

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Критерий Бартлета. Пусть генеральные совокупности Х1, Х2,…,Хl распределены нормально. Из этих совокупностей извлечены независимые выборки различных объемов ni . По выборкам найдены исправленные дисперсии ![]() ,
,![]() ,…,
,…,![]() . Требуется на уровне значимости α проверить нулевую гипотезу:
. Требуется на уровне значимости α проверить нулевую гипотезу:
Н0: ![]() =
=![]() =….=
=….=![]() .
.
В качестве выборочной характеристики используется статистика, предложенная Бартлетом: ![]() =
=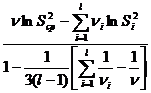 , (3.26)
, (3.26)
При ![]() >3 величина
>3 величина ![]() приближенно имеет
приближенно имеет ![]() распределение с ν= l-1 степенями свободы, где l - число выборок;
распределение с ν= l-1 степенями свободы, где l - число выборок; ![]() -исправленная выборочная дисперсия i – ой выборки;
-исправленная выборочная дисперсия i – ой выборки; ![]() =
=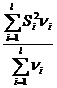 - среднее значение исправленной дисперсии по всем l выборкам.
- среднее значение исправленной дисперсии по всем l выборкам.
Правило. Для проверки нулевой гипотезы строят правостороннюю критическую область, границы которой ![]() находят по таблице
находят по таблице ![]() распределения из условия: P (
распределения из условия: P (![]() >
>![]() (α; ν=l-1)= α. (3.27)
(α; ν=l-1)= α. (3.27)
Если ![]() <
< ![]() - нет оснований отвергнуть нулевую гипотезу, если
- нет оснований отвергнуть нулевую гипотезу, если ![]() >
> ![]() - нулевую гипотезу отвергают.
- нулевую гипотезу отвергают.
Критерий Кохрана. Данный критерий применяется для проверки на уровне значимости α нулевой гипотезы Н0: ![]() =
=![]() =….=
=….=![]() по выборкам разных объемов ni. В качестве выборочной характеристики используется статистика, предложенная Кохраном: G=
по выборкам разных объемов ni. В качестве выборочной характеристики используется статистика, предложенная Кохраном: G=![]() , (3.28)
, (3.28)
имеющая G – распределение с числом степеней свободы ν1= n –1 и ν2= l, где l – число сравниваемых совокупностей.
Для проверки нулевой гипотезы строят правостороннюю критическую область, границу которой Gкр определяют по таблице G – распределения, исходя из условия: P (Gн > Gкр (α; ν))= α. (3.29)
Если Gн < Gкр - то нулевая гипотеза не отвергается.
Гипотеза об однородности ряда вероятностей
Пусть Х1, Х2,…,Хl - l генеральных совокупностей, каждая из которых характеризуется неизвестным параметром Рi, где Рi - вероятность появления события А в соответствующей выборке. Требуется на уровне значимости α проверить нулевую гипотезу Н0: р1= p2 =… = pl.
Для проверки гипотезы используется статистика
![]() =
= 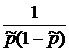
![]() , (3.30)
, (3.30)
которая имеет асимптотическое ![]() распределение с ν= l-1 степенями свободы, l - число выборок;
распределение с ν= l-1 степенями свободы, l - число выборок;
где ![]() =
= ![]() - частость появления события А в i–ой выборке;
- частость появления события А в i–ой выборке;
![]() - частота появления события А в i–ой выборке;
- частота появления события А в i–ой выборке;
![]() - объем i–ой выборки;
- объем i–ой выборки;
![]() =
=![]() – частость появления события А во всех выборках;
– частость появления события А во всех выборках;
![]() =(1-
=(1-![]() ) – частость появления события
) – частость появления события ![]() , противоположного событию A, во всех выборках.
, противоположного событию A, во всех выборках.
Для проверки нулевой гипотезы строят правостороннюю критическую область, границу которой определяют из условия: P (![]() >
>![]() (α; ν))= α. (3.31)
(α; ν))= α. (3.31)
Если ![]() <
< ![]() - нет оснований отвергнуть нулевую гипотезу, если
- нет оснований отвергнуть нулевую гипотезу, если ![]() >
> ![]() - нулевую гипотезу отвергают.
