

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1 билет
Задачи и основные понятие математической статистики!!!
Задачи математической статистики.
Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении методами теории вероятностей статистических данных — результатов наблюдений.![]() Первая задача математической статистики—указать способы сбора и группировки статистических сведений, полученных в результате наблюдений или в результате специально поставленных экспериментов.
Первая задача математической статистики—указать способы сбора и группировки статистических сведений, полученных в результате наблюдений или в результате специально поставленных экспериментов.![]() Вторая задача математической статистики—разработать методы анализа статистических данных в зависимости от целей исследования. Сюда относятся:а) оценка неизвестной вероятности события; оценка неизвестной функции распределения; оценка параметров распределения, вид которого известен; оценка зависимости случайной величины от одной или нескольких случайных величин и др.;б) проверка статистических гипотез о виде неизвестного распределения или о величине параметров распределения, вид которого известен.Современная математическая статистика разрабатывает способы определения числа необходимых испытаний до начала исследования (планирование эксперимента), в ходе исследования (последовательный анализ) и решает многие другие задачи. Современную математическую статистику определяют как науку о принятии решений в условиях неопределенности. Итак, задача математической статистики состоит в создании методов сбора и обработки статистических данных для получения научных и практических выводо
Вторая задача математической статистики—разработать методы анализа статистических данных в зависимости от целей исследования. Сюда относятся:а) оценка неизвестной вероятности события; оценка неизвестной функции распределения; оценка параметров распределения, вид которого известен; оценка зависимости случайной величины от одной или нескольких случайных величин и др.;б) проверка статистических гипотез о виде неизвестного распределения или о величине параметров распределения, вид которого известен.Современная математическая статистика разрабатывает способы определения числа необходимых испытаний до начала исследования (планирование эксперимента), в ходе исследования (последовательный анализ) и решает многие другие задачи. Современную математическую статистику определяют как науку о принятии решений в условиях неопределенности. Итак, задача математической статистики состоит в создании методов сбора и обработки статистических данных для получения научных и практических выводо
2. Основные понятия математической статистикиПространством элементарных событий называется множество исходов некоторого эксперимента. Элементарным событием называется любой элемент пространства элементарных событий. Событием называется любое подмножество пространства элементарных событий. Генеральной совокупностью называется достаточно большое, быть может, бесконечное подмножество элементарных событий. Случайной величиной называют функцию от элементарного события. Экспериментом называется функция, принимающая значение на пространстве элементарных событий. Статистическая моделью называется совокупность законов, которым подчиняется процедура эксперимента. Случайной выборкой1 или просто выборкой1 объема n называется набор некоторого числа элементов генеральной совокупности, наблюденных при серии из n одинаковых экспериментовВыборкой2 объема n называется набор 1,…,n случайных величин, определенных на натуральных числах 1,…,n, k-я с. в. принимает значение исхода ki-го эксперимента на числе i, при условии, что все эксперименты одинаковы. Статистикой называется любая измеримая функция от выборки. Функцией правдоподобия называется плотность распределения выборки2, как n-мерной случайной величины. Вариационный ряд, распределение порядковых статистик. Эмпирические Квантили ГММЕ 398.к-й порядковой статистикой выборки х1,…,хn называется такая случайная величина х(k), что для каждого набора значений выборки х1,…,хn х(k) равна такому хi, для которого найдется ровно i-1 элементов выборки, которые меньше хi.Если х1,…,хn - независимые, одинаково распределенные случайные величины, что распределение к-й порядковой статистики задается следующей формулой:где B(a, b) - плотность бета распределения. Вариационным рядом называется последовательность порядковых статистик x(1),…,x(n). Выборочным квантилем порядка р называется значение х([np]+1). Квантилью p для с. в. х с функцией распределения F(x)называется любой корень уравнения F(p)=p.
2 билет
Генеральная и выборочная совокупность) повторная и безповторная выборки) репрезентивная выборка и способы отбора!
