
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Стохастические грамматики с отсечением
Предложена модель стохастической грамматики, явно учитывающая финитность естественно-языковых конструкций. Показано отличие основанных на ней выводов и оценок от выводов и оценок, полученных в традиционной модели. В частности, продемонстрирована применимость предложенной модели в случае неприменимости традиционной. Рассмотрена проблема выбора вариантов отсечения. Сформулированы задачи оценивания параметров модели, в том числе уровней отсечения.
Соглашение об обозначениях
Ниже используются общепринятые обозначения для контекстно-свободной грамматики (КСГ): G=<VN, VT, P, S>, где VT – алфавит основных (терминальных), а VN – вспомогательных (нетерминальных) символов, S Î VN – начальный символ, с которого начинается порождение, P – набор правил порождения. Символы из VN обозначаются заглавными, из VT – строчными буквами, как впрочем, и смешанные строки. Правила подстановки будем также называть продукциями, а выражения в их левых частях – посылками. Языком L(G), порождаемым грамматикой G, называется множество всех конечных строк из символов VT, выводимых в грамматике G. Наконец, НФХ – нормальная форма Хомского (для КСГ), СКСГ и СНФХ – стохастические КСГ и НФХ. При прочих терминологических затруднениях, касающихся грамматик, обратитесь к [3] или [1], касающихся N-грамм – к [1].
Психолингвистические предпосылки грамматик с отсечением
Лингвистическая критика формальных грамматик обычно состоит в предъявлении очередных примеров неприменимости КСГ к разбору каких-либо конструкций естественного языка. В этом отношении типична работа [7], где перечислены конструкции швейцарского немецкого, не покрываемые правилами КСГ, и не без иронии сообщается, что неадекватность КСГ еще не есть свидетельство адекватности грамматики непосредственных составляющих. Но в любом варианте собственно лингвистической критики с позиций разбора не могут возникнуть претензии к его глубине – не в смысле глубины мысли, а в смысле способности разобрать сколь угодно вложенную конструкцию. Здесь потенциальная бесконечнось уровней (цепочки вывода) нисколько не недостаток модели, а скорее проявление ее общности. Действительно, нет ничего дурного, если грамматика, позволяя разобрать реальное, а стало быть конечное (и очень конечно-уровневое) предложение, заодно справится с разбором актуально бесконечного.
Совершенно иначе обстоит с задачей порождения, а именно с ней мы имеем дело, оценивая вероятностные характеристики порождаемого грамматикой языка. Необоримая плодовитость порождающих грамматик имеет очень мало общего и с естественным языком и с мышлением его носителей.
Остановимся на последней, психолингвистической стороне проблемы. Психолингвистика вместо задачи разбора рассматривает задачу описания понимания/восприятия. В экспериментах Шлесинджера [6] от испытуемых требовалось понять смысл предложений типа «Вот кот, который синицу, которая пшеницу, которая хранится, ворует, пугает и ловит.» Оказалось, что такие вложенные конструкции, как правило, становятся доступны для понимания только после перевода из линейной естественно-языковой формы в структурированное, в сущности, формально-грамматическое, представление. Лучший способ понять такую фразу – нарисовав ее дерево. В других терминах и в более общем виде, скажем, что Шлесинджер наблюдал проявление двух свойств. Первое, одно и то же знание может быть без искажений представлено по-разному, в частности, на разных языках или различными высказываниями на одном и том же языке. Второе, сложность восприятия разных представлений одного знания различна. Иначе, собственно, не появились и не прижились бы формы представления, отличные от описания на естественном языке. Действительно, рисунок многосвязного объекта понятнее фразы, описывающей его многосвязность, а предложение «Вот кот, который пугает и ловит синицу, которая часто ворует пшеницу, которая в темном чулане хранится в доме, который построил Джек.» понятнее исходного.
