
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Сортировка разделением (быстрая сортировка)
Хотя пузырьковая сортировка среди элементарных методов считается в среднем самой неэффектной, ее улучшение – быстрая сортировка является самым лучшим на данный момент методом сортировки массивов. Метод был предложен Хоором и назван быстрой сортировкой.
В этом методе для достижения наилучшей эффективности перестановки производятся на большие расстояния, как и в методе Шелла.
Рекурсивный вариант
При просмотре элементов с обоих концов массива элементы массива А[l…r] переставляются таким образом, чтобы элементы A[l…k] были не больше любого элемента A[k+1, r], где к – некоторый индекс на интервале l…r, то есть l![]() k
k![]() r. То есть массив разбивается на две части, в первой из которых сосредоточены меньшие значения, а во второй – большие. Эта операция называется разделением.
r. То есть массив разбивается на две части, в первой из которых сосредоточены меньшие значения, а во второй – большие. Эта операция называется разделением.
Затем операция рекурсивно выполняется для частей A[l…k] и A[k+1…r] до тех пор, пока размер части не станет равным 1. После этого массив отсортирован.
44 | 55 | 12 | 42 | 94 | 06 | 18 | 67 |

18 | 06 | 12 | 42 |
94 | 55 | 44 | 67 |
44 | 55 |
94 | 67 |
55 |
94 |
18 | 42 |
06 |
18 | 12 | 42 |
44 |
67 |
12 |
18 |
42 |
Общий ход быстрой сортировки запишем так:
QSort (A, l, r)
1 if l<r
2 then k![]() Partition (A, l, r)
Partition (A, l, r)
3 QSort (A, l, k)
4 QSort (A, k+1, r)
Основной операцией является операция разделения массива на две части с описанными выше свойствами. Чем лучше она работает, тем эффективнее работает алгоритм в целом.
Разбиение массива (Partition)
Наугад берется элемент массива в качестве опорного, относительно которого массив разбивается на две части. Часть массива A[l…k] будет содержать элементы, не большие х, а вторая часть A[k+1…r] – элементы не меньшие х.
Разделение происходит при просмотре массива с двух концов. Вначале просматриваем массив от конца до тех пор, пока не обнаружим элемент A[j]![]() x, затем просматриваем массив от начала до тех пор, пока не обнаружим элемент A[i]
x, затем просматриваем массив от начала до тех пор, пока не обнаружим элемент A[i]![]() x.
x.
Теперь поменяем эти элементы и продолжим процесс встречного просмотра и обмена до тех пор, пока оба просмотра не встретятся где-то посередине массива. В результате массив окажется разбитым на две части. В левой части будут элементы с ключами меньшими или равными х, в правой – с ключами большими или равными х, а значение индексов просмотра определяют точку разбиения массива на две части – k.
i j
4418 67
Допустим, в качестве опорного значения х взят ключ 42.
![]()

![]() i j
i j
4418 67

![]()
![]() i j
i j
1844 67
i j
1844 67
j=3 k i=5
Теперь по рекурсии разделяем первую и часть A[l…k] и A[k+1…r], выбирая в них в свою очередь опорные элементы.
В приведенном примере опорный элемент выбран удачно, и массив оказался поделенным на две части. Итак, псевдокод операции Partition можно записать так. Partition (A, l, r);
Реализация алгоритма разбиения содержит ряд тонких моментов. Во-первых, не очевидно, что индексы i и j не выйдут за пределы участка l…r в процессе работы. Во-вторых, разбиение зависит от того, насколько удачно выбран опорный элемент х.
Если разбиение происходит на примерно равные части, то время работы составляет O(nlogn). В худшем случае, если размеры частей сильно отличаются, время разбиения пропорционально O(n2) и снижается к эффективности метода сортировки вставками. Но метод имеет и недостатки: он неэффективен для небольших n. Алгоритм не любит упорядоченные массивы. Еще одно неприятное свойство – это проблема глубины рекурсии. Как известно, вызов функции образует в системном стеке кластер, в котором сохраняются точка возврата из функции, входные параметры функции, локальные переменные. Для больших файлов глубина рекурсии может быть значительной, особенно в наихудшем случае. То есть количество кластеров в стеке колеблется от logn до n. Это может привести к переполнению стека и отказу системы. Поэтому предлагают итеративную версию быстрой сортировки.