- нулевую гипотезу отвергают.
Гипотезы о виде законов распределения генеральной совокупности
Проверка гипотез о виде законов распределения генеральной совокупности осуществляется с помощью критериев согласия.
Критерием согласия называется статистический критерий, предназначенный для проверки гипотезы Н0 о том, что ряд наблюдений х1, х2,…хn образует случайную выборку, извлеченную из генеральной совокупности Х с функцией распределения F(x)=F(x;θ1; θ2;… θk), где общий вид функции F(x) считается заданным, а параметры θ1; θ2;… θk , от которых она зависит могут быть, как известными, так и неизвестными. Критерии согласия основаны на использовании различных мер расстояний между анализируемой эмпирической функцией распределения Fn(x), определяемой по выборке, и функцией распределения F (x) генеральной совокупности Х.
Математически, нулевую гипотезу можно записать в следующем виде:
Н0: ![]() =р1,
=р1, ![]() = р2,
= р2, ![]() = рl,
= рl,
![]() - относительная частота i-го интервала вариационного ряда или i-го варианта, принимаемого случайной величиной Х;
- относительная частота i-го интервала вариационного ряда или i-го варианта, принимаемого случайной величиной Х;
рl – вероятность попадания случайной величины в i-тый интервала или вероятность того, что дискретная величина примет i-тое значение (Х=хi).
Критерий Пирсона (критерий - ![]() ) имеет наибольшее применение при проверке согласования теоретической и эмпирической функций распределения.
) имеет наибольшее применение при проверке согласования теоретической и эмпирической функций распределения.
Процедура проверки статистической гипотезы о виде распределения с помощью критерия согласия Пирсона состоит из следующих этапов.
1. Весь диапазон значений исследуемой случайной величины разбивается на ряд интервалов группирования Δ1, Δ2, …,Δl, необязательно одинаковой длины.
2. Подсчитывается число точек, попавших в каждый из интервалов группирования Δi.
3. На основе сгруппированных данных вычисляются оценки ![]() k неизвестных параметров распределения θ k.
k неизвестных параметров распределения θ k.
4. Вычисляется вероятность рi попадания случайной величины Х в каждый из интервалов группирования Δi.
5. Вычисляется наблюдаемое значение статистики критерия
![]() =
=![]() , (3.32)
, (3.32)
![]() сравнивается с табличным значением
сравнивается с табличным значением ![]() , найденным для уровня значимости α и числа степеней свободы ν = l-k-1, где l - число интервалов, k – число параметров, которыми определяется функция распределения.
, найденным для уровня значимости α и числа степеней свободы ν = l-k-1, где l - число интервалов, k – число параметров, которыми определяется функция распределения.
Если ![]()
![]()
![]() , то гипотеза о том, что генеральная совокупность Х подчиняется закону распределения F (x) принимается.
, то гипотеза о том, что генеральная совокупность Х подчиняется закону распределения F (x) принимается.
В случае нормального закона распределения вероятность попадания случайной величины Х в соответствующие интервалы вычисляется по интегральной теореме Лапласа: рi = Р(аi<x<bi) =![]()
![]() , (3.33)
, (3.33)
где t1i = ![]() , t2i =
, t2i = ![]() ; аi, bi – нижняя и верхняя граница соответствующего интервала i.
; аi, bi – нижняя и верхняя граница соответствующего интервала i.
Контрольные вопросы и задачи
3.1. По результатам 15 испытаний установлено, что среднее время изготовления детали ![]() = 28с. В предположении, что время изготовления детали является нормальной случайной величиной с известным генеральным средним квадратическим отклонением
= 28с. В предположении, что время изготовления детали является нормальной случайной величиной с известным генеральным средним квадратическим отклонением ![]() =1,2с, на уровне значимости
=1,2с, на уровне значимости ![]() =0,05 проверить гипотезу Н0: μ= 30 с против конкурирующей гипотезы Н1: μ= 25с.
=0,05 проверить гипотезу Н0: μ= 30 с против конкурирующей гипотезы Н1: μ= 25с.
