

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
21вопрос
Распределение Стьюдента
Распределение Стьюдента (t-распределение, предложено в 1908 г. английским статистиком В. Госсетом, публиковавшим научные труды под псевдонимом Student) характеризует распределение случайной величины 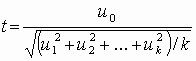 , где u0, u1, …, uk взаимно независимые нормально распределенные случайные величины с нулевым средним и конечной дисперсией. Аргумент t не зависит от дисперсии слагаемых. Функция плотности распределения Стьюдента
, где u0, u1, …, uk взаимно независимые нормально распределенные случайные величины с нулевым средним и конечной дисперсией. Аргумент t не зависит от дисперсии слагаемых. Функция плотности распределения Стьюдента
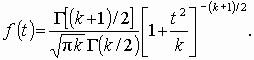
(3.5)
Величина k характеризует количество степеней свободы. Плотность распределения – унимодальная и симметричная функция, похожая на нормальное распределение, рис. 3.7.
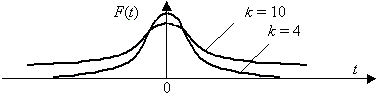
Область изменения аргумента t от – до . Математическое ожидание и дисперсия равны 0 и k/(k–2) соответственно, при k>2. По сравнению с нормальным распределение Стьюдента более пологое, оно имеет меньшую дисперсию. Это отличие заметно при небольших значениях k, что следует учитывать при проверке статистических гипотез (критические значения аргумента распределения Стьюдента превышают аналогичные показатели нормального распределения). Таблицы распределения содержат значения для односторонней 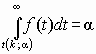 или двусторонней
или двусторонней 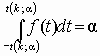 критической области.
критической области.
Распределение Стьюдента применяется для описания ошибок выборки при k 30. При k >100 данное распределение практически соответствует нормальному, для 30 < k < 100 различия между распределением Стьюдента и нормальным распределением составляют несколько процентов. Поэтому относительно оценки ошибок малыми считаются выборки объемом не более 30 единиц, большими – объемом более 100 единиц. При аппроксимации распределения Стьюдента нормальным распределением для односторонней критической области вероятность Р{t > t(k; )} = u1– (0, k/(k–2)), где u1– (0, k/(k–2)) – квантиль нормального распределения. Аналогичное соотношение можно составить и для двусторонней критической области.
22вопрос
Критерии, основанные на нормальном распределении
6.4.1. Сравнение выборочного среднего арифметического со средним значением генеральной совокупности
Рассмотрим, как с помощью статистических критериев решить вопрос: значимо ли отличие выборочного среднего значения от среднего значения генеральной совокупности, из которой предположительно взята выборка, или наблюдаемое различие является случайным? Такая постановка вопроса типична для выборочного контроля качества продукции в промышленности, но и при исследованиях в правоведении такой вопрос часто возникает, когда предстоит решить, значимо ли отличается среднее значение признака, полученное по выборке, от среднего значения, известного по результатам многочисленных предыдущих экспериментов.
Применяемый для этих целей t-критерий Стьюдента основан на предположении о нормальности распределения генеральной совокупности, но результаты проверки гипотез удовлетворяют по точности и при небольших отклонениях от нормальности распределения.
Условия применения t-критерия: выборка получена из генеральной совокупности, имеющей приближенно нормальное распределение с параметрами ![]() и
и ![]() .
.
Гипотеза Н0: ![]() =
= ![]() – среднее значение
– среднее значение ![]() генеральной совокупности, из которой получена выборка, равно данному значению
генеральной совокупности, из которой получена выборка, равно данному значению ![]() (известному, например, из предыдущих экспериментов).
(известному, например, из предыдущих экспериментов).
Альтернатива Н0: ![]()
![]()
![]() (двусторонний критерий применяется тогда, когда допускаются отклонения в обе стороны от
(двусторонний критерий применяется тогда, когда допускаются отклонения в обе стороны от ![]() ).
).
Уровень значимости:![]() .
.
Порядок применения T-критерия:
1. Принимается предположение о нормальности, формулируются гипотезы Н0 и H1 задается уровень значимости ![]() .
.
2. Получают выборку объема n.
3. Вычисляется выборочное среднее арифметическое ![]() и исправленная выборочная дисперсия S2.
и исправленная выборочная дисперсия S2.
4. Определяется значение t-критерия по формуле:
![]() (6.1)
(6.1)
Величина t имеет при справедливости гипотезы Н0 t-распределение Стьюдента (определенное в гл. 4) с =n–1 степенями свободы.
