

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Каждое из этих уравнений имеет решение, причём единственное, что следует из допущения б). Решениями уравнений являются квантили порядков ![]() и
и ![]() распределения статистики
распределения статистики 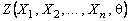 соответственно:
соответственно: ![]() ,
, ![]()
Обычно при определении ![]() и
и ![]() полагают
полагают ![]() . Это объясняется тем, что для симметричных распределений статистики
. Это объясняется тем, что для симметричных распределений статистики ![]() (например,
(например, ![]() или
или ![]() ) такой выбор даёт доверительный интервал наименьшей длины. А для несимметричных распределений (
) такой выбор даёт доверительный интервал наименьшей длины. А для несимметричных распределений (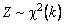 ,
, ![]() ) длина интервала будет близкой к минимальной и случайные выбросы статистики
) длина интервала будет близкой к минимальной и случайные выбросы статистики ![]() в обе стороны от интервала
в обе стороны от интервала ![]() будут равновероятны.
будут равновероятны.
Итак, выбираем ![]() и
и ![]() , в результате получаем
, в результате получаем
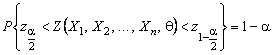 . (4.6.2)
. (4.6.2)
4. Решим неравенства
![]() (4.6.3)
(4.6.3)
относительно параметра ![]() :
:
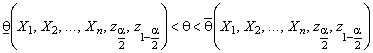 . (4.6.4)
. (4.6.4)
В силу допущения г) неравенства (4.6.3) разрешимы в виде (4.6.4) и, кроме того, неравенства (4.6.3) и (4.6.4) равносильны. Поэтому с учётом (4.6.2) можно записать:
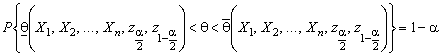 ,
,
т. е. неравенства определяют интервальную оценку параметра ![]() , см. (4.6.1).
, см. (4.6.1).
Окончательно, по выборке ![]() находим доверительный интервал
находим доверительный интервал
![]() .
.
Отметим, что для квантилей симметричных распределений статистики ![]() справедливо равенство
справедливо равенство ![]() , поэтому для таких распределений полагают
, поэтому для таких распределений полагают 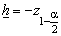 и
и ![]() .
.
Итак, план построения доверительного интервала для параметра ![]() сводится к выполнению следующих действий.
сводится к выполнению следующих действий.
1. Выбор доверительной вероятности ![]() .
.
2. Подбор или построение центральной статистики ![]() с известным законом распределения и нахождение квантилей
с известным законом распределения и нахождение квантилей ![]() и
и ![]() распределения этой статистики, если это распределение несимметрично или квантили
распределения этой статистики, если это распределение несимметрично или квантили ![]() , если оно симметрично.
, если оно симметрично.
3. Решение неравенств 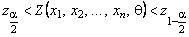 относительно неизвестного параметра
относительно неизвестного параметра ![]() , что приводит к искомому доверительному интервалу
, что приводит к искомому доверительному интервалу
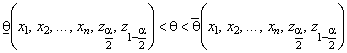
(если распределение статистики симметрично, то ![]() ).
).
При построении доверительных интервалов для параметров нормально распределённых генеральных совокупностей обычно используются статистики, перечисленные в табл. 4.5.1.
13
Понятие корреляции является одним из основных понятий теории вероятностей и математической статистики, оно было введено Гальтоном и Пирсоном.
Закон природы или общественного развития может быть представлен описанием совокупности взаимосвязей. Если эти зависимости стохастичны, а анализ осуществляется по выборке из генеральной совокупности, то данная область исследования относится к задачам стохастического исследования зависимостей, которые включают в себя корреляционный, регрессионный, дисперсионный и ковариационный анализы. В данном разделе рассмотрена теснота статистической связи между анализируемыми переменными, т. е. задачи корреляционного анализа.
