
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
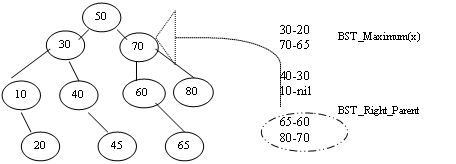
21. Бинарное дерево поиска. Алгоритм поиска К–го порядкового элемента, алгоритм разбиения дерева на два дерева
Описание бинарного дерева поиска дано в вопросе №15.
Выборка К – го значения из BST – дерева
Одной из причин распространенности BST-деревьев является эффективная поддержка операций сортировки и выбора k-го по порядку элемента. Сортировка выполняется при поперечном обходе узлов дерева. Обход сопровождается спуском по дереву, поэтому можно ожидать, что затраты определяются логарифмической зависимостью. Для операции Select k можно использовать идею, аналогичную бинарному поиску в массиве. Для отыскания в BST-дереве элемента с k-м наименьшим ключом проверяется количество узлов в левом поддереве корня. Если там имеется k узлов, то возвращается корневой элемент. В противном случае, если левое поддерево содержит более k узлов, рекурсивно отыскивается k-й элемент в левом поддереве. Если левое поддерево содержит m узлов и m<k, то k-й элемент является (k-m-1)-м наименьшим элементом в правом поддереве. В этом случае рекурсивно отыскивается (k-m-1)-й элемент в правом поддереве. Для реализации операции Select k удобно в структуру узлов BST-дерева ввести счетчик числа узлов в поддереве – n. Этот счетчик модифицируется любой операцией, изменяющей дерево(insert, delete, R, L). Это дополнение может снизить производительность операций вставки и удаления, увеличить затраты памяти. Но если операция Select k важна, то на эти затраты приходится идти. Selectk(t, k);
Разбиение BST – дерева на два дерева
 Операция заключается в спуске по дереву до требуемого узла и затем подъему по дереву с выполнением ротаций для перемещений этого узла в корень. BST_Part(t, k)+ BST_Partition(t, x)+ Selectk(t, k);
Операция заключается в спуске по дереву до требуемого узла и затем подъему по дереву с выполнением ротаций для перемещений этого узла в корень. BST_Part(t, k)+ BST_Partition(t, x)+ Selectk(t, k);
22. Бинарное дерево поиска. Алгоритм удаления элемента на основе операций разделения и объединения двух поддеревьев
Описание бинарного дерева поиска дано в вопросе №15. Еще одна модификация алгоритма удаления узла из BST-дерева использует операцию разделения дерева и объединение двух поддеревьев. BST_Remove(t, k)+ BST_JoinLR(a, b)+ BST_Part(t, k);
23. Бинарное дерево поиска. Алгоритм объединения двух деревьев
Описание бинарного дерева поиска дано в вопросе №15.
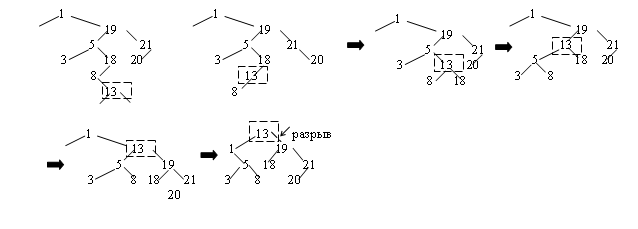
Существуют различные алгоритмы объединения деревьев. Например, можно обойти первое дерево, вставляя каждый его узел во второе дерево. В этом случае для функции обхода в качестве операции можно задать функцию вставки узла во второе BST-дерево. Время выполнения такого алгоритма нелинейно, так как для каждой вставки может потребоваться линейное время в случае вырожденного BST-дерева. Другой подход заключается в обходе обоих BST-деревьев, помещении элементов в массив и затем построении нового дерева при выборке из этого массива элементов. Время этого алгоритма может быть линейным, но требует потенциально большего массива. Можно использовать алгоритм с линейным временем выполнения и не требующим дополнительной памяти. Основан этот алгоритм на операции вставки элемента в корень дерева.
