


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лекция 7
Синтаксис языков программирования
Нотация Бэкуса-Наура и синтаксические диаграммы Вирта
Как уже было сказано в предыдущих лекциях, для определения синтаксиса языков программирования широко применяется нотация, предложенная Дж. Бэкусом и П. Науром.
Определение. Нотация Дж. Бэкуса и П. Наур используют зарезервированные метасимволы «::=» и «|», которые читаются как «является» и «или», определяемые понятия, которые выделяются посредством угловых скобок «á» и «ñ», и символы алфавита языка (которые называются терминальными символами). Каждое правило (определение) в этой нотации имеет вид
определяемое понятие ::= серия альтернатив разделённых «|»
где каждая из альтернатив может содержать как определяемые понятия, так и терминальные символы, а в каждой альтернативе синтаксические элементы следуют в порядке их перечисления. Каждое определяемое понятие может иметь несколько определений, которые можно сгруппировать в единое определение, перечислив через «|» как альтернативы. Кроме того, в правой части правил можно использовать вспомогательные (парные) метаскобки «[», «]» «{» и «}»: «[» и «]» означают, что часть определения, заключённая в эти скобки, может быть опущена, а «{» и «}» - что часть определения, заключённая в эти скобки, может быть повторена любое число раз (0, 1, 2 и т. д.).
Точный смысл нотации будет определён после того, как будет определено понятие грамматики и порождаемого языка. А пока ограничимся тем, что приведём один пример. Так, понятие áчислоñ в языке НеМо может быть определено[1] посредством следующих трёх правил:
áчислоñ ::= [áзнакñ] áцифраñ {áцифраñ}
áзнакñ ::= + | -
áцифраñ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Согласно первому из этих правил, число – это любая конечная последовательность цифр, состоящая как минимум из одной цифры, которой может предшествовать знак. Согласно второму, знак – это плюс или минус. Согласно третьему, цифра – это десятичная цифра. В этом определении áчислоñ, áзнакñ и áцифраñ - определяемые понятия, а знаки «+», «-» и цифры «0» … «9» - терминальные символы. Недостаток данного определения – это допустимость ведущих незначащих нулей: +00000 – вполне «законное» áчислоñ. Таким образом, áчислоñ, определённое по этим правилам, - это десятичное целое со знаком (с допустимыми незначащими нулями).
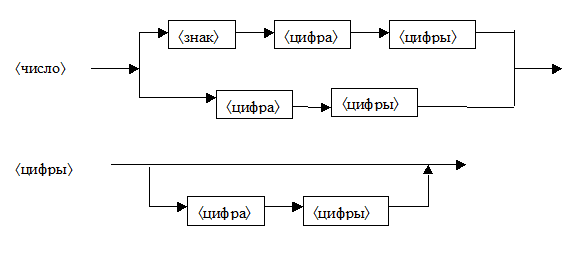
Графический формализм для определения синтаксиса языков программирования – синтаксические диаграммы, введённые в активный «оборот» Н. Виртом.
Определение. В нотации синтаксических диаграмм каждое определение представляет собой ориентированны граф с одним входом и одним выходом, в котором вершины – это
- или терминальные символы,
- или определяемые синтаксические понятия,
- или разветвления/соединения для представления альтернатив,
а дуги представляют отношение «следующий синтаксический элемент».

Пример синтаксических диаграмм: десятичные целые числа со знаком (с допустимыми незначащими нулями) может быть определено следующей диаграммой.
Нотацию Бэкуса-Наура легко перевести в синтаксические диаграммы. Для этого, во-первых, надо «избавиться» от вспомогательных метаскобок «[» и «]», «{» и «}»:
- всякое использование пары метаскобок «[» и «]» можно заменить парой альтернатив с использованием и без использования их содержимого;
- всякое использование пары метаскобок «{» и «}» можно заменить на новый áметаэлементñ и добавить новое определение
áметаэлементñ::= áпустоñ | áсодержимое метаскобокñ áметаэлементñ
(где áпустоñ имеет очевидное определение).
Во-вторых, надо каждое правило
определяемое понятие ::= серия альтернатив разделённых «|»
заменить на синтаксическую диаграмму, которая начинается с ветвления по числу альтернатив, заканчивается соединением ветвей всех альтернатив, а каждая альтернатива представлена цепью, состоящей из элементов этой альтернативы, перечисленных в их естественном порядке.
