
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. Анализ вычислительной сложности алгоритмов.
Алгоритм –метод решения.
Большинство представляющих интерес алгоритмов сопряжены с методами организации данных, участвующих в вычислениях. Созданные таким образом объекты называются «структурами данных».
Анализ алгоритмов – ключ к их пониманию в степени, достаточной для эффективности их применения при решении практических задач.
Существуют два основных способа анализа – проводить исчерпывающие эксперименты или предварительный математический анализ программы. Целью анализа является получение характеристик производительности выбранного алгоритма. Анализ играет определенную роль в каждой точке разработки и реализации алгоритмов. Прежде всего, можно сократить время выполнения на три-шесть порядков за счет правильного выбора алгоритма. Как правило, на этом этапе можно провести приближенный математический анализ. Точный предварительный математический анализ зачастую невозможен ввиду сложной структуры алгоритма и данных, непредсказуемого состава данных. Задачей программиста является использование полученных результатов (в литературе) анализа при выборе алгоритма для разрабатываемого приложения.
Очевидно, что время сортировки массива зависит от размера сортируемого массива и его упорядоченности. Время работы алгоритма определяется числом шагов, которые он выполняет. Будем считать, что строка псевдокода требует не более чем фиксированного количества элементарных операций, если строка не является формулировкой сложных действий. В последнем случае строка соответствует программной функции, а в основном алгоритме ей соответствует вызов той функции. Вызов функции и ее выполнение отличаются по времени.
При анализе около каждой строки будем отмечать ее стоимость – число элементарных операций Сi и число раз, которые эта строка выполняется.
Выведем основной параметр, используемый при анализе – размерность массива n, т. е. число элементов.
Insertion_Sort (A) | Стоимость | Число раз | |
1. | for j | С1 | n |
2. | do key | С2 | n-1 |
3. |
| ||
4. | i | С4 | n-1 |
5. | while i>0 and A[i]>key | С5 |
|
6. | do A[i+1] | С6 |
|
7. | i | С7 |
|
8. | A[i+1] | С8 | n-1 |
Для каждого j от 2 до n подсчитаем, сколько раз будет выполнена строка 5 и обозначим это число через tj.
Строка стоимостью С, повторенная n раз, вносит в общее время c*m операций.
Сложив все вклады строк, получим показатель:
![]()
Эффективность зависит не только от размерности массива, но и от его упорядоченности. Наиболее благоприятный случай, когда массив уже отсортирован. Тогда цикл в строке 5 завершается после первой проверки, т. к. A[i]![]() key при i= j-1 и tj =1. Тогда общее время равно:
key при i= j-1 и tj =1. Тогда общее время равно:
![]()
![]()
Таким образом, T(n) линейная функция и имеет вид Т(n)=a*n+b. Если массив расположен в обратном порядке, убывающем порядке, время работы функции будет максимальным, т. к. каждый элемент A[j] придется сравнивать со всеми элементами A[1]…A[j-1]. При этом tj =j. , то в худшем случае получим:
Т. к. ![]() и
и 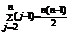
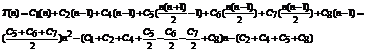
![]() , т. е. функция T(n)- квадратичная и имеет вид T(n)=a*n2+b*n+c. Константы a, b, c определяются значениями С1, …. , С8.
, т. е. функция T(n)- квадратичная и имеет вид T(n)=a*n2+b*n+c. Константы a, b, c определяются значениями С1, …. , С8.
О(1) - | Большинство инструкций программы запускается один или несколько раз, независимо от n. Т. е. время выполнения программы постоянно. |
О(logn) - | Программа работает медленнее с ростом n. Такое время характерно для программ, которые сводят большую задачу к набору меньших подзадач, уменьшая на каждом шаге размер подзадачи на некоторый постоянный коэффициент. |
О(n) - | Время выполнения программы линейно. Каждый входной элемент подвергается небольшой обработке. |
О(nlogn) - | Время выполнения программы пропорционально nlogn возникает тогда, когда алгоритм решает задачу, разбивая ее на меньшие подзадачи, решая их независимо и затем объединяя решения. Можно применить к такой зависимости термин «линерифмический». |
О(n2) - | Время выполнения программы является квадратичным. Такие алгоритмы можно использовать для относительно небольших n. Такое время характерно, когда обрабатываются все пары элементов (в цикле двойного уровня вложенности). |
О(n3) - | Алгоритм обрабатывает тройки элементов (возможно, в цикле тройного уровня вложенности) и имеет кубическое время выполнения. Такой алгоритм практически применим только для малых задач. |
О(2n) - | Лишь несколько алгоритмов с экспоненциальным временем имеет практическое применение, хотя такие алгоритмы возникают естественным образом при попытке прямого решения задач. |
Обычно время выполнения в результате анализа выглядит как многочлен, где главным членом является один из вышеприведенных. Коэффициент при главном члене зависит от количества инструкций во внутреннем цикле. Поэтому так важно максимально упрощать количество инструкций во внутреннем цикле. При росте N начинает доминировать главный член, поэтому остальными слагаемыми в многочлене можно пренебречь.