3.2. На основании 20 измерений, было установлено что средняя длина трубы равна ![]() = 15,4м, а s=0,23м. В предположении о нормальном законе распределения на уровне значимости
= 15,4м, а s=0,23м. В предположении о нормальном законе распределения на уровне значимости ![]() =0,05 проверить гипотезу Н0: μ= 15м против конкурирующей гипотезы Н1: μ 15м.
=0,05 проверить гипотезу Н0: μ= 15м против конкурирующей гипотезы Н1: μ 15м.
3.3. По данным задачи 3.2 проверить на уровне значимости ![]() =0,05 гипотезу Н0:
=0,05 гипотезу Н0:![]() =0,06 м2 при конкурирующей гипотезе Н1: =0,03 м2.
=0,06 м2 при конкурирующей гипотезе Н1: =0,03 м2.
3.4. По двум независимым выборкам объемом ![]() n1=30 и n2=15, извлеченным из нормальных генеральных совокупностей, найдены выборочные средние
n1=30 и n2=15, извлеченным из нормальных генеральных совокупностей, найдены выборочные средние ![]() =25 и
=25 и ![]() =27. Дисперсии генеральных совокупностей известны
=27. Дисперсии генеральных совокупностей известны ![]() =1,3 и
=1,3 и ![]() =1,6. На уровне значимости
=1,6. На уровне значимости ![]() =0,1 проверить гипотезу Н0: μ1= μ2 при конкурирующей гипотезе Н1: μ1
=0,1 проверить гипотезу Н0: μ1= μ2 при конкурирующей гипотезе Н1: μ1![]() μ2.
μ2.
3.5. Для сравнения точности изготовления деталей двумя станками-автоматами взяты две выборки объемом n1=12 и n2=8. По результатам измерений контролируемого размера деталей вычислены средние ![]() =31,5мм и
=31,5мм и ![]() =30,2мм, а также исправленные выборочные дисперсии
=30,2мм, а также исправленные выборочные дисперсии ![]() =1,05мм2 и
=1,05мм2 и ![]() =0,86мм2. Проверить на уровне значимости
=0,86мм2. Проверить на уровне значимости ![]() =0,05 гипотезу Н0:
=0,05 гипотезу Н0: ![]() =
=![]() при конкурирующей гипотезе Н1:
при конкурирующей гипотезе Н1: ![]() >
>![]() .
.
3.6. По четырем независимым выборкам объемом n1 =12, n2=8, n3=13, n4=11, извлеченным из нормальных генеральных совокупностей, найдены выборочные исправленные дисперсии ![]() =2,1,
=2,1, ![]() =1,9,
=1,9, ![]() =2,2,
=2,2, ![]() =2,3. Проверить на уровне значимости
=2,3. Проверить на уровне значимости ![]() =0,05 гипотезу об однородности дисперсий Н0:
=0,05 гипотезу об однородности дисперсий Н0: ![]() =
=![]() =….=
=….=![]() .
.
3.7. Для сравнения точности работы четырех станков из продукции каждого станка взято по одной выборке из 25 деталей. По результатам измерений найдены несмещенные оценки дисперсий ![]() =0,1,
=0,1, ![]() =0,19,
=0,19, ![]() =0,2,
=0,2, ![]() =0,13. Допустив, что погрешность есть нормальная случайная величина, проверить при уровне значимости
=0,13. Допустив, что погрешность есть нормальная случайная величина, проверить при уровне значимости ![]() =0,05 гипотезу о том, что точность станков одинакова.
=0,05 гипотезу о том, что точность станков одинакова.
3.8. Для сравнения качества работы четырех сборочных конвейеров из общего дневного объема продукции каждого конвейера отобрано соответственно n1 =20, n2=26, n3=18, n4=24 изделий, из которых оказались дефектными m1=2, m2=4, m3=1, m4=2. На уровне значимости ![]() =0,05 проверить гипотезу о том, что вероятности появления дефектного изделия на всех станках равны, т. е. Н0: р1= p2 = p3 = p4.
=0,05 проверить гипотезу о том, что вероятности появления дефектного изделия на всех станках равны, т. е. Н0: р1= p2 = p3 = p4.
