
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() B B R
B B R
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() R R y
R R y
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() x R x
x R x
Если дядя нового узла y-красный, то восстановление свойства в области включения сводится к перекраске родителя и дяди в черный цвет, а деда – в красный. Перекраска не меняет черной высоты дерева. Но теперь может быть нарушено 3-е свойство выше по дереву. Случаи 2 и 3 соответствуют конфигурации, когда у красного узла x родитель красный, но дядя - черный. Случай 2 имеет дело с конфигурацией, когда x имеет правую (левую) ориентацию, а родитель – левую (правую) ориентацию, то есть разные ориентации в дереве.
 Случай 2 Случай 3
Случай 2 Случай 3
![]()
![]()
![]() P[x]
P[x]
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()

![]()
![]() P[x] перекраска
P[x] перекраска
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() X дед
X дед
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() y
y
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() x
x
 | ||||
В случае 2 используем левый поворот родителя узла x, чтобы свести случай 2 к случаю 3.
В случае 3 делаем правый поворот деда узла x и перекраску: опущенный дед перекрашивается в красный цвет, а поднятый родитель – в черный цвет.It_RB_Insert(t,x); Моделирование показало, что если встречается случай 2 , то выполняется не более 2-х вращений, при случае 3 – не более одного вращения.
34. Хеш – таблицы. Типы и особенности функций хеширования.
Хеш-таблица - это обычный массив с необычной адресацией, задаваемой хеш-функцией.
Хеширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом объеме памяти, и нужен способ быстрого, практически произвольного доступа. Хэш-таблицы часто применяются в базах данных, и, особенно, в языковых процессорах типа компиляторов и ассемблеров, где они изящно обслуживают таблицы идентификаторов. В таких приложениях, таблица - наилучшая структура данных. Так как всякий доступ к таблице должен быть произведен через хэш-функцию, функция должна удовлетворять двум требованиям: Она должна быть быстрой, и она должна порождать хорошие ключи для распределения элементов по таблице. Последнее требование минимизирует коллизии (случаи, когда два разных элемента имеют одинаковое значение хеш-функции) и предотвращает случай, когда элементы данных с близкими значениями попадают только в одну часть таблицы.
Один из наиболее эффективных способов реализации словаря - хеш-таблица. Среднее время поиска элемента в ней есть O(1), время для наихудшего случая - O(n).
Модульное хэширование ( хэш - функция ): h(k)=k%m, o<=h(k)<=m-1, где k-данные для хэширования, m - размер хэш-таблицы. Преимущество : быстрое вычисление, но не для всех значений m. Не рекомендуется брать m=2^p и m=10^p и m=3^p (если ключи символьные). Лучше всего в качестве размера таблицы брать простое число.
![]()
![]() Мультипликативное хэширование : h(k)={m*[A*k]}, где 0<A<1 –const. “[ ]”-дробная часть, “{}” –целая часть. m - размер хэш-таблицы. к - хэшируемые данные. В качестве такой константы Кнут рекомендует золотое сечение (sqrt/2 = 0..
Мультипликативное хэширование : h(k)={m*[A*k]}, где 0<A<1 –const. “[ ]”-дробная часть, “{}” –целая часть. m - размер хэш-таблицы. к - хэшируемые данные. В качестве такой константы Кнут рекомендует золотое сечение (sqrt/2 = 0..
При данной функции хэширования размер хэш-таблицы лучше всего брать как
Хэширование строк
![]()
![]()
или
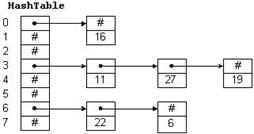 35. Хеш – таблицы с цепочками коллизий. Эффективность операций в хеш-таблицах с цепочками коллизий
35. Хеш – таблицы с цепочками коллизий. Эффективность операций в хеш-таблицах с цепочками коллизий
![]() Цепочное хэширование (или открытое). В такую таблицу можно включить неограниченное количествово элементов.
Цепочное хэширование (или открытое). В такую таблицу можно включить неограниченное количествово элементов.
![]()
максимальное количество элементов, m – размер хэш таблицы.