Пример преобразования нотации Бэкуса-Наура в синтаксические диаграммы: определение áчислоñ ::= [áзнакñ] áцифраñ {áцифраñ} . Во-первых, избавимся от метаскобок:
- сначала от «[» и «]»: áчислоñ ::= áцифраñ {áцифраñ} | áзнакñ áцифраñ {áцифраñ};
- затем от «{» и «}»: áчислоñ ::= áцифраñ áцифрыñ | áзнакñ áцифраñ áцифрыñ áцифрыñ::= | áцифраñ áцифрыñ .
Во-вторых, заменим каждое из получившихся определений на диаграмму:
Синтаксические диаграммы также легко перевести в нотацию Бэкуса-Наура.
Грамматики, языки и классификация Н. Хомского
"Глокая куздра штеко бодланула бокра и курдячит бокренка"
“Colorless green ideas sleep furiously”
N. Chomsky
Определение. Грамматика – это четвёрка вида (N, T, R, S), где
- N – конечный алфавит нетерминальных символов (или нетерминалов),
- T – конечный алфавит терминальных символов (или терминалов),
- R – конечное множество правил (или продукций) вида wL ® wR, где wL и wR – слова в объединённом алфавите NÈT,
- S – начальный (или стартовый) нетерминалы.
Определение. Каждая грамматика G = (N, T, R, S) определяет некоторый L(G) язык следующим образом. Для любых слов a и b в объединённом алфавите NÈT
1. будем писать aGÞb и говорить, что «b получается из a в G за один шаг», если существуют такие слова w1 и w2, wL и wR, что
1.1.a можно представить в виде w1wLw2,
1.2.b можно представить в виде w1wRw2,
1.3.wL®wR – одна из продукций из R;
2. будем писать aGÞnb и говорить, что «b получается из a в G за n шагов» (где n³0),
2.1.если n=0 и a совпадает с b,
2.2.или n>0 и существует такое слово g в объединённом алфавите NÈT, что aGÞg и gGÞ(n-1)b;
3. будем писать aGÞ*b и говорить, что «b получается из a в G», если существует такое n³0, что aGÞnb.
Язык L(G) состоит из всех слов a в алфавите терминальных символов T таких, что SGÞ*a. Принято говорить, что грамматика G порождает язык L(G).
Н. Хомский предложил следующую классификацию грамматик, языки которых не включают пустого слова (т. е. слова без единого символа).
Определение.
- Регулярные грамматики используют продукции вида n®t, n®tm и n®m где n и m – любые нетерминалы, а t – любой терминал;
- контекстно-свободные грамматики используют продукции вида n®w, где n – любой нетерминал, а w – любое непустое слово в объединённом алфавите нетерминалов и терминалов;
- контекстно-зависимые (или неукорачивающие) грамматики используют продукции вида вида wL ® wR, где wL и wR – любые слова в объединённом алфавите нетерминалов и терминалов такие, что |wL|£ |wR|;
- грамматики со фразовой структурой общего вида используют любые продукции с непустой правой частьюы.
Определение. Хомского распрастраняется на грамматики, языки которых включают пустое слово. Для грамматик со фразовой структурой разрешается использовать любые продукции. Для контекстно-зависимых грамматик разрешается использовать одно специальное правило S® (пусто), где S - стартовый нетерминал. Для регулярных и контекстно-свободных грамматик являются допустимыми правила вида n® (пусто) с любым метасимволом n.
Определение. Грамматики G¢ и G¢¢ называются эквивалентными (по языку), если их языки совпадают: L(G¢) = L(G¢¢).
Сделаем следующее замечание об языковой эквивалентности регулярных и контекстно-свободных граммитик. Можно довольно-таки просто доказать, что всякая регулярная или контекстно-свободная грамматика G эквивалентна по языку некоторой грамматике того же класса, но которая, во-первых, не имеет т. н. «цепных правил» – т. е. продукций вида n®m, где n и m – произвольные нетерминалы, во-вторых, в которой стартовый символ S не встречается в правых частях продукций, а в третьих, в которой все правила кроме возможно одного имеют непустую правую часть, а единственное допустимое правило с пустой правой частью - это S® áпустоñ (где S - стартовый нетерминал) допукскается тогда и только тогда, когда L(G) содержит пустое слово. Тем, кто заинтересован как доказать данное утверждение, рекоммендуется попробовать сделать это самостоятельно, или обратиться к стандартным[2] учебникам по синтаксическому анализу, например: Улюман Дж. Теория синтаксического анализа, перевода и компиляции. М: Мирб 1978. Т.1 «Синтаксический анализ», параграф 2.4.2 «Преобразования КС грамматик».