 Вначале вставляем корень первого дерева в корень второго дерева. После этой операции образуются 4 поддерева. В первом дереве это два поддерева корня, во втором дереве - это два поддерева нового корня. Для них справедливо то, что все элементы в обоих левых поддеревьях меньше элемента нового корня во втором поддереве, а все элементы в обоих правых поддеревьях больше или равны элемента в новом корне. Поэтому можно объединить два левых поддерева в левое поддерево и два правых поддерева во втором поддереве по тому же методу, то есть можно разработать рекурсивную функцию, реализующую объединение двух BST-деревьев. BST_Join(a, b)+ BST_Root_Insert; Пример :
Вначале вставляем корень первого дерева в корень второго дерева. После этой операции образуются 4 поддерева. В первом дереве это два поддерева корня, во втором дереве - это два поддерева нового корня. Для них справедливо то, что все элементы в обоих левых поддеревьях меньше элемента нового корня во втором поддереве, а все элементы в обоих правых поддеревьях больше или равны элемента в новом корне. Поэтому можно объединить два левых поддерева в левое поддерево и два правых поддерева во втором поддереве по тому же методу, то есть можно разработать рекурсивную функцию, реализующую объединение двух BST-деревьев. BST_Join(a, b)+ BST_Root_Insert; Пример :
24. Сбалансированные деревья поиска. Алгоритм балансировки бинарного дерева поиска
У BST-деревьев два основных недостатка – значительный объем дополнительной памяти для связей в дереве и возможность вырождения дерева в список. Рассмотрим способы балансировки дерева, снижающие эффект вырождения деревьев в худших случаях. Очень часто дерево формируют элементы упорядоченного файла, или файла с большим числом дублированных ключей. В этом случае построение дерева будет занимать квадратичное время, а поиск - линейное время. Можно периодично выполнять повторную балансировку дерева при его обходе. Но для слишком крупных деревьев выполнять ее часто не желательно. BST_Balance(t); Такая балансировка не гарантирует против квадратичной зависимости для худшего случая между повторными балансировками – к тому же сама балансировка, по меньшей мере, имеет линейную зависимость. Поэтому более распространены методы локальной балансировки, сопровождающие включение и удаление элементов из BST-дерева. В идеально сбалансированном дереве поиск занимает О(log n) время, а построение дерева – О(n*log n) времени. Но поддержание идеально сбалансированного дерева при включении новых элементов требует больших затрат, поэтому при балансировке используются более мягкие критерии. Если внешние узлы дерева расположены на одном, в крайнем случае, двух нижних уровнях, то обеспечивается достаточно высокая производительность. Существует много BST-деревьев, эффективных по производительности, высота которых ограничена величиной 2*log n. Один из методов балансировки – построение рандомизированных BST-деревьев.
При построении рандомизированного дерева основное исходное положение заключается в том, что любой элемент может с одинаковой вероятностью быть корнем BST-дерева. Причем это справедливо и для поддеревьев BST-дерева.
25. Рандомизированное дерево поиска. Алгоритм вставки элементов, эффективность поиска в рандомизированном дереве
Один из методов балансировки BST-деревьев – построение рандомизированных BST-деревьев.
При построении рандомизированного дерева основное исходное положение заключается в том, что любой элемент может с одинаковой вероятностью быть корнем BST-дерева. Причем это справедливо и для поддеревьев BST-дерева.
