

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Применение методов вычислительной геометрии для поиска линейных объектов.
,
Аннотация:
В статье рассмотрено применение методов вычислительной геометрии к различным классам задач анализа изображений, позволяющее существенно повысить скорость обработки данных. Произведено обобщение введенной ранее технологии ассоциативных структур на объекты сложной формы. Описаны алгоритмы поиска линейных объектов на растровых изображениях, базирующиеся на данной технологии.
1. Ассоциативная структура как основа быстрых алгоритмов автоматической классификации
В предыдущих работах автора [5, 7] была предложена методология существенного понижения вычислительной сложности широкого класса алгоритмов анализа данных, в частности, алгоритмов автоматической классификации. Основой данной методологии является представление массива подлежащих анализу данных в виде структуры специального вида (ассоциативной структуры – в дальнейшем просто АС) и прямой доступ к любой интересующей области данных при их анализе без просмотра всего массива с использованием построенной ассоциативной структуры.
Напомним вкратце базовую концепцию данной технологии анализа данных. Предположим, что в p-мерном признаковом пространстве Rp имеется некоторое множество X={xi,, i=1…n} анализируемых данных и одной из основных массовых операций их обработки является поиск подмножества объектов из X, принадле-жащих окрестности ε некоторой точки FÎRp.
Если имеются априорные представления о форме и размере окрестности ε (во многих практически важных случаях окрестность имеет фиксированную форму и размер, поэтому предположим без ограничения общности, что окрестность ε является гиперсферой радиуса T, отметив при этом, что предлагаемая технология была успешно применена и в более общих случаях), то АС может быть построена следующим образом:
а) определим в Rp изотетичный гиперпараллелепипед H мини-мального размера, охватывающий все множество X;
б) зададим на области H сетку С, форма и размер ячеек которой зависят от вида и размера окрестности ε, используемой при дальнейшем анализе. В простейшем случае ячейки имеют гиперпараллелепипедную форму и не пересекаются. В этом случае множество ячеек C={c} задает разбиение области H.
в) выделим подмножество X(c) объектов из X, принадлежащих некоторой ячейке c и с каждой ячейкой c сетки ассоциируем соответствующее ей подмножество X(c).
Очевидно, время построения АС линейно зависит от размера множества X и размерности пространства p. Более точно, это время есть O(n*p). В случае анализа двумерных изображений время построения АС линейно зависит от удвоенного числа объектов.
Теперь, имея АС, мы можем существенно ускорить поиск в окрестности, освободившись от необходимости просмотра при этом всего исходного массива данных.
Предположим, что требуется найти все объекты множества X, принадлежащие окрестности ε некоторой точки FÎRp (см. Рис. 1). Отметим, что запросы такого типа или операции, легко сводящиеся к таким запросам, зачастую образуют основную вычислительную сложность алгоритмов автоматической классификации.
На АС отбор объектов из ε-окрестности сводится к исполнению следующих основных шагов [5]:
а) определим p-мерный индекс ячейки сетки, в которой нахо-дится центральная точка F окрестности;
б) покроем ε-окрестность набором ячеек C(ε):
C(ε) = {cÎС | cÇε ¹ {Æ} }. На плоскости в случае, если ε-окрестность представляет собой круг радиуса T, покрытие C(ε) будет представлять собой 3*3-окрестность центральной ячейки АС (рис. 1).
в) Формируем множество X(C(ε)) объектов, принадлежащих покрытию:
г) на множестве X(C(ε)) находим искомое подмножество X(ε)={xÎC(ε) | xÎε}.
Таким образом вместо просмотра всего исходного множества X задача редуцировалась к просмотру объектов покрытия C(ε) заданной
ε-окрестности.

Рис. 1 Двумерная точечная ассоциативная структура
2. Точечные ассоциативные структуры
Основным допущением, используемым при построении АС, является предположение о точечном характере объектов в признаковом пространстве и существенная эксплуатация такого точечного представления объектов при определении факта принадлежности объектов ячейкам АС. Назовем АС, построенные с учетом такого допущения, точечными АС.
Заметим, что областью применимости подобной точечной идеализации объектов исследования является ситуация, когда размеры объектов сопоставимы с размерами ячеек сетки АС [6]. В этом случае мы имеем дело с достаточно олднородными размерностными характеристиками исследуемого множества X. Но даже в этом случае представление классифицируемых объектов в точечной форме часто является неприемлемым огрублением. Поэтому при классификации на АС используется следующая техника: на этапе отбора объектов из ε-окрестности используется точечное представление, а точное исследование дистанции на парах объектов производится на оригинальном представлении объектов.