Тема меры сложности представления (восприятия) чрезвычайно интересна, однако ограничимся констатацией, что далеко не все высказывания, представимые формальной грамматикой и структурно допустимые в естественном языке, могут в нем встретиться. Причина – в ограниченности уровня восприятия/понимания текста. Вложенности выше какого-то уровня уже просто не воспринимаются даже если предложение вполне грамматически корректно (последнее вряд ли относится к экспериментам Шлесинджера).
Парадокс СКСГ
Приведем пример из [8]. Дана СНФХ Gs* с правилами:
S ® z | (с вероятностью p) |
S ® SS | (с вероятностью 1–p) |
Нужно вычислить математическое ожидание для униграммы z:
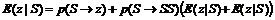
или
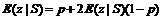
То есть
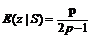
При p<0,5 получаем отрицательное величину, а при p=0,5 соответственно –¥ слева и +¥ справа. Что вполне согласуется с условием согласованности грамматики ([1],[3],[5]). Приведенный пример любим Штольке [8] и достаточно регулярно воспроизводится им в качестве наглядного доказательства мощи условия согласованности СКСГ и предостережения от использования СКСГ, не удовлетворяющих этому условию.
Грамматики с отсечением
Грамматикой с отсечением назовем грамматику с неважно как заданным ограничением на глубину вывода. Форма ограничения действительно не имеет значения для свойств грамматики и порождаемого ею языка. Важно же то, что при отсечении конечны и процесс порождения (дерево вывода) и порождаемый язык. Для стохастической грамматики переход от вероятностной меры грамматики к выроятностной мере языка производится очевидным образом – умножением вероятности каждой строки языка на величину, обратную сумме вероятностей всех строк.
Отказ при изучении естественно-языковых структур от СКСГ в пользу СКСГ с отсечением полезен во всех отношениях. Во-первых, в отличие от замены КСГ на СКСГ, это действительно подвижка к реализму. Во-вторых, это снятие проблемы, состоящей в том, что задача об эквивалентности двух произвольных КСГ в общем случае неразрешима. Конечные языки, какими являются языки грамматик с отсечением, можно по крайней мере задать перичислением и тем самым сравнить непосредственно. В-третьих, исключаются псевдопарадоксы, проистекающие исключительно из-за того, что модели естественного языка вменяются свойства бесконечного вероятностного процесса.
Если язык такой грамматики задан простым перечислением, то отпадает задача определения по данной (терминальной) строке, выводима ли она в данной грамматике. Задача оценивания параметров модели принимает новые формы. Теперь в число оцениваемых параметров могут быть включены и параметры, определяющие уровень отсечения. Кроме того, с учетом конечноуровневости дерева вывода ничто не мешает как аккуратно проверить гипотезу о постоянстве вероятностных весов, так и сделать их (более) свободными параметрами единственно с ограничением на сумму вероятностей продукций, имеющих одну посылку.
Пример с простой фразой
Хотя правила подстановки из примера Штольке [8] трудно отнести к высказываниям на естественном-языке, тем не менее этот пример воспринимается как издевательство над неявным, но неоспоримо истинным знанием. Формальный результат всецело противоречит нашему естественно-языковому опыту. Означать это может только одно – формальный объект (каковым в данном случае оказался ветвящийся процесс – [4]) не есть модель реального – естественного языка. Заметим, что по самому построению грамматики с отсечением, вероятность униграммы z для примера [8] равна 1, поскольку никаких других терминальных символов не используется.
Ниже рассматривается отчасти дидактический пример. целей Поскольку СКСГ – плод борьбы за больший реализм Потому выводы о вероятностях порождения строк, полученные в рамках формализма стохастических грамматик, заслуживают по меньшей мере скептического отношения.
Рассмотрим вполне реалистичный класс фраз русского языка, имеющих структуру
<прилагательное – ед. число, муж. род>n <существительное– ед. число, муж. род> <глагол – ед. число, прошедшее время, муж. род>
Примеры таких фраз: «Кот мяукнул», «Рыжий кот вскочил», «Жирный рыжий кот урчал», «Пушистый жирный рыжий кот завизжал» или «Окрыленный кровососущий гнус воспарил».