Тема 5. Методика статистического анализа количественных и качественных показателей
Корреляционный анализ является методом исследования взаимозависимости признаков в генеральной совокупности. Основная задача корреляционного анализа состоит в оценке корреляционной матрицы генеральной совокупности по выборке и определении на ее основе оценок коэффициентов корреляции.
В рамках реализации статистических процедур корреляционного анализа необходимо: выбрать (с учетом специфики и природы анализируемых переменных) подходящий измеритель статистической связи (коэффициент корреляции, корреляционное отношение, ранговый); оценить с помощью точечной и интервальной оценок его числовое значение по выборочным данным; проверить гипотезу о том, что полученное числовое значение анализируемого измерителя связи действительно свидетельствует о наличии статистической связи.
Парная корреляция занимается изучением характеристик взаимосвязи двух случайных величин. Корреляционная зависимость двух случайных величин задается моделью X=X(Y,Z) и Y= Y(Х,Z), где Z – набор внешних случайных факторов.
Основой получения этих характеристик служит совместное распределение случайных величин F(x,y) = P![]() .
.
Плотность двумерного нормального закона распределения определяется пятью параметрами: ![]() - математическое ожидание Х;
- математическое ожидание Х; ![]() - математическое ожидание Y;
- математическое ожидание Y; ![]() - дисперсия Х;
- дисперсия Х; ![]() - дисперсия Y;
- дисперсия Y; ![]()
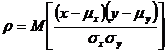 - парный коэффициент корреляции между Х и Y.
- парный коэффициент корреляции между Х и Y.
Парный коэффициент корреляции характеризует тесноту линейной связи между двумя переменными. Выборочное значение ![]() парного коэффициента корреляции ρ подсчитывается по исходным статистическим данным по формуле:
парного коэффициента корреляции ρ подсчитывается по исходным статистическим данным по формуле:
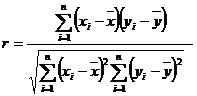 . (4.1)
. (4.1)
Коэффициент корреляции не имеет размерности и изменяется в диапазоне
-1![]() ρ
ρ![]() +1. Положительность коэффициента корреляции означает одинаковый характер тенденции взаимосвязанного изменения случайных величин Х и Y: с увеличением Х наблюдается тенденция увеличения соответствующих индивидуальных значений Y. Отрицательное значение говорит о противоположной тенденции взаимосвязанного изменения случайных величин Х и Y. Если ρ=0, можно сделать вывод, что линейная связь между Х и Y отсутствует. Однако это не означает, что Х и Y статистически независимы, так как не отрицается возможность существования нелинейной связи между Х и Y. Значение ρ= говорит о функциональном характере связи между Х и Y.
+1. Положительность коэффициента корреляции означает одинаковый характер тенденции взаимосвязанного изменения случайных величин Х и Y: с увеличением Х наблюдается тенденция увеличения соответствующих индивидуальных значений Y. Отрицательное значение говорит о противоположной тенденции взаимосвязанного изменения случайных величин Х и Y. Если ρ=0, можно сделать вывод, что линейная связь между Х и Y отсутствует. Однако это не означает, что Х и Y статистически независимы, так как не отрицается возможность существования нелинейной связи между Х и Y. Значение ρ= говорит о функциональном характере связи между Х и Y.
В рамках корреляционного анализа можно построить линии условных математических ожиданий (линий регрессии у по х и х по у)
у(х)=М(Y/X=x), x(y)=М(X/Y=y) ; (4.2)
а также линии условных дисперсий, которые характеризует, насколько точно линии регрессии передают изменение одной случайной величины при изменении другой,
![]() = М
= М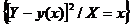 , (4.3)
, (4.3)
![]() = М.
= М.
Точные (или приближенные) прямолинейные регрессии
y(x) = ![]() ,
, ![]() x(y) =
x(y) = ![]() (4.4)
(4.4)
задаются следующими коэффициентами:
![]() ;
;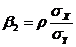 , (4.5)
, (4.5)
![]() ,
,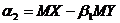 .
.