5. По таблицам находится tкритич – критическое значение t-критерия при уровне значимости ![]() и числе степеней свободы =n–1. (Таблицы обычно содержит критические значения tкритич для двустороннего критерия.)
и числе степеней свободы =n–1. (Таблицы обычно содержит критические значения tкритич для двустороннего критерия.)
6. Делается вывод: если ![]() , то выборочное среднее значимо отличается от
, то выборочное среднее значимо отличается от ![]() на уровне значимости , и в этой ситуации отклоняется гипотеза Н0, т. е. считается, что выборка взята из другой генеральной совокупности, для которой
на уровне значимости , и в этой ситуации отклоняется гипотеза Н0, т. е. считается, что выборка взята из другой генеральной совокупности, для которой ![]() . Если
. Если ![]() , то на заданном уровне различие незначимо и сохраняется гипотеза Н0.
, то на заданном уровне различие незначимо и сохраняется гипотеза Н0.
Замечание 2.
При больших объемах выборки (![]() ), как указано и гл. 4, t-распределение переходит в нормированное нормальное распределение, поэтому при проверке гипотезы вместо t-критерия можно использовать U-критерий, основанный на нормированном нормальном распределении статистики критерия.
), как указано и гл. 4, t-распределение переходит в нормированное нормальное распределение, поэтому при проверке гипотезы вместо t-критерия можно использовать U-критерий, основанный на нормированном нормальном распределении статистики критерия.
В этом случае вычисляют величину
![]() (6.2)
(6.2)
и сравнивают ее с критическими значениями uа нормированного нормального распределения. Для стандартных уровней значимости значения uа приведены в табл. 6.2.1
Замечание 1.
Если перед проведением эксперимента известно не только среднее значение ![]() генеральной совокупности, из которой получена выборка, но и его дисперсия
генеральной совокупности, из которой получена выборка, но и его дисперсия ![]() , то нет необходимости в вычислении S. Кроме того, при проверке гипотезы вместо t-критерия можно использовать Z-критерий, основанный на нормированном нормальном распределении статистики критерия.
, то нет необходимости в вычислении S. Кроме того, при проверке гипотезы вместо t-критерия можно использовать Z-критерий, основанный на нормированном нормальном распределении статистики критерия.
В этом случае вычисляют величину
![]() (6.3)
(6.3)
и сравнивают ее с критическими значениями z нормированного нормального распределения. Для стандартных уровней значимости значения z приведены в табл. 6.2
Таблица 6.2 Критические значения u-критерия
a и числе степеней свободы = n –1.
6. Делается вывод: если ![]() , то наблюдаемое различие значимо на уровне значимости , в противном случае различие статистически незначимо.
, то наблюдаемое различие значимо на уровне значимости , в противном случае различие статистически незначимо.
При больших выборках (для n>30) вместо t-критерия можно использовать u-критерий. В этом случае вычисленное по формуле (6.4) значение tнабл сравнивается с критическим значением uкритич нормированного нормального распределения (см. габл. 6.2).
6.4.3. Сравнение двух выборочных дисперсий из нормальных совокупностей
Условия применения F-критерия: обе выборки независимы и получены из нормально распределенных генеральных совокупностей с параметрами ![]() и
и ![]() .
.
Гипотеза H0:![]() =
= ![]() .
.
Альтернатива H1:![]()
![]()
![]() .
.
(Это двусторонняя гипотеза, поэтому следует применять двусторонний критерий. Если же предположить, что одна из генеральных совокупностей имеет| большую дисперсию (обозначим ее ![]() ), чем другая (
), чем другая (![]() ), то можно сформулировать одностороннюю гипотезу H1:
), то можно сформулировать одностороннюю гипотезу H1:![]() >
> ![]() |, и тогда применяется односторонний F-критерий.)
|, и тогда применяется односторонний F-критерий.)
Уровень значимости критерия задается ![]() .
.
Порядок применения F-критерия следующий:
1. Принимается предположение о нормальности распределения генеральных совокупностей, формулируется гипотеза и альтернатива, назначается уровень значимости ![]() , как указано выше.
, как указано выше.
2. Получают две независимые выборки из совокупностей X и Y объемом nх и nу соответственно.
3. Рассчитываются значения исправленных выборочных дисперсий ![]() и
и ![]() . Большую из дисперсий (
. Большую из дисперсий (![]() или
или ![]() ) обозначают
) обозначают ![]() , меньшую —
, меньшую — ![]()
4. Вычисляется значение F-критерия по формуле:
![]() (6.5)
(6.5)
5. Сравнивается вычисленное значение Fнабл с критическим значением Fкритич при заданном уровне значимости ![]() и числе степеней свободы 1 = n1–1 и 2 =n2–1.