Итеративный вариант
Итеративный алгоритм использует собственный стек разбиений. На каждом этапе возникают две следующих части. Только к одной части можно приступить сразу же, другая же заносится в стек. Каждая часть запоминается в стеке в виде левого и правого индекса. Часть, помещенная в стек первой будет в дальнейшем выбрана из стека последней. С расчетом на худший случай размер стека должен быть равным 2n. Itrative_QSort (A, n); И все-таки, несмотря на утешительные результаты при случайном выборе разделяющего элемента, допускающего чередование плохих и хороших разделений, предлагаются методы выбора разделяющего элемента, который будет медианой, то есть будет делить массив на две равные части. Это приближает быструю сортировку к оптимальной.
Хоор предложил выбирать разделяющий элемент в неупорядоченном массиве случайным образом, то есть задавать индекс в виде случайного числа. Такой алгоритм сортировки называется вероятностным. Для задания индекса можно использовать генератор случайных чисел. Такой способ показал хорошую эффективность.
Еще один способ поиска разделяющего элемента близкого к медиане известен, как метод медианы трех, когда в качестве граничного используется средний из трех случайно выбранных элементов массива.
Этот метод существенно снижает возникновение вероятности худшего случая, поскольку вероятность выбора сразу двух наименьших или наибольших значений существенно ниже вероятности выбора одного наименьшего или наибольшего значения.
Например, в качестве трех элементов можно взять первый, последний и серединный элементы в массиве A[l…r], то есть A[l], A[r], A[(l+r)/2].
Есть способ точного определения медианы. Хоор предложил другой способ поиска медианы, использующий ту же схему просмотра элементов, которая используется в алгоритме разбиения при быстрой сортировке.
Сначала применяется разделение относительно выбранного значения A[k]. Получаются значения индексов i и j такие, что
1) A[h]![]() x для h<i
x для h<i
2) A[h]![]() x для h>i
x для h>i
3) i<j
Возможны три варианта:
1) x слишком мало. В результате искомое значение ищется в большей правой части
|
|
l j i r
k
2) x слишком велико и наоборот левая часть содержит искомое значение.
|
|
![]()
![]() l j i r
l j i r
k
3) k лежит в интервале j<k<i. И элемент A[k] является медианой.
|
|
j k i
Процесс разбиения продолжается до появления случая 3. Find_median (A, n, k);
В среднем каждое разбиение уменьшает размер следующего просматриваемого подмассива. Таким образом, на поиск медианы потребуется
n+n/2+n/4+…+1=2n шагов.
Но в худшем случае этот метод дает O(n2) шагов. Его не следует использовать для небольших массивов.
Сортировка слиянием
Сортировка слиянием во многом похожа на метод быстрой сортировки и также относится к алгоритмам типа O(nlogn). Если сопоставить производительность трех методов типа O(nlogn), то исследования показали, что производительность сортировки слиянием лежит между производительностью пирамидальной и быстрой сортировки. Но в отличие от пирамидальной и быстрой сортировок, метод сортировки слиянием ведет себя стабильно, поскольку он не зависит от перестановок элементов в массиве. Еще одним достоинством сортировки слиянием является то, что он удобен для структур с последовательным доступом к элементам, таким как файлы на внешнем устройстве, связные списки. Этот метод, прежде всего, используется для внешней сортировки.
Но метод имеет и недостатки. Он требует дополнительной памяти по объему равной объему сортируемого файла. Поэтому для больших файлов проблематично организовать сортировку слиянием в оперативной памяти.
В случаях, когда гарантированное время сортировки важно и размещение в оперативной памяти, возможно, следует предпочесть метод сортировки слиянием.