Опишем некоторые задачи, эффективно решаемые с применением технологии точечных АС:
Задача 1 Поиск текстовых строк на изображении текста – классическая задача анализа структуры текста. В работе [1] описана процедура иерархического кластер-анализа ClustAs, основанная на АС и примененная для быстрого нахождения текстовых строк. Данная процедура была использована в OCR-системе CRIPT.
Задача 2 Быстрое оценивание угла перекоса изображения машинописного текста. Применение точечной АС для формирования кластеров символов из одной строки привело к синтезу алгоритма оценивания угла, значительно превосходящего по скорости классические алгоритмы оценивания перекоса текста [7].
Задача 3 Поиск колонок и текстовых фрагментов в много-колонных текстах. В работах [2, 7] описан алгоритм иерархической кластеризации, базирующийся на АС, который позволяет оценить древовидную структуру текстовых колонок. Отметим, что изображения многоколонных текстов могут состоять из довольно большого числа компонент связности (до 10 тысяч и более). Поэтому для данной задачи особенно актуально получение вычислительно-эффективного алгоритма. Алгоритм, основанный на точечной АС, имеет практически линейную по числу компонент связности вычислительную сложность.
Задача 4 Предварительное выделение табличных ячеек в таблицах сложной иерархической структуры. Предлагаемая технология точечных АС была успешно применена для выделения текстовых ячеек на норвежских налоговых декларациях XIX века [3, 4].
Задача 5 Расчет характеристик светового потока в задачах математического моделирования отражательной способности автомобильных фар (Optical Research Assotiation, Inc. – пакет имитационного моделирования). Отметим, что в отличие от вышеописанных задач, в соответствие с особенностями решаемой задачи в данном случае была использована пространственная (трехмерная) АС.
Задача 6 Поиск поля “Legal Amount” на изображениях американских коммерческих чеков [8]. В данной задаче с помощью точечной АС производится поиск текстовых блоков и строк на изображениях чеков. Здесь также используется алгоритм быстрого кластер-анализа, основанный на технологии АС.
3. Распределенные ассоциативные структуры
В ряде задач анализа данных (в особенности обработки и распознавания изображений) точечная идеализация объектов неприменима. Типичными примерами таких объектов являются топографические объекты на картах (реки, моря, дороги), объекты на технических чертежах (линии и разнообразные геометрические фигуры), линии и разграфка таблиц в текстовых изображениях. Очевидно, перечисленные объекты можно подразделить на одномерные и двумерные.
Распространим понятие АС на существенно неточечные объекты. Напомним, что в основе точечной АС лежат понятия “принадлежности” и “соседства”. Объект x приписывается к ячейке c АС, если его точечное представление принадлежит области Rp, ограниченной ячейкой c. Далее, объекты признаются соседями на АС, если их точечные представления принадлежат заданной ε-окрестности (что на изображениях часто сводится к простому условию принадлежности объектов одной или смежным ячейкам).
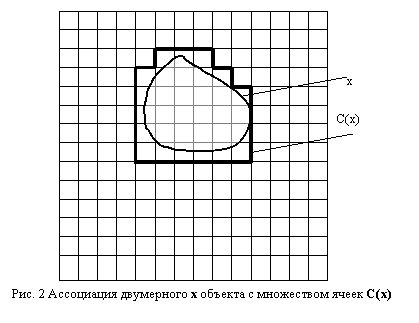
Первым очевидным обобщением АС на неточечные объекты является замена понятия “принадлежности” на понятие “пересечение”. Более формально – будем считать, что некий объект xÎX связан с ячейкой cÎC, если cÇx ¹ {Æ}, т. е. если пересечение данного объекта с данной ячейкой является непустым. Очевидно, в данном случае объект может быть ассоциирован более чем с одной ячейкой АС. Для прямого доступа ко всем ячейкам C(x)={cÎC | cÇx ¹ {Æ}} (см. Рис. 2), связанным с данным объектом, в АС вводится дополнительная ссылка “объект-объект”. Назовем структуру, построенную по данному правилу, распределенной АС.
Операция отбора всех объектов из ε-окрестности в пространстве Rp на распределенной АС будет выполняться по алгоритму, аналогичному случаю точечной АС, с одним содержательным различием – в результате отбора будет выделено некоторое подмножество объектов X(ε), не обязательно целиком принадлежащих ε-окрестности (гарантированно лишь наличие общих точек ε-окрестности с каждым выделенным объектом).
 |
4. Линейные ассоциативные структуры
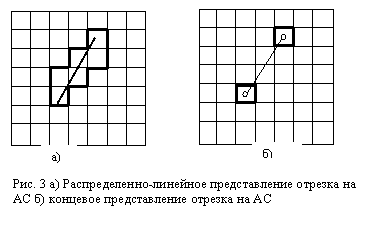
Рассмотрим важный с практической точки зрения частный случай распределенной АС, когда объекты представляют собой прямолинейные отрезки. При этом, в зависимости от специфических особенностей решаемых задач, возможно два различных представления линейных объектов на АС – распределенно-линейное и концевое.