В качестве измерителей степени тесноты парных связей между количественными переменными используются коэффициент корреляции (или то же самое "коэффициент корреляции Пирсона") и корреляционное отношение.
Пусть при проведении некоторого опыта наблюдаются две случайные величины ![]() и
и ![]() , причем одно и то же значение
, причем одно и то же значение ![]() встречается
встречается ![]() раз,
раз, ![]() раз, одна и та же пара чисел (
раз, одна и та же пара чисел (![]() наблюдается
наблюдается ![]() раз. Все данные записываются в виде таблицы, которую называют корреляционной.
раз. Все данные записываются в виде таблицы, которую называют корреляционной.
Выборочная ковариация ![]() величин
величин ![]() и
и ![]() определяется формулой
определяется формулой
![]()
где ![]() , а
, а ![]() ,
, ![]() - выборочные средние величин
- выборочные средние величин ![]() и
и ![]() . При небольшом количестве экспериментальных данных
. При небольшом количестве экспериментальных данных ![]() удобно находить как полный вес ковариационного графа:
удобно находить как полный вес ковариационного графа:
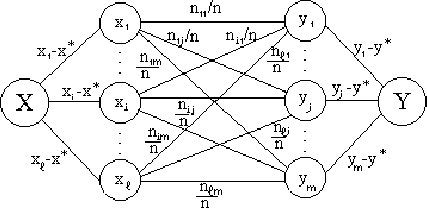
Рис. 101
Выборочный коэффициент корреляции находится по формуле
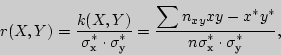
где ![]() - выборочные средние квадратические отклонения величин
- выборочные средние квадратические отклонения величин ![]() и
и ![]() .
.
Выборочный коэффициент корреляции ![]() показывает тесноту линейной связи между
показывает тесноту линейной связи между ![]() и
и ![]() : чем ближе
: чем ближе ![]() к единице, тем сильнее линейная связь между
к единице, тем сильнее линейная связь между ![]() и
и ![]() .
.
Пример 171. Среднемесячная заработная плата (тыс. руб.) в Ярославской области в годах составила по отраслям:
отрасль | здравоохранение | наука | образование | транспорт | промышленность | |
2001 год | 2 | 1,5 | 2,7 | 1,3 | 3,2 | 3,2 |
2002 год | 3 | 2,8 | 3,6 | 2,4 | 4,9 | 4,5 |
Найдите выборочный коэффициент корреляции для заработной платы в указанные годы.
Решение. 1). Найдем выборочные средние
![]()
2). Вычислим выборочную ковариацию
![]()
3). Найдем выборочные средние квадратические отклонения:
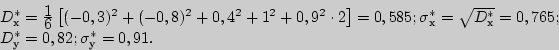
4). Вычислим теперь выборочный коэффициент корреляции
![]()
Поскольку ![]() достаточно близко к
достаточно близко к ![]() , то между заработной платой по отраслям в 2001 и 2002 годах существовала почти линейная зависимость (зарплата в 2002 году по каждой отрасли увеличилась примерно в 1,5 раза).
, то между заработной платой по отраслям в 2001 и 2002 годах существовала почти линейная зависимость (зарплата в 2002 году по каждой отрасли увеличилась примерно в 1,5 раза).
14
Корреляционная зависимость.
Условимся обозначать через Х независимую переменную. а через У—зависимую переменную.
Зависимость величины Y от Х называется функциональной. если каждому значению величины Х соответствует единственное значение величины У.
Обратим внимание на то, что если Х—детерминированная величина (т. е. принимающая вполне определенные значения), то и функционально зависящая от нее величина У тоже является детерминированной; если же X— случайная величина, то и У также случайная величина.
Однако гораздо чаще в окружающем нас мире имеет место не функциональная, а
стохастическая, или вероятностная, зависимость, когда каждому фиксированному значению независимой переменной Х соответствует не одно, а множество значений переменной У, причем сказать заранее, какое именно значение примет величина У, нельзя.
