
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
На правах рукописи
УДК 81’04
Ларионова
Елена Александровна
Применение IT в исследовании грамматических категорий
Выпускная работа по
«Основам информационных технологий»
Магистранта кафедры русского языка
Специальность: 10.02.02 – русский язык
Научные руководители:
кандидат филологических наук Долбик Е. Е.
Старший преподаватель
Минск 2012
Оглавление
Оглавление. 2
Список обозначений. 3
Введение. 4
Глава 1 Взаимодействие IT и филологии. 5
Глава 2 Использование «Национального корпуса русского языка» при исследовании грамматической категории определенности/неопределенности. 7
Глава 3 Использование текстового редактора MS Word при работе с грамматической категории определенности / неопределенности. 11
Заключение. 12
Библиографический список. 13
. 15
Предметный указатель. 15
16
Интернет ресурсы в предметной области исследования. 16
. 19
Действующий личный сайт: http://www. anelja. *****. 19
20
Граф научных интересов. 20
. 21
Тестовые вопросы по Основам информационных технологий. 21
22
Созданная статья в Википедии и Print SCreen страницы.. 22
. 23
Презентация магистерской диссертации. 23
Список обозначений
НКРЯ – Национальный корпус русского языка;
АПТ – автоматическое понимание текстов;
ИТ – информационные технологии;
КЛ – компьютерная лингвистика;
О/НО – определенность/неопределенность;
ТФГ – теория функциональной грамматики.
Введение
Информатизация общества связана с расширением сферы применения информационных технологий. В процесс информатизации, затронувший практически все области знания, вовлекаются и социально-гуманитарные науки. В связи с непрерывным совершенствованием технических характеристик и программного обеспечения персональные компьютеры становятся все более привлекательным и эффективным инструментом исследований в гуманитарных науках, создаются реальные возможности для применения новых информационных технологий в работе гуманитария.
Актуальность данной работы обусловлена тем, что вопросы поиска, анализа и обработки информации имеют большое значение для филологов. Современные компьютеры и программное обеспечение позволяют применить широкий класс математических методов анализа неструктурированных данных для обработки больших массивов документов, эффективно решая задачи поиска информации, классификации, кластерного анализа, выявления скрытых закономерностей и другие. В современных прикладных исследованиях достаточно часто в качестве основного инструмента изучения языка и речи используются количественные или статистические методы анализа. В этих условиях математика, информатика и информационные технологии играют все более значительную роль в обучении филологов.
Целью нашего реферата является выявление и описание современных средств IT, которые применяются при исследовании грамматических категорий (на примере категории определенности/неопределенности). Для достижения поставленной цели следует решить следующие задачи:
1. Познакомиться с литературой, посвященной взаимодействию ИТ и филологии.
2. Определить методы исследования грамматических категории (на примере категории определенности/неопределенности) и оценить эффективность этих методов, проверив их на практике.
Глава 1
Взаимодействие IT и филологии
Использование ИТ значительно увеличивает эффективность функционирования любой сферы человеческой деятельности. Лингвистика не является исключением. Неоспоримая связь между ними подтверждается фактом существования компьютерной лингвистики (КЛ) – «направления в прикладной лингвистике, ориентированного на использование компьютерных инструментов – программ, компьютерных технологий организации и обработки данных – для моделирования функционирования языка в тех или иных условиях, ситуациях, проблемных сферах и т. д., а также всей сферы применения компьютерных моделей языка в лингвистике и смежных дисциплинах» [Зубов 2004, с. 8]. Более того, если учесть, что главным предметом исследования в лингвистике являются тексты и что именно современные ИТ открывают новые возможности для обработки и анализа текстов и предоставляют разнообразные средства создания, распространения, поиска и учета текстовой информации, связь и взаимодействие этих двух сфер становятся еще более очевидными.