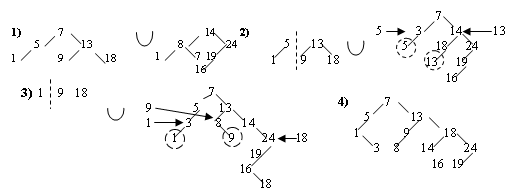
Поэтому введем случайность в алгоритм включения в BST-дерево, а именно для нового элемента случайным образом выбирается метод включения элемента в качестве листа, или в качестве корня. Вероятность появления нового узла в корне определяется как 1/(n+1), где n – число узлов в дереве. Random_BST_Insert(t,x); Например, формирование рандомизированного дерева для возрастающей последовательности ключей может выглядеть так.:
![]() В корень в корень
В корень в корень
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
3 3 5
в корень в корень в корень
1 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 8
8
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
7
То есть дерево выглядит так, будто элементы поступали в случайном порядке. Поскольку принимаемые алгоритмом решения являются случайными, то при каждом выполнении алгоритма при одной и то же последовательности включений будут получатся деревья различной конфигурации. Таким образом, несмотря на увеличение трудоемкости операции включений, за счет рандомизации получается структура дерева, близкая к сбалансированной. Поиск в рандомизированном дереве ведется по стандартному алгоритму поиска в BST-дереве. Благодаря сбалансированности дерева в среднем поиск в рандомизированном дереве оценивается О(log n) и более эффективен в среднем, чем в BST-дереве. Недостатком рандомизированной вставки являются затраты на генерацию случайных чисел в каждом узле. Чтобы минимизировать эти затраты, можно вместо системного генератора случайных чисел использовать числа, которые не являются совершенно случайными, но для генерации требуют небольших затрат. Например, функцию rand() можно заменить проверкой 111% n[t]=3 для принятия решения о вставке в корень. Второй недостаток – необходимость поддержки в узлах параметра n[t], количество узлов в поддеревьях узла. Но если этот параметр необходим в дереве и по другим причинам, например, для операции Select(). То поддержка этого параметра для рандомизированной вставки не является решающим недостатком.
26. Рандомизированное дерево поиска. Алгоритм объединения двух рандомизированных деревьев поиска
Описание рандомизированного дерева поиска см. в вопросе №25. Принцип рандомизации касается не только операции включения, но и операции объединения двух деревьев и операции удаления. Для объединения дерева из N узлов с деревом из M узлов используется базовый метод, за исключением принятия рандомизированного решения о выборе корня. Решение исходит из того, что корень объединенного корня выбирается из N-узлового дерева с вероятностью N(M+N), а из M-узлового дерева – с вероятностью M/(M+N). Random_BST_Join(a, b); В функцию BST_Join нужно вставить обновление параметра n[t], которое в объединенном дереве равно сумме параметров n[t] объединенных деревьев+1. BST_Join(a, b);
СБАЛАНСИРОВАННЫЕ ДЕРЕВЬЯ
Анализ среднего пути доказывает, что в среднем высота дерева пропорциональна О(log n). Но малая высота не гарантируется и в худших случаях деревья не более эффективны, чем списки, то есть имеют высоту О(n).
Если худший случай недопустим, то используются специальные методы, предотвращающие вырождение дерева в список при вставке или удалении элементов из дерева. Применяются методы балансировки деревьев путем вращений. Деревья, использующие балансировку, называются сбалансированными деревьями. К этому классу относятся АВЛ-деревья, красно-черные деревья. 2-3 деревья и Б-деревья обеспечивают баланс за счет изменения степеней вершин. Рассмотрим эти методы.
27. АВЛ – дерево поиска. Алгоритм вставки элементов, эффективность операций в АВЛ-дереве
Алгоритм построения сбалансированного дерева был предложен Адельсоном-Вельским и Ландисом в 1962 г. Дается следующее определение сбалансированности дерева:
Дерево является сбалансированным тогда и только тогда, когда для каждого узла высота его двух поддеревьев различается не более чем на 1.Рассмотрим операцию включения в сбалансированное дерево нового узла. Пусть дан корень a с левым и правым поддеревьями L и R. Предположим, что новый узел включается в L, вызывая увеличение его высоты на 1. Возможны 3 случая после включения.
1) Если hl=hr до включения, то L и R становятся неравной высоты, но критерий сбалансированности не нарушен.
2) Если hl<hr до включения, то L и R становятся равной высоты и сбалансированность даже улучшается.
3) Если hl>hr до включения, то критерий сбалансированности нарушается и дерево нужно перестраивать.