Сортировку слиянием можно проиллюстрировать примером:
4406 67
Разобьем на первом шаге файл на два файла:
44
94
Объединим эти два файла снова в один файл, содержащий упорядоченные пары:
44 94’ 18 55’ 06 12’ 42 67
Снова разобьем файл и объединим пары в четверки:
44 94’ 18 55
06 12’ 42 67
Слияние:’
Разобьем файл и объединим четверки:
06
18
Слияние:55 67 94
Итак, основной операцией является слияние. При слиянии требуется дополнительная память для размещения файла, образующегося при слиянии. Операция линейно зависит от количества элементов в объединяемых массивах.
В общем, виде можно предположить, что сливаемые файлы имеют разную размерность: A[1…n], B[1…m]. При слиянии образуется третий массив C[1…n+m]. Merge (A, n, B, m, C); Такая операция называется двух путевым слиянием.
Нисходящая сортировка слиянием.
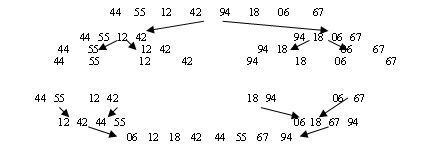 Эта сортировка является рекурсивной операцией, которая делит файл пополам и выполняет по рекурсии сортировку обеих половин. Дерево рекурсии выглядит следующим образом:
Эта сортировка является рекурсивной операцией, которая делит файл пополам и выполняет по рекурсии сортировку обеих половин. Дерево рекурсии выглядит следующим образом:
Рекурсия ограничена снизу размером разделяемого файла, равным 1. Каждый рекурсивный вызов делит файл пополам. В случае если размер файла кратен 2, получается полное, сбалансированное дерево рекурсии. Если n не кратно 2, то дерево получается несбалансированным, но все равно его высота оценивается logn. Общий алгоритм нисходящей сортировки слиянием выглядит следующим образом: Merge_Sort (A, L, R, C); Для нисходящей сортировки модифицируем процедуру слияния. Вместо двух файлов она получает границы двух сливаемых частей массива А. Кроме того, результат слияния она вновь помещает в исходный массив А. Массив С используется как вспомогательный для слияния. Его размерность равна размерности массива А. Merge (A, L, m, R, C); Такая реализация слияния избавляет от необходимости проверок при слиянии конца того или другого массива, поскольку максимальный элемент того или другого файла ограничивают продвижение индекса в файле с меньшим максимальным элементом.
Восходящая сортировка слиянием
Сначала выполняются все слияния 1 – с – 1, что соответствует нижнему уровню дерева, затем все слияния 2 – с – 2, затем слияния 4 – с – 4 и т. д. То есть дерево обходится снизу, с полной обработкой каждого уровня.
0667 94
![]()
![]() 4 – с – 4
4 – с – 4
1267 94
2 – с – 2 2 – с – 2
4506 67

![]()
![]()
![]() 1 – с – 1 1 – с – 1 1 – с – 1 1 – с – 1
1 – с – 1 1 – с – 1 1 – с – 1 1 – с – 1
4406 67
Такую схему сортировки можно выполнить с помощью итеративного алгоритма: Iterative_Merge_Sort (A, n, C); Итак, сортировка слиянием так же, как и пирамидальная и быстрая сортировки имеют оценку эффективности O(nlogn). Она превосходит по быстродействию пирамидальную сортировку, но уступает почти в два раза быстрой сортировке. Но у нее есть превосходство перед быстрой сортировкой – устойчивость. Главный недостаток – использование дополнительной памяти.
10. Линейная структура - стек, формы представления и операции.