2 – 9. Сортировка
Базовые принципы построения алгоритмов сортировки
Последовательности элементов или файлы элементов сортируются с использованием ключей. Как правило, ключи являются частью элементов. В процессе сортировки элементы упорядочиваются по ключам в алфавитном или цифровом порядке.
Если сортируемый файл полностью помещается в операторной памяти, то используемый метод сортировки называется внутренним. Сортировка файлов, хранящихся на диске, называется внешней. Особенностью внешней сортировки является последовательный доступ к элементам или доступ к большим блокам элементов.
Данные могут быть организованы в массивы или связанные списки. Основными операциями сортировки являются сравнение и обмен элементов.
Алгоритмы сортировки могут быть адаптивными, когда выполняются различные последовательности действий в зависимости от результатов сравнения. И наоборот - неадаптивными, т. е. не зависящими от порядка следования элементов.
Часто используются методы сортировки элементов с несколькими ключами; когда сортировка элементов в различные моменты времени по разным ключам. Метод сортировки называется устойчивым, если при сортировке по одному ключу он сохраняет относительный прядок по другим ключам.
Если сортируемые элементы имеют большие размеры, то целесообразно применять непрямую сортировку, когда переупорядочиваются не сами элементы, а указатели на элементы. Ключи хранятся либо вместе с элементами, либо вместе с указателями.
Основной характеристикой алгоритма сортировки является показатель вычислительной сложности, зависящий от количества сортируемых элементов n. Элементарные методы сортировки требуют О(n2) шагов. Более совершенные методы имеют показатель О(nlogn).
Аналитические оценки получены на основе подсчета базовых операций сравнения и обмена. Как правило, эти операции сосредоточены во внутренних циклах алгоритма. Поэтому эти циклы максимально упрощены за счет удаления по возможности вспомогательных команд.
Вторым показателем эффективности алгоритма сортировки является объем дополнительной памяти, используемый для сортировки. По этому показателю алгоритмы делятся на три группы:
1. алгоритмы, которые организуют сортировку на том же месте и не используют дополнительную память, за исключением стека или таблицы.
2. алгоритмы, которые используют представление в виде связанного списка или другие структуры указателей или индексов.
алгоритмы, которые требуют дополнительную память для размещения еще одной копии массива для сортировки.
Сортировка выбором
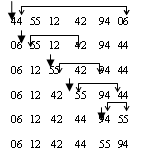 Сначала ищется минимальный элемент в массиве A[1…n] и меняется местами с первым элементом в массиве. Далее находится второй минимальный элемент в массиве A[2…n] и меняется местами со вторым элементом и т. д. Т. е. алгоритм работает по принципу выбора наименьшего элемента из числа несортированных.
Сначала ищется минимальный элемент в массиве A[1…n] и меняется местами с первым элементом в массиве. Далее находится второй минимальный элемент в массиве A[2…n] и меняется местами со вторым элементом и т. д. Т. е. алгоритм работает по принципу выбора наименьшего элемента из числа несортированных.
Основную составляющую времени представляет количество операций сравнения во внутреннем цикле (строка 4). Это время пропорционально n2 . Количество операций обмена равно n-1.
Недостатком сортировки выбором является то, что время выполнения алгоритма мало зависит от упорядоченности массива. На сортировку почти отсортированного файла или файла, где много одинаковых ключей, уходит столько же времени, что и на сортировку файла, упорядоченного случайным образом.
Однако этому методу надо отдать предпочтение, когда элементы файла имеют большой размер, а ключи занимают небольшой объем. В этом случае затраты на перемещение больших элементов минимальны при небольшой стоимости операций сравнения. Selection_Sort (A)
Сортировка вставками
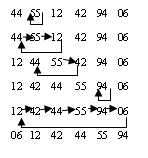 При сортировке вставками каждый очередной элемент помещается в надлежащее место среди отсортированных элементов. Для освобождения места для вставляемого элемента производится смещение части элементов в отсортированной части на одну позицию вправо.