2.2. Способы выборки.
При составлении выборки можно поступать двумя способами: после того как объект отобран и над ним произведено наблюдение, он может быть возвращен либо не возвращен в генеральную совокупность. В соответствии со сказанным выборки подразделяют на повторные и бесповторные.![]() Повторной называют выборку, при которой отобранный объект (перед отбором следующего) возвращается в генеральную совокупность.
Повторной называют выборку, при которой отобранный объект (перед отбором следующего) возвращается в генеральную совокупность.![]() Бесповторной называют выборку, при которой отобранный объект в генеральную совокупность не возвращается.На практике обычно пользуются бесповторным случайным отбором. Для того чтобы по данным выборки можно было достаточно уверенно судить об интересующем признаке генеральной совокупности, необходимо, чтобы объекты выборки правильно его представляли. Другими словами, выборка должна правильно представлять пропорции генеральной совокупности. Это требование коротко формулируют так: выборка должна быть репрезентативной (представительной) . В силу закона больших чисел можно утверждать, что выборка будет репрезентативной, если ее осуществить случайно: каждый объект выборки отобран случайно из генеральной совокупности, если все объекты имеют одинаковую вероятность попасть в выборку.На практике применяются различные способы отбора. Принципиально эти способы можно подразделить на два вида:1. Отбор, не требующий расчленения генеральной совокупности на части. Сюда относятся: а) простой случайный бесповторный отбор; б) простой случайный повторный отбор.2. Отбор, при котором генеральная совокупность разбивается на части. Сюда относятся: а) типический отбор;б) механический отбор; в) серийный отбор. Простым случайным называют такой отбор, при котором объекты извлекают по одному из всей генеральной совокупности и после обследования не возвращают (бесповторный отбор) или возвращают ( повторный отбор) в генеральную совокупность. Типическим называют отбор, при котором объекты отбираются не из всей генеральной совокупности, а из каждой ее «типической» части. Например, если детали изготовляют на нескольких станках, то отбор производят не из всей совокупности деталей, произведенных всеми станками, а из продукции каждого станка в отдельности. Типическим отбором пользуются тогда, когда обследуемый признак заметно колеблется в различных типических частях генеральной совокупности. Например, если продукция изготовляется на нескольких машинах, среди которых есть более и менее изношенные, то здесь типический отбор целесообразен. Механическим называют отбор, при котором генеральную совокупность «механически» делят на столько групп, сколько объектов должно войти в выборку, а из каждой группы отбирают один объект. Например, если нужно отобрать 20% изготовленных станком деталей, то отбирают каждую пятую деталь; если требуется отобрать 5% деталей, то отбирают каждую двадцатую деталь, и т. д. Следует указать, что иногда механический отбор может не обеспечить репрезентативности выборки. Серийным называют отбор, при котором объекты отбирают из генеральной совокупности не по одному, а «сериями», которые подвергаются сплошному обследованию. Например, если изделия изготовляются большой группой станков-автоматов, то подвергают сплошному обследованию продукцию только нескольких станков. Серийным отбором пользуются тогда, когда обследуемый признак колеблется в различных сериях незначительно. Подчеркнем, что на практике часто применяется комбинированный отбор, при котором сочетаются указанные выше способы. Репрезентативная выборка – это такая выборка, в которой все основные признаки генеральной совокупности, из которой извлечена данная выборка, представлены приблизительно в той же пропорции или с той же частотой, с которой данный признак выступает в этой генеральной совокупности. Таким образом, если 50% всех законодательных органов штатов собираются лишь раз в два года, приблизительно половина состава репрезентативной выборки законодательных органов штатов должна быть такого типа. Если 30% избирателей Пенсильвании принадлежат к “синим воротничкам”, около 30% репрезентативной выборки для этих избирателей (а не 100%, как в приведенном выше примере) должны быть из числа “синих воротничков”. И если 2% всех студентов колледжей являются спортсменами, приблизительно та же самая часть репрезентативной выборки студентов колледжей должна приходиться на спортсменов. Иными словами, репрезентативная выборка представляет собой микрокосм, меньшую по размеру, но точную модель генеральной совокупности, которую она должна отражать. В той степени, в какой выборка является репрезентативной, выводы, основанные на изучении этой выборки, можно без всяких опасений считать применимыми к исходной совокупности. Это распространение результатов и есть то, что мы называем генерализуемостью.