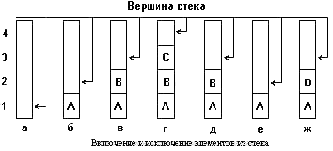 Стек - такой последовательный список с переменной длиной, включение и исключение элементов из которого выполняются только с одной стороны списка, называемого вершиной стека. Применяются и другие названия стека - магазин, функционирующая по принципу LIFO (Last - In - First - Out - "последним пришел - первым исключается"). Примеры стека: винтовочный патронный магазин, тупиковый железнодорожный разъезд для сортировки вагонов. Основные операции над стеком - включение нового элемента (английское название push - заталкивать) и исключение элемента из стека (англ. pop - выскакивать). Полезными могут быть также вспомогательные операции: определение текущего числа элементов в стеке; очистка стека; неразрушающее чтение элемента из вершины стека, которое может быть реализовано, как комбинация основных операций: x:=pop(stack); push(stack, x);
Стек - такой последовательный список с переменной длиной, включение и исключение элементов из которого выполняются только с одной стороны списка, называемого вершиной стека. Применяются и другие названия стека - магазин, функционирующая по принципу LIFO (Last - In - First - Out - "последним пришел - первым исключается"). Примеры стека: винтовочный патронный магазин, тупиковый железнодорожный разъезд для сортировки вагонов. Основные операции над стеком - включение нового элемента (английское название push - заталкивать) и исключение элемента из стека (англ. pop - выскакивать). Полезными могут быть также вспомогательные операции: определение текущего числа элементов в стеке; очистка стека; неразрушающее чтение элемента из вершины стека, которое может быть реализовано, как комбинация основных операций: x:=pop(stack); push(stack, x);
11. Линейная структура - очередь, формы представления и операции
Очередью FIFO (First - In - First - Out - "первым пришел - первым исключается"). называется такой последовательный список с переменной длиной, в котором включение элементов выполняется только с одной стороны списка (эту сторону часто называют концом или хвостом очереди), а исключение - с другой стороны (называемой началом или головой очереди). Те самые очереди к прилавкам и к кассам, которые мы так не любим, являются типичным бытовым примером очереди FIFO. Основные операции над очередью - те же, что и над стеком - включение, исключение, определение размера, очистка, неразрушающее чтение.
12. Линейная структура – связный список, формы представления и операции
 Списком называется упорядоченное множество, состоящее из переменного числа элементов, к которым применимы операции включения, исключения. Список, отражающий отношения соседства между элементами, называется линейным. Длина списка равна числу элементов, содержащихся в списке, список нулевой длины называется пустым списком. Линейные связные списки являются простейшими динамическими структурами данных. Графически связи в списках удобно изображать с помощью стрелок. Если компонента не связана ни с какой другой, то в поле указателя записывают значение, не указывающее ни на какой элемент. Такая ссылка обозначается специальным именем - nil. На рис. приведена структура односвязного списка. На нем поле INF - информационное поле, данные, NEXT - указатель на следующий элемент списка. Каждый список должен иметь особый элемент, называемый указателем начала списка или головой списка, который обычно по формату отличен от остальных элементов. В поле указателя последнего элемента списка находится специальный признак nil, свидетельствующий о конце списка. Двусвязный список характеризуется наличием пары указателей в каждом элементе: на предыдущий элемент и на следующий. Очевидный плюс тут в том, что от данного элемента структуры мы можем пойти в обе стороны. Таким образом упрощаются многие операции. Однако на указатели тратится дополнительная память. Разновидностью рассмотренных видов линейных списков является циклический список, который может быть организован на основе как односвязного, так и двухсвязного списков. При этом в односвязном списке указатель последнего элемента должен указывать на первый элемент; в двухсвязном списке в первом и последнем элементах соответствующие указатели переопределяются. При работе с такими списками несколько упрощаются некоторые процедуры. Однако, при просмотре такого списка следует принять некоторых мер предосторожности, чтобы не попасть в бесконечный цикл.