Среди существующих литературных источников, посвященных применению ИТ в лингвистике, стоит отметить следующие: «Информационные технологии в лингвистике» , «Основы искусственного интеллекта для лингвистов» и , «Автоматическое понимание текстов: системы, модели, ресурсы» Н. Н. Леонтьева, «Компьютерная обработка лингвистических данных» А. В. Всеволодовой.
В учебном пособии «Информационные технологии в лингвистике» А. В. Зубов определяет прикладную лингвистику (ПЛ) как особую область лингвистики, которая осуществляет реализацию лингвистических знаний с целью решения всякого рода практических задач, а также как раздел языкознания, в котором разрабатываются методы решения практических задач, связанных с оптимизацией использования языка как важнейшего средства человеческой коммуникации.
Затем автор дает определение ИТ как «совокупности законов, методов и средств получения, хранения, передачи, распространения, преобразования информации с помощью компьютеров» [Зубов 2004, с. 8]. Кроме того, А. В. Зубов конкретизирует определение понятия «ИТ» по отношению к лингвистике и замечает, что ИТ в лингвистике – «это совокупность законов, методов и средств получения, хранения, передачи, распространения, преобразования информации о языке и законах его функционирования с помощью компьютеров» [Зубов 2004, с. 8].
В учебном пособии «Основы искусственного интеллекта для лингвистов» и заостряют внимание на том, что «необходима глубокая интеграция ИТ с лингвистическими и психологическими знаниями в рамках искусственного интеллекта» [Зубов 2007, с. 10], что «современное состояние исследований по искусственному интеллекту характеризуется нарастанием интереса к этой проблеме со стороны специалистов широкого профиля, в том числе и лингвистов» [Зубов 2007, с. 10].
Учебное пособие «Автоматическое понимание текстов: системы, модели, ресурсы» обобщает опыт создания российских и зарубежных систем, реализующих АПТ. Эти сложные интеллектуальные системы выделяются из множества систем, в которых просто используется автоматическая обработка текста, поскольку автора интересует именно качественный аспект понимания. Рассмотрены те компоненты процесса АПТ, которые могут быть заданы в вербальном виде. В основе пособия – идея «мягкого» понимания текста. Представлена экспериментальная лингвистическая система ПОЛИТЕКСТ, осуществляющая гибкое соединение лингвистических и предметных знаний.
Глава 2
Использование «Национального корпуса русского языка» при исследовании грамматической категории определенности/неопределенности
Основное понятие корпусной лингвистики – это корпус текстов (или письменный текстовый массив), под которым понимается большой, представленный в электронном виде, унифицированный, структурированный, размеченный, филологически компетентный массив языковых данных, предназначенный для решения конкретных лингвистических задач». Зубов дает такое определения корпуса: «Корпус текстов — это совокупность текстов, являющаяся достаточной для обеспечения надежных научных выводов о некотором языке, диалекте или ином другом подмножестве языка» [Зубов 2004, с. 166].
Наиболее известными являются Британский национальный корпус английского языка немецкоязычные корпуса LIMAS, COSMAS. Можно выделить также такие корпуса как Венгерский национальный корпус, Корпус современного итальянского языка, Польский национальный корпус и многие другие. Особый интерес представляет собой Национальный корпус русского языка с базой более 70 млн. слов.
Первоначально корпусы текстов использовались преимущественно для статистических подсчетов, выявления частотности того или иного языкового элемента: графемы, морфемы, словосочетания.
Сегодня корпусы текстов используются практически во всех областях лингвистических исследований: лексикология, фразеология, словообразование, морфология, фонетика и фонология, синтаксис, семантика, прагматика и др. Так, при исследовании лексикографии и лексикологии корпусы используются для составления различных словарей, составления ассоциативных связей слов в тексте, выделения терминов и терминологических словосочетаний. Преимущество использования корпуса текстов в таких исследованиях в том, что на их основе словари могут составляться гораздо быстрее, чем раньше, появляется возможность фиксировать текущее состояние языка, информация, собранная с помощью корпуса, не успевает устареть к моменту выхода готового словаря.