ВКЛЮЧЕНИЕ В АВЛ-ДЕРЕВО

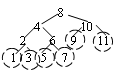 В дерево на рисунке узлы с ключами 9 и 11 можно вставить без балансировки. Включение 9 ухудшает сбалансированность поддерева с корнем 10, но не нарушает критерий сбалансированности (случай 1). В поддереве с корнем 8 сбалансированность даже улучшается (случай ). Но включение узлов 1, 3, 5 или 7 требует балансировки в поддереве с корнем 8. Рассмотрим случаи нарушения сбалансированности:
В дерево на рисунке узлы с ключами 9 и 11 можно вставить без балансировки. Включение 9 ухудшает сбалансированность поддерева с корнем 10, но не нарушает критерий сбалансированности (случай 1). В поддереве с корнем 8 сбалансированность даже улучшается (случай ). Но включение узлов 1, 3, 5 или 7 требует балансировки в поддереве с корнем 8. Рассмотрим случаи нарушения сбалансированности:
Случай 1возникает при включении узла 3 и 1, случай 2 – при включении узла 5 и 7.
Простые преобразования этих двух структур восстанавливают сбалансированность.
Возможны лишь перемещения по вертикали узлов и поддеревьев. Их относительное горизонтальное расположение остается неизменным. Это обеспечивает сохранение упорядоченности узлов в перестроенном дереве. Для контроля сбалансированности в структуру узлов вводится дополнительное поле с показателем сбалансированности bal. bal=hr-hl. В общих чертах процесс включения узла в сбалансированное дерево состоит из трех этапов:
1 Поиск места включения нового узла в каком – либо листе.
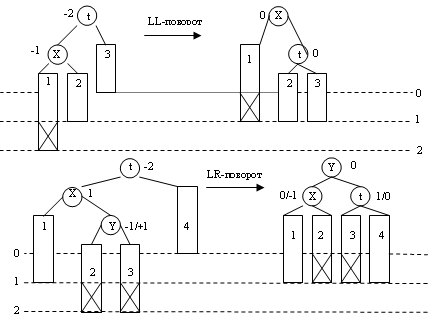 2 Включение нового узла и определение нового показателя сбалансированности в месте включения.
2 Включение нового узла и определение нового показателя сбалансированности в месте включения.
3 Обратный проход по пути включения и проверка сбалансированности у каждого узла на этом пути.
LL_Rotate(t); LR_Rotate(t);
Bal_Tree_Insert(t, x,&h);
Пример включения в сбалансированное дерево(ниже):
 Математический анализ этого алгоритма сложен. Эмпирические проверки этого алгоритма показывают, что ожидаемая высота сбалансированного дерева равна h=log(n)+c (c=0.25). То есть АВЛ - деревья ведут себя как идеально сбалансированные полные деревья. Балансировка необходима приблизительно 1 раз на два включения и однократный и двукратный повороты равновероятны. Из-за сложности операций балансировки АВЛ – деревья рекомендуется использовать в случае, если число операций поиска значительно превышает число операций включения и удаления.
Математический анализ этого алгоритма сложен. Эмпирические проверки этого алгоритма показывают, что ожидаемая высота сбалансированного дерева равна h=log(n)+c (c=0.25). То есть АВЛ - деревья ведут себя как идеально сбалансированные полные деревья. Балансировка необходима приблизительно 1 раз на два включения и однократный и двукратный повороты равновероятны. Из-за сложности операций балансировки АВЛ – деревья рекомендуется использовать в случае, если число операций поиска значительно превышает число операций включения и удаления.
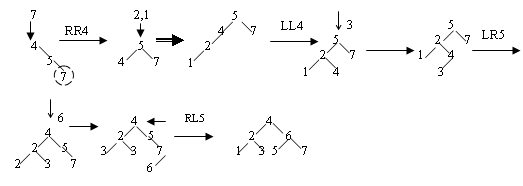
28. АВЛ – дерево поиска. Алгоритм удаления элементов, эффективность операций в АВЛ-дереве
При удалении узлов из АВЛ – дерева операция балансировки в основном остается такой же, что и при включении и заключается в однократном или двукратном повороте. При этом булевская переменная h, возвращаемая операцией удаления означает уменьшение высоты поддерева. Пример:
![]()
![]() R поворот 3
R поворот 3
5 5
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 0
0
1
![]()
![]()
![]()
![]()
![]() L поворот 7
L поворот 7
![]()
![]() 5 5 3
5 5 3
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 9
9
 |
![]()
![]()
![]() RL3 поворот L 3
RL3 поворот L 3
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 7 7 10
7 7 10
![]()
![]()
![]() 3
3
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Удаление элементов также имеет стоимость О(log n). Но если включение может вызвать один поворот, удаление может потребовать повороты в каждом узле пути поиска при обратном ходе рекурсии. Но эмпирические проверки показали, что если при включении выполняется один поворот на каждые два включения, то при удалении один поворот приходится на 5 удалений.