Используется массив списков. При хэшировании включаемого ключа получаем место в массиве (фактически попадаем в нужный нам список) и включаем в данный список наши данные(ключ). Графически это может быть проиллюстрированно так: в данном примере размер таблицы = 8. Например, чтобы добавить 11, мы делим 11 на 8 и получаем остаток 3. Таким образом, 11 следует разместить в списке, на начало которого указывает hashTable[3].
![]() Операции поиска и удаления аналогичны. Чтобы найти число, мы его хешируем и проходим по соответствующему списку. Чтобы удалить число, мы находим его и удаляем элемент списка, его содержащий. При добавлении элементов в хеш-таблицу выделяются куски динамической памяти, которые организуются в виде связанных списков, каждый из которых соответствует входу хеш-таблицы. Этот метод называется связыванием.Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай - когда все ключи хешируются в один индекс. При этом мы работаем с одним линейным списком, который и вынуждены последовательно сканировать каждый раз, когда что-нибудь делаем. Отсюда видно, как важна хорошая хеш-функция. Оценка эффективности : n – текущее кол-во элементов, m - размер таблицы, alpha-коэф. заполненности. Alpha –дожна быть больше 0. Эффективность операций O(1+alpha).
Операции поиска и удаления аналогичны. Чтобы найти число, мы его хешируем и проходим по соответствующему списку. Чтобы удалить число, мы находим его и удаляем элемент списка, его содержащий. При добавлении элементов в хеш-таблицу выделяются куски динамической памяти, которые организуются в виде связанных списков, каждый из которых соответствует входу хеш-таблицы. Этот метод называется связыванием.Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай - когда все ключи хешируются в один индекс. При этом мы работаем с одним линейным списком, который и вынуждены последовательно сканировать каждый раз, когда что-нибудь делаем. Отсюда видно, как важна хорошая хеш-функция. Оценка эффективности : n – текущее кол-во элементов, m - размер таблицы, alpha-коэф. заполненности. Alpha –дожна быть больше 0. Эффективность операций O(1+alpha).
36. Хеш – таблицы с открытой адресацией. Операции поиска, вставки и удаления в хеш - таблицу с открытой адресацией. Эффективность операций в хеш-таблицах с открытой адресацией
Хеш-таблицы с открытой адресайцией особенно эффективны, когда максимальные размеры входящего набора данных уже известены. Было доказано, что, когда таблица заполняется более чем на 50 процентов, ее эффективность значительно ухудшается(возрастает количество коллизий). Такие таблицы обычно используются для быстродействующего макетирования (они просты для программирования и быстры) и там, где быстрый доступ (нет связаного списка) приоритетен, а память легко доступна.
Хэш-таблица строится на базе динамического массива. Листинги операций даны в «псевдокоде». При вставке элемента может возникнуть ситуация, что это место в массиве занято в этом случае делается повторное хэширование и т. д. пока либо не будет найдено пустого место либо все варианты будут просмотрены. Повторение элементов не допустимо.
Эффективность операций: Эффективность поиска несуществующего элемента и опера. Включения O(1/(1-alpha)). Поиск присутствующего элемента O((1/alpha)*ln(1/ (1-alpha))). 0<alpha<=1.
37. Хеш – таблицы с открытой адресацией. Виды повторного хеширования
Описание хэш-таблиц с открытой адрессацией дано в вопросе №36.
1. Линейное повторное хэширование h2 ( k, i ) = ( h ( k ) + c * i ) % m, где 0<=i<m – номер попытки. Недостаток: уходим от O(1) к O(N).
2. Квадратичное хэширование h2 ( k, i ) = ( h ( k) + C1 * i + C2 * i ^ 2) % m
3. Двойное хэширование h ( k, i ) = ( h1 ( k ) + i * h2 ( k ) ) % m, где h1( k ) - модульное или мультипликативное, для модульного h2( k ) = k % ( m - 1 ).