Анализ на основе корпуса текстов расширяет возможности в исследовании семантики. С целью выявления семантических признаков лингвистической единицы необходимо наблюдение данной единицы в различных контекстах. При вхождении слова сразу в несколько семантических категорий возникает вопрос о степени принадлежности слова к той или иной категории. Эта степень может быть вычислена путем подсчета частот распределения слова по разным категориям.
В грамматике корпусы применяются для определения частоты грамматических морфем различного типа, частоты употребления классов слов и т. д., в лингвистике текста – для дифференциации типов текста, создания конкордансов, выявления связи между предложениями в абзацах и между абзацами и т. д.
Среди достоинств исследований языка на базе корпусов лингвисты отмечают возможность анализа огромных массивов текстов, что гарантирует надежность полученных данных, возможность получения реальных контекстов, реальных статистических данных. Кроме того, однажды созданный корпус текстов может служить для решения многочисленных и очень разнообразных исследований.
Корпусы текстов могут использоваться лингвистами для различных целей. В зависимости от этих целей выделяют несколько видов корпусов:
· исследовательские корпусы текстов создаются с целью изучения различных аспектов функционирования языка. Как правило, такие корпусы текстов содержат несколько десятков миллионов словоупотреблений;
· с помощью иллюстративных корпусов выделяются лингвистические примеры, подтверждающие те или иные языковые (речевые, текстовые) факты, обнаруженные ранее иными лингвистическими приемами;
· тексты какого-то небольшого временного промежутка содержатся в статических корпусах текстов;
· в динамические корпусы текстов включают письменные источники большого временного периода, используются такие корпусы для диахронических исследований;
· корпусы параллельных текстов включают в себя множество текстов-оригиналов, написанных на каком-либо исходном языке, и текстов-переводов этих исходных текстов на один или несколько других языков. Такие корпусы текстов являются базой для проведения сравнительно-сопоставительных исследований.
Созданию корпуса текстов того или иного языка предшествует этап тщательной подготовки, в ходе которой решается ряд вопросов, проблем и задач. Необходимо определить потенциальных пользователей данного ресурса (индивид, группа, лингвистическое общество), основную логическую идею корпуса, объем используемых данных, принципы отбора текстов в корпус.
Определение исходного объема области, из которой должны быть сделаны выборки, происходит путем проведения предварительных экспериментов. Одним из важнейших понятий корпусной лингвистики является понятие репрезентативности, под которой понимается «необходимо-достаточное и пропорциональное представление в корпусе текстов различных периодов, жанров, стилей, авторов и т. п.» [Захаров 2005, с. 4]. Корпус текстов, по существу, должен представлять собой уменьшенную модель языка или подъязыка, поэтому важно соблюсти пропорциональное отношения между текстами различных исходных областей. Захаров отмечает, что применительно к общеязыковому (национальному) корпусу текстов невозможно рассчитать и описать понятие репрезентативности строго математически, однако к этому необходимо стремиться.
Использование Национального корпуса при изучении категории определенности помогает при составлении статистических данных. Специфика исследуемой категории состоит в том, что она представлена системой разноуровневых средств. В русском языке специфических, стабильно и обязательно выступающих средств выражения для передачи значений О/НО нет. Тем не менее категория О/НО выражается в русском языке совокупностью разнородных языковых средств. Акцентно-просодические средства выражения категории О/НО (порядок слов и фразовая интонация) составляют линейно-интонационный центр поля О/НО в русском языке. При этом существует корреляция межу ФСП О/НО и актуальным членением. центр местоименных детерминативов образуют неопределённые местоимения один, а также указательные местоимения этот. Неопределённые и указательные местоимения (какой-нибудь, некий, кое-какой, кое-что, кое-кто, кто-то, что-то, кто-нибудь, кто-либо, что-нибудь, какой-нибудь, некоторый, некий, чей-то, чей-нибудь, чей-либо, некогда, кое-когда, кое-куда, кое-откуда, где-то, где-нибудь, где-либо, всякий, тот, такой и др.), личные местоимения, прилагательные типа неизвестный, данный, несметный, неопределенный, известный, следующий, существительные куча, толпа, вещь, человек, народ, люди, вещь, штука, частицы ещё, ведь, же, вот, это, вот и составляют периферию ФСП О/НО. что на синтаксическом уровне категория О/НО выражается с помощью определенно-личных, неопределенно-личных, обобщенно-личных предложений. Средством выражения О/НО является также согласование счетной конструкции с глаголом («правило Потебни»).
