
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
10. Ограниченность контекстно-свободной грамматики
Теорема (о накачке КС-языка). Пусть L - произвольный контекстно-свободный язык. Тогда существует такое целое число k, что для любого слова aÎL с длиной |a| > k:
1) cлово a можно представить в виде: a = uxvyw , где u, x, v, y, w – цепочки терминалов, причем слово xy - не пустое и |xvy| £ k;
2) вместе с a в языке L лежат все слова вида uxivyiw (i = 0,1,2,…).
Доказательство. Возьмем грамматику в нормальной форме Хомского, распознающую язык L. Пусть N – множество ее нетерминалов. Обозначим n = |N|. Берем:
k = 2n
Пусть a:ÎL и |a| > k. Тогда |a| > 2n -1. Дерево разбора для вывода a является бинарным и только на самых нижних переходах от нетерминала к терминалу ведет одна ветка. Если высотой дерева считать число ребер в его самой длинной ветке, то вполне очевидно, что это то же самое, что число нетерминалов на его самой длинной ветке. Если высота строго больше n, то некоторые нетерминалы на ветке неизбежно будут повторяться. Если высоту ограничить числом n, то вдоль каждой ветви раздвоения происходят во всех нетерминальных вершинах кроме самых нижних, на предпоследних уровнях.
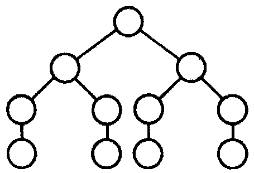
Длина заключительного слова в таком дереве не может превзойти 2n-1. Следовательно на максимальной ветви дерева разбора для нашего a какой-то нетерминал A встретится более одного раза. Следующий рисунок ясно иллюстрирует, что такое u, x, v, y, w.
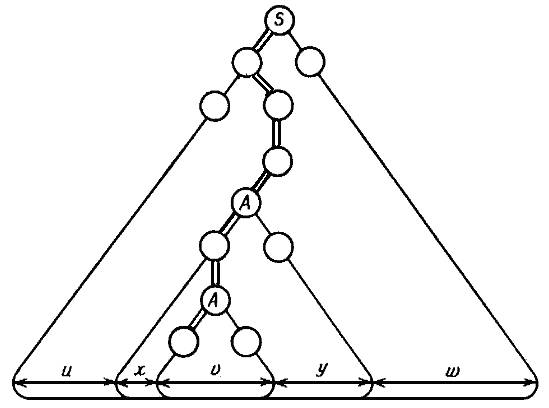
Выберем парочку этих A так, что в поддереве под верхним A больше нет повторяющихся нетерминалов. Тогда высота этого поддерева будет не больше n+1. Значит |xvy| £ 2n=k. Вполне очевидно, что из нижнего A можно вывести не только v, но и xvy – также, как это выводится из верхнего A. Значит ux2vy2w Î L. Аналогично ux3vy3wÎL и т. д. uxivyiwÎ L для i ³ 1. Наконец, из верхнего A можно вывести v также, как оно выводится из нижнего. Значит, uxivyiwÎ L для i = 0. Теорема доказана.
Теорема позволяет доказать для ряда языков, что они не являются контекстно-свободными. Например, язык всех слов вида anbncn (n³1), N={a,b,c} не является контекстно-свободным. Действительно, если это не так, то согласно теореме бесконечная серия слов вида uxivyiw при одних и тех же u, x, v, y, w должна иметь вид anbncn. Нетрудно видеть, что это невозможно.
Если обратить внимание на доказательство этой теоремы, то можно извлечь такой факт.
Лемма. Пусть L – контекстно-свободный и бесконечный язык, k – число из теоремы о накачке. Тогда в L имеется хотя бы одно слово a длина которого подчиняется условию: k < |a| £ 2 k.
Доказательство. Выберем самое короткое слово a из L, из тех, длина которых больше k. По теореме имеем соответствующее представление a = uxvyw , где u, x, v, y, w – цепочки терминалов, слово xy - не пустое, |xvy| £ k и т. д. Если допустить, что |a| > 2k, то |uw|>k. Тем более, |uvw|>k. Но слово uvw лежит в L и короче, чем a, что противоречит нашему выбору a. Значит |a| £ 2 k, что и требовалось.
Следствием этой леммы является уже принципиальный результат
Теорема. Проблема конечности языка для класса контекстно-свободных грамматик алгоритмически разрешима.
Теорема означает, что существует алгоритм, который по любой контекстно-свободной грамматике за конечное число шагов определяет, является или нет язык, порожденный этой грамматикой, бесконечным. Алгоритм состоит в следующем. По данной грамматике G строим ей эквивалентную грамматику G’ в нормальной форме Хомского. Пусть n – число нетерминалов в G’. Перебором всех возможных выводов в G’ мы можем определить, есть ли в грамматике, порожденной G’ (а, значит, и порожденной G) хоть одно слово, длина которого больше 2n, но не больше 2n+1. По лемме это и будет критерием бесконечности языка.
Если немного поглубже “покопаться” в доказательстве теоремы о накачке, то можно извлечь такой факт.