Замечание. Вряд ли нам удастся довести число прилагательных до четырех. Фразы обычно рассчитаны на понимание. И недопустимость одноуровневой конструкции с большим числом прилагательных вызвана не в последнюю очередь этим. Осутствие запятых побуждает человек помнить всю незавершенную цепочку из прилагательных. Если же явно указать на перечисление, разделив прилагательные запятыми, то, похоже читатель чувствует, что для понимания достаточно помнить последнее в ряду и тогда восприятие фразы «пушистый, жирный, мерзкий, …,прелестный, тощий, облезлый рыжий кот» никакого дискомфорта не вызовет, правда и ее противоречивость замечена не будет. (Собственно, чудесное свойство эксплицитного указания на перечисление позволяет легко воспринимать предложения длиной в абзац, а еще вернее – во много строф.) Фразы AA…An, где n=<существительное>, а A=<прилагательное с теми же атрибутами > и A’A’…A’n, где n=<существительное>, а A’=<прилагательное с теми же атрибутами ><запятая>, порождаются приводимыми друг к другу грамматиками. Поэтому по виду правила подстановки, к сожалению, нельзя сказать о “максимально допустимом” числе его применений (подряд) в одном выводе.
Формальная грамматика, описывающая такие фразы – это автоматная грамматика G = (VN, VT, P, S), где VN = {S, Q}, VT = { a =<произвольные прилагательные ед. числа, муж. рода>, n = <произвольные существительные ед. числа, муж. рода>, v = <произвольные глаголы ед. числа, прошедшего времени, муж. рода >} и правила P:
S ® ahnQ
Q ® aQ
Q ® hn
Грамматика G позволяет разобрать все фразы из описанного класса, в том числе заведомо несуществующие – с обилием прилагательных. Реализация языка, порождаемого грамматикой G, в рамках естественного языка гораздо беднее его возможностей приписывать прилагательные.
Построим стохастический аналог G – грамматику Gs, отличающуюся от G лишь наличием вероятностных весов p и 1–p при правилах
Q ® aQ | (p) |
Q ® hn | (1–p) |
Сформулируем две задачи:
(1) по p оценить вероятности появления N-грамм, построенных на алфавите {a, h, n};
(2) по выборке из фраз описанного класса оценить p.
Первая задача связана с порождением строк языка L(Gs), вторая – с их разбором. Начнем с задачи (1).
Вероятность получить в грамматике Gs строку w=anhv (где an = aan-1 – конкатенация строк a и an-1, a0 = l – пустая строка) равна P(anhv)=pn(1-p). Подсчитаем математическое ожидание числа биграмм в языке L(Gs), то есть множестве всех строк, генерируемом грамматикой Gs.
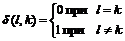
В любой строке имеется ровно одна биграмма hn, (n-1) биграмма aa (где n>0) и d(n,0) биграмм ah, где
Тогда математические ожидания биграмм в языке L(Gs):
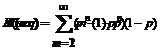
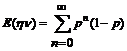
Вероятность биграммы p(биграмма) = E(биграмма)/S, где
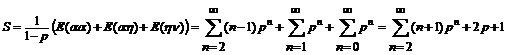
откуда
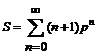
или
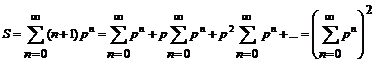
Но
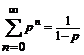
Таким образом,
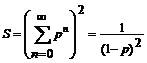
Теперь вычислим числители в формулах для вероятностей биграмм p(биграмма) = E(биграмма)/S.