При сортировке вставками каждый очередной элемент помещается в надлежащее место среди отсортированных элементов. Для освобождения места для вставляемого элемента производится смещение части элементов в отсортированной части на одну позицию вправо.
Алгоритм можно улучшить, убрав проверку i>0 в цикле while. Для этого перед сортировкой в массиве ищется минимальный элемент и помещается в первую позицию массива. После этого можно приступить к сортировке, не проверяя начало массива во внешнем цикле.
В отличие от сортировки выбором сортировка вставками зависит от исходного порядка ключей в файле. Если ключи уже упорядочены, то сортировка вставками протекает быстро.
Обменная сортировка (пузырьковая)
Алгоритм выполняет повторные проходы по файлу с обменом местами соседних элементов, нарушающих заданный порядок. Проходы прекращаются, когда файл окажется отсортированным. Пузырьковый метод в общем случае обладает меньшим быстродействием. Достаточно выполнить n проходов. За каждый проход очередной минимальный элемент перемещается на первую позицию в неотсортированной части. Bubble_Sort (A) ;
;
Представленный алгоритм не является адаптивным. Его можно улучшить, проверяя, не оказался ли очередной проход таким, что на нем не было выполнено ни одной операции перестановки. Если файл полностью упорядочен, то не произойдет ни одной перестановки и внешний цикл можно прекратить. Однако внедрение подобного усовершенствования не достигает эффективности алгоритма сортировки вставками, в которм осуществляется прерывание внутреннего цикла, а не внешнего.
Все представленные алгоритмы сортировки характеризуются оценкой эффективности О(n2), но не нуждаются в дополнительной памяти. Время выполнения этих алгоритмов отличается только коэффициентом пропорциональности.
Сортировка вставками и пузырьковая сортировка показывают хорошие результаты при обработке файлов, не обладающих произвольной организацией, которые часто встречаются на практике. Применение к таким файлам универсальной сортировки нецелесообразно. Например, частично отсортированный файл часто появляется, если к отсортированному файлу добавляются несколько новых элементов, или изменяются ключи нескольких элементов. Для таких файлов наиболее эффективным является алгоритм сортировки вставками.
Шейкер–сортировка
Шейкер–сортировка является усовершенствованным методом пузырьковой сортировки.
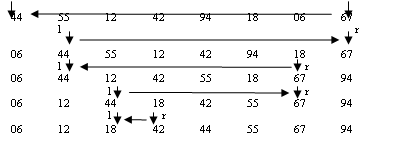 Во-первых, вводится достаточное прерывание проходов, если на очередном проходе обнаруживается, что файл уже отсортирован. Для этого на каждом проходе запоминается, организовался ли обмен на этом проходе.
Во-первых, вводится достаточное прерывание проходов, если на очередном проходе обнаруживается, что файл уже отсортирован. Для этого на каждом проходе запоминается, организовался ли обмен на этом проходе.
Если запоминать не только факт обмена, но и место (индекс) последнего обмена, то можно организовать просмотр пар на следующем проходе этим индексом. Действительно, поскольку левее этого индекса не было обменов, значит, все пары левее этого индекса уже упорядочены и нет смысла их просматривать.
Алгоритм пузырьковой сортировки демонстрирует симметрию: один неправильно расположенный «пузырек» всплывает на место за один проход, а неправильно расположенный «тяжелый» элемент в легком конце опускается за один проход на один шаг в сторону правильного места.
Массив 1294 06 будет отсортирован за один проход, а массив 9455 67 будет отсортирован за 7 проходов. Эта симметрия подсказывает третье улучшение – менять направление следующих один за другим проходов. Поэтому алгоритм называется шейкер-сортировкой. Sheker_Sort (A);
Шелл - сортировка
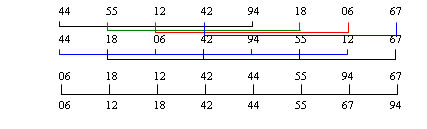 Алгоритм Шейкер-сортировки является усовершенствованием алгоритма сортировки методом вставок. Быстродействие сортировки Шелла по сравнению с методом вставок обеспечивается за счет того, что при погружении элемента перемещается сразу на большое расстояние.
Алгоритм Шейкер-сортировки является усовершенствованием алгоритма сортировки методом вставок. Быстродействие сортировки Шелла по сравнению с методом вставок обеспечивается за счет того, что при погружении элемента перемещается сразу на большое расстояние.
Сортировка происходит за несколько этапов. На первом этапе элементы, отстоящие друг от друга на расстоянии h, объединяются в группу. Таким образом, образуется n/h групп. В каждой группе производится сортировка вставками.