Если случайные величины Х и Y независимы, ρ=0 , то все условные математические ожидания и дисперсии не зависят от фиксированного значения другой случайной величины и совпадают с безусловными.
Стоит отметить, что выборочные коэффициенты корреляции могут быть формально вычислены для любой двумерной системы наблюдений.
Для проверки значимости парного коэффициента корреляции выдвигается гипотеза Н0: ρ=0. При проверки нулевой гипотезы используется статистика:
![]() , (4.6)
, (4.6)
имеющая распределение Стьдента с ν=n-2 числом степеней свободы.
Если ![]() <
<![]() , нулевая гипотеза не отвергается, следовательно, случайные величины Х и Y независимы. Если
, нулевая гипотеза не отвергается, следовательно, случайные величины Х и Y независимы. Если ![]() >
>![]() , коэффициент корреляции считается значимым.
, коэффициент корреляции считается значимым.
На практике для проверки нулевой гипотезы пользуются также распределением Фишера-Йетса. На уровне значимости α по таблице распределения Фишера-Йетса находят ![]() (α, ν=n-2). Если
(α, ν=n-2). Если ![]()
![]()
![]() , гипотеза отвергается, коэффициент корреляции считается значимым.
, гипотеза отвергается, коэффициент корреляции считается значимым. ![]() - взятое по модулю значение выборочного коэффициента корреляции.
- взятое по модулю значение выборочного коэффициента корреляции.
Для значимых параметров связи можно построить интервальную оценку.
При определении границ доверительного интервала коэффициента корреляции ρ используется преобразование Фишера: ![]() . (4.7)
. (4.7)
Предварительно устанавливают интервальную оценку для ![]() из условия:
из условия:
Р(![]() ) =
) =![]() =Ф(
=Ф(![]() ), (4.8)
), (4.8)
где ![]() находят по таблице интегральной функции Лапласа для данного уровня
находят по таблице интегральной функции Лапласа для данного уровня ![]() .
.
Получив доверительный интервал для ![]() ,
, ![]() , при помощи таблицы z - преобразования Фишера делают обратный переход от
, при помощи таблицы z - преобразования Фишера делают обратный переход от ![]() и
и ![]() к
к ![]() и
и ![]() . Таким образом окончательно получаем:
. Таким образом окончательно получаем:![]()
![]()
![]() .
.
При выборе ![]() и
и ![]() следует учитывать нечетность z- функции.
следует учитывать нечетность z- функции.
Трехмерная корреляционная модель является частным случаем множественной корреляционной модели. На примере анализа трехмерной корреляционной модели удобно показать все свойства множественной корреляции. Трехмерная нормально распределенная генеральная совокупность, образуемая тремя признаками X, Y, Z, определяется девятью параметрами: тремя математическими ожиданиями, тремя дисперсиями и тремя парными коэффициентами корреляции:
![]() ,
,![]() ,
,![]() - математические ожидания Х, Y и Z соответственно;
- математические ожидания Х, Y и Z соответственно;
![]() ,
,![]() ,
,![]() - дисперсии Х, Y и Z соответственно;
- дисперсии Х, Y и Z соответственно;
- парный коэффициент корреляции между Х и Y,
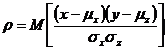 - парный коэффициент корреляции между Х и Z,
- парный коэффициент корреляции между Х и Z,
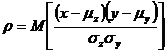 - парный коэффициент корреляции между Z и Y.
- парный коэффициент корреляции между Z и Y.
При изучении корреляционной зависимости между более чем двумя случайными величинами с заданным совместным многомерным распределением используют множественные и частные коэффициенты корреляции.
Частный коэффициент корреляции – это мера линейной зависимости между двумя случайными величинами из некоторой совокупности Х1, Х2,…,Хn, когда исключено влияние остальных случайных величин. Частный коэффициент корреляции обладает всеми свойствами парного коэффициента корреляции. В общем случае частный коэффициент корреляции выражается через элементы корреляционной матрицы R =![]() , составленной из коэффициентов парной корреляции.
, составленной из коэффициентов парной корреляции.