Для p(aa) числитель равен
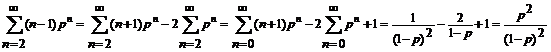
Воспользовавшись формулой для S, имеем
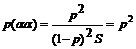
Опустив вычисления для p(ah) и p(hn), сразу запишем итоговые вероятности биграмм
Эти формулы соответствуют языку L(Gs), то есть всему бесконечному дереву выводов грамматики Gs. Теперь предположим, что на язык L(Gs) наложены ограничения. Простейшее из них – ограничение на число уровней вывода. На рис. 1 изображено дерево вывода для Gs, обрубленное по k=4-му уровню. То есть ветка, которая с вероятностью pk вела на продолжение бесконечного порождения терминальных строк, обрублена. В результате пропорции “вероятностей” выведенных терминальных строк anhv (n<k) – те же, что в языке L(Gs), но сумма их вероятностей равна 1– pk . Коль скоро теперь язык L(Gs)={ anhv, где n<k}, то, пронормировав эти вероятности с коэффициентом (1– pk)–1, получим вероятностную меру на L(Gs).
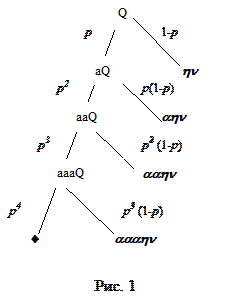 |
Вычислим вероятности терминальных строк в грамматике Gs с отсечением по k-му ярусу дерева вывода. Обозначив p(w, k) вероятность получить строку w в грамматике Gs с отсечением по k-му ярусу, можно записать
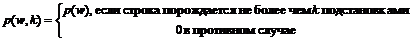
Обозначим
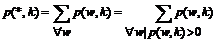
В грамматике с отсечением вероятность порождения строки w равна
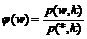
По построению
Для 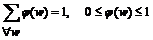
рассматриваемого примера
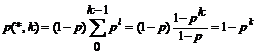
Для рассматриваемой грамматики за l+1 шаг выводится ровно одна строка, поэтому можно обозначить ее wl. Тогда для выводимых не более чем за k шагов строк имеем
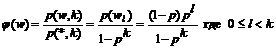
Подсчитаем распределение биграмм на множестве строк, выводимых не более чем за k шагов.
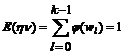
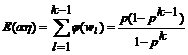
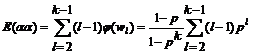
Тогда
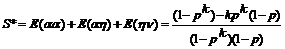
В результате имеем
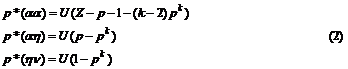
где
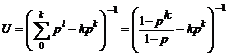
и
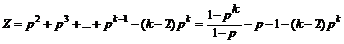
Нетрудно положить какое-то p и сравнить вероятности биграмм, полученные по (1) и (2). Даже при k=4 разница будет очень заметна в смысле завышения в (1) вероятности биграммы aa. Соответственно, будут смещены и выборочные оценки этих вероятностей.
Циклы вывода в контекстно-свободных грамматиках
Введем понятие матрицы выводимости E(G) для грамматики G (для краткости вместо E(G) будем писать E). Итак, E(G) – матрица размерности n´n, где n – число нетерминалов грамматики G. Элемент Eij отличен от нуля тогда и только тогда, когда существует правило, в левой части которого стоит Ai, а в правой содержится Aj. Ненулевые элементы Eij формируются в зависимости от того, стохастическая грамматика G или нет. Если G – не стохастическая, то отличные от нуля элементы равны 1. Если G – стохастическая, то Eij равен математическому ожиданию числа нетерминалов Aj в строках, непосредственно выводимых по Ai-правилам. В случае стохастической КСГ одновременно с матрицей математических ожиданий E полезно рассматривать матрицу выводимости несущей грамматики (обозначим эту матрицу M), позволяющую вычислить, например, число цепочек вывода какой-то длины. Обратим внимание на очевидную связь матрицы выводимости с матрицей смежности или матрицей переходных вероятностей. Кстати, условием согласованности СКСГ является Et®0 (где 0 – нулевая матрица) при t®¥, или ограничение на спектральный радиус матрицы E: |r|<1 [5, 1].
