться средними величинами при определении сезонных колебаний, то при создании стратегического плана необходимы более точные модели, а значит - более сложные методы.
3.5 Моделирование результатов банковской деятельности
По десяти кредитным учреждениям получены данные, характеризующие зависимость объема прибыли (Y, млн. руб.) от величины доходов по кредитам (X1, млн. руб.), доходов по депозитам (X2, млн. руб.) и размера внутрибанковских расходов (X3, млн. руб.) (см. табл.1).
Таблица 1
Данные результатов деятельности банковских организаций
Y | 32 | 40 | 44 | 28 | 50 | 56 | 50 | 56 | 60 | 62 |
X1 | 22 | 30 | 20 | 32 | 44 | 34 | 52 | 56 | 66 | 68 |
X2 | 56 | 48 | 52 | 58 | 66 | 62 | 48 | 66 | 70 | 68 |
X3 | 64 | 68 | 82 | 76 | 84 | 96 | 100 | 104 | 108 | 102 |
С целью выявления и анализа зависимости прибыли банковских организаций от различных показателей деятельности осуществим построение регрессионных моделей и проведем анализ качества данных моделей.
I. Выбор факторных признаков для построения модели осуществляется с помощью матрицы коэффициентов парных корреляций. Для её построения необходимо выбрать Сервис->Анализ данных->Корреляция (см. рис.1).
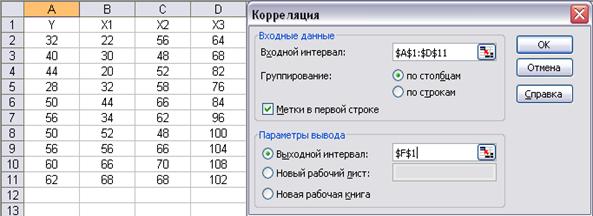
Рис.1. Ввод параметров инструмента «Корреляция»
Результаты представлены на рис.2.
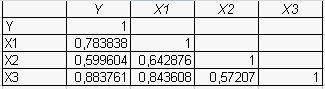
Рис.2 Таблица коэффициентов парных корреляций
Для выявления мультиколлинеарности необходимо проанализировать коэффициенты парной корреляции между факторными признаками. Так как 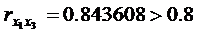 , т. е. между факторными признаками X1 и X3 существует явление мультиколлинеарности, то для построения модели выбираем тот факторный признак, который оказывает большее влияние на результативный признак (фактор, для которого коэффициент парной корреляции с результативным признаком, взятый по модулю, является большим).
, т. е. между факторными признаками X1 и X3 существует явление мультиколлинеарности, то для построения модели выбираем тот факторный признак, который оказывает большее влияние на результативный признак (фактор, для которого коэффициент парной корреляции с результативным признаком, взятый по модулю, является большим). ![]()
Следовательно, фактор X3 оказывает большее влияние на результативный признак (Y) и этот фактор рекомендуется в модели оставить. Таким образом, для построения модели множественной регрессии выбираются два факторных признака - Х2 (величина доходов по депозитам) и Х3 (величина внутрибанковских расходов).
Расчет параметров регрессионной модели можно осуществить с помощью инструмента анализа данных Регрессия (MS EXCEL) (cм. рис.3).
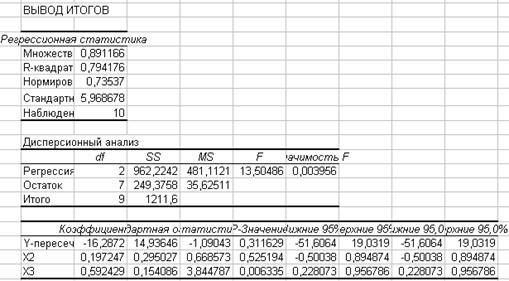
Рис.3. Вывод итогов регрессии
На основании полученных данных можно записать уравнение множественной регрессии
Y=-16,2872 + 0,197247*X2 + 0,592429*X3 (1)
Оценим качество построенной модели множественной регрессии по следующим направлениям:
· Коэффициент детерминации ![]() = 0.794176 достаточно близок к 1, следовательно, качество модели можно признать высоким.
= 0.794176 достаточно близок к 1, следовательно, качество модели можно признать высоким.
· Критерий Фишера F = 13,50486 > Fтабл = 4,74 , следовательно, уравнение регрессии признается статистически значимым и может быть использовано для анализа и прогнозирования экономических процессов.
· с помощью коэффициентов эластичности, b - и D - коэффициентов.
- Коэффициент эластичности определяется по формуле:
![]() , (2)
, (2)
где ![]() - среднее значение соответствующего факторного признака,
- среднее значение соответствующего факторного признака,
![]() - среднее значение результативного признака.
- среднее значение результативного признака.
bi – коэффициенты регрессии соответствующих факторных признаков.
- ß-коэффициент определяется по следующей формуле:
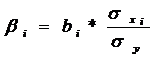 , (3)
, (3)
где ![]() - среднеквадратическое отклонение (СКО) соответствующего факторного признака (рассчитывается как корень квадратный из дисперсии признака),
- среднеквадратическое отклонение (СКО) соответствующего факторного признака (рассчитывается как корень квадратный из дисперсии признака),
![]() - СКО результативного признака.
- СКО результативного признака.
- ∆-коэффициент определяется по следующей формуле:
![]() , (4)
, (4)
где ![]() - коэффициент парной корреляции результативного и соответствующего факторного признаков,
- коэффициент парной корреляции результативного и соответствующего факторного признаков,
![]() - коэффициент детерминации.
- коэффициент детерминации.
На рисунке 4 представлены расчеты описанных выше коэффициентов.
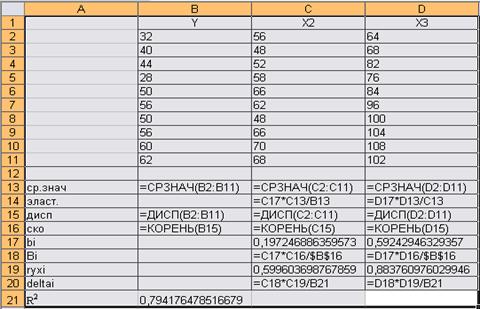
Рис.4. Формулы расчетов коэффициентов
Результаты вычислений представлены в таблице 2.
Таблица 2
Результаты расчета бета-, дельта - и коэффициентов эластичности
Y | X2 | X3 | |
32 | 56 | 64 | |
40 | 48 | 68 | |
44 | 52 | 82 | |
28 | 58 | 76 | |
50 | 66 | 84 | |
56 | 62 | 96 | |
50 | 48 | 100 | |
56 | 66 | 104 | |
60 | 70 | 108 | |
62 | 68 | 102 | |
Ср. знач | 47,8 | 59,4 | 88,4 |
Эласт. | 0,245114 | 0,881663 | |
Дисп | 134,6222 | 67,6 | 247,8222 |
СКО | 11,60268 | 8,221922 | 15,74237 |
bi | 0,197247 | 0,592429 | |
| 0,139774 | 0,803801 | |
| 0,599604 | 0,883761 | |
| 0,105529 | 0,894471 | |
Выводы:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