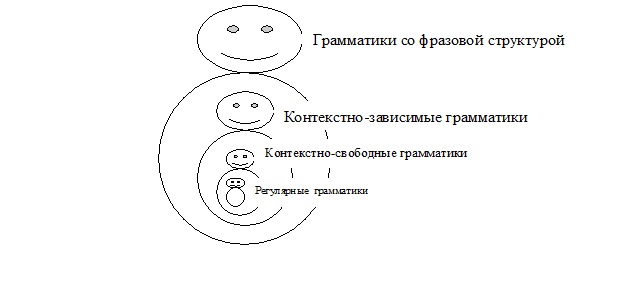
Из определения следует, что классификация Н. Хомского не задаёт разбиение всех грамматик на непересекающиеся классы, а представляет собой некоторую «матрёшку» из вложенных классов:
Определение. Язык L называется
- регулярным,
- контекстно-свободным,
- контекстно-зависимым,
- со фразовой структурой (или рекурсивно-перечислимым)
если существует такая
- регулярная,
- контекстно-свободная,
- контекстно-зависимая,
- со фразовой структурой
грамматика G, которая порождает этот язык (т. е. L=L(G)).
Пример регулярного языка: десятичные целые числа со знаком (с допустимыми незначащими нулями). Пусть Gint= (Nint, Tint, Rint, Sint), где
- Nint ={Sint, Dint} – алфавит метасимволов,
- Tint ={+, -, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9} – алфавит терминальных символов,
- Rint есть объединение 3 следующих наборов продукций
- Sint® +Dint, Sint® - Dint, Sint® Dint ;
- Dint® 0Dint, Dint® 1Dint, Dint® 2Dint, Dint® 3Dint, Dint® 4Dint, Dint® 5Dint, Dint® 6Dint, Dint® 7Dint, Dint® 8Dint, Dint® 9Dint;
- Dint® 0, Dint® 1, Dint® 2, Dint® 3, Dint® 4, Dint® 5, Dint® 6, Dint® 7, Dint® 8, Dint® 9.
Ещё один пример регулярного языка: идентификаторы (т. е. последовательности букв и цифр, которые начинаются с буквы). Пусть Gidn= (Nidn, Tidn, Ridn, Sidn), где
- Nidn ={Sidn, Didn} – алфавит метасимволов,
- Tidn =[a..z]È[0..9] – алфавит терминальных символов,
- Ridn есть объединение 3 следующих наборов продукций
- Sidn® aDidn, … Sidn® zDidn;
- Didn® aDidn, … Didn® zDidn, Didn® 0Didn, … Didn® 9Didn;
- Didn® a, … Didn® z, Didn® 0, … Didn® 9.
Пример контекстно-свободного языка: арифметические выражения над целочисленными переменными и константами. Пусть Gexp= (Nexp, Texp, Rexp, Sexp), где
- Nexp ={Sexp} È Nint È Nidn – алфавит метасимволов,
- Texp = {( , )} È Tint È Tidn– алфавит терминальных символов,
- Rexp есть объединение Rint, Ridn и следующих 3 наборов продукций
- Sexp®Sint, Sexp®Sidn;
- Sexp® (Sexp);
- Sexp® Sexp + Sexp, Sexp® Sexp - Sexp, Sexp® Sexp * Sexp, Sexp® Sexp /Sexp.
Недостаток языка L(Gexp) – использование знака числа после открывающих скобок или после знака арифметической операции из-за правила Sexp®Sint. Так, например, выражение (+123 - +* -0) является вполне легитимным словом этого языка.