Более частое появление такой зависимости объясняется действием на результирующую переменную не только контролируемого или контролируемых факторов (в данном случае таким контролируемым фактором является переменная X), а и многочисленных неконтролируемых случайных факторов. В этой ситуации переменная У является случайной величиной. Переменная же Х может быть как детерминированной, так и случайной величиной.
Если при изменении одной из величин изменяется среднее значение другой, то стохастическая зависимость называется корреляционной.
Приведем пример такой зависимости: пусть У – урожай зерна, Х – количество удобрений. С одинаковых по площади участков при равном количестве внесенных удобрений снимают разный урожай. Т. е. У не является функцией от Х. это объясняется влиянием случайных факторов: осадки, температура и т. п. Но опыт показывает что средний урожай является функцией от количества удобрений, У связан с Х корреляционной зависимостью: изменяя количество вносимых удобрений, изменяется и средний урожай, т. е. математическое ожидание величины У изменяется при изменении значения Х. Такое математическое ожидание называется условным и обозначается М( У/ Х= х) и читается: математическое ожидание СВУ при условии, что Х =х.
Тогда можно считать: корреляционная зависимость имеет место, если при изменении х изменяется условное математическое ожидание У.
Аналогично вводится понятие условного математического ожидания для СВХ.
g(x) =М(У/Х=х) и f(y) = М(Х/У=у) – называются функциями регрессии, а линию на плоскости, соответствующую этому уравнению – линией регрессии соответственно У на Х и Х на У. Эта линия показывает, как в среднем зависит У от Х или Х от У.
Корреляционной зависимостью ![]() от
от ![]() называют функциональную зависимость условной средней
называют функциональную зависимость условной средней ![]() от
от ![]() .
.
Корреляционная зависимость может быть линейной и криволинейной. В случае линейной корреляционной зависимости выборочное уравнение прямой линии регрессии ![]() на
на ![]() имеет вид:
имеет вид:
![]()
Параметры ![]() и
и ![]() уравнения прямой
уравнения прямой ![]() линии регрессии
линии регрессии ![]() на
на ![]() можно находить по методу наименьших квадратов из системы уравнений
можно находить по методу наименьших квадратов из системы уравнений
![]()
Пример 173. Построить прямую регрессии мировых рекордов по прыжкам с шестом от соответствующего года, если нам известна динамика результатов в ХХ веке.
1912 г. 1936 г. 1972 г. 1980 г. 1988 г. 1994 г. | Стокгольм, Берлин, Москва, Сеул, Сетриере | Гарри Бебкок (США) Эрл Мидоуз (США) Волфганг Нордвик (ГДР) Владислав Казакевич (Польша) Сергей Бубка (СССР) Сергей Бубка (Украина) | 3,95 4,35 5,50 5,78 5,90 6,14 |
Решение. 1). Запишем в таблицу соответствие результатов некоторых мировых рекордов по прыжкам с шестом и годы их установления в ХХ веке.
| (19)12 | 36 | 72 | 80 | 88 | 94 |
| 395 | 435 | 550 | 578 | 590 | 614 |
2). ![]() (см.)
(см.)
3). ![]()
4). ![]()
5). Искомое уравнение прямой регрессии выглядит следующим образом
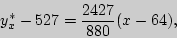
или ![]()
По полученной прямой регрессии можно на вероятностном языке предсказывать уровень мировых рекордов по прыжкам с шестом, так, в 2010 году
(![]() = 110) получаем ожидаемый прыжок на высоту примерно в 6 м 53 см. (поживем - увидим!)
= 110) получаем ожидаемый прыжок на высоту примерно в 6 м 53 см. (поживем - увидим!)
В том случае, когда исследуется связь между несколькими признаками, то корреляцию называют множественной и она задается всеми коэффициентами парных корреляций, которые записываются в корреляционную матрицу.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