и числе степеней свободы 1 = n1–1 и 2 =n2–1.
(Критические значения F при уровнях значимости ![]() , равных 0,05, 0,01, 0,001 приведены в таблицах).
, равных 0,05, 0,01, 0,001 приведены в таблицах).
Отметим, что в обычно в таблице приведены критические значения одностороннего F-критерия. Поэтому если цель исследования доказать, что одна дисперсия больше другой (H1:![]() ), то критические значения берутся непосредственно из этой таблицы. Если же применяется двусторонний критерий (H1:
), то критические значения берутся непосредственно из этой таблицы. Если же применяется двусторонний критерий (H1: ![]() ), то критические значения, взятые из таблиц, соответствуют удвоенным уровням значимости: 0,01, 0,02 и 0,002.
), то критические значения, взятые из таблиц, соответствуют удвоенным уровням значимости: 0,01, 0,02 и 0,002.
6. Делается вывод: если вычисленное значение Fнабл - больше или равно критическому Fкритич, то дисперсии различаются значимо на заданном уровне значимости. К противном случае нет оснований для отклонения нулевой гипотезы о равенстве двух дисперсий.
Следует отметить, что F-критерий очень чувствителен к отклонениям от нормальности распределения генеральной совокупности. Если предположение о нормальном распределении не может быть принято, то F-критерий применять не следует. В этом случае используются непараметрические методы.
F-критерий используется для малых и средних объемов выборки (n < 100). Для больших объемов выборки (n > 100) при проверке гипотезы о равенстве дисперсий удобнее применять U-критерий. В этом случае вычисляется величина
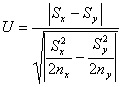
и сравнивается с критическими значениями U, взятыми из таблиц нормированного нормального распределения. Для стандартных уровней значимости значения u приведены в табл. 6.2.
6.4.4. Сравнение двух выборочных средних значений для независимых выборок
В этом разделе рассматривается очень важный для практики критерий математической статистики, позволяющий получить ответ на вопрос: значимо ли различаются средние значения, полученные по двум независимым выборкам (например, по результатам в контрольной и экспериментальной группах)? Здесь также применяется t-критерий Стьюдента, основанный на предположении, что выборки получены из генеральных совокупностей, имеющих приближенно нормальное распределение. Кроме того, применение t-критерия отличается при различных предположениях относительно дисперсий этих генеральных совокупностей. В математической статистике обычно рассматриваются случаи известных и неизвестных генеральных дисперсий, но, поскольку на практике генеральные дисперсии, как правило, неизвестны, здесь описывается только случай неизвестных дисперсий. При этом возможны следующие варианты предположений:
1) обе дисперсии неизвестны, но предполагается, что они равны между собой;
2) обе дисперсии неизвестны, и предположение о их равенстве не делается.
Как выбрать подходящий вариант? Конечно, если нет уверенности в равенстве дисперсий, нужно использовать второй вариант, потому что в этом случае требуется меньше знаний о распределении генеральных совокупностей, но всегда платой за это является меньшая точность выводов.
Поэтому обычно поступают следующим образом: вначале по имеющимся выборочным данным проверяют гипотезу о равенстве дисперсий, используя F-критерий, а затем уже выбирают тот или иной вариант t-критерия. Строго говоря, это некорректно с точки зрения математической статистики, поскольку, как уже неоднократно подчеркивалось, критерий должен выбираться до получения экспериментальных данных, и правильнее было бы выбрать предположение о равенстве или неравенстве дисперсий по другим, предварительно полученным экспериментальным данным.
При описанном выше подходе t-критерий применяется следующим образом.
Условия применения: обе выборки независимы и получены из генеральных совокупностей X и Y, имеющих нормальное распределение с параметрами ![]() и
и ![]() .
.
Гипотеза Н0: ![]() .
.
Альтернатива Н1: ![]() или Н1:
или Н1: ![]() (
(![]() ) в зависимости от того, что требуется доказать: простое различие средних значений или то, что одно из них больше другого.
) в зависимости от того, что требуется доказать: простое различие средних значений или то, что одно из них больше другого.
Уровень значимости: ![]() .
.
Порядок применения:
1. Принимается предположение о нормальности, формулируются гипотеза Но и альтернатива Н1, задается уровень значимости ![]() .
.