Национальный корпус удобен для построения статистических данных, так как включает большое количество текстов, что позволяет говорить о презентаттивности выборке.
Кроме того, в магистерской диссертации исследуются тексты художественные (поэтические и драматические), а также публицистические. Наличие поэтического и газетного корпуса позволяют провести достаточно масштабное исследование грамматической категории.
Глава 3
Использование текстового редактора MS Word при работе с грамматической категории определенности / неопределенности
Исследование грамматической категории проводится с помощью сплошной выборки. MS Word очень удобен для осуществления данного метода, так как вручную исследовать большой объем текста представляется весьма кропотливой работой. Редактор MS Word ускоряет этот процесс и обеспечивает надежную выборку по заданным параметрам. Так, для осуществления выборки функция «Найти». В окне вводится искомое слово. В результате узнаем имеющееся количество единицы в тексте.
В своей работе я исследовала текст А. Курейчика «Потерянный рай». Благодаря функции «Найти» легко посчитать количество используемых местоимений, которые представляют микрополе определенности и микрополе неопределенности. частотность употребления указательных местоимений в пьесе «Потерянный рай» выше, чем неопределённых. Так, частотность местоимения этот – 0,67%, тот – 0,03%, такой – 0,23%; неопределенных местоимений с формантом –то – 0,18%, - нибудь – 0,07%, лексемы один – 0,08%. Таким образом, указательные местоимения составляют 0,93%, а неопределённые – 0,33%.
Заключение
Применение позволяет получить результат в кратчайшие сроки. Интернет расширяет возможности исследователя, дает ему в руки мощный и эффективный инструмент обработки художественного текста и поиска необходимой информации. применение ИТ в филологических исследованиях является весьма эффективным. работы. Для наиболее интенсивного развития науки, филологии в частности, внедрение ИТ необходимо.
Важнейшая роль информационных технологий (ИТ) в развитии постиндустриального общества признана повсеместно. На то указывают статистические данные, доклады ЮНЕСКО, тематика исследовательской и практической деятельности Российской академии наук.
В ходе реферативного исследования мы показали, что интерес к тексту является не только сферой интереса лингвистики, но и сферой интереса IT. Этот взаимный интерес уже развивается в рамках такой дисциплины как компьютерная лингвистика, однако требует пристального внимания и представителей направления лингвистического анализа текста. Непосредственная работа с грамматической категорией значительно облегчается существованием текстового редактора MS Word, а обработка лексем, составляющих текст, упрощается благодаря существованию электронных ресурсов с базами электронных словарей.
Библиографический список
1. Вигурский, издания и электронные библиотеки как специфический вид автоматизированных информационные систем / К. Вигурский // Межотраслевая информационная служба, Вып. 1, 1999. – С. 7-15.
2. Вигурский, и современные информационные технологии (К постановке проблемы) / К. Вигурский, И. Пильщиков // Известия Российской академии наук. Сер. лит. и яз., Т. 62, № 2, 2003. – С. 9-16.
3. Всеволодова, обработка лингвистических данных / . – 2–е изд., исправленное. – Москва: Флинта: Наука, 2007. – 90 с.
4. Захаров, лингвистика: Учебно-метод. пособие / В. П. Захаров. – Санкт-Петербург, 2005. – 48 с.