29. 2 – 3-дерево поиска. Алгоритм вставки элементов, 2 – 3-дерево. Алгоритм вставки элементов, эффективность операций в 2-3-дереве
Предложены Хопкрофтом в 1973 г.
В 2-3 дереве
1) Каждый внутренний узел имеет 2 или 3 сына.
2) Все пути от корня до любого листа имеют одинаковую длину.
3) Элементы располагаются в листьях 2-3 дерева.
4) В каждый внутренний узел записывается ключ наименьшего элемента, являющегося потомком второго сына и ключ наименьшего элемента, - потомка третьего сына, если третий сын есть.
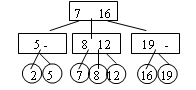 k-1 k-1
k-1 k-1
2-3 дерево с k уровнями имеет от 2 до 3 листьев, то есть 2-3 дерево, содержащее n элементов, имеет высоту не менее 1+log3 n и не более 1+log2 n. Таким образом высота дерева имеет порядок О(log n).
Элемент можно найти за время О(log n), сравнивая ключ искомого элемента с параметрами в узлах. Если ключ меньше, чем минимальный элемент у второго сына, то выбирается первый сын. Иначе, если узел имеет двух сыновей, выбирается второй сын. Если есть третий сын, то выбирается второй сын, если ключ меньше минимального ключа третьего сына, или третий сын в противном случае. Таким образом поиск приводит к листу с искомым ключом.
ВКЛЮЧЕНИЕ ЭЛЕМЕНТА В 2-3 ДЕРЕВО
Включение нового элемента начинается так же, как и процесс поиска. Пусть мы находимся в некотором внутреннем узле x, чьи сыновья – листья и не содержат элемента с заданным ключом k. Если узел содержит двух сыновей, то новый элемент подключается к этому узлу в качестве третьего сына. Новый элемент помещается так, чтобы не нарушить упорядоченность сыновей. После этого корректируются значения минимальных ключей в узле x. Например, включаем элемент с ключом 18. При поиске мы приходим к самому правому узлу на среднем уровне. Помещаем 18 среди сыновей этого узла в порядке 16, 18, 19. В узле записываются значения 18 и 19.
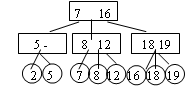 Если при подключении к узлу новый элемент является четвертым, то узел x разбивается на 2 узла x и x’. Два наименьших элемента переносятся в узел x, а два наибольших – в x’. Теперь надо вставить узел x’ среди сыновей родителя узла x. Здесь ситуация повторяется. Если родитель имеет двух сыновей, то узел x’ становится третьим сыном. Если родитель имеет трех сыновей, то он в свою очередь разбивается на два узла. Процесс идет в случае необходимости выше и может достигнуть корня дерева. При необходимости разбиения корня создается новый корень, сыновьями которого становятся два узла, получившиеся при разбиении старого корня.
Если при подключении к узлу новый элемент является четвертым, то узел x разбивается на 2 узла x и x’. Два наименьших элемента переносятся в узел x, а два наибольших – в x’. Теперь надо вставить узел x’ среди сыновей родителя узла x. Здесь ситуация повторяется. Если родитель имеет двух сыновей, то узел x’ становится третьим сыном. Если родитель имеет трех сыновей, то он в свою очередь разбивается на два узла. Процесс идет в случае необходимости выше и может достигнуть корня дерева. При необходимости разбиения корня создается новый корень, сыновьями которого становятся два узла, получившиеся при разбиении старого корня.
Пусть мы вставляем элемент m с ключом 10. Выбранный узел до подключения имеет трех сыновей, поэтому он разбивается на два новых узла.

![]()
![]()
![]() 7 16
7 16

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