Контекстно-свободные грамматики и нотация Бэкуса-Наура
Пусть заданы совокупность определений[3] в нотации Бэкуса-Наура и выделено главное определяемое синтаксическое понятие. По этой совокупности определений и определяемому понятию можно определить контекстно-свободную грамматику (N, T, R, S) следующим образом. Алфавит нетерминалов N состоит из всех определяемых понятий (которые в соответствии с нотацией заключены в угловые скобки «á» и «ñ»). Алфавит терминалов T совпадает с алфавитом терминальных символов, используемых в определениях. А совокупность продукций R получается в результате «разбиения» каждого определения
определяемое понятие ::= альтернатива1 | … | альтернативаk
на серию из отдельных k определений
определяемое понятие ::= альтернатива1 ,
…
определяемое понятие ::= альтернативаk
и последующей замены метасимвола «является» «::=» на продукционную стрелку «®»:
определяемое понятие ® альтернатива1 ,
…
определяемое понятие ® альтернативаk.
И, наконец, в качестве начального символа S примем главное определяемое понятие.
Контекстно-свободная грамматика построенная по произвольной совокупности определений с выделенным главным определяемым понятием, и язык, порождаемый этой грамматикой, будем считать смыслом (семантикой) данной системы определений. Отметим, что при использовании нотации Бэкуса-Наура для определения какого-либо языка программирования главное понятие – это обычно áпрограммаñ, которое обычно явно не выделяется, а выделение подразумевается по умолчанию.
Заметим так же, что любую контекстно-свободную грамматику легко представить в нотации Бэкуса-Наура: для этого достаточно вместо продукционной стрелки «®» использовать метасимвол «::=», заключить всякий нетерминал в угловые метаскобки «á» и «ñ», а начальный символ объявить выделенным главным определяемым понятием.
Регулярные языки
Определение. Коечный автомат – это пятёрка вида (Q, T, P, S, F), где
- Q – конечное множество управляющих (контрольных) состояний;
- T – конечный алфавит входных (терминальных) символов;
- PÍ Q´T´Q – программа (таблица) переходов;
- S, F ÎQ – стартовое (начальное) и финальное (заключительное) состояния.
Операционная семантика конечных автоматов определяется в терминах конфигураций, переходов между конфигурациями и языков, которые принимаются (распознаются) автоматами. Все эти понятия определяются ниже. Для удобства определения выберем и зафиксируем произвольный конечный автомат A=(Q, T, P, S, F) и произвольное слово a=t1…tn в алфавите T.
Определение. Конфигурация A состоит из
- входной ленты, ограниченной слева и бесконечной вправо, разделённой на ячейки, на которой записано слово в алфавите T, по одному символу в ячейке, начиная с первой слева ячейки;
- читающей головки, позиционированной в ячейке входной ленты, которая находится в управляющем состоянии из Q.
Графически конфигурация, в которой на входной ленте записано слово t1…tn в алфавите T, а читающая головка «обозревает» i-ую ячейку ленты (1£ i £ n+1) находится в состоянии qÎQ, принято изображать следующим образом

а текстуально эту конфигурацию принято представлять в виде тройки (q, i, a).
Определение. Начальная конфигурация – это конфигурация (S, 1, a), в которой головка обозревает самую левую ячейку ленты и находится в стартовом стоянии S:
Определение. 
Заключительная конфигурация – это конфигурация (F, (n+1), a), в которой читающая головка обозревает самую левую пустую ячейку ленты, и находится в финальном стоянии F:
Определение. 
Переход между конфигурациями – это произвольная пара конфигураций такая, что (q, ti, q’) ÎP (см. рисунок ниже). В текстуальной форме данный переход принято записывать так: (q, i, a) AÞ (q’, (i+1), a).
Определение. 
Для произвольных конфигураций (q, i, a) и (q”, j, a) и произвольного k³0 принято писать (q, i, a) AÞk (q”, j, a) и говорить, что конфигурация (q”, j, a) получается из (q, i, a) за k шагов тогда и только тогда k=(i-j)=0 и q=q”, или когда k=(j-i)>0 и существует такая конфигурация (q’, (i+1), a), для которой (q, i, a) AÞ (q’, (i+1), a) и (q’, (i+1), a) AÞ(k-1) (q”, j, a). Другими словами, (q, i, a) AÞk (q”, j, a) тогда и только тогда, когда существует последовательность из k конфигураций, в которой каждая следующая получается из предыдущей в результате перехода.
Определение. Для произвольных конфигураций (q, i, a) и (q”, j, a) принято писать (q, i, a) AÞ* (q”, j, a) и говорить, что конфигурация (q”, j, a) получается (достижима) из (q, i, a) тогда и только тогда, когда (q, i, a) AÞk (q”, j, a) для некоторого k³0.
