


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Здесь n, p, q те же, что и в примере 1 : n=100 , p = q =0,5 , k1=47 , k2 = 57 .
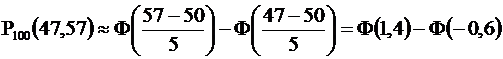
Функция F вычисляется с помощью таблиц ( см. приложение ).
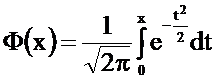
Функция Ф(x) нечетная: Ф(-х) = - Ф(х) . При х > 5 считают, что Ф(х) = 0,5.
Итак, Р100(47,57) = Ф(1,4) + Ф(0,6). По таблице Ф(1,4) = 0,4192, Ф(0,6) = 0,2257 , поэтому Р100(47,57) = 0,6449.
При небольших значениях вероятности p ( меньших 0,1 ) и больших значениях n более точный результат дает другая приближенная формула - формула Пуассона
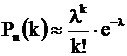 , l = np
, l = np
l называется параметром распределения Пуассона, а сама формула выражает “закон редких явлений” (т. к. p мало).
Пример 3. Первый черновой набор “Методических указаний” на 50 страницах содержит 100 опечаток. Какое из событий вероятнее: на наудачу взятой странице нет опечаток, 1 опечатка, 2 опечатки, 3 опечатки?
Вероятность того, что данная опечатка попадет на наудачу взятую страницу равна 1/50 = 0,02 , число испытаний ( опечаток ) n = 100 . Поскольку p мало, воспользуемся формулой Пуассона с параметром l = np = 2 . Вероятность того, что опечаток нет
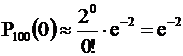 ( т. к. 0! = 1 )
( т. к. 0! = 1 )
Другие вероятности
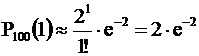 ,
,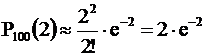
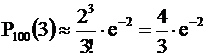 .
.
Как видим, наибольший коэффициент при е-2 у Р100(1) и Р100(2).
Ответ: наиболее вероятны 1 или 2 опечатки, их вероятность 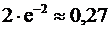 .
.
КОММЕНТАРИИ К ЗАДАЧЕ № 3
§13. СЛУЧАЙНЫЕ ВЕЛИЧИНЫ ДИСКРЕТНОГО ТИПА.
Cлучайной величиной называют величину, которая в результате испытания примет одно и только одно возможное числовое значение из заранее известной совокупности значений. Случайной величиной дискретного типа (дискретной случайной величиной) называется величина, которая может принимать либо конечное число возможных значений, либо такое бесконечное число значений, которые могут быть расположены в числовую последовательность Е1, Е2, ... . Для каждого из этих значений указывают его вероятность. Сумма этих вероятностей должна быть равна 1. Если случайная величина принимает только одно значение, то соответствующая ему вероятность равна 1.
Пример 1. Пусть Х1 - число “орлов”, выпавших при двух бросках симметричной монеты. Х может принимать значения 0, 1 или 2 с вероятностями, вычисленными по формуле Бернулли: 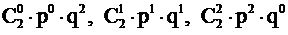 . Т. к. p = q = 0,5 , то эти вероятности равны 0,25; 0,5; 0,25 соответственно.
. Т. к. p = q = 0,5 , то эти вероятности равны 0,25; 0,5; 0,25 соответственно.
Дискретные случайные величины записывают в виде таблицы. Для данного примера получим:
Х1 | 0 | 1 | 2 |
Р | 0,25 | 0,5 | 0,25 |
Верхняя строчка - возможные значения Х1, Р - их вероятности, сумма которых равна 1.
С помощью таблицы можно считать вероятности попадания случайной величины дискретного типа в интервалы. Например, для заданной выше случайной величины Х
![]() .
.
Пример 2. В полном наборе игры в домино 28 костей. Пусть Х2 – сумма очков на случайно выбранной кости. Поскольку наименьшее значение такой суммы равно 0 («пусто-пусто»), следующее – 1 и так до 12 («6-6»), Х является случайной величиной дискретного типа. Зададим ее таблицей.