Лемма. Пусть G – контекстно-свободная грамматика в нормальной форме Хомского. Пусть N – алфавит ее нетерминалов и n = |N|. Тогда язык L грамматики G тогда и только тогда является бесконечным, когда в L имеется хотя бы одно слово a длина которого подчиняется условию: 2n-1 < |a| £ 2n-1+2n.
Действительно, уже из 2n-1< |a| следует бесконечность, т. к. в доказазательстве теоремы именно отсюда получается выводимость серии uxivyiw. Надо теперь показать, что из бесконечности L вытекает существование a с условием 2n-1 < |a| £ 2n-1+ 2n. Возьмем среди всех aÎL с условием 2n-1 < |a| самое короткое. Допустим, что |a| > 2n-1+2n . Следуя доказательству теоремы имеем a = uxvyw , |xvy| £ 2n и uxivyiw Î L (i = 0,1,2,…). В частности, b = uvw Î L. Слово b короче, чем слово a. По выбору a отсюда |b| £ 2n-1. Значит, |a| = |uxvyw| = |uvw| + |xvy| - |v| £. |uvw| + |xvy| £ 2n-1+ 2n. Противоречие, доказывающее лемму.
Лемма означает, что для проверки бесконечности КС-языка достаточно после приведения его грамматики к нормальной форме Хомского проверять на пустоту только множество слов с длинами больше 2n-1, но не больше 2n-1+2n, что немного лучше, чем в предыдущем алгоритме.
11. Нормальная форма Грейбах
Говорим, что контекстно-свободная грамматика G имеет нормальную форму Грейбах, если каждое ее правило имеет один из следующих четырех видов:
A® e
A® a
A® aB
A® aBC
где A, B, C – нетерминалы, a – терминал.
Теорема. Каждая контекстно-свободная грамматика эквивалентна некоторой грамматике в нормальной форме Грейбах.
Идея доказательства. Рассмотрим случай, когда грамматика не содержит пустого слова. Сначала найдем грамматику, эквиваленитную G и находящуюся в нормальной форме Хомского. Пусть P – ее продукции. Тогда правила в нормальной форме Хомского имеют один из видов: A® a, A® BC, причем B и C не совпадают с начальным нетерминалом S.
Рассмотрим в грамматике G только правила A® BC и все сентенциальные формы, выводимые из этих правил. Обозначим множество этих правил за P~. Рассмотрим какой-нибудь вывод в P~.
A Þ* a
Здесь A – нетерминал, a - непустая цепочка нетерминалов. Представим a в виде a = Bb.
Перед нами утверждение
“ Цепочка b такова, что из A Þ* Bb только правилами P~ ”.
Это высказывание определяет некоторую совокупность цепочек b, для которой мы введем обозначение в виде нового нетерминального символа: XAB

Рисунок показывает бинарное дерево разбора для вывода цепочки Bb. Голубая линия очерчивает область, относящуюся к b.
Добавим новые нетерминалы к нетерминалам G (один новый символ для каждой упорядоченной пары A, B) и попытаемся так расширить правила P~, чтобы они действительно реализовали указанный смысл. Прежде всего добавляем
XAA® e (1)
т. к. для пустой цепочки b конечно справедливо A Þ* Ab.
Рассмотрим теперь дерево разбора утверждения A Þ* Bb для непустого b более детально.

В этом бинарном дереве появление буквы B происходит в конце самой левой ветки с помощью применения какого-то правила C ® BD. Слово b выводится частью из D и частью из A, которая находится в красной области. На рисунке хорошо видно, что эти части подходят под понятия XDE и XAC. Надо только впереди XDE добавить еще букву E. Таким образом напрашивается правило:
XAB ® E XDE XAC (2)
Эти правила и надо внести в грамматику для каждого C ® BD из P~ и каждой пары старых нетерминалов A,E. В частности, будет добавлено правило
XСB ® D XDD XСC
из которого, с учетом правил (1) следует XСB Þ* D.
После добавления к P~ всех указанных правил (1) и (2) сделаем решительный шаг – все старые правила выкинем. Останутся только новые, множество которых обозначим за P^.
Если A Þ* Bb, то действуя так, как на переходе от рисунка к рисунку получим
XAB Þ E XDE XAC Þ EE’ XD’E’ XDC’ E’’ XD’’E’’ XAC’’ Þ …
Нетерминалы XD’’E’’ сворачиваются во все более короткие отрезки, пока все не превратятся просто в старые нетерминалы. Получим XABÞ*b в P^, для чего, собственно, и старались. Верно и обратное, если XABÞ*b в P^, то A Þ* Bb в P~.
Короче, математической индукцией по длине слова b из нетерминалов грамматики G надо показать:
A Þ* Bb в P~ тогда и только тогда, когда XABÞ*b в P^.
Далее грамматика P^ доделывается следующим образом. Если правила P начальной грамматики G содержат продукцию A® a, то в P^ добавляем
S® a XSA
Продукция вполне естественная – если в P~ выводится S Þ* Ab, то сейчас в P^ получится S Þ* ab.