Бесповторной называют выборку, при которой отобранный объект в генеральную совокупность не возвращается.На практике обычно пользуются бесповторным случайным отбором. Для того чтобы по данным выборки можно было достаточно уверенно судить об интересующем признаке генеральной совокупности, необходимо, чтобы объекты выборки правильно его представляли. Другими словами, выборка должна правильно представлять пропорции генеральной совокупности. Это требование коротко формулируют так: выборка должна быть репрезентативной (представительной) . В силу закона больших чисел можно утверждать, что выборка будет репрезентативной, если ее осуществить случайно: каждый объект выборки отобран случайно из генеральной совокупности, если все объекты имеют одинаковую вероятность попасть в выборку.На практике применяются различные способы отбора. Принципиально эти способы можно подразделить на два вида:1. Отбор, не требующий расчленения генеральной совокупности на части. Сюда относятся: а) простой случайный бесповторный отбор; б) простой случайный повторный отбор.2. Отбор, при котором генеральная совокупность разбивается на части. Сюда относятся: а) типический отбор;б) механический отбор; в) серийный отбор. Простым случайным называют такой отбор, при котором объекты извлекают по одному из всей генеральной совокупности и после обследования не возвращают (бесповторный отбор) или возвращают ( повторный отбор) в генеральную совокупность. Типическим называют отбор, при котором объекты отбираются не из всей генеральной совокупности, а из каждой ее «типической» части. Например, если детали изготовляют на нескольких станках, то отбор производят не из всей совокупности деталей, произведенных всеми станками, а из продукции каждого станка в отдельности. Типическим отбором пользуются тогда, когда обследуемый признак заметно колеблется в различных типических частях генеральной совокупности. Например, если продукция изготовляется на нескольких машинах, среди которых есть более и менее изношенные, то здесь типический отбор целесообразен. Механическим называют отбор, при котором генеральную совокупность «механически» делят на столько групп, сколько объектов должно войти в выборку, а из каждой группы отбирают один объект. Например, если нужно отобрать 20% изготовленных станком деталей, то отбирают каждую пятую деталь; если требуется отобрать 5% деталей, то отбирают каждую двадцатую деталь, и т. д. Следует указать, что иногда механический отбор может не обеспечить репрезентативности выборки. Серийным называют отбор, при котором объекты отбирают из генеральной совокупности не по одному, а «сериями», которые подвергаются сплошному обследованию. Например, если изделия изготовляются большой группой станков-автоматов, то подвергают сплошному обследованию продукцию только нескольких станков. Серийным отбором пользуются тогда, когда обследуемый признак колеблется в различных сериях незначительно. Подчеркнем, что на практике часто применяется комбинированный отбор, при котором сочетаются указанные выше способы. Репрезентативная выборка – это такая выборка, в которой все основные признаки генеральной совокупности, из которой извлечена данная выборка, представлены приблизительно в той же пропорции или с той же частотой, с которой данный признак выступает в этой генеральной совокупности. Таким образом, если 50% всех законодательных органов штатов собираются лишь раз в два года, приблизительно половина состава репрезентативной выборки законодательных органов штатов должна быть такого типа. Если 30% избирателей Пенсильвании принадлежат к “синим воротничкам”, около 30% репрезентативной выборки для этих избирателей (а не 100%, как в приведенном выше примере) должны быть из числа “синих воротничков”. И если 2% всех студентов колледжей являются спортсменами, приблизительно та же самая часть репрезентативной выборки студентов колледжей должна приходиться на спортсменов. Иными словами, репрезентативная выборка представляет собой микрокосм, меньшую по размеру, но точную модель генеральной совокупности, которую она должна отражать. В той степени, в какой выборка является репрезентативной, выводы, основанные на изучении этой выборки, можно без всяких опасений считать применимыми к исходной совокупности. Это распространение результатов и есть то, что мы называем генерализуемостью.