Рассмотрим транзитивное замыкание M+ матрицы выводимости M (или, в данном случае не важно, E). С помощью M+ легко устранить из КСГ бесполезные символы и правила, то есть символы и правила, не встречающиеся ни в одной из цепочек вывода, порождаемых данной грамматикой. Полагая A1=S, просмотрим элементы M+1j. Если M+1j = 0, (j =2,…,n) то нетерминал Aj не входит не в одну из цепочек вывода S Þ …Aj…, то есть является бесполезным нетерминалом. Выкинем такие Aj из VN, а правила, в которых они встречаются в левой или правой части – из P. И наконец, выкинем из VT все терминалы, отсутствующие в оставшихся правилах. Ниже будем считать, что в рассматриваемых грамматиках (уже) нет бесполезных символов и правил.
Если в M+ нет ненулевых диагональных элементов M+ii для i £ n, то не существует такой последовательности выводов, в которой хотя бы одно правило использовалось бы более одного раза. Понятно, что набор правил, которым соответствует такая M, можно свернуть в одноуровневое представление – набор из правил вида S®t, где t Î V+T (то есть t – цепочка терминальных сиволов), а VN = {S}.
Рассмотрим последовательно матрицы M1, M2, … Mk, … Mn (k=1…n) и построим на VN множества циклически повторяющихся цепочек выводов длины k. То, что Mkij>0, означает существование цепочки из k правил, начинающейся посылкой Ai и заканчивающейся правилом, в правой части которого присутствует Aj. Поэтому Mkii>0 означает, что существует циклический вывод Ai Þ …Ai… длиной k. Этот цикл образуют правила, посылками которых являются нетерминалы {Aj | Mkjj>0 и Mk-1ij>0 при Mkii>0}. Цикл повторяется с периодом k. Цикл C(k) с периодом k одновременно является и циклом с периодами, кратными k. В частности, если есть цикл с периодом 1 (то есть в КСГ есть правила непосредственного самопорождения вида Ai ® …Ai…), то этот цикл будет присутствовать среди циклов с любым периодом.
Легко доказать, что если нетерминал Ai входит в циклы с периодами k1, k2,… km, то он входит и в циклы с периодами Sniki, где ni³0 и Sni>0.
Введем понятия непроизводного и производного цикла, разложения цикла и базиса разложения. Запишем перечисление цикла C(k), имеющего период k, “без замыкания”, то есть не в форме {A1, A2, A3, …, Ak, Ak+1} (где Ai Î VN и A1 = Ak+1), а в форме {A1, A2, A3, …, Ak}. Тогда если в перечислении цикла C(k)={A1, A2, A3, …, Ak} все символы различны, цикл называется непроизводным. Иначе цикл C(k) называется производным. Производный цикл разлагается на циклы меньшего периода. Базисом разложения в нетерминале Ai называется совокупность неразложимых циклов, содержащих этот нетерминал. Одновременно с разложением по циклам будем говорить о разложении по периодам и, соответственно, о базисе периодов.
Допустим, для нетерминала Aj известен какой-то базис – содержащие Aj неразложимые циклы с периодами ki (i=1,…,b)соответственно. Тогда число V(K) различных разложимых циклов (разложений) с периодом K в этом базисе равно
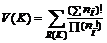
где R(K) – множество целочисленных неотрицательных векторов n=(n1, n2, …, nb), таких, что
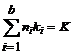
( ni – натуральные числа).
То есть любой вектор n – это целочисленное разложение числа K по базису, образуемому числами ki. Это разложение периода K по образующим базис периодам ki.
А число перестановок базисных циклов внутри каждого разложения по периодам равно
![]()
О базисных периодах ki мы не сказали ничего кроме того, что они соответствуют неразложимым циклам. Однако понятно, что нетерминал может входить в несколько неразложимых циклов с одинаковым периодом.