Пример :
m=13 flag- пустое место

h1(k)=k%13
h2(k)=k%11
Insert ( 14 )
H0=h1(14)=14%13=1
H1=h1(14)+1*h2(14)=1+3=4
H2=h1(14)+2*h2(14)=1+2*3=7
H3=h1(14)+3*h2(14)=10
38. Структуры внешнего поиска. Хешированный файл, разреженный индекс файла, плотный индекс файла
СД используются тогда когда необходимо:
1) Большой объём хранимых данных
2) Долговременное хранение данных
Закреплённые записи – место записи менятся не может ( удаляться, перемещаться и т. д.). Незакреплённые данные – наоборот.
Hash –File – организовывается по принципу цепочной хэш-таблицы.
 Разряженный индексный файл
Разряженный индексный файл
Используется при одном условии, что файл данных отсортирован( основной ) по ключу.
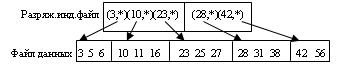 В разр. инд. файл записываются записи( ключ - начальное значение блока в файле данных + файловый указатель на начало блока). Файл данных должен быть разбит на блоки. Проиллюстрировать данную организацию можно простым примером(см. рисунок). Для использования бинарного поиска в разр. файле лучше его представить в виде массива.
В разр. инд. файл записываются записи( ключ - начальное значение блока в файле данных + файловый указатель на начало блока). Файл данных должен быть разбит на блоки. Проиллюстрировать данную организацию можно простым примером(см. рисунок). Для использования бинарного поиска в разр. файле лучше его представить в виде массива.
Плотный индексный файл
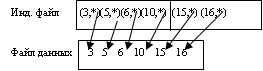 Индексный файл, который фиксирует в себе каждую запись. В сортировки файла данных не нуждается, т. к. при вставке новый элемент проосто включается в конец файла данных с возвратом файлового указателя на это место.
Индексный файл, который фиксирует в себе каждую запись. В сортировки файла данных не нуждается, т. к. при вставке новый элемент проосто включается в конец файла данных с возвратом файлового указателя на это место.
Запись в индексном файле содержит ключ + файловый указатель на позицию в файле данных. Данную структуру можно показать следущим образом:
39. Структуры внешнего поиска. Б-дерево. Эффективность операций в Б-дереве. Представление Б-дерева
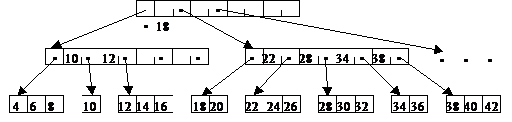 Б-деревья – сбалансированные деревья, удобные для хранения информации на дисках. Характерным для Б-деревьев является их малая высота h. Представление информации во внешней памяти в виде Б-дерева стало стандартным способом в системах баз данных. Пример: Б-дерево степени 5. В Б-дереве узел может иметь много сыновей, на практике до тысячи. Количество сыновей (максимальное) определяет степень Б-дерева.
Б-деревья – сбалансированные деревья, удобные для хранения информации на дисках. Характерным для Б-деревьев является их малая высота h. Представление информации во внешней памяти в виде Б-дерева стало стандартным способом в системах баз данных. Пример: Б-дерево степени 5. В Б-дереве узел может иметь много сыновей, на практике до тысячи. Количество сыновей (максимальное) определяет степень Б-дерева.
Узел х, хранящий n[x] ключей, имеет n[x]+1 сыновей. Хранящиеся в х ключи служат границами, разделяющими всех потомков узла на n[x]+1 групп. За каждую группу отвечает один из сыновей х. При поиске в Б-дереве искомый ключ сравнивается с границами в узле х и выбирает один из n[x]+1 путей для дальнейшего поиска.