3 билет
Шкала измерения. Квантили
Измерение – операция для определения отношения одного объекта к другому. Измерение реализуется за счет приписывания объектам значений так, чтобы отношения между значениями отражали отношения между объектами. К примеру, мы измеряем рост двух людей (объект измерения - рост). Получив значения 170 и 185 см. мы можем точно сказать, что один человек выше другого. Данный вывод был получен благодаря измерению роста. Таким образом, отношение между объектами было передано с помощью чисел. Шкала измерения – ограничение типа отношений между значениями переменных, накладываемое на результаты измерений. Чаще всего, шкала измерения зависит от инструмента измерения. К примеру, если переменной является цвет глаз, то мы не можем сказать, что один человек больше или меньше другого по этой переменной, мы так же не можем найти среднее арифметическое цвета. Если переменной является порядок (именно порядок) рождения детей в семье, то мы можем сказать, что первый ребенок однозначно старше второго, но не можем сказать на сколько он старше (отношения «больше/меньше»). Имея результаты теста интеллекта, мы можем однозначно сказать на сколько один человек интеллектуальнее другого. С.Стивенс рассматривал четыре шкалы измерения.1. Шкала наименований - простейшая из шкал измерения. Числа (равно как буквы, слова или любые символы) используются для различения объектов. Отображает те отношения, посредством которых объекты группируются в отдельные непересекающиеся классы. Номер (буква, название) класса не отражает его количественного содержания. Примером шкалы такого рода может служить классификация испытуемых на мужчин и женщин, нумерация игроков спортивных команд, номера телефонов, паспортов, штрих-коды товаров. Все эти переменные не отражают отношений больше/меньше, а значит являются шкалой наименований. Особым подвидом шкалы наименований является дихотомическая шкала, которая кодируется двумя взаимоисключающими значениями (1/0). Пол человека является типичной дихотомической переменной. В шкале наименований нельзя сказать, что один объект больше или меньше другого, на сколько единиц они различаются и во сколько раз. Возможна лишь операция классификации — отличается/не отличается. В психологии иногда невозможно избежать шкалы наименований, особенно при анализе рисунков. К примеру, рисуя дом, дети часто рисуют солнце в верхней части листа. Можно предположить, что расположение солнца слева, посередине, справа или отсутствие солнца вообще может говорить о некоторых психологических качествах ребенка. Перечисленные варианты расположения солнца являются значениями переменной шкалы наименований. Причем, мы можем обозначить варианты расположения номерами, буквами или оставить их в виде слов, но как бы мы их не называли, мы не можем сказать, что один ребенок «больше» другого, если нарисовал солнце не посередине, а слева. Но мы можем точно сказать, что ребенок, нарисовавший солнце справа однозначно не является тем, кто нарисовал солнце слева (или не входит в группу).Таким образом, шкала наименований отражает отношения типа: похож/не похож, тот/не тот, относится к группе/не относится к группе.2. Порядковая (ранговая) шкала - отображение отношений порядка. Единственно возможные отношения между объектами измерения в данной шкале – это больше/меньше, лучше/хуже. Самой типичной переменной этой шкалы является место, занятое спортсменом на соревнованиях. Известно, что победители соревнований получают первое, второе и третье место и мы точно знаем, что спортсмен с первым местом имеет лучшие результаты, чем спортсмен со вторым местом. Кроме места, имеем возможность узнать и конкретные результаты спортсмена. В психологии возникают менее определенные ситуации. К примеру, когда