Например, для грамматики с правилами
A1 ® A2 | A1 ® A3 |
A2 ® A1 | A3 ® A1 |
матирицы Mk имеют вид
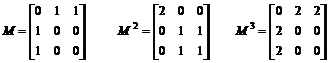
и для A1 число неразложимых циклов с периодом 2 равно 2 (а число любых циклов с периодами 1 и 3 – нулю).
Когда нетерминал входит в ti>1 неразложимых циклов одного периода ki, в базис внесем только одно значение ki. Но при этом будем иметь в виду, что ему соответствует различных циклов, то есть любому вхождению ki в разложение производного цикла может соответствовать ti различных циклов периода ki. Тогда формула для V(K) примет вид
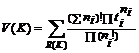
Заметим, что Mkii– общее число разложимых и неразложимых циклов с периодом k, содержащих нетерминал Ai. Последовательно анализируя матрицы M1, M2, … Mk, … Mn, получим для каждого Ai полный базис из всех неразложимых циклов.
Пример. Задана КСГ с правилами
A1 ® a1A1a2 | A1 ® A2a3 | A1 ® A3a4 | A2 ® a5A1 | A2 ® a6a7A3 | A3 ® A1a9a10 |
(где AiÎVN, aiÎVT)
Этой грамматике соответствует матрица выводимости
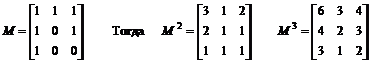
Из M видно, что для нетерминала A1 имеется один (неразложимый) цикл с периодом 1 – С(A1,1)={A1}. Включаем период 1 в базис. Далее, С(A1,2) – число циклов с периодом 2, содержащих A1, равно 3. Поскольку 2 разлагается на текущий базис однозначно (2=1+1), один из 3 циклов – производный от С(A1,1). Остальные два – непроизводные с периодом 2. Включаем период 2 в базис и учитываем, что базисных циклов с таким периодом два. Общее число циклов С(A1,3) с периодом 3 равно 6. Поскольку 3=1+1+1=2+1=1+2, число разложений (сумм) по периодам равно 3. Так как периоду 2 соответствуют два базисных цикла, то каждая из сумм 2+1 и 1+2 дают по 21=2 варианта разложения по циклам. Итого число разложений по циклам текущего базиса равно 1+2´2 = 5. То есть в A1 существует один неразложимый цикл с периодом 3. Таким образом, полный базис разложения в A1 состоит из периодов 1 (один цикл), 2 (два цикла) и 3 (один цикл). В предыдущем примере базис в A1 состоял из двух циклов с периодом 2.
Нормальная форма Хомского для СКСГ. Уровни вывода и вероятности
Известный факт теории формальных грамматик – для любой КСГ существует эквивалентная ей (то есть порождающая тот же язык) грамматика в одной из нормальных форм – Грейбах или Хомского (НФХ). Мы будем пользоваться последней. Напомним, правила подстановки в НФХ исчерпываются двумя видами:
A ® BC | (Хом1) |
или | |
A ® t | (Хом2) |
где A, B, C Î VN, а tÎVT.
В прикладных исследованиях КСГ задается как описание содержательных зависимостей, которые редко непосредственно представимы в нормализованном виде. Поэтому рассмотрим алгоритм приведения КСГ к НФХ с двух точек зрения – изменения при этом преобразовании числа уровней вывода и вероятностей (случай стохастической грамматики).
Если исходная КСГ отличается от эквивалентной ей НФХ, то измененным набором правил P’ и дополненным алфавитом нетерминалов – V’N. Обозначив нетерминалы НФХ штрихом, изложим алгоритм приведения КСГ к НФХ, предположив, что исходный набор правил не содержит избыточных правил вида A ® B, где B –нетерминал.
0-0. Перенесем в V’T все символы V’T и назначим начальным значением P’ и V’N пустое множество. Счетчик r правил из P’ приравнивается нулю.