Наконец сделаем последнюю переделку. Каждую продукцию вида (2) заменим на несколько продукций
XAB ® e XDE XAC
по всем таким терминалам e, для которых P содержит правило E ® e. Если в P ни одного такого правила нет, то продукцию (2) просто выкидываем. Полученная грамматика и будет искомой.
12. Регулярные грамматики
Напомним, что при компиляции почти любого языка высокого уровня начальные и главные стадии – это лексический и синтаксический анализ. Главная часть синтаксический анализа – построение дерева разбора. Это дерево вполне подобно дереву разбора при выводе цепочки в КС-грамматике. Роль грамматики для языка программирования играет описание этого языка в виде нормальной формы Бэкуса-Наура. Цепочка, для которой строится вывод и дерево разбора – это компилируемая программа.
Тем не менее, предварительным этапом является лексический анализ, позволяющий, попросту говоря, переобозначить некоторые фрагменты текста программы, придав им статус терминальных символов. Оказывается, что на этом этапе также можно использовать математический аппарат КС-грамматик, но в его самом простом виде - в виде регулярных грамматик.
Напомним, что КС-грамматика называется регулярной, если все ее правила имеют один из видов: A®e , A® a, A® aB.
Язык L называется регулярным, если он определяется некоторой регулярной грамматикой.
Правила вида A®e как и в контекстно-свободных грамматиках, не играют существенной роли. Алгоритм избавления от e–правил оставляет регулярную грамматику регулярной. Поэтому утверждения о e-свободных регулярных грамматиках – это фактически утверждения о всех регулярных грамматиках.
Пример. Грамматика S® pA, A® i | iS определяет множество слов вида pipipi… Рассмотроим для иллюстрации дерево разбора сентенции pipi в данной регулярной грамматике.
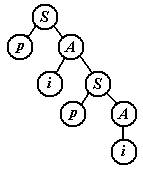
Такой же вид имеет любое дерево разбора в регулярной грамматике. Не смотря на кажущуюся простоту, регулярные грамматики обладают, тем не менее, выразительной силой, достаточной для выполнения задач лексического анализа. Ограниченность же ее возможностей демонстрирует
Теорема (о накачке регулярного языка). Пусть L - произвольный регулярный и e-свободный язык. Пусть n – количество нетерминалов в некоторой регулярной и e-свободной грамматике, определяющей L. Тогда для любого слова aÎL с длиной |a| > n:
1) cлово a можно представить в виде: a = uxv , где u, x, v – цепочки терминалов, причем слово x - не пустое и |ux| £ n;
2) вместе с a в языке L лежат все слова вида uxiv (i = 0,1,2,…).
Доказательство. Допустим, что |a| > n для aÎL и рассмотрим дерево разбора при выводе этой цепочки.
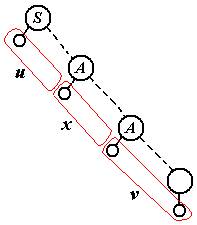
Очевидно, что число нетерминалов в дереве – это длина выводимой цепочки. Значит какой-то нетерминал встречается дважды. Рассмотрим самую “верхнюю” пару таких нетерминалов A, в том смысле, что над нижним A этой пары уже нет повторяющихся нетерминалов. Рисунок иллюстрирует, что такое u, x, v. Ясно, что вместе с a из S выводятся все слова вида uxiv (i = 0,1,2,…). А т. к. в последовательности нетерминалов, из которй получается ux, нет одинаковых букв, длина этой последовательности и вместе с ней слова ux не превосходит n. Теорема доказана.
Из теоремы о накачке в частности очевидно, что язык, состоящий из всех слов вида anbn (n³1) не является регулярным. Интересно, что при этом язык anbm (n,m³1) регулярен (S® aA, A® aA|bB|b, B® bB|b).
Мы видим, что регулярные грамматики слабее контекстно-свободных. Однако их выразительной силы достаточно для лексического анализа. Приведем ряд примеров, иллюстрирующих эти возможности.
Пример 1.
S ® <Число> | <Знак><Число>
<Знак> ® + | –
<Число> ® <Цифра><Число>|<Цифра>
<Цифра> ® 0|1|2|3|4|5|6|7|8|9
Эта грамматика очевидно определяет язык целочисленных числовых констант. По виду она не яаляется регулярной. Однако цепное правило S ® <Число> можно “устранить” нетерминал <Знак> в первом и остальных правилах заменить на два варианта “ + – ”, аналогично в третьем и остальных правилах заменить нетерминал <Цифра> на соответствующие терминалы. В результате получится эквивалентная регулярная грамматика.
Пример 2.
S ® <Буква>|<Буква>S
<Буква> ® _|a|b|c … z|A|B|C … Z
Эта грамматика определяет регулярный язык идентификаторов.
Пример 3.
S ® <Слово>@<Конец>
<Конец> ® <Слово>.<Слово>|<Слово>.<Конец>
<Слово> ® <Буква>|<Буква><Слово>
<Буква> ® -|_|a|b|c … z|A|B|C … Z
Эта грамматика определяет язык правильных e-mail-адресов. На этот раз регулярность языка не так очевидна. Однако дальше му убедимся, что и эта грамматика эквивалентна регулярной.