Таким образом в файле образуется совокупность отсортированных подфайлов, т. е. файл h-упорядочен. На следующем этапе расстояние h уменьшается и вновь повторяется h-сортировка подфайлов. Она выполняется быстрее, поскольку в результате предыдущего этапа файл уже частично отсортирован. Таким образом последовательно выполняются h-сортировки с уменьшающимся шагом. На последнем этапе h=1, но файл уже почти отсортирован и число перемещений на этом этапе будет значительно меньше по сравнению с обычным методом вставок.
Немаловажным вопросом является выбор расстояний h1, h2, h3, … ,ht при условии ht=1 и hi+1< hi. Сортировка с h1+i < hi/2 … 4, 2, 1 дает плохие результаты, поскольку на всех этапах, за исключением последнего, элементы на нечетных позициях не сравниваются с элементами на четных позициях. Для случайных файлов эффективность резко снижается и приближается к О(n2). Это пропорционально, например, если половина элементов с меньшими значениями находится на четных позициях, а другая половина с большими значениями – на нечетных позициях. Shell_Sort (A);
Анализ эффективности сортировки Шелла показал, что алгоритм имеет показатель эффективности О(n3/2).
Сортировка с помощью дерева – выбора.
Этот метод возник при попытке улучшить сортировку выбором, эффективность которой – О(n2).
Напомню, сортировка выбором основана на выборе наименьшего ключа среди n элементов, затем среди n-1 элементов и т. д. Поиск наименьшего ключа соответственно требует n-1, n-2, n-3 и т. д. сравнений.
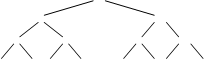
Можно ускорить сортировку, уменьшив количество сравнений при поиске наименьшего элемента, если в результате каждого прохода получать больше информации, чем просто позицию минимального элемента.
Например, можно сравнить попарно соседние элементы и определить в каждой паре меньший элемент. Для этого потребуется n/2 сравнений. Затем сравнить попарно меньшие элементы и определить меньшие из меньших (требуется n/4 сравнений). Наконец получится одна пара меньших из меньших и определяется наименьший элемент.
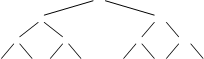 Изобразим этот процесс графически: Хотя в сумме получилось n-1 сравнений, но зато определен минимальный элемент и получено дерево выбора, хранящее информацию о наименьших элементах в подгруппах из двух, четырех и т. д. элементах. Как использовать это дерево для выбора следующего наименьшего элемента?
Изобразим этот процесс графически: Хотя в сумме получилось n-1 сравнений, но зато определен минимальный элемент и получено дерево выбора, хранящее информацию о наименьших элементах в подгруппах из двух, четырех и т. д. элементах. Как использовать это дерево для выбора следующего наименьшего элемента?
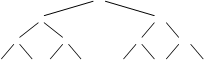 Для этого убираем из дерева выбора наименьший элемент (выбор) и заменяем его в дереве на «дыру» (или ключ
Для этого убираем из дерева выбора наименьший элемент (выбор) и заменяем его в дереве на «дыру» (или ключ ![]() ). Для этого мы спускаемся по дереву по пути, указанному значением наименьшего ключа и заменяем его «дырой».
). Для этого мы спускаемся по дереву по пути, указанному значением наименьшего ключа и заменяем его «дырой».
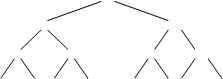
При возврате корректируем промежуточные узлы дерева, замененные «дырами», выбираем вновь в парах наименьшие значения (снизу вверх).В корне дерева вновь оказался элемент с наименьшим ключом. Вновь удаляем его из дерева и т. д.
 Повторив n таких шагов, дерево становится пустым (то есть состоит из «дыр») и процесс сортировки закончен.
Повторив n таких шагов, дерево становится пустым (то есть состоит из «дыр») и процесс сортировки закончен.
Поскольку операция спуска по дереву при исключении элемента на каждом шаге пропорциональна log2n, то сортировка займет время nlog2n, то есть это лучше, чем О(n2) для элементарной сортировки выбором.
Но задача сортировки стала сложнее. Она требует хранение дополнительной информации (2n-1) о структуре дерева, сам алгоритм усложнился и выигрыш кажется сомнительным. Желательно избавиться от «дыр» в дереве, которые приводят к ненужным сравнениям при удалении элементов. Кроме того, хотелось бы вернуться к сортировке без использования дополнительной памяти.
То есть нужно найти такой способ организации дерева, чтобы не использовать дополнительной памяти и в нем не было бы «дыр». Поэтому и создана пирамидальная сортировка.