Определение. Говорят, что автомат A=(Q, T, P, S, F) распознаёт (принимает) слово a=t1…tn в алфавите T тогда и только тогда, когда заключительная конфигурация со словом a достижима из начальной конфигурации с этим же словом на ленте, т. е. когда (S, 1, a) AÞ* (F, (n+1), a).
Для иллюстрации определений используем следующий конечный автомат ADD, в котором QADD = { S, F, M}, TADD = {0,1}´{0,1}´{0,1}, а программа PADD состоит из следующих переходов:
(S, (0,0,0), S), (S, (0,1,1), S), (S, (1,0,1), S), (S, (1,1,0), M),
(S, (0,0,0), F), (S, (0,1,1), F), (S, (1,0,1), F), (S, (1,1,0), M),
(M, (0,0,1), S), (M, (0,1,0), M), (M, (1,0,0), M), (M, (1,1,1), M), (M, (0,0,1), F).
Допустимо использовать «табличный» формат для программы переходов, в котором на пересечении строки, соответствующей какому-либо состоянию qÎQ, и столбца, соответствующего какому-либо символу алфавита tÎTADD, перечислены все такие q', для которых (q, t,q’)ÎP:
(0,0,0) | (0,0,1) | (0,1,0) | (0,1,1) | (1,0,0) | (1,0,1) | (1,1,0) | (1,1,1) | |
S | S, F | S, F | S, F | M | ||||
M | S, F | M | M | M |
Для большей наглядности будем изображать символы алфавита TADD не в строчку, а в столбик. Тогда любое слово в этом алфавите, записанное на входную ленту автомата ADD, можно мыслить как три двоичных кода, состоящих из одинакового колличества разрядов, записанных одно под другим. Например,
0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | |
1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | |
1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
представляет слово (0,1,1)(1,1,0)(1,1,1)(0,1,0)(0,0,1)(1,0,1)(0,0,0)(1,0,1)(0,1,1), а
0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | |
1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
представляет слово (0,1,0)(1,0,0)(0,1,0)(1,0,0)(0,1,0)(1,0,0)(0,1,0)(1,0,0)(0,1,0).
Интерпретируем каждый из этих двоичных кодов как двоичное число, записанное «задом наперёд»: младшие разряды – слева, старшие – справа. Тогда первый пример – правильный пример на сложение столбиком, соответствующий равенству 166 (первая строчка) + 271 (вторая строчка) = 437 (третья строчка). А второй пример – неправильный пример на сложение столбиком: 170 (первая строчка) + 341 (вторая строчка) ¹ 0 (третья строчка).
Первый пример (0,1,1)(1,1,0)(1,1,1)(0,1,0)(0,0,1)(1,0,1)(0,0,0)(1,0,1)(0,1,1) принимается автоматом ADD, что подтверждается следующей «эволюцией» состояний вдоль слова:
0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | |
1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | |
1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
А вот второе слово (0,1,0)(1,0,0)(0,1,0)(1,0,0)(0,1,0)(1,0,0)(0,1,0)(1,0,0)(0,1,0) не принимается автоматом ADD, т. к. уже для первого символа этого слова (0,1,0) не существует такого состояния qÎQADD= {S, M, F}, что (S, (0,1,0), q)ÎPADD.
То, что автомат ADD принимает первое слово и не принимает второе, - неслучайно. Оказывается, для любого слова a=t1…tn в алфавите TADD, для любого iÎ[1..n] имеет место следующее:
- (S, i, a)ADDÞ(n+1-i)(F, (n+1), a) тогда и только тогда, когда суффикс ti…tn слова a - правильный пример на сложение двоичных чисел, записанных задом наперёд;
- (M, i, a)ADDÞ(n+1-i)(F, (n+1), a) тогда и только тогда, когда суффикс ti…tn слова a - правильный пример на сложение числа 1 (единицы переноса) и двоичных чисел, записанных задом наперёд.
Доказательство легко провести индукцией по iÎ[1..n]. Отсюда следует, в частности, что (S, 0, a)ADDÞ* (F, (n+1), a) тогда и только тогда, когда a - правильный пример на сложение двоичных чисел, записанных задом наперёд.