2. Получают две независимые выборки из совокупностей X и У объемом nх и nу.
3. Вычисляются выборочные характеристики х, Sx и у, Sy методами, рассмотренными в гл. 3.
4. Используется F-критерий для проверки гипотезы о равенстве генеральных дисперсий, как показано в разделе 6.3.1.
5. По результатам применения F-критерия принимается или не принимается предположение о равенстве дисперсий.
6. Вычисляются значение t-критерия и число степеней свободы . Применяемые для этого формулы приведены в табл. 6.3, они различаются в зависимости от предположения о дисперсиях и соотношения между объемами выборок nх и nу.
7. Из таблицы t-распределения Стьюдента находится ![]() – критическое значение t-критерия при заданном уровне значимости а и числе степеней свободы .
– критическое значение t-критерия при заданном уровне значимости а и числе степеней свободы .
8. Делается вывод: если ![]() , то выборочные средние значимо различаются на уровне значимости (вероятность ошибки меньше ). В противном случае различие статистически незначимо.
, то выборочные средние значимо различаются на уровне значимости (вероятность ошибки меньше ). В противном случае различие статистически незначимо.
![]() представляет уравнение регрессии
представляет уравнение регрессии ![]() на
на ![]() , а
, а ![]() - уравнение регрессии
- уравнение регрессии ![]() на
на ![]() .9
.9
ТОЧЕЧНЫЕ И ИНТЕРВАЛЬНЫЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
Важной задачей математической статистики является задача оценивания (приближенного определения) по выборочным данным параметров закона распределения признака X генеральной совокупности. Другими словами, необходимо по данным выборочного распределения оценить неизвестные параметры теоретического распределения. Статистические оценки могут быть точечными и интервальными.
Задачу статистического оценивания, а также основные виды статистических оценок, рассмотрим для частного случая: пусть признак X генеральной совокупности распределен нормально, то есть теоретическое распределение имеет вид:
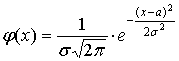
с параметрами: 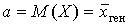 – математическое ожидание признака X ;
– математическое ожидание признака X ; ![]() – среднеквадратическое отклонение признака X.
– среднеквадратическое отклонение признака X.
Точечной оценкой неизвестного параметра называют число (точку на числовой оси), которое приблизительно равно оцениваемому параметру и может заменить его с достаточной степенью точности в статистических расчетах.
Точечной оценкой генеральной средней ![]() и параметра a может служить выборочная средняя
и параметра a может служить выборочная средняя ![]() .
.
Точечными оценками генеральной дисперсии ![]() могут служить выборочная дисперсия
могут служить выборочная дисперсия ![]() , или, при малых объемах выборки n, исправленная выборочная дисперсия:
, или, при малых объемах выборки n, исправленная выборочная дисперсия:
![]() .
.
Точечными оценками для генерального среднеквадратического отклонения ![]() могут служить:
могут служить: ![]() – выборочное среднее квадратическое отклонение или
– выборочное среднее квадратическое отклонение или ![]() – исправленное выборочное среднее квадратическое отклонение.
– исправленное выборочное среднее квадратическое отклонение.
Формулы, необходимые для вычисления выборочной средней ![]() и выборочной дисперсии
и выборочной дисперсии ![]() , приведены в п. 2.
, приведены в п. 2.
Для того чтобы точечные статистические оценки обеспечивали “хорошие” приближения неизвестных параметров, они должны быть несмещенными, состоятельными и эффективными.
Пусть ![]() – точечная оценка неизвестного параметра q.
– точечная оценка неизвестного параметра q.
Несмещенной называют такую точечную статистическую оценку ![]() , математическое ожидание которой равно оцениваемому параметру:
, математическое ожидание которой равно оцениваемому параметру: 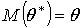 .
.
Состоятельной называют такую точечную статистическую оценку, которая при 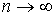 стремится по вероятности к оцениваемому параметру. В частности, если дисперсия несмещенной оценки при
стремится по вероятности к оцениваемому параметру. В частности, если дисперсия несмещенной оценки при ![]() стремится к нулю, то такая оценка оказывается и состоятельной.
стремится к нулю, то такая оценка оказывается и состоятельной.
Эффективной называют такую точечную статистическую оценку, которая при фиксированном n имеет наименьшую дисперсию.
Можно показать, что выборочная средняя ![]() является несмещенной, состоятельной и эффективной оценкой генеральной средней
является несмещенной, состоятельной и эффективной оценкой генеральной средней ![]() .
.