Пирамидальная сортировка
 Пирамида определяется как последовательность ключей
Пирамида определяется как последовательность ключей ![]() такая, что
такая, что ![]()
![]() и
и ![]() для i=l, …, z/2, где
для i=l, …, z/2, где ![]() - левый сын,
- левый сын, ![]() - правый сын узла
- правый сын узла ![]() .
.
Часто пирамиду называют частично упорядоченным деревом, поскольку здесь не обязательно соблюдение требования 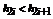 . Такую последовательность (дерево) можно разместить в массиве. Корень дерева занимает первую позицию, то есть имеет индекс 1, сыновья корня – позиции 2, 3. В свою очередь сыновья сыновей занимают позиции 4 и 5 и 6 и 7 соответственно и т. д.
. Такую последовательность (дерево) можно разместить в массиве. Корень дерева занимает первую позицию, то есть имеет индекс 1, сыновья корня – позиции 2, 3. В свою очередь сыновья сыновей занимают позиции 4 и 5 и 6 и 7 соответственно и т. д.
Попробуем использовать вместо дерева выбора такую пирамиду. Например, пирамида является деревом выбора. 06
![]()
42 12
55
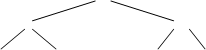
Как построить пирамиду на базе сортируемого массива?
Во-первых, надо рассматривать алгоритм построения и расширения пирамиды. Пусть дана исходная пирамида из семи элементов, которую мы хотим расширить, добавив элемент ![]() =44.
=44.
![]()
42 06
55
Добавляем этот элемент в корень будущей пирамиды (в массиве - слева). Далее этот элемент просеивается по пути, на котором находятся меньшие по сравнению с ним элементы. Просеивание идет до тех пор, пока элемент не займет правильное место. Встречающиеся на пути меньшие элементы соответственно поднимаются вверх. При этом в корень попадает минимальный элемент.
44
42 06
55
При просеивании соблюдается правило: если промежуточный узел имеет сыновей, ключи которых меньше, то следующим выбирается сын с наименьшим значением, то есть при просеивании 44 мы выберем узлы 6 и 12
06
42 12
55
Как в сортируемом массиве выстроить пирамиду?
44|
![]()
Вторую половину массива можно считать нижним уровнем пирамиды. Здесь элементы взаимно не упорядочены. Будем постепенно добавлять к пирамиде слева элементы, и просеивать их.
Вторую половину массива можно считать нижним уровнем пирамиды. Здесь элементы взаимно не упорядочены. Будем постепенно добавлять к пирамиде слева элементы, и просеивать их.
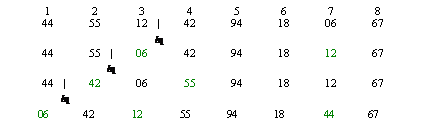
Рассмотрим алгоритм в пирамиде. Входом является массив и индексы, задающие границы строящейся в массиве пирамиды.
Shift (A, l, R);
06 (1)
42 ![]()
![]()
![]()
![]()
55 )
67 (8)
Теперь надо удалить элемент из пирамиды таким образом, чтобы на ее вершине вновь оказался минимальный элемент. Это можно сделать, взяв самый последний элемент в пирамиде и поставив его в вершину. Последующее просеивание поставит в вершину новый минимальный элемент.
![]()
![]() 12
12
![]()
![]()
![]()
![]() 42 18
42 18
55
И т. д. пока пирамида не опустеет.
Извлекаемые элементы из пирамиды помещаются на место последних элементов, которые переносятся в вершину пирамиды во время сортировки.
Итак, имеем исходную пирамиду:
0644 67
Удаляем элемент из вершины (06) и затем помещаем в вершину последний элемент (67). Значение 06 помещаем на место 67. При этом правая граница пирамиды смещается влево на одну позицию.
![]()
![]()
![]()
![]() 6744 | 06
6744 | 06
 |
1244 06
![]()
![]() 44| 12 06
44| 12 06
 |
1812 06
![]()
![]()
![]()
![]() 67|
67|
 |  |
4212 06
94|
4412 | 06
![]()
![]() 6712 | 06
6712 | 06
 |
5512 | 06
94 67 |06
6712 | 06
Heap_Sort (A);
Оценка эффективности:
Пирамидальная сортировка неэффективна для небольших n, но очень эффективна при больших n и становится сравнима с сортировкой Шелла. Даже в самом плохом случае сортировка имеет эффективность О(nlogn). Неясно, какой случай плохой. Сортировка очень любит последовательности, в которых элементы более менее отсортированы в обратном порядке.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