Х2 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
Вероятности в этой таблице вычислены по формуле классической вероятности, в числителях дробей количества костей домино с данным числом очков, знаменатели равны общему числу костей.
Случайные величины традиционно обозначаются заглавными буквами X, Y, Z, ... , а их возможные значения - прописными: x1, x2, y1, и т. д.
§14. ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
Если F(x) = P(X < x), то функция F(x) называется функцией распределения (интегральной функцией распределения) случайной величины Х, т. е. функция распределения в точке “х” - это вероятность того, что случайная величина Х примет значение, меньшее заданного числа х.
Из определения сразу следуют несколько свойств F(x):
F(- ¥) = 0, F(+ ¥ ) = 1;
F(x) - неубывающая функция (т. е. если x1 < x2 , то F(x1) £ F(x2) ).
Функция распределения для случайной величины дискретного типа имеет “ступенчатый” график. Для случайной величины Х1 из §13 F(x) запишется так:
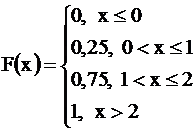
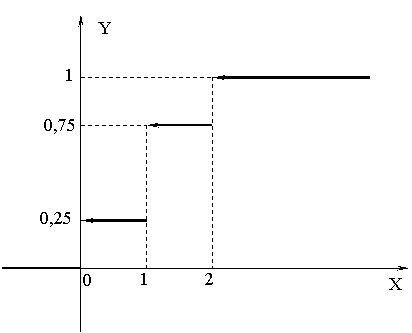
Обратите внимание, что левые концы «ступенек» - выколотые, а правые - нет. Например, F(1) = P(X1 < 1) = P(X1 =0) = 0,25;
F(1,1) = P(X1<1,1) = P(X1 = 0) + P(X1 = 1) = 0,75. «Высоты» «ступенек» равны очередным вероятностям, взятым из таблицы : сначала 0,25, затем еще +0,5, и наконец еще +0,25.
Аналогичный график и для другого примера – про домино – только там будет не 2, а 12 «ступенек».
Справедлива формула: P(a £ X < b) = F(b) - F(a).
§15. МАТЕМАТИЧЕСКОЕ ОЖИДАНИЕ СЛУЧАЙНОЙ
ВЕЛИЧИНЫ ДИСКРЕТНОГО ТИПА
Математическое ожидание - важнейшая “характеристика положения” случайной величины. Для дискретной величины она вычисляется по формуле
М(Х) = x1 · p1 + x2 · p2 + ... + xk · pk (+...) = 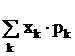 ,
,
где x1, x2, ... , xk, ... - возможные значения случайной величины (верхняя строка таблицы), p1, p2, ..., pk, ... - их вероятности (нижняя строка).
Математическое ожидание - это число, которое выражает среднее значение случайной величины (иначе, среднее значение по распределению). Для примера из §13
М(Х1) = 0 · 0,25 + 1 · 0,5 + 2 · 0,25 = 1 .
Здесь Х1 - число “орлов”, выпавших при 2 бросках симметричной монеты. М(Х1) - среднее число “орлов”, выпадающих при 2 бросках симметричной монеты, это число равно 1.
Для другого примера из §13 М(Х2) = 6.
Отметим два простейших свойства математического ожидания:
1. М (С) = С
2. М (С · Х) = С · М(Х) ( С - постоянная ).
В дальнейшем нам придется вычислять математическое ожидание случайной величины Х2. Если случайная величина Х задается таблицей
X | x1 | x2 | ... | xk |
P | p1 | p2 | ... | pk |
то случайная величина Х2 получится после возведения в квадрат возможных значений случайной величины Х, при этом Р(Х = хк)= = Р(Х2 = хк2) = pk :
X2 | x12 | x22 | ... | xk2 |
P | p1 | p2 | ... | pk |
Поэтому М(Х2) = x12 · p1 + x22 · p2 + ... + xk2 · pk = ![]() .