0-1. Определим операцию пополнения набора правил как следующую процедуру. Берется правая часть x подлежащего внесению правила и проверяется, нет ли уже в P’ правила с такой же правой частью. Если такого правила нет, то на 1 увеличивается счетчик правил r, в V’N вносится новый нетерминал Ar, к списку правил P’ приписывается правило Ar ® x и в качестве результата возвращается “созданный” нетерминал Ar. Если же правило с такой же правой чавстью уже есть, то набор P’ остается без изменений, а в качестве результата выполнения процедуры возвращается нетерминал Ar из левой части найденного в P’ правила Ar ® x.
0-2. Начнем просмотр исходных правил из P.
1. Если очередное исходное правило задано в одном из двух форматов НФХ, то оно без изменений переносится в P’, а счетчик r увеличивается на 1.
2. Иначе строка b Î V+ из правой части продукции Ai®b содержит, с учетом предположения об отсутствии избыточных правил, не менее двух символов и отлична от (Хом1). Исключим из строки терминалы, заменяя каждый терминал g ннетерминалом. Именно, просмотрим строку b и встретив очередной терминал g, во-первых, пополним (согласно процедуре 0-1) набор правил P’ правилом, имеющим правой частью g, а во-вторых, заменим g в строке b на результат пополнения.
3. Теперь строка b из правой части исходного правила не содержит терминалов, а ее длина |b| ³ 2. Выполним итеративную процедуру бинаризации строки b, состоящую в представлении b =Q1Q2 Q3 …Qk (где все Qi Î VN) в виде двоичной цепочки R1 ® R2R3, R3 ® R4R5, R5 ® R6R7,… или R1 ® R2R3, R2 ® R4R5, R4 ® R6R7,… (то есть лево - или правосторонней двоичной развертки исходной строки). Процедура в сущности состоит в производимой слева-направо или справа-налево расстановке скобок в исходной строке: (((Q1Q2) Q3) Q3) …Qk) или (Q1(Q2 …( Qk-2 (Qk-1Qk))). Ничто не мешает расставить бинаризовать Q1Q2 Q3 …Qk каким-то другим образом, например, из центра и т. п. Итак, приведем процедуру бинаризации снизу-вверх (могли бы и наоборот) справа-налево:
4. Если текущая длина |b| > 2, пополним P’ правилом с правой частью <предпоследний символ текущей b><последний символ текущей b>, после чего заменим эту пару в b на нетерминал, возвращаемый процедурой пополнения, и вновь повторим шаг 4. Если текущая длина |b| = 2, внесем в P’ правило Ai®<предпоследний символ текущей b><последний символ текущей b> с посылкой из исходного правила.
5. Приведения КСГ к НФХ завершено.
Замечание о приведении. Различные способы бинаризации приводят к НФХ-грамматикам с разными наборами правил. При этом любая из них эквивалентна исходной КСГ, а стало быть и друг другу.
Замечание о вероятностях. Применительно к стохастической КСГ алгоритм приведения сохраняет вероятность подстановки в правилах, заимствующих посылку из исходных правил, и строит одозначные (то есть с вероятностью 1) отображения для правил, имеющих посылкой вновь созданный нетерминал.
Замечание об уровнях. Введение любого числа нетерминалов, “замещающих” соответствующие терминалы в правой части продукции, увеличивает уровень вывода на 1. Бинаризация правой части продукции увеличивает уровень вывода на |b|–2, где |b| – длина правой части в исходном правиле. Число ярусов (уровень вывода) в дереве, представляющем (исходное) правило, равен 1. В результате же приведения исходное одноярусное дерево разворачивается в многоярусное двоичное, имеющее ту же крону, что и исходное. В НФХ число ярусов эквивалентной записи исходного правила:
– остается равен 1 для правил, имеющих формат НФХ;
– становится равным |b|–1+d, где
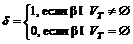
Рассмотрим пример приведения правила. Исходное правило
A ® BCpDE, где B, C,D, E Î VN, а pÎVT.