Для построения интервальной оценки рассмотрим событие, заключающееся в том, что отклонение точечной оценки параметра ![]() от истинного значения этого параметра q по абсолютной величине не превышает некоторую положительную величину D. Вероятность такого события
от истинного значения этого параметра q по абсолютной величине не превышает некоторую положительную величину D. Вероятность такого события 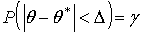 . Заменив неравенство
. Заменив неравенство ![]() на равносильное, получим:
на равносильное, получим:
![]() .
.
Вероятность того, что доверительный интервал ![]() заключает в себе (покрывает) неизвестный параметр q равна g и называется доверительной вероятностью или надежностью интервальной оценки. Величину D называют точностью оценки.
заключает в себе (покрывает) неизвестный параметр q равна g и называется доверительной вероятностью или надежностью интервальной оценки. Величину D называют точностью оценки.
Построим интервальную оценку параметра ![]() для двух случаев:
для двух случаев:
1) параметр s нормального закона распределения признака Х генеральной совокупности известен. В этом случае интервальная оценка параметра ![]() с заданной надежностью g определяется формулой:
с заданной надежностью g определяется формулой:
![]() ,
,
где D = ![]() , t – аргумент функции Лапласа: Ф(t) =
, t – аргумент функции Лапласа: Ф(t) = ![]() .
.
2) параметр s нормального закона распределения признака Х генеральной совокупности неизвестен. В этом случае интервальная оценка параметра ![]() с заданной надежностью g определяется формулой:
с заданной надежностью g определяется формулой:
![]() ,
,
где D = ![]() , S – точечная оценка параметра s,
, S – точечная оценка параметра s, ![]() – значения распределения Стьюдента, которые находим по таблице.
– значения распределения Стьюдента, которые находим по таблице.
Пример. С целью определения среднего трудового стажа на предприятии методом случайной повторной выборки проведено обследование трудового стажа рабочих. Из всего коллектива рабочих завода случайным образом выбрано 400 рабочих, данные о трудовом стаже которых и составили выборку. Средний по выборке стаж оказался равным 9,4 года. Считая, что трудовой стаж рабочих имеет нормальный закон распределения, определить с вероятностью 0,97 границы, в которых окажется средний трудовой стаж для всего коллектива, если известно, что s = 1,7 года.
Решение. Признак Х – трудовой стаж рабочих. Этот признак имеет нормальный закон распределения с известным параметром s = 1,7, параметр а неизвестен. Сделана выборка объемом n = 400, по данным выборки найдена точечная оценка параметра а: ![]() в = 9,4. С надежностью g = 0,97 найдем интервальную оценку параметра
в = 9,4. С надежностью g = 0,97 найдем интервальную оценку параметра 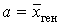 по формуле:
по формуле:
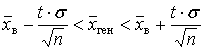 .
.
По таблице значений функции Лапласа из уравнения Ф(t) »![]() = 0,485 находим t = 2,17; тогда:
= 0,485 находим t = 2,17; тогда: 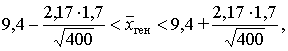
9,4 – 0,18 < ![]() ген < 9,4 + 0,18. Итак, 9,22 <
ген < 9,4 + 0,18. Итак, 9,22 < ![]() ген < 9,58, то есть средний трудовой стаж рабочих всего коллектива лежит в пределах от 9,22 года до 9,58 года (с надежностью g = 0,97).
ген < 9,58, то есть средний трудовой стаж рабочих всего коллектива лежит в пределах от 9,22 года до 9,58 года (с надежностью g = 0,97).
С изменением надежности g изменится и интервальная оценка.
Пусть g = 0,99, тогда Ф(t) = 0,495, отсюда t = 2,58. Тогда:
![]() или 9,4 – 0,22 <
или 9,4 – 0,22 < ![]() ген < 9,4 + 0,22 .
ген < 9,4 + 0,22 .
Окончательно: 9,18 < ![]() ген < 9,62.
ген < 9,62.
Пример. С целью определения средней продолжительности рабочего дня на предприятии методом случайной повторной выборки проведено обследование продолжительности рабочего дня сотрудников. Из всего коллектива завода случайным образом выбрано 30 сотрудников. Данные табельного учета о продолжительности рабочего дня этих сотрудников и составили выборку. Средняя по выборке продолжительность рабочего дня оказалась равной 6,85 часа, а S = 0,7 часа. Считая, что продолжительность рабочего дня имеет нормальный закон распределения, с надежностью g = 0,95 определить, в каких пределах находится действительная средняя продолжительность рабочего дня для всего коллектива данного предприятия.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