5. Зубов, технологии в лингвистике: Учеб. пособие для студ. лингв. фак–тов высш. учеб. заведений / , . – М.: Академия, 2004. – 208 с.
6. Зубов, искусственного интеллекта для лингвистов: Учеб. пособие / , . – М.: Университетская книга; Логос, 2007. – 320 с.
7. Лабовкин, технологии для филологов / , . – Витебск: Издательство ВГУ, 2005. – 55 с.
8. Леонтьева, понимание текстов: системы, модели, ресурсы: учеб пособие для студ. лингв. фак. вузов / . – М.: Академия, 2006. – 304 с.
9. Поляков, подготовки информации в Национальном корпусе русского языка / А. Е. Поляков. –http://*****/sbornik2005/11polyakov. pdf – Дата доступа: 20.11.2011
10. Электронный ресурс: http://*****/default. aspx? p=3053. Дата доступа: 17.10.2012.
11. Электронный ресурс: http://**/search. xml? env=alpha&mycorp=&mysent=&mysize=&mysentsize=&spd=&text=lexgramm&mode=main&sort=gr_tagging&lang=ru&nodia=1&parent1=0&level1=0&lex1=&gramm1=A%2Cplen%20%26%20A&sem1=r%3Aqual%20%26%20t%3Ahumq%20%26%20(ev%20%7C%20ev%3Aposit%20%7C%20ev%3Aneg)&sem–mod1=sem2&sem–mod1=semf&sem–mod1=semf2&flags1=&m1=&parent2=0&level2=0&min2=1&max2=1&lex2=&gramm2=S&sem2=r%3Aconcr%20%26%20t%3Atool%3Acloth%20%26%20(pt%3Apart%20%26%20pc%3Atool%3Acloth)&sem–mod2=sem2&sem–mod2=semf&sem–mod2=semf2&flags2=&m2=&p=7 Дата доступа: 18.11.2012
Приложение А
Предметный указатель
И
информационные технологии, 12
К
компьютерная лингвистика, 5
Корпус текстов, 7, 8, 9
Корпусная лингвистика, 7, 9
Н
Национальный корпус, 9
П
прикладная лингвистика, 5
С
сплошная выборка, 11
Т
текстовый редактор MS Word, 11, 12
Приложение Б
Интернет ресурсы в предметной области исследования
http://**/: совместный интернет–проект московского издательства ОГИ и кафедры русской литературы Тартуского университета. Основная задача сайта – информировать читателей о текущих событиях научной жизни, памятных датах, ресурсах интернета.
http://www. philsoc. org. uk/default. asp/: Сайт Международного филологического общества. Членом The Philological Society может стать каждый лингвист. Участие в The Philological Society дает возможность публиковать свои работы в специальном издании общества. Также проводятся конференции, работает форум лингвистов со всего мира.
http://iling. *****/: Сайт Института лингвистических исследований Российской академии наук (ИЛИ РАН) – главного лингвистического институт России. Располагает библиотекой по общему языкознанию, разделом периодики и разделом публикаций, где размещены работы крупнейших российских лингвистов. Постоянно обновляется информация о конференциях.
http://www. ling–phil. ox. ac. uk/index. php? section=1: Faculty of Linguistics, Philology & Phonetics. Факультет лингвистики, филологических исследований и фонетики Оксфорда. Можно познакомиться с кругом научных интересов и лингвистическими разработками исследователей из Оксфорда, в том числе касающихся Russian Studies. Содержит информацию о конференциях и семинарах.
http://www. *****/: библиотека современной русской литературы. Содержит обширную подборку современной поэзии, разгруппированной по авторам. Также располагает разделом критических статей и исследований.
http://www. *****/: Институт грамматологии. Исследования в области нарратологии. Обширная библиотека от классиков формализма до современных зарубежных трудов по нарратологии. Проект русскоязычного учебника по нарратологии.