человека просят проранжировать цвета по предпочтению, от самого приятного, до самого неприятного. В этом случае, мы точно можем сказать, что один цвет приятнее другого, но о единицах измерения мы не можем даже предположить, т. к. человек ранжировал цвета не на основе каких-либо единиц измерения, а основываясь на собственных чувствах. То же самое происходит в тесте Рокича, по результатам которого мы так же не знаем на сколько единиц одна ценность выше (больше) другой. Т. е., в отличие от соревнований, мы даже не имеем возможности узнать точные баллы различий. Проведя измерение в порядковой шкале нельзя узнать на сколько единиц отличаются объекты, тем более во сколько раз они отличаются.3. Интервальная шкала - помимо отношений указанных для шкал наименования и порядка, отображает отношение расстояния (разности) между объектами. Разности между соседними точками в этой шкале равны. Большинство психологических тестов содержат нормы, которые и являются образцом интервальной шкалы. Коэфициент интеллекта, результаты теста FPI, шкала градусов цельсия – всё это интервальные шкалы. Ноль в них условный: для IQ и FPI ноль – это минимально возможный балл теста (очевидно, что даже проставленные наугад ответы в тесте интеллекта, позволят получить какой-либо балл отличный от нуля). Если бы мы не создавали условный ноль в шкале, а использовали реальный ноль как начало отсчета, то получили бы шкалу отношений, но мы знаем, что интеллект не может быть нулевымНе психологический пример шкалы интервалов — шкала градусов Цельсия. Ноль здесь условный — температура замерзания воды и существует единица измерения — градус Цельсия. Хотя мы знаем, что существует абсолютный температурный ноль - это минимальный предел температуры, которую может иметь физическое тело, который в шкале Цельсия равен -273,15 градуса. Таким образом, условный ноль и наличие равных интервалов между единицами измерения являются главными признаками шкалы интервалов. Измерив явление в интервальной шкале, мы можем сказать, что один объект на определенное количество единиц больше или меньше другого.4. Шкала отношений. В отличие от шкалы интервалов может отражать то, во сколько один показатель больше другого. Шкала отношений имеет нулевую точку, которая характеризует полное отсутствие измеряемого качества. Данная шкала допускает преобразование подобия (умножение на константу). Определение нулевой точки - сложная задача для психологических исследований, накладывающая ограничение на использование данной шкалы. С помощью таких шкал могут быть измерены масса, длина, сила, стоимость (цена), т. е. всё, что имеет гипотетический абсолютный ноль. Квартили и децили – дополнительные характеристики вариационного ряда
Дополнительно к медиане для характеристики вариационного ряда исчисляют квартили, которые делят ряд по сумме частот на четыре равные части, и децили, которые делят ряд на десять равных частей. Второй квартиль равен медиане, а первый – Q1 и третий – Q3 исчисляют аналогично расчету медианы, только вместо медианного интервала берется для первого квартиля интервал, в котором находится варианта, отсекающая ј численности частот, а для третьего квартиля – варианта, отсекающая ѕ численности частот. Исчислим для нашего примера первый и третий квартили:
Q1 = XQ1 +iQ1 * (∑f/4 – SQ1-1)/fQ1,
Q1 = 300 + 50 * (125–60)/100 = 332,5
Для расчета первого квартиля находим ј всех частот: ∑f/4 составит /4). Из таблицы 3 видно, что 125-я варианта находится в интервале 300 – 350.
Следовательно, XQ1 = 300. Сумма накопленных частот до этого интервала равна 60 (SQ1-1), частота этого интервала – 100. Расчет дает значение первого квартиля 332,5 тыс. руб. Это означает, что у трех четвертей всех рабочих заработная плата составляет 332,5 тыс. руб. и выше.