Списком называется упорядоченное множество, состоящее из переменного числа элементов, к которым применимы операции включения, исключения. Список, отражающий отношения соседства между элементами, называется линейным. Длина списка равна числу элементов, содержащихся в списке, список нулевой длины называется пустым списком. Линейные связные списки являются простейшими динамическими структурами данных. Графически связи в списках удобно изображать с помощью стрелок. Если компонента не связана ни с какой другой, то в поле указателя записывают значение, не указывающее ни на какой элемент. Такая ссылка обозначается специальным именем - nil. На рис. приведена структура односвязного списка. На нем поле INF - информационное поле, данные, NEXT - указатель на следующий элемент списка. Каждый список должен иметь особый элемент, называемый указателем начала списка или головой списка, который обычно по формату отличен от остальных элементов. В поле указателя последнего элемента списка находится специальный признак nil, свидетельствующий о конце списка. Двусвязный список характеризуется наличием пары указателей в каждом элементе: на предыдущий элемент и на следующий. Очевидный плюс тут в том, что от данного элемента структуры мы можем пойти в обе стороны. Таким образом упрощаются многие операции. Однако на указатели тратится дополнительная память. Разновидностью рассмотренных видов линейных списков является циклический список, который может быть организован на основе как односвязного, так и двухсвязного списков. При этом в односвязном списке указатель последнего элемента должен указывать на первый элемент; в двухсвязном списке в первом и последнем элементах соответствующие указатели переопределяются. При работе с такими списками несколько упрощаются некоторые процедуры. Однако, при просмотре такого списка следует принять некоторых мер предосторожности, чтобы не попасть в бесконечный цикл.
13. Линейная структура –список на базе массива, формы представления и операции.
14. Деревья. Классификация деревьев. Способы программного представления деревьев.
Дерево – математическая абстракция, которая используется при разработке и анализе алгоритмов
· для описания динамических свойств алгоритмов,
· построения явных структур данных.
Одно из наиболее известных структур данных – дерево каталогов в файловой системе компьютера.
Существуют различные типы деревьев:
· 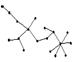 -дерево (свободное дерево) – непустое множество вершин и ребер. Характерным для дерева является существование только одного пути между любыми двумя вершинами. В этом смысле дерево можно считать частным случаем графа.
-дерево (свободное дерево) – непустое множество вершин и ребер. Характерным для дерева является существование только одного пути между любыми двумя вершинами. В этом смысле дерево можно считать частным случаем графа.
· -лес – несвязанный набор деревьев.
· дерево с корнем – дерево, в котором выделен узел – корень дерева. Между корнем и любым другим узлом существует только один путь. Обычно ребра в дереве с корнем указывают направление пути от корня к узлам. В этом смысле к узлам дерева с корнем применяется терминология генеалогических деревьев (узел – родитель, дочерний узел, узлы – потомки, узлы - предки). Узлы, не имеющие дочерних узлов, называются листьями.
· упорядоченное дерево – дерево с корнем, в котором определен порядок дочерних узлов каждого узла.
· М-арное дерево – дерево, в котором каждый узел должен иметь конкретное количество дочерних узлов. Если узлы не имеют заданного количества узлов, то они ссылаются на фиктивные узлы.
· бинарное дерево – дерево, в котором каждый узел имеет два дочерних узла. Строго говоря, бинарное дерево – это либо внешний узел, либо внутренний узел, связанный с парой бинарных деревьев – левым и правым поддеревом.
Способы представления деревьев:
· на базе массива,
· связное представление, основывающееся на использовании индексов массивов или адресных указателей.
Для представления деревьев с любым числом дочерних узлов обычно принято связное представление по схеме «левый сын – правый брат», в котором каждый узел имеет два указателя. Левый указывает на связный список дочерних узлов для данного узла, правый – используется для включения данного узла в список дочерних узлов родителя.
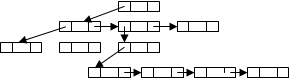
 Для связного представления М-арных деревьев узлы снабжены массивом из М указателей на дочерние узлы. Для экономии памяти в М-арных деревьях выделяется особый тип узлов – листья, не имеющих массива указателей на дочерние узлы. Узлы бинарных деревьев имеют два указателя на левый и правый дочерние узлы. Если алгоритм требует прохождения от узлов к корню, то узлы могут быть снабжены третьим указателем на родителя.