http://ifi. *****/: Институт филологии и истории РГГУ. Аппарат ссылок на различные сайты филологических сообществ, библиотек и на персональные страницы крупнейших исследователей.
http://www. ifw. filg. uj. edu. pl/: Instytut Filologii Wschodniosłowiańskiej Uniwersytetu Jagiellońskiego. Институт восточнославянских языков Ягеллонского университета. Сайт располагает материалами о ближайших конференциях, можно познакомиться с последними разработками польских исследователей русского, белорусского и украинского языков. Также содержит информацию о стажировках и стипендиях.
http://www. *****/: Филологический портал, на котором компактно представлена различная информация, касающаяся филологии как теоретической и прикладной науки. Центральным разделом портала является библиотека филологических текстов (монографий, статей, методических пособий).
http:///: Сайт посвящен лингвистике в Беларуси, проблемам и перспективам развития этой науки. Особенно интересен тем, что здесь можно найти нужные белорусскому филологу книги, публикации, информацию о конференциях.
http://www. filologdirect. *****: портал филолога, на котором представлены работы по филологии. По своей сути проект является полностью рецензируемым и научно достоверным периодическим электронным изданием гуманитарной направленности.
http://www. helpforlinguist. *****/: Информационно-образовательный портал для лингвистов, переводчиков и всех, кто интересуется языком,
http://www. philol. *****/: Сайт филологического факультета Московского государственного университета, полезный, в первую очередь, своей богатой электронной библиотекой научных и научно-методических изданий.
http://philologos. *****/: Сайт филологического факультета МГУ им. .
Сайт предлагает вниманию пользователей постоянно обновляющиеся материалы по теории языка и литературы.
http://www. *****: На этом справочно-информационном портале особый интерес представляют закладки «Словари» и «Библиотека». В первом случае находим внушительный список ссылок на различные словари русского языка.
http://*****ssian. slavica. org/: Сайт "Балканская Русистика" отличается тем, что предлагает множество статей, авторефератов, публикаций на актуальные лингвистические и литературоведческие темы. Кроме того, присутствует рубрика, где регулярно появляются полезные ссылки.
http://www. philol. *****: Сайт Вестника МГУ (Серия филология). Ведущий российский университет, центр филологических исследований с мировым именем. Можно знакомиться с материалами, которые публикуются в Вестнике.
http://www. *****/: На сайте Фундаментальной электронной библиотеки представлены материалы, которые печатались в Известиях Российской академии наук. Серия литературы и языка. Можно познакомиться с материалами с 1852 года.
http://linguistlist. org/: крупнейший сетевой ресурс для лингвистов всего мира. Сайт содержит более 2000 страниц, обладает богатым архивом публикаций по различным направлениям лингвистики (теоретической и прикладной), содержит обширный каталог лингвистических интернет-ресурсов, предоставляет широкий обзор мировой литературы, посвящённой изучению естественных и искусственных языков.
http://www. *****/soft/catalogue/catalogue. html: каталог, который включает в себя описание программ, связанных с анализом текстов и вычислительной лингвистикой, а также соответствующих ресурсов, доступных сегодня в глобальной сети Интернет. Упор при составлении каталога делается на бесплатные программы, доступные для загрузки. Однако также описаны некоторые on-line и коммерческие версии программ.
http://*****: сайт инновационной компании, создающей технологии анализа текстов на естественном языке.
http://*****/index. php? id-dict: новосибирская инновационная компания. В рамках ее исследовательских интересов находится в том числе разработки в области текстов, инженерии знаний, систем и средств искусственного интеллекта. На сайте представлен комплект лингвистических баз данных – словари RU. DICT.
http://*****: компания Russian Context Optimizer занимается разработкой технологий анализа и поиска текстовой информации. На сайте можно найти серию продуктов, разработанных RCO, а также ряд статей в области компьютерной лингвистики.
http://tpl-it. : проект студентов специальности «Теоретическая и прикладная лингвистика» и магистрантов Иркутского государственного лингвистического университета
http://*****: Национальный корпус русского языка. Содержит более 300 млн. слов.
http://ru. wikiversity. org/wiki/0: Информационные_технологии_в_филологии# – много полезной информации о возможностях использования ИТ в лингвистике.
http://*****/participants. html#Polymorph: представлен список морфологических парсеров русского языка.