Под распределенно-линейным представлением, как и в общем случае распределенных АС, будем понимать ассоциацию линейного объекта со всеми ячейками, имеющими с ним непустое пересечение (рис. 3а). АС, построенные с использованием такого типа ассоциаций, будем называть распределенно-линейными АС.
Под концевым представлением линейного объекта на АС будем понимать ассоциацию с ним двух ячеек АС, соответствующих двум его концам (рис. 3б).
На каждом из введенных линейных представлений по-своему определяется и понятие соседства – если на распределенно-линейной АС соседство традиционно распределено вдоль линейного объекта, то на концевой АС зоны соседства сосредоточены вокруг концов отрезка.
 |
5. Применение АС в задачах поиска линейных объектов на изображениях
В данном разделе мы рассмотрим несколько задач поиска линий на изображениях документов, эффективно решаемых на АС.
Задача 7 Поиск точечных и пунктирных линий. Особенностью данной задачи является большой размер первичного массива анализируемых данных (например, на изображениях платежных поручений, напечатанных на точечном принтере, число компонент связности – кандидатов в элементы линий, может достигать 10-20 тысяч, а при наличии интенсивного шума – еще более). Поэтому использование АС здесь особенно эффективно с точки зрения понижения вычислительной сложности алгоритмов. Реализованый алгоритм носит иерархический характер и основан на разного типа АС и кластер-анализе.
Вначале строится двумерная точечная АС на компонентах связности, соразмерных с элементами искомых линий и на этой структуре производится поиск фрагментов линий:
- линейных с помощью разработанной автором [5, 7] универсальной процедуры быстрого кластер-анализа ClustAs, основанного на технологии ассоциативных структур;
- перекрестий, напечатанных знаком ‘+’ и уголков, соеди-няющих линейные фрагменты, с использованием той же точечной АС.
При кластеризации используются метрики двух типов – одна из них – на парах “компонента - компонента”, учитывающая возможные комбинации взаиморасположения элементов в точечных и пунктирных линиях; другая – на парах “компонента – линейный эталон”, основанная на критериях линейности формируемого кластера.
Отметим, что сформированные линейные фрагменты часто не совпадают с оригинальными линиями, а покрывают их частично кусочно-линейным образом. В основном это связано с двумя следующими факторами:
- непропечаткой некоторых точек линии, что приводит к разрыву в ее пиксельном образе;
- слиянием последовательности точек (пунктиров) в единый вытянутый конгломерат, который не попадает в число кандидатов на элементы линии, что также приводит к ее разрыву.
Для устранения разрывов в линиях, связанных со вторым фактором, применяется смешанная точечно-распределенная АС – элементы уже сформированных линейных кластеров заносятся в нее как точки, а вытянутые компоненты – кандидаты на мостики между линейными фрагментами – в виде двух взаимосвязанных концов. На сформированной таким образом гибридной АС производится быстрое сращивание разрывов в линиях.
 |
Сформированные линейные кластеры, перекрестия и уголки являются объектами кластеризации более высокого уровня, целью которой является сращивание разрывов в рваных линиях, связанных с первым из вышеперечисленных факторов. Природа задачи диктует применение линейной концевой АС (см. Рис. 4), поскольку очевидно, что фрагменты, подлежащие объединению в кластеры-линии, соседствуют концами. Метрика, используемая для объединения линейных фрагментов в линии, учитывает степень соосности фрагментов, согласованность их ориентаций с ориентацией формируемой линии, геометрическую близость фрагментов, а также непревышение ширины соответствующего линии точечного облака некоторого порога (степени линейности).
Данный набор алгоритмов используется в Системе распознавания стандартных форм Cognitive Forms [9] для поиска точечных и пунктирных линий, склеивания разрывов в рваных линиях и как составной элемент поиска боксов на формах с индексными полями.
Остановимся кратко на двух других задачах поиска линий, эффективно решаемых на АС.
Задача 8 Фомирование единой оценки набора линий на изображении по результатам поиска сплошных линий и точечно-пунктирных линий. В данном случае входной информацией являются два набора оценок линий, полученные разными алгоритмами и необходимо на основании имеющихся двух оценок сформировать единую, более точную оценку.
Описанная задача также решается методом быстрого кластер-анализа ClustAs с использованием одномерной точечной АС (более точно – для поиска горизонтальных линий зона изображения разбивается на горизонтальные-полосы – ячейки АС, а для поиска вертикальных линий – соответственно на вертикальные). Метрика, используемая для построения линейных цепочек, учитывает специфику алгоритмов поиска сплошных и точечных линий. Данный алгоритм используется в Системе распознавания стандартных форм Cognitive Forms [9] для формирования финальной оценки набора линий анализируемой формы.