Пусть A – конечный автомат. Язык, который распознаёт (допускает или принимает) A – это множество L(A) всех слов, которые принимает этот автомат.
Теорема 3 (о распознавании регулярных языков).
1. Всякий регулярный язык допускается некоторым конечным автоматом.
2. Всякий язык, который допускается конечным автоматом, является регулярным.
Доказательство.
1. Пусть L – произвольный регулярный язык. Пусть G=(N, T,R, S) – регулярная грамматика, порождающая L, т. е. L=L(G). Если язык L не содержит пустого слова, то можно считать, что все продукции этой грамматики имеют вид n®t и n®tm, где n и m – любые нетерминалы, а t – любой терминал; если же язык L содержит пустое слово, то грамматика G содержит ещё одно правило S® . Оба случая рассматриваются аналогично, поэтому рассмотрим только первый из них, когда пустое слово не содержится в языке L. В этом случае определим автомат A следующим образом. В качестве множества состояний Q примем множество нетерминалов N, расширенное заключительным состоянием F: Q = N È {F}. Начальное состояние автомата совпадает с начальным символом грамматики. Множество терминалов автомата, разумеется, совпадает с T. Множество продукций P состоит из двух частей:
1.1. { (n, t, m) : n, m Î N, tÎT и (n®tm)ÎR }
1.2. { (n, t, F) : nÎN, tÎT и (n®t)ÎR }.
Тогда для любого k³1, любого слова t1…tk в алфавите T и любых n1,…nkÎN имеем: n1 GÞ t1n2 GÞ … GÞ t1…t(k-1)nk GÞ t1…t(k-1)tk тогда и только тогда, когда (n1, 1, t1…tk) AÞ (n2, 2, t1…tk) AÞ… (nk, k, t1…tk) AÞ (F, (k+1), t1…tk). Действительно, для любого iÎ[1..(k-1)] имеем:
(ni, i, t1…tk) AÞ (n(i+1), (i+1), t1…tk)
ßÝ
(ni, ti, n(i+1)) ÎP
ßÝ
(ni® tin(i+1)) ÎR
ßÝ
t1…t(i-1)ni GÞ t1… t(i-1)tin(i+1).
Аналогично:
(nk, k, t1…tk) AÞ (F, (k+1), t1…tk)
ßÝ
(nk, tk, F) ÎP
ßÝ
(nk® tk) ÎR
ßÝ
t1…t(k-1)nk GÞ t1… t(k-1)tk.
2. Пусть L – произвольный язык, допускаемый конечным автоматом. Пусть A=(Q, T, P, S, F) – конечный автомат, который принимает этот язык. Определим регулярную грамматику G следующим образом. В качестве алфавита нетерминалов N примем множество состояний Q. Разумеется, алфавит терминальных символов будет T, а начальным нетерминальным символом будет S. Множество продукций R грамматики G состоит из двух подмножеств:
2.1. { n®tm : n, m Î Q, tÎT и (n, t, m)ÎP }
2.2. { n®t : nÎQ, tÎT и (n, t, F)ÎR }.
Тогда для любого k³1, любого слова t1…tk в алфавите T и любых q1,…qkÎQ имеем: q1 GÞ t1q2 GÞ … GÞ t1…t(k-1)qk GÞ t1…t(k-1)tk тогда и только тогда, когда (q1, 1, t1…tk) AÞ (q2, 2, t1…tk) AÞ… (qk, k, t1…tk) AÞ (F, (k+1), t1…tk). (Доказательство – аналогично предыдущему случаю.)
■
Следствием из этой теоремы является следующая «лемма о разрастании».
Теорема 2.
|
 Для всякого регулярного языка L существует такое число k>0, что любое слово aÎL, длина которого |a| больше k, можно представить в виде bgd (где g - непустое слово) так, что для любого i>0 слово bgi d ÎL (где gi есть g … g ).
Для всякого регулярного языка L существует такое число k>0, что любое слово aÎL, длина которого |a| больше k, можно представить в виде bgd (где g - непустое слово) так, что для любого i>0 слово bgi d ÎL (где gi есть g … g ).