.
В частности, для примера из §13
X2 | 02 | 12 | 22 |
P | 0,25 | 0,5 | 0,25 |
и М(Х2) = 02 · 0,25 + 12 · 0,5 + 22 · 0,25 = 1,5
§16. ДИСПЕРСИЯ СЛУЧАЙНОЙ ВЕЛИЧИНЫ
Дисперсия - важнейшая «характеристика рассеивания» случайной величины. Рассеивание оценивается относительно среднего значения случайной величины Х - математического ожидания М(Х). Из всех возможных значений случайной величины Х вычитают число М(Х). Новая случайная величина Y = X-M(X) называется отклонением случайной величины Х, причем ее среднее значение М(Y) = 0. Далее рассматривается случайная величина Y2. Ее возможные значения неотрицательны. Среднее значение квадрата отклонения М(Y2) также неотрицательно. Оно и называется дисперсией. Итак,
D(X) = M(Y2)=M((X - M(X) )2).
Для вычисления дисперсии используют формулу
D(X) = M(X2) - (M(X))2.
Для дисперсии справедливы свойства:
D(C) = 0, D(C · X) = C2 · D(X).
Вновь вспомним пример из §13 . Для него М(Х1) и М(Х12) уже подсчитаны выше: М(Х1) = 1, М(Х12) = 1,5. Поэтому D(X) = 1,5-12 = 0,5 .
Для второго примера из §13 М(Х2) = 6, М(Х22) = 45, D(X) == 9.
§17. БИНОМИАЛЬНЫЙ И ПУАССОНОВСКИЙ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ
Биномиальное распределение связано с повторными независимыми испытаниями и формулой Бернулли. Оно задается фиксированным числом испытаний n и вероятностью «успеха» в одном испытании p. Отличительные черты биномиального эксперимента:
1. все n испытаний абсолютно одинаковы;
2. результаты разных испытаний не зависят друг от друга;
3. для каждого испытания возможны только два исхода: «успех» и «неудача»; «успех» ‑ когда интересующее нас событие появилось, и «неудача», ‑ когда не появилось;
4. для каждого испытания вероятность появления «успеха» постоянна и равна p.
Число «успехов» в n независимых испытаниях будет случайной величиной X, распределенной по биномиальному закону. Вероятность того, что случайная величина X, распределенная по биномиальному закону примет значение k, вычисляется по известной формуле Бернулли:
![]()
 |
Ряд распределения X принимает вид:
Числовые характеристики биномиального распределения.
1. математическое ожидание равно произведению числа испытаний n на вероятность «успеха» в одном испытании p: М(Х)= np;
2. дисперсия равна произведению числа испытаний n на вероятность «успеха» в одном испытании p и на вероятность «неудачи» q: D(X)= npq.
Распределение Пуассона.
Приведем примеры, приводящие к случайным величинам, распределенным по закону Пуассона:
· Автоматическая телефонная станция получает в среднем за минуту а вызовов. Какова вероятность того, что за данную минуту она получит ровно m вызовов? Случайное число вызовов за данную минуту распределено по закону Пуассона.
· Автодорожная инспекция регистрирует количество аврий за неделю на определенном участке дороги. Какова вероятность того, что в течение данной недели произойдет ровно m дорожных аварий? Случайное число аварий за неделю распределено по закону Пуассона.
Аналогичные примеры можно привести не только для временных интервалов (минута, неделя), но и при учете дефектов дорожного покрытия на километр пути или опечаток на страницу текста.
Отличительные черты эксперимента, приводящего к распределению Пуассона (на примере временных интервалов):
1. каждый малый интервал времени может рассматриваться как испытание, результатом которого служит либо «успех» - поступление телефонного вызова, либо «неудача». Интервалы столь малы, что может быть только один «успех» в одном интервале, вероятность которого мала и неизменна.
2. Число «успехов» в одном большом интервале не зависит от их числа в другом. То есть попадание «успехов» в неперекрывающиеся интервалы – события независимые, и «успехи» беспорядочно разбросаны по временным промежуткам;
3. среднее число «успехов» в большом интервале для разных интервалов постоянно на протяжении всего времени.