Отметим, что данная задача может быть также решена с использованием двумерной распределенно-линейной АС.
Задача 9 Оценивание иерархической структуры линий.
Данная задача обычно возникает при анализе сложных табличных структур, имеющих наборы соосных линий в качестве разграфки (см. например, таблицы в работе [4]), а также на определенном классе форм, локализация полей на которых также базируется на предварительном обнаружении соосных кластеров горизонтальных и вертикальных линий (типичным приложением является задача поиска полей на английских и австралийских коммерческих чеках). Пример такого типа табличной структуры приведен на рис. 5.
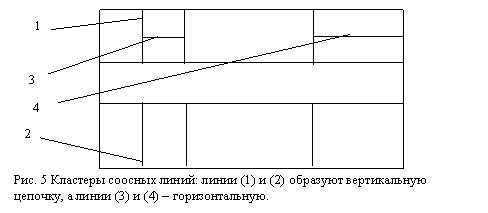 |
Данная задача решается методом быстрого кластер-анализа ClustAS c применением технологии одномерных точечных и распределенно-линейных АС. В работах [4, 5] описана система анализа норвежских налоговых деклараций XIX века, представляющих собой сложноорганизованные таблицы с горизонтальной и вертикальной нетривиальной иерархией, имеющие разрывы структурной иерархии. Поиск наборов соосных линий позволил эффективно анализировать подобные табличные структуры.
Заключение
Таким образом, в настоящей работе рассмотрено применение методов вычислительной геометрии к различным задачам анализа изображений. Проанализированы ограничения предложенной в предыдущих работах автора точечной АС и произведено распространение данной технологии на более сложные одномерные и двумерные объекты.
Предложены следующие обобщения точечной АС:
распределенная АС;
распределенно-линейная АС;
концевая АС.
Описано приложение точечных, распределенно-линейных и концевых (одно-, двух - и трех-мерных) АС для решения ряда задач анализа текстовой и линейной информации на изображениях, анализа документов сложной структуры (таблиц, платежных поручений, чеков) , а также для решения ряда задач оптики.
Рассмотрены алгоритмы поиска точечных и пунктирных линий, склеивания разрывов в линиях и оценивания иерархической структуры линий, основанные на различных типах АС. Описано внедрение описанных алгоритмов в ряде прграммных продуктов.
Литература
1. Vitaly Klyahzkin, Eugene Shchepin, Konstantin Zingerman Application of hierarchical methods of cluster analysis to the printed text structure recognition //"Shape, Structure, and Pattern Recognition" Nahariya, Israel, 4-6 October 1994 Dov Dori and Alfred Bruckstein, Eds., World Scientific, 1995, Singapore, New Jersey, London, Hong Kong (SSPR'94), pp 333-342
2. Vitaly Klyahzkin, Eugene Shchepin, Konstantin Zingerman Hierarchical analysis of multi-column texts //Pattern Recognition and Image Analysis, Vol.5, No.1, 1995, Interperiodica, pp.1-12
3. Vitaly Kliatskin, Evgeny Shchepin, Konstantin Zingerman About the limitations of the automatic conversion of the content of historical documents // "XI International Conference of the Association for History and Computing" "Data modelling - modelling history" august 20-24, 1996, Moscow State University, edited by Leonid Borodkin, Moscow, 1996, pp 56-57
4. Vitaly Kliatskine, Eugene Shchepin, Gunnar Thorvaldsen, Konstantin Zingerman, Valery Lazarev A Structural Method for the Recognition of Complex Historical Tables //History & Computing, Edinburg University Press 1997, vol.9, No.3. pp.58-77.
5. Использование методов вычислительной геометрии для синтеза быстрых алгоритмов автоматической классификации //В сб. "Геометрия, топология и приложения", М.:МВиССО, Московский инст-т приборостроения. Межвуз. сб. науч. трудов.-1990.-С.46-53.
6. , Методы классификации на плоскости и их применение при анализе точечных изображений //В сб. "Теория и практика классификации и систематизации в народном хозяйстве" Сборник докладов Международного научно-технического симпозиума Пущино 1990, С. 76-77
7. Иерархический кластер-анализ многоколонных текстов //Труды V Международной конференции “Статистический и дискретный анализ данных и экспертные оценки” Изд-во Одесского политех. университета, Одесса, 1994, С. 132-134.
8. QuickStrokes API. Application Development Manual //Mitek Systems Inc., 1998
9. Система распознавания стандартных форм Cognitive Forms (http://www. *****)