Приложение В
Действующий личный сайт: http://www. anelja. *****
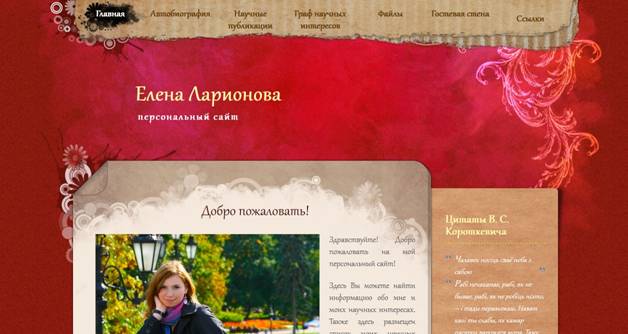
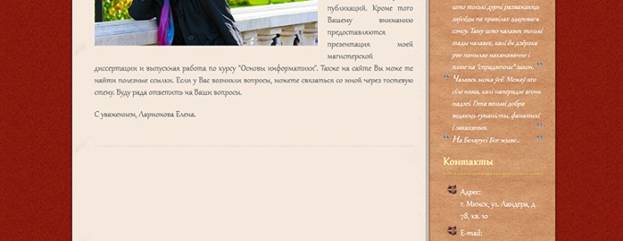

1 – PrintScreen главной страницы
Приложение Г
Граф научных интересов
Магистрантки филологического факультета
специальности «языкознание»
Смежные специальности
| Основная специальность
| Сопутствующие специальности
|
Приложение Д
Тестовые вопросы по Основам информационных технологий
<question type="close" id="">
<text>01 Какой запрос в Google позволит найти ссылки, содержащие слово «лингвистика» и его синонимы? </text>
<answers type="request">
<answer id="1" right="0"> +лингвистика </answer>
<answer id="2" right="1"> ~лингвистика </answer>
<answer id="3" right="0"> лингвистика*синонимы </answer>
<answer id="4" right="0"> - лингвистика </answer>
</answers>
</question>
<question type="close" id="">
<text>02 Какой тип разметки в корпусе текстов фиксирует информацию об авторе? </text>
<answers type="request">
<answer id="1" right="0"> просодическая разметка </answer>
<answer id="2" right="0"> семантическая разметка </answer>
<answer id="3" right="1"> метаразметка </answer>
<answer id="4" right="0"> анафорическая разметка </answer>
</answers>
</question>
Приложение Е
Созданная статья в Википедии и Print SCreen страницы
http://ru. wikipedia. org/wiki/%D0%9A%D0%B0%D1%82%D0%B5%D0%B3%D0%BE%D1%80%D0%B8%D1%8F_%D0%BE%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B8/%D0%BD%D0%B5%D0%BE%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B8
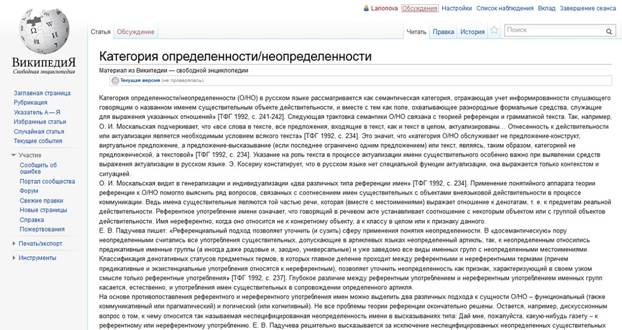

Рисунок Е1 – PrintScreen страницы Википедии
Приложение Ж
Презентация магистерской диссертации