Особенности структуры Б-дерева вытекают из особенностей обработки информации во внешней памяти. Обычно эта информация (множество) имеет весьма большой объем и насчитывает миллионы и миллиарды элементов. Хранить такой объем в ОП невозможно. При обработке в ОП хранится только часть элементов, обрабатываемых в данный момент. Общая схема обработки отдельных элементов выглядит так: 1) … 2) x←указатель на какой-либо объект
3) Disk_Read(x) 4) обработка и изменение элемента х 5) Disk_Wirte(x) 6)операции, которые только используют элемент х, но не изменяют его 7) …
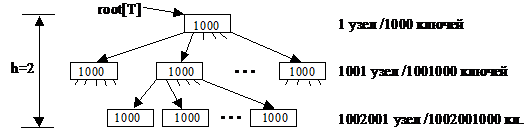 |
Вместе с элементом х считываются/записываются и смежные элементы. Поэтому узлы Б-дерева содержат не один элемент, а группу элементов размером в 1 сектор. Чтобы уменьшить количество операций чтения-записи на диск при поиске элемента в Б-дереве, нужно максимально уменьшить его высоту. Для этого степень Б-дерева делается максимальной. Типичная степень – (50-2000). Она зависит от соотношения размера сектора и размера отдельного элемента. Например, Б-дерево степени 1000 и высоты 2 может хранить более миллиарда ключей. Пример:
Узел-корень дерева обычно всегда хранится в ОП, для доступа к остальным ключам требуется всего 2 операции чтения с диска. Представление Б-дерева
Как и в других деревьях, дополнительная информация и ключи хранятся в узлах дерева. Обычно дополнительная информация представлена в виде ссылки на сектор диска, где она хранится. Вместе с ключом при его перемещении дополнительная информация перемещается вместе с ним.
В отличие от 2-3 дерева ключи и дополнительная информация размещается не только в листьях, но и во внутренних узлах дерева. Хотя возможна организация Б-деревьев, в которых дополнительная информация хранится только в листьях, а во внутренних узлах – ключи и указатели на сыновей. Это экономит память во внутренних узлах и позволяет увеличить их степень при том же размере сектора. Кроме того узел хранит:
1) n[x] – текущее количество ключей, хранящихся в узле;
2) сами ключи в неубывающем порядке key1[x] ≤ key2[x] ≤ … ≤ keyn[x][x];
3) булевский признак leaf[x] истинный, если узел – лист;
4) n[x]+1 указателей p1[x], p2[x], …, pn[x]+1[x] на сыновей. У листьев эти поля не определены.
Ключи key1[x], …, keyn[x][x] служат границами, разделяющими значения ключей в поддеревьях:
K1 ≤ key1[x] ≤ key2[x] ≤ … ≤ keyn[x][x] ≤ Kn[x]+1,
где Ki – множество ключей, хранящихся в поддереве с корнем pi[x].
Все листья находятся на одной глубине, равной высоте дерева h.
Число ключей, хранящихся в одном узле, ограничено сверху и снизу единым для Б-дерева числом t, где t – минимальная степень дерева (t≥2).
Каждый узел, кроме корня содержит минимум t-1 ключей и t сыновей. Если дерево не пусто, то в корне должен храниться хотя бы один ключ. В узле хранится не более 2t-1 ключ, и внутренний узел имеет не более 2t сыновей. Узел, хранящий 2t-1 ключей, называется полным.
Если t=2, то у каждого внутреннего узла может быть 2, 3, 4 сына и такое дерево называется 2-3-4 деревом.
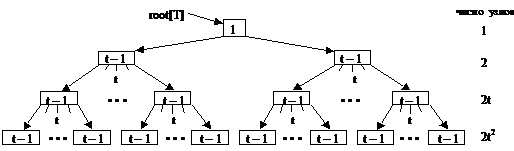
![]() Высота дерева: .
Высота дерева: .
Минимальное:
Т. е. временная сложность операций для Б-дерева оценивается как О(logt n).
40. Б-дерево. Алгоритм вставки в Б-дерево
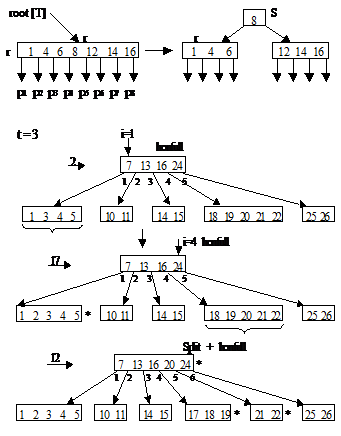 Операции при включении проходит по одному из путей поиска от корня к месту. Для этого требуется время О(th)=О(t logt n) и О(h) обращений к диску. На пути поиска встречающиеся полные узлы расщепляются с помощью операции B_Tree_Split(x, i, y)+ B_Tree_Insert (T, k); Точкой роста Б-дерева является не лист, а корень. Новый корень содержит ключ-медиану старого корня.