Для связного представления М-арных деревьев узлы снабжены массивом из М указателей на дочерние узлы. Для экономии памяти в М-арных деревьях выделяется особый тип узлов – листья, не имеющих массива указателей на дочерние узлы. Узлы бинарных деревьев имеют два указателя на левый и правый дочерние узлы. Если алгоритм требует прохождения от узлов к корню, то узлы могут быть снабжены третьим указателем на родителя.
15. Бинарное дерево поиска. Схемы обхода бинарных деревьев. Алгоритм вертикального вывода дерева на экран.
Математические свойства бинарных деревьев
Бинарное дерево с n внутренними узлами имеет n+1 внешних узлов (листьев).
Бинарное дерево с n внутренними узлами имеет 2n ребер, n-1 ребро с внутренними узлами и n+1 ребро с внешними узлами.
Уровень узла в дереве на единицу выше уровня родительского узла. Уровень корня равен 0.
Высота дерева – максимальный из уровней узлов в дереве. Длина пути дерева – сумма уровней всех узлов дерева. Длина внутреннего пути – сумма уровней всех внутренних узлов дерева. Длина внешнего пути – сумма уровней всех внешних узлов дерева.
Из этих определений вытекают рекурсивные определения: высота дерева на единицу больше максимальной высоты поддеревьев его корня.
При анализе рекурсивных алгоритмов максимальная глубина рекурсии соответствует высоте дерева рекурсии и определяет размер стека, необходимого для поддержки вычислений.
Высота бинарного дерева с n внутренними узлами не меньше log2 n и не больше n-1.
Длина внутреннего пути с n внутренними узлами не меньше, чем n*log(n/4) и не больше, чем n*(n-1)/2.
Деревья бинарного поиска
Для решения проблемы излишних затрат на вставку и удаления и сохранения быстрого бинарного поиска используется явная древовидная структура – дерево бинарного поиска (BST).
BST – это бинарное дерево, с каждым из узлов которого связан ключ, причем ключ в любом узле больше(или равен) ключам во всех узлах левого поддерева этого узла и меньше(или равен) ключам во всех узлах правого поддерева этого узла.
Каждый узел BST содержит ссылки на левого и правого сына, возможно на родителя, ключ и ссылку на данные.
Ввиду рекурсивной природы дерева обычно алгоритмы операций также рекурсивны.
Обход BST – дерева
Наиболее общей функцией обработки деревьев является обход дерева, когда для выполнения некоторой операции на дереве, требуется выборка значений из узлов дерева. В зависимости от алгоритма операции возможна одна из трех схем обхода: прямой обход(сверху вниз), при котором обрабатывается значение в узле, а затем значения из левого и правого поддеревьев узла поперечный обход(слева направо), при котором обрабатываются значения из левого поддерева, затем значение узла, затем значения из правого поддерева обратный обход(снизу вверх), при котором обрабатываются значения из левого и правого поддеревьев, а затем значение узла. Псевдокод обхода “сверху вниз” : To_Down(T); Над деревом можно выполнять операции, имеющие не рекурсивный алгоритм. Но для этого операции должны использовать собственный стек, чтобы иметь возможность вернуться к ранее пройденным, но не обработанным узлам. Iterative_To_Down(T); Существует еще одна схема обхода узлов дерева – по уровням, при которой узлы посещаются сверху вниз и слева направо на одном уровне. Обход по уровням можно получить из предыдущей операции обхода «сверху вниз», заменив в ней стек на очередь, обслуживаемую по дисциплине FIFO. Traverse(T);
Рассмотрим использование операций обхода дерева для выполнения быстрого вывода дерева.
Схема поперечного обхода удобна для вертикальной распечатки дерева. Show(T, level) + Print(data, level);
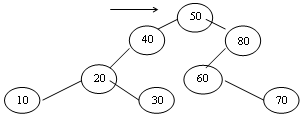 Например, дерево
Например, дерево
Вызов функции - Show(root, 1)
В результате вызова задается порядок обхода
(0,3),(80,2),(0,5),(70,4),(0,5),(60,3),(0,4),(50,1),(0,3),(40,2),(0,5),(30,4),(0,5),(20,3),(0,5),(10,4),(0,5)
Если распечатать дерево по схеме прямого обхода, то получится схема печати, аналогичная распечатке дерева каталогов в файловой системе. Show_Down(T, level);
16. Бинарное дерево поиска. Рекурсивные алгоритмы поиска и вставки нового элемента, эффективность алгоритмов.