Рассчитаем третий квартиль. Три четверти численности частот (3/4 ∑f) составит 375 = 500*3/я варианта находится в интервале 400 – 450. Следовательно:
Q3 = XQ3 + iQ3 * (3/4∑f – SQ3-1)/fQ3,
Q3 = 400 + 50 *(375 – 275)/180 = 427,75
Третий квартиль составляет 427,75 тыс. руб. Следовательно, заработная плата каждого четвертого работника превышает 427,75 тыс. руб.
4 билет
Вариационный и статический вариант полигон частот и гистограмма!
Способы группировки статистических данных. Вариационные ряды.
3.1. Дискретный вариационный ряд.Обычно полученные наблюдаемые данные представляют собой множество расположенных в беспорядке чисел. Просматривая это множество чисел, трудно выявить какую-либо закономерность их варьирования (изменения). Для изучения закономерностей варьирования значений случайной величины опытные данные подвергают обработке. Рассмотрим пример. На телефонной станции проводились наблюдения над числом Х неправильных соединений в минуту. Наблюдения в течение часа дали следующие результаты: 3; 1; 3; 1; 4; 2; 2; 4; 0; 3; 0; 2; 2; 0; 2; 1;4; 3; 3; 1; 4; 2; 2; 1; 1; 2; 1; 0; 3; 4; 1; 3; 2; 7; 2; 0; 0; 1; 3; 3; 1; 2; 4;2; 0; 2; 3; 1; 2; 5; 1; 1; 0; 1; 1; 2; 2; 1; 1; 5. Здесь число X является дискретной случайной величиной, а полученные о ней сведения представляют собой статистические (наблюдаемые) данные. Операция, заключающаяся в том, что результаты наблюдений над случайной величиной, т. е. наблюдаемые значения случайной величины, располагают в порядке неубывания, называется ранжированием опытных данных.После проведения операции ранжирования опытные данные группируют так, что в каждой отдельной группе значения случайной величины будут одинаковы. Расположив приведенные выше данные в порядке неубывания и сгруппировав их, получают ранжированный ряд данных наблюденияИз ряда чисел видно, что все 60 значений случайной величины разбиты на семь групп, в пределах каждой из которых все значения случайной величины одинаковы. Таким образом, имеется семь различных значений случайной величины: 0; 1; 2; 3; 4; 5; 7. Каждое такое значение обычно называют вариантом. Значение случайной величины, соответствующее отдельной группе сгруппированного ряда наблюдаемых данных, называется вариантом, а изменение этого значения варьированием.Варианты будем обозначать малыми буквами конца латинского алфавита с соответствующими порядковому номеру группы индексами. Для каждой группы сгруппированного ряда данных можно подсчитать их численность, т. е. определить число, которое показывает, сколько раз встречается соответствующий вариант в ряде наблюдений. Такие числа называют частотой варианта.![]() Численность отдельной группы сгруппированного ряда наблюдаемых данных называется частотой или весом соответствующего варианта и обозначается тi , где i—индекс варианта. В ряде случаев представляет практический интерес относительная частота того или иного варианта, называемая частостью.
Численность отдельной группы сгруппированного ряда наблюдаемых данных называется частотой или весом соответствующего варианта и обозначается тi , где i—индекс варианта. В ряде случаев представляет практический интерес относительная частота того или иного варианта, называемая частостью.![]() Отношение частоты данного варианта к общей сумме частот всех вариантов называется частостью или долей этого варианта и обозначается рi , где i—индекс варианта, т. е.
Отношение частоты данного варианта к общей сумме частот всех вариантов называется частостью или долей этого варианта и обозначается рi , где i—индекс варианта, т. е.