Операции при включении проходит по одному из путей поиска от корня к месту. Для этого требуется время О(th)=О(t logt n) и О(h) обращений к диску. На пути поиска встречающиеся полные узлы расщепляются с помощью операции B_Tree_Split(x, i, y)+ B_Tree_Insert (T, k); Точкой роста Б-дерева является не лист, а корень. Новый корень содержит ключ-медиану старого корня.
Сделав корень неполным (или он не был таковым с самого начала), мы вызываем операцию B_Tree_Insert_Nonfull (x, k), которая добавляет элемент k в поддерево с корнем в неполном узле х. Это рекурсивная операция.
41. Б-дерево. Алгоритм удаления из Б-дерева
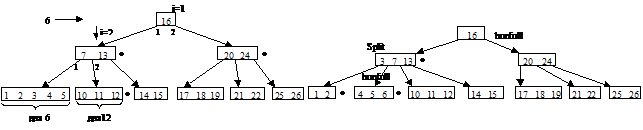 При удалении ключа их поддерева с корнем в узле х должно выполняться условие: узел х
При удалении ключа их поддерева с корнем в узле х должно выполняться условие: узел х
содержит не меньше t ключей, т. к. по правилам Б-дерева узел содержит минимум t –1 ключ. Т. е. при удалении нужно следить, чтобы в узлах на пути поиска был всегда запасной ключ. Если в результате удаления опустел корень, то корнем становится его единственный сын и высота Б-дерева уменьшается.
При удалении возможны различные случаи:
1. Если ключ k находится в узле х, являющемся листом, то k удаляется из х (рис.1).
2. Если ключ k найден во внутреннем узле х, то
a) если сын y узла х, предшествующий k, содержит не менее t ключей, то в его поддереве находится ключ k`, непосредственно предшествующий k. Этот ключ находится в листе поддерева с корнем y. Найти его можно за один просмотр поддерева от его корня к листу. Рекурсивно вызываем операцию для k`: удаляем k`, заменяем в х ключ k на k`(рис.2);
b) если сын z, следующий за k, содержит не менее t ключей, поступаем аналогично;
c) если и y и z содержат t –1 элементов, соединяем узел y, ключ k и узел z, помещая все в вершину y, которая теперь содержит 2t –1 ключей. Уничтожаем z и удаляем из x ключ k и указатель на z. Рекурсивно удаляем k из y (рис.3).
3. Если х – внутренний узел, но ключа k в нем нет, найдем среди сыновей узла х корень pi [x] поддерева, где должен лежать ключ k (если этот ключ вообще есть). Если pi [x] содержит не менее t ключей, можно рекурсивно удалить k из поддерева pi [x]. Если же pi [x] содержит всего t –1 элементов, то предварительно делаем шаги 3a или 3b:
a) пусть оба соседа узла pi [x] содержат t –1 элементов. Тогда объединим узел pi [x] с одним из соседей (как в случае 2c). При этом ключ, разделяющий их в узле х, станет ключом медианой нового узла (рис.4);
b) пусть pi [x] содержит t –1 элементов, но один из его соседей содержит по крайней мере t элементов (соседом называем такого сына узла х, который отделен от pi [x] ровно одним ключом разделителем). Тогда добавим сыну pi [x] элемент из узла х, разделяющий pi [x] и его правого соседа, а в узел х вместо него поместим самый левый ключ этого соседа. При этом самый левый сын соседа превращается в самого правого сына узла pi [x]. Аналогично поступаем для левого соседа (рис.5).
Описанный алгоритм требует возврата к уже просмотренному узлу (случаи 2a, 2b). Это происходит, когда требуется удалить элемент из внутренней вершины. К счастью большинство узлов Б-дерева – листья и эти случаи редки.
 Операция требует О(h) обращений к диску. Вычисления требуют О(th)=О(t logt n) времени. Иллюстрация:
Операция требует О(h) обращений к диску. Вычисления требуют О(th)=О(t logt n) времени. Иллюстрация:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