Число «успехов» на заданном интервале будет случайной величиной, распределенной по закону Пуассона. Случайное число аварий за неделю может принимать значения 0, 1, 2, 3, … (верхнего предела нет). Вероятность того, что случайная величина X, распределенная по закону Пуассона примет значение m, вычисляется по известной формуле Пуассона:
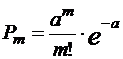 , m = 0, 1, 2, …
, m = 0, 1, 2, …
Числовые характеристики распределения Пуассона.
Математическое ожидание равно дисперсии и равно параметру распределения а: М(Х)= а, D(X)= а.
КОММЕНТАРИИ К ЗАДАЧЕ № 4
§18. СЛУЧАЙНЫЕ ВЕЛИЧИНЫ НЕПРЕРЫВНОГО ТИПА.
Если возможные значения случайной величины сплошь заполняют некоторый промежуток <a, b> Ì R (быть может, и всю ось) , то табличный способ задания случайной величины непригоден. Такая случайная величина называется случайной величиной непрерывного типа. Ее функция распределения F(x) будет непрерывна. Напомним, что F(- ¥ ) = 0 , F(+ ¥ ) = 1 , F(x) - монотонная неубывающая функция. Производная такой функции F(x) будет функцией неотрицательной. Она называется плотностью распределения вероятностей или дифференциальной функцией распределения вероятностей. Ее обозначение ![]() .
.
Часто по условию задачи задают именно плотность распределения, зная которую можно вычислить и (интегральную) функцию распределения ( по формуле Ньютона - Лейбница ):
F(x) = F(x) - F(- ¥ ) = 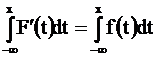
Заметим, что f(x) - не обязательно непрерывная функция, она допускает в отдельных точках разрывы 1-го рода.
Итак, f(x) - неотрицательная кусочно-непрерывная функция, причем, согласно одному из свойств F(x),
F(+ ¥ ) =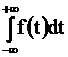 = 1
= 1
Последнее равенство, называемое условием нормировки f(x), показывает, что f(x) - не любая неотрицательная функция: площадь между графиком плотности распределения и осью абсцисс должна быть равна 1.(Для дискретной случайной величины условием нормировки являлось равенство 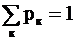 ).
).
Для непрерывных случайных величин справедливы равенства F(b) - F(a) = P(a £ X < b) = P(a < X < b) = P(a < X £ b) = = P(a £ X £ b) = 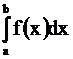 .
.
М(Х) и D(X) определяются формулами
M(X) =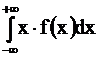 , D(X) =
, D(X) =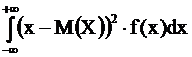 .
.
Вычислительная формула для D(X):
D(X) = M(X2) - (M(X))2 = 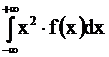 - (M(X))2.
- (M(X))2.
§19. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО
ХАРАКТЕРИСТИКИ
Нормальный (гауссовский) закон распределения задается плотностью распределения по формуле
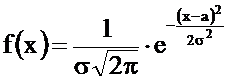 , - ¥ < x < +¥
, - ¥ < x < +¥
Числа а Î R и s > 0 называются параметрами нормального закона. Нормальный закон с такими параметрами обозначается N(a, s).
При а = 0 функция f(x) четная ( f(-x) = f(x) ) , ее график симметричен относительно оси OY, и поэтому среднее значение М(Х) = 0. График f(x) для закона N(a, s) получается из графика f(x) для N(0,s) сдвигом на а единиц вправо ( это известно из курса средней школы ), поэтому в общем случае М(Х) = а для нормального закона.
Дисперсия же вычисляется по формуле D(X) =s2.
Пример. Случайная величина Х распределена по нормальному закону с плотностью вероятности
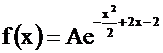
Найти А, М (Х), D(X), P(-3<X<3).