Нетрудно заметить, что частость является статистической вероятностью появления варианта. Естественно считать частость выборочным аналогом (вычисленной по выборочным данным) вероятности рi появления значения хi, случайной величины X. Подсчитав частоты и частости для каждого варианта, наблюдаемые данные представляют в виде таблицы, которую называют дискретным вариационным рядом. В первой строке расположены - варианты, во второй - соответствующие частоты, в третьей- соответствующие частости. Дискретным вариационным рядом распределения называется ранжированная совокупность вариантов хi с соответствующими им частотами или частностями.Для рассмотренного примера ряд имеет вид:
xi | 0 | 1 | 2 | 3 | 4 | 5 | 7 |
mi | 8 | 17 | 16 | 10 | 6 | 2 | 1 |
| 8/60 | 17/60 | 16/60 | 10/60 | 6/60 | 2/60 | 1/60 |
По данным дискретного вариационного ряда строят ![]() полигон частот или относительных частот: ломаную, отрезки которой соединяют точки
полигон частот или относительных частот: ломаную, отрезки которой соединяют точки
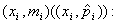
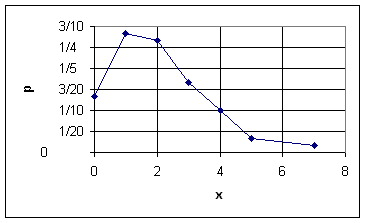
Полигон относительных частот

3.2. Интервальный вариационный ряд.
Если изучаемая случайная величина является непрерывной, то ранжирование и группировка наблюдаемых значений зачастую не позволяют выделить характерные черты варьирования ее значений. Это объясняется тем, что отдельные значения случайной величины могут как угодно мало отличаться друг от друга и поэтому в совокупности наблюдаемых данных одинаковые значения величины могут встречаться редко, а частоты вариантов мало отличаются друг от друга. Нецелесообразно также построение дискретного ряда для дискретной случайной величины, число возможных значений которой велико. В подобных случаях следует построить интервальный (вариационный) ряд распределения. Для построения такого ряда весь интервал варьирования наблюдаемых значений случайной величины разбивают на ряд частичных интервалов и подсчитывают частоту попадания значений величины в каждый частичный интервал.![]() Интервальным вариационным рядом называется упорядоченная совокупность интервалов варьирования значений случайной величины с соответствующими частотами или частостями попаданий в каждый из них значений величины.Построение интервального вариационного ряда рассмотрим на примере. При измерении диаметра валиков после шлифовки получены следующие результаты:
Интервальным вариационным рядом называется упорядоченная совокупность интервалов варьирования значений случайной величины с соответствующими частотами или частостями попаданий в каждый из них значений величины.Построение интервального вариационного ряда рассмотрим на примере. При измерении диаметра валиков после шлифовки получены следующие результаты:
6,75; 6,77; 6,77; 6,73; 6,76; 6,74; 6,70; 6,75; 6,71; 6,72; 6,77; 6,79; 6,71; 6,78;
6,73; 6,70; 6,73; 6,77; 6,75; 6,74; 6,71; 6,70; 6,78; 6,76; 6,81; 6,69; 6,80; 6,80;
6,77; 6,68; 6,74; 6,70; 6,70; 6,74; 6,77; 6,83; 6,76; 6,76; 6,82; 6,77; 6,71; 6,74;
6,77; 6,75; 6,74; 6,75; 6,77; 6,72; 6,74; 6,80; 6,75; 6,80; 6,72; 6,78; 6,70; 6,75;
6,78; 6,78; 6,76; 6,77; 6,74; 6,74; 6,77; 6,73; 6,74; 6,77; 6.74; 6,75; 6,74; 6,76;
6,76; 6,74; 6,74; 6,74; 6,74; 6,76; 6,74; 6,72; 6,80; 6,76; 6,78; 6,73; 6,70; 6,76;
6,76; 6,77; 6,75; 6,78; 6,72; 6,76; 6,78; 6,68; 6,75; 6,73; 6,82; 6,73; 6,80; 6,81;