 Доказательство. Пусть L – произвольный регулярный язык. Тогда существует некоторый конечный автомат A= (Q, T, P, S, F), который принимает этот язык (т. е. L=L(A)). Пусть k число состояний автомата A (т. е. k=|Q|). Для любого слова a= t1…tn, длина которого |a| = n >k, которое принимает автомат A, существует последовательность состояний q1,… q(n+1) такая, что q1=S, q(n+1)=F, а то, что слово a принимается автоматом A, подтверждается следующей «эволюцией» состояний вдоль ленты автомата:
Доказательство. Пусть L – произвольный регулярный язык. Тогда существует некоторый конечный автомат A= (Q, T, P, S, F), который принимает этот язык (т. е. L=L(A)). Пусть k число состояний автомата A (т. е. k=|Q|). Для любого слова a= t1…tn, длина которого |a| = n >k, которое принимает автомат A, существует последовательность состояний q1,… q(n+1) такая, что q1=S, q(n+1)=F, а то, что слово a принимается автоматом A, подтверждается следующей «эволюцией» состояний вдоль ленты автомата:
t1 | t2 | ………… | t(n-1) | tn | ………….. |
![]()
![]()
![]()
![]()
Т. к. слово a имеет длину |a|>k, то среди состояний q1,… q(n+1) найдётся хотя бы одно повторяющееся. Пусть qs (где sÎ[1..k])– первое слева такое состояние, которое уже ранее встречалось, т. е. для которого qs=qr (где rÎ[1..s[). Имеем:
t1 | ..b¢.. | tr | ..g'.. | ts | ..d¢.. | tn | …………. |
где b¢, g¢ и d¢ – соответствующие части слова a. Т. к. qr=qs, то
t1 | ..b¢.. | tr | ..g¢.. | tr | ..g¢.. | ts | ..d¢.. | tn | … |
![]()
![]()
![]()
![]()
![]()
представляет последовательность конфигураций, которая подтверждает, что слово t1b¢ trg¢ trg¢ tsd¢tn принимается автоматом A и, следовательно, принадлежит языку L. Поэтому если принять t1b¢ в качестве b, trg¢ – в качестве g, а tsd¢tn – в качестве d, то получается, что слово a=bgd, а слово t1b¢trg¢trg¢tsd¢tn=bggd. Применив к слову bggd вышеизложенную процедуру выделения подслова g повторно, получаем, что bgggdÎL, а многократно – что bgidÎL для любого i>0. По построению g - непустое слово.
■
Как явствует из доказательства леммы о разрастании, её формулировка может быть усилена следующим образом: Для всякого регулярного языка L существует такое число k>0, что любое слово aÎL, длина которого |a| больше k, можно представить в виде bgd так, что |b|<k, 0<|a|<k и для любого i>0 слово bgi d ÎL. В такой «усиленной» форме лемма о разрастании может использоваться для того, чтобы доказывать не регулярность некоторых языков.
Например, докажем, что ранее определённый язык арифметических выражений над целочисленными переменными и константами не является регулярным.
Предоложим, что язык L(Gexp) является регулярным. Тогда (согласно усиленной лемме о расширении) существует такое число k>0, что любое слово aÎL, длина которого |a| больше k, можно представить в виде bgd так, что |b|<k, 0<|g|<k и для любого i>0 слово bgi d ÎL. Выберем n>2k. Слово (n 0 )n, cостоящее из n открывающих скобок, нуля и n закрывающих скобок, является правильно построенным арифметическим выражением и приналежит языку L(Gexp). Это слово, в частности, можно представить в виде bgd так, что |b|<k, 0<|a|<k и для любого i>0 слово bgi d ÎL. В силу того, что n>2k заключаем, что g непусто и состоит только из открывающих скобок и, следовательно (n+|g| 0 )n ÎL(Gexp). Но это слово не является правильно построенным арифметическим выражением из-за дисбаланса открывающих и закрывающих скобок и, следовательно, (n+|g| 0 )n ÏL(Gexp). – Противоречие. Следовательно, предположение, что L(Gexp) – регулярный язык, неверно.
[1] Здесь и далее будут приводиться в качестве примеров некоторые варианты определений, но не единственно возможные варианты. В частности, некоторые варианты и примеры могут даже противоречить друг другу.
[2] Наш курс более нацелен на изучение семантических вопросов трансляции.
[3]Как уже отмечалось ранее, не теряя общности можно считать, что в определениях не используются вспомогательные метаскобки «[», «]» «{» и «}».