Результат приведения:
Q1 ® p
Q2 ® DE
Q3 ® Q1Q2
Q4 ® CQ3
A ® BQ4,
где Q1, Q2, Q3, Q4 – вновь созданные нетерминалы.
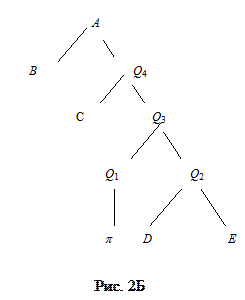 |
На рис.2А изображено дерево исходного правила. На рис.2Б представлено дерево, полученное из него применением описанного алгоритма справа-налево – (Q1(Q2 …( Qk-2 (Qk-1Qk))), а на рис.2В – слева-направо – (((Q1Q2) Q3) Q3) …Qk).
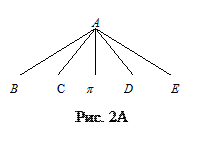 |  |
Положим, помимо правила A ® BCpDE имеется правило E ® A., определяющее вместе с первым цикл {A, E}. Уровень дерева первого правила, на котором применимо второе, равен 1 – для исходной формы, 4 – для приведенной формы с рис.2Б, 1 – для формы с рис.2В. А в записи ((BC)p)(DE), которая также является НФХ, он равен 2.
Варианты отсечения
Понятно, что глубина порождения, по крайней мере для вложенных конструкций, не должна быть чрезмерной. Понятно, что модель отсечения должно как-то соответствовать способности к восприятию/пониманию, а постольку – и к порождению текста. Однако как операционализировать это понимание? В каких терминах говорить о глубине? Вне зависимости от варианта психолингвистического ответа на эти вопросы, который, безусловно, является определяющим, разберем, имея в виду предположительные ответы, чисто формальный аспект проблемы, доступный имеющимся средствам.
Если “уровень отсечения” – это просто уровень в дереве вывода, то, как мы только что убедились, даже в совершенно однотипных формах представления одного и того же правила уровни будут различны. Поэтому обрезание по уровню в дереве никак не годится. Из достаточно общих соображений, как минимум, нуждающихся в конкретных подтверждениях, в качестве инварианта отсечения следует избрать уровень вложенности применяемых правил. В таком случае ограничение на глубину есть ограничение на циклическое применение правила или всей совокупности правил, в которых некоторый нетерминал является посылкой.
Заключение
Помимо введения грамматик с отсечением, в пространном дидактическом примере мы убедились, что подход, популярный в рассматриваемой области прикладной лингвистики, ничем не отличается от следующего. Прикладной лингвист решает задачу сложения двух чисел. Однако, в отличии от лингвиста архаического, у него есть мощный инструмент познания –формальная модель. Следуя ей, прикладной лингвист объявляет числа первыми членами степенного ряда. Затем, приведя формулу для суммы ряда, обращает наше внимание, что если отношение второго члена к первому не меньше 1, то ряд расходится, а его сумма бесконечна. Поэтому, предупреждает нас прикладной лигвист, корректное примененение модели возможно только в случае, когда первое число больше второго. Иначе задача неразрешима.
Литература
1. , , N-граммы в лингвистике. // Настоящий сборник.
2. Грин Дж. Психолингвистика. М., 1976
3. Фу К. Структурные методы в распознавании образов. М., 1977.
4. Теория ветвящихся случайных процессов. М., 1966.
5. Booth T. Probability Representation of Formal Languages. // IEEE Annual Symp. Switching and Automata Theory. 1969.
6. Schlesinger E. Sentence Structure and the Reading Process. Mouton. 1968.
7. Shieber S. Evidence against the context-freeness of natural language. // Linguistics and Philosophy, vol.
8. Stolcke A., Segal J. Precise n-gram probabilities from stochastic context-free grammars. // Proceedings of the 32th Annual Meeting of ACL. 1994.