6,71; 6,82; 6,77; 6,80; 6,80; 6,70; 6,70; 6,82; 6,72; 6,69; 6,73; 6,76; 6,74; 6,77;
6,72; 6,76; 6,78; 6,78; 6,73; 6,76; 6,80; 6,76; 6,72; 6,76; 6,76; 6,70; 6,73; 6,75;
6,77; 6,77; 6,70; 6,81; 6,74; 6,73; 6,77; 6,74; 6,78; 6,69; 6,74; 6,71; 6,76; 6,76;
6,77; 6,70; 6,81; 6,74; 6,74; 6,77; 6,75; 6,80; 6,74; 6,76; 6,77; 6,77; 6,81; 6,75;
6,78; 6,73; 6,76; 6,76; 6,76; 6,77; 6,76; 6,80; 6,77; 6,74; 6,77; 6,72; 6,75; 6,76;
6,77; 6,81; 6,76; 6,76; 6,76; 6,80; 6,74; 6,80; 6,74; 6,73; 6,75; 6,77; 6,74; 6,76;
6,77; 6,77; 6,75; 6,76; 6,74; 6,82; 6,76; 6,73; 6,74; 6,75; 6,76; 6,72; 6,78; 6,72;
6,76; 6,77; 6,75; 6,78.Для построения интервального ряда необходимо определить величину частичных интервалов. Считая, что все частичные интервалы имеют одну и ту же длину, для каждого интервала следует установить его верхнюю и нижнюю границы, а затем в соответствии с полученной упорядоченной совокупностью частичных интервалов сгруппировать результаты наблюдении. Длину частичного интервала h следует выбрать так, чтобы построенный ряд не был громоздким и в то же время позволял выявить характерные черты изменения значений случайной величины. Просматривая результаты наблюдений, находим, что наибольшим значением случайной величины х наиб является 6,83, а наименьшим х наим - 6,68. Найдем размах варьирования R. :R=6,83-6,68=0,15.Выберем число интервалов. Для того чтобы вариационный ряд не был слишком громоздким, обычно число интервалов берут от 7 до 11. Положим предварительно v=7, тогда длина частичного интервала
![]() За начало первого интервала рекомендуется брать величину хнач = хнаим - 0,5h. В данном случае хнач = 6,67.
За начало первого интервала рекомендуется брать величину хнач = хнаим - 0,5h. В данном случае хнач = 6,67.
Конец последнего интервала должен удовлетворять условию
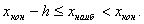
Промежуточные интервалы получают прибавляя к концу предыдущего интервала длину частичного интервала h (в рассматриваемом случае h=0,02).Теперь, просматривая результаты наблюдений, определяем, сколько значений признака попало в каждый конкретный интервал. При этом в интервал включают значения случайной величины, большие или равные нижней границе и меньшие верхней границы. В таблице частота mi , показывает, в скольких наблюдениях случайная величина приняла значения, принадлежащие тому или иному интервалу, причем нижний конец интервала входит в него, а верхний—нет. Такие частоты обычно называют интервальными, а их отношение к общему числу наблюдений—интервальными частостями. При вычислении интервальных частостей округление результатов следует проводить таким образом, чтобы общая сумма частостей была равна 1:
![]() Для данного примера интервальный вариационный ряд имеет вид:
Для данного примера интервальный вариационный ряд имеет вид:
№ | xi - xi+1 | mi |
| mi/h |
|
1 | 6,67-6,69 | 2 | 0,01 | 100 | 0,5 |
2 | 6,69-6,71 | 15 | 0,075 | 750 | 3,75 |
3 | 6,71-6,73 | 17 | 0,085 | 850 | 4,25 |
4 | 6,73-6,75 | 44 | 0,22 | 2200 | 11 |
5 | 6,75-6,77 | 52 | 0,26 | 2600 | 13 |
6 | 6,77-6,79 | 44 | 0,22 | 2200 | 11 |
7 | 6,79-6,81 | 14 | 0,07 | 700 | 3,5 |
8 | 6,81-6,83 | 11 | 0,055 | 550 | 2,75 |
9 | 6,83-6,85 | 1 | 0,005 | 50 | 0,25 |
| 200 | 1 |
По данным интервального ряда строят гистограмму частот или гистограмму относительных частот:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