В рамках простой трехмерной корреляционной модели могут быть рассчитаны три частных коэффициента корреляции:
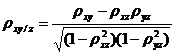 ;
; 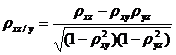 ;
; 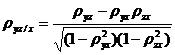 . (34.9)
. (34.9)
Для проверки значимости частного коэффициента корреляции выдвигается гипотеза Н0: ![]() =0. При проверки нулевой гипотезы используется статистика:
=0. При проверки нулевой гипотезы используется статистика:
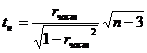 , ((34.10)
, ((34.10)
имеющая распределение Стьюдента с ν=n-3 числом степеней свободы.
Если ![]() <
<![]() , нулевая гипотеза не отвергается, следовательно, случайные величины Х и Y независимы. Если
, нулевая гипотеза не отвергается, следовательно, случайные величины Х и Y независимы. Если ![]() >
>![]() , коэффициент корреляции считается значимым.
, коэффициент корреляции считается значимым.
Как и в случае парной корреляции на практике для проверки нулевой гипотезы чаще пользуются распределением Фишера-Йейтса. На уровне значимости α по таблице распределения Фишера-Йейтса находят ![]() (α, ν=n-3). Если
(α, ν=n-3). Если ![]()
![]()
![]() , гипотеза отвергается, частный коэффициент корреляции считается значимым.
, гипотеза отвергается, частный коэффициент корреляции считается значимым. ![]() - взятое по модулю значение выборочного частного коэффициента корреляции.
- взятое по модулю значение выборочного частного коэффициента корреляции.
При определении границ доверительного интервала коэффициента корреляции ρ используется преобразование Фишера: 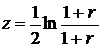 (34.11)
(34.11)
Предварительно устанавливают интервальную оценку для ![]() из условия:
из условия:
Р(![]() ) =
) =![]() =Ф(
=Ф(![]() ), (34.12)
), (34.12)
где ![]() находят по таблице интегральной функции Лапласа для данного уровня
находят по таблице интегральной функции Лапласа для данного уровня ![]() .
.
Получив доверительный интервал для ![]() ,
, ![]() , при помощи таблицы z - преобразования Фишера делают обратный переход от
, при помощи таблицы z - преобразования Фишера делают обратный переход от ![]() и
и![]() к
к ![]() и
и ![]() . Таким образом окончательно получаем:
. Таким образом окончательно получаем:![]()
![]()
![]() .
.
Множественный коэффициент корреляции R служит мерой линейной зависимости между случайной величиной Х1 и набором случайных величин Х2,…,Хn. В общем случае множественные коэффициенты корреляции выражаются через элементы корреляционной матрицы. Для трехмерной модели может быть рассчитано три множественных коэффициента корреляции:
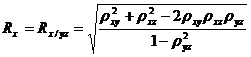 ;
;
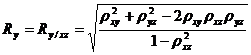 ; (34.13)
; (34.13)
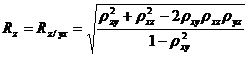 .
.
Множественный коэффициент корреляции изменяется в диапазоне 0![]() R
R![]() +1. Если, например,
+1. Если, например, ![]() = 1, то связь между случайной величиной Х и двумерной случайной величиной (Х, Z) является функциональной; если
= 1, то связь между случайной величиной Х и двумерной случайной величиной (Х, Z) является функциональной; если ![]() = 0, то случайная величина Х и двумерная случайная величина (Х, Z) независимы.
= 0, то случайная величина Х и двумерная случайная величина (Х, Z) независимы.
Множественный коэффициент детерминации показывает долю дисперсии случайной величины Х1, обусловленную влиянием остальных факторов Х2,…,Хn, входящих в многомерную модель. Множественный коэффициент детерминации может увеличиваться при введении в модель дополнительных признаков и не увеличиваться при исключении некоторых признаков из модели. Для двухмерной корреляционной модели коэффициент детерминации равен квадрату парного коэффициента корреляции.
При проверке значимости множественного коэффициента корреляции (множественного коэффициента детерминации) выдвигается гипотеза Н0: ![]() =0 (или
=0 (или![]() =0 ). При проверке нулевой гипотезы используется статистика:
=0 ). При проверке нулевой гипотезы используется статистика:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