Т. к. 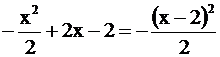 , то
, то 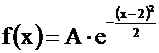
Показатель экспоненты 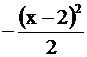 приравняем к
приравняем к 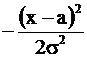 , откуда а = 2 , s = 1 . Числовой коэффициент
, откуда а = 2 , s = 1 . Числовой коэффициент 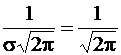 должен быть равен А, следовательно,
должен быть равен А, следовательно,
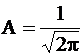 , M (X) = a = 2, D(X) = s 2 = 1.
, M (X) = a = 2, D(X) = s 2 = 1.
P (-3 < X < 3) = F(3) - F(-3) = =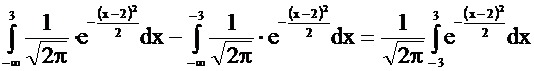
Этот интеграл не вычисляется в элементарных функциях, его численное значение можно найти по таблицам.
В большинстве учебников имеются таблицы для вычисления функций
Ф(х) = 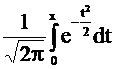 или Ф1(х) =
или Ф1(х) = 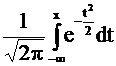 =
= ![]() + Ф(х)
+ Ф(х)
Ф(х) - нечетная функция, т. е. Ф(-х) = - Ф(х). В общем случае
Р(x1 < X < x2) = 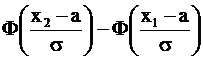 ,
,
где а и s - параметры нормального закона. Следовательно, для данного примера
P(|X| < 3) = Ф1(1) - Ф1(-5) = Ф(1) - Ф(-5) = Ф(1) + Ф(5) =
= 0,3413 + 0,5 = 0,8413.
§20. ДРУГИЕ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ НЕПРЕРЫВНЫХ СЛУЧАЙНЫХ ВЕЛИЧИН
Кроме нормального закона есть и другие случайные величины, часто встречающиеся в приложениях. Приведем некоторые из них.
Для равномерного закона плотность вероятности и функция распределения задаются формулами
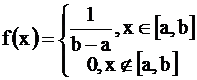 ,
, 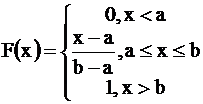 ,
,
а числовые характеристики М(Х)= ![]() , D(X)=
, D(X)= 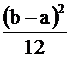 .
.
Для показательного закона плотность вероятности и функция распределения задаются формулами
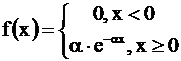 ,
, 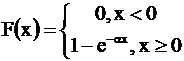 ,
,
а числовые характеристики М(Х)= 1/a, D(X)= 1/a2.
Эти формулы можно использовать при решении задач.
4. МЕТОДИЧЕСКИЕ УКАЗАНИЯ К ВЫПОЛНЕНИЮ ЗАДАНИЯ № 5
Математическая статиcтика изучает массовые явления и процессы, ставя целью получение выводов по данным наблюдений за ними. В результате появляются утверждения об общих характеристиках таких явлений в предположении постоянства начальных условий явления. Теоретической основой математической статистики является теория вероятностей.
Поскольку число наблюдений конечно, их результаты можно записать в таблицу аналогично дискретной случайной величине, только в нижней строке не вероятности, а частоты тех или иных значений, а чаще – диапазонов. При этом при анализе такой таблицы нередко возникает предположение, что данная величина распределена по одному из известных непрерывных законов (см. комментарии к задаче № 4), чаще всего – нормальному (гауссовскому).
Типовой пример
Получены статистические данные (N=500) зависимости результатов измерения роста студентов (Х) от окружности груди (Y). Измерения проводились с точностью до 1 см.
Таблица 1
Статистические данные типового примера
N | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
X | 172 | 172 | 163 | 187 | 172 | 161 | 176 | 164 | 166 | 168 | 162 | 163 |
Y | 88 | 91 | 89 | 99 | 90 | 85 | 88 | 84 | 82 | 82 | 82 | 89 |
…………..

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