Описание бинарного дерева поиска дано в вопросе 15. Листинг рекурсивной операциии поиска: BST_Search(t, k);
Вставки нового элемента: BST_Insert(t, k);
Оценка производительности операций в BST – дереве
Производительность операций вставки, поиска и удаления в среднем пропорциональна О(log n).
Но BST-дерево в худшем случае вырождается(когда ключи поступают в дерево в порядке возрастания или убывания). В этом случае сложность операций оценивается как О(n).
17. Бинарное дерево поиска. Итеративные алгоритмы поиска и вставки нового элемента, эффективность алгоритмов.
Описание бинарного дерева поиска дано в вопросе №15. Листинг итеративной операциии поиска: BST_Iterative_Search(t, k); Вставки нового элемента: BST_Iterative_Insert(t, x); Оценнка эффективности алгоритмов дана в вопросе №16
18. Бинарное дерево поиска. Алгоритм удаления элемента, эффективность алгоритма.
Описание бинарного дерева поиска дано в вопросе №15. Листинг операции удаления: BST_Delete(t, k) + Del(t, t0);
Оценка эффективности дана в вопросе № 16
19. Бинарное дерево поиска. Алгоритм вставки в корень дерева нового элемента, эффективность алгоритма
Описание бинарного дерева поиска дано в вопросе №15. В стандартной реализации BST-дерева каждый новый элемент вставляется в нижнюю часть дерева и становится листом дерева. Иногда целесообразно вставлять новый элемент в корень дерева. В результате вновь поступившие элементы располагаются ближе к корню дерева. Такая схема особенно целесообразна, когда приложение чаще всего обрабатывает последние элементы, недавно поступившие в структуру. Благодаря тому, что они находятся ближе к корню, среднее время поиска этих элементов снижается.
Первое решение, которое приходит на ум - сделать новый элемент новым корнем, а старый корень пристроить в качестве правого или левого сына в зависимости от соотношения ключей нового элемента и старого корня. Пример:
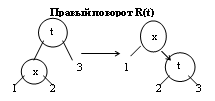
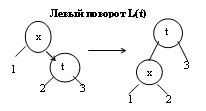
 Но проблема заключается в том, что в левом или правом поддереве могут оказаться ключи, нарушающие упорядоченность дерева. Поэтому нужна определенная перестройка дерева. Чтобы обеспечить упорядоченность BST-дерева, при включении используется несколько иная схема. Новый элемент включается, как и при стандартной схеме в качестве листа, но затем путем поворотов поднимается в корень. Повороты осуществляются снизу вверх для каждого узла, лежащего на пути от нового листа к корню. Могут использоваться левые и правые повороты. Листинги : R(t)+L(t);
Но проблема заключается в том, что в левом или правом поддереве могут оказаться ключи, нарушающие упорядоченность дерева. Поэтому нужна определенная перестройка дерева. Чтобы обеспечить упорядоченность BST-дерева, при включении используется несколько иная схема. Новый элемент включается, как и при стандартной схеме в качестве листа, но затем путем поворотов поднимается в корень. Повороты осуществляются снизу вверх для каждого узла, лежащего на пути от нового листа к корню. Могут использоваться левые и правые повороты. Листинги : R(t)+L(t);
Функция вставки в корень рекурсивная: BST_Root_Insert(t, x);
Проиллюстрируем работу этой функции на примере дерева:
Можно заметить еще одно преимущество такой вставки - балансировка высоты левого и правого поддерева, что оправдывает дополнительные затраты на вращения.
20. Бинарное дерево поиска. Алгоритм поиска предыдущего элемента
Описание бинарного дерева поиска дано в вопросе №15. BST_Predecessor(t, x)+ BST_Maximum(left[x]) + BST_Right_Parent(t, x);

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
