

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Основные особенности архитектуры NetBurst.
Для того, чтобы ЦП могли работать на частотах порядка нескольких ГГц Intel увеличил длину конвейера Pentium IV до 20 стадий (Hyper Pipelined Technology) - для сравнения – длина конвейера Pentium III составляет 10 стадий. Чего же достиг Intel, так удлинив конвейер? Благодаря декомпозиции выполнения каждой команды на более мелкие этапы, каждый из этих этапов теперь может выполняться быстрее, что позволяет увеличивать частоту процессора. Так, если при используемом технологическом процессе 0.18 мкм предельная частота для Pentium III составляет 1 ГГц, то Pentium IV мог достигнуть частоты в 2 ГГц. Однако у чрезмерно длинного конвейера есть и свои недостатки. Первый недостаток - каждая команда, проходя большее число стадий, выполняется дольше. ![]() Второй недостаток длинного конвейера вскрывается при ошибках в предсказании переходов.
Второй недостаток длинного конвейера вскрывается при ошибках в предсказании переходов.
Из-за такого увеличения длины конвейера время выполнения одной команды в процессорных тактах также увеличивается. Поэтому компания осуществила модернизацию алгоритмов предсказания переходов.
Advanced Dynamic Execution - осуществляет минимизацию простоя процессора при неправильном предсказании переходов и увеличение вероятности правильных предсказаний. Для этого Intel улучшил блок выборки инструкций для внеочередного выполнения и повысил правильность предсказания переходов. Правда, для этого алгоритмы предсказания переходов были доработаны минимально, основным же средством для достижения цели было выбрано увеличение размеров буферов, с которыми работают соответствующие блоки процессора. Количество предварительно загружаемых инструкций увеличилось до 126 по сравнению с 48 у Pentium III. Буфер, хранящий адреса условных переходов, также увеличился с 512 байт до 4 КБ. Все это позволило увеличить вероятность правильного предсказания переходов на 33%.

![]()


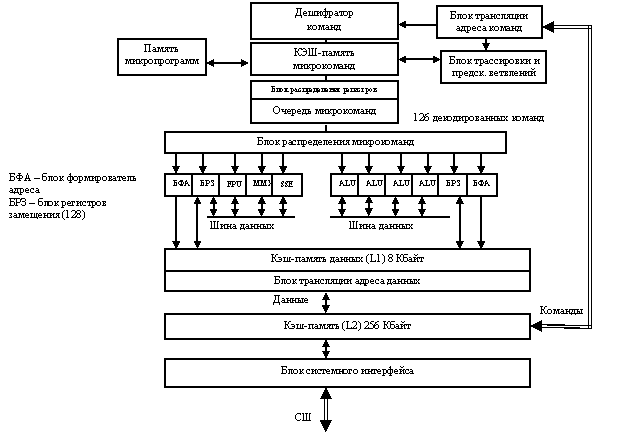

Рис. 3.2. Архитектура процессора Pentium IV
Для ускорения работы целочисленных операций в Pentium IV применена технология удвоения внутренней тактовой частоты (Rapid Execution Engine). Два блока АЛУ, выполняющие операции над целочисленными данными, работают на частоте вдвое большей, чем частота самого процессора. Таким образом, например, в Pentium IV с частотой 1.4 ГГц АЛУ работает на частоте 2.8 ГГц. В АЛУ исполняются простые целочисленные инструкции, поэтому, производительность нового процессора при операциях с целыми числами очень высока. Однако, на производительности Pentium IV при операциях с вещественными числами, MMX или SSE двукратное ускорение АЛУ никак не сказывается.
Кэш 1-го уровня в процессоре также претерпел значительные изменения. В отличие от Pentium III, кэш которого мог хранить команды и данные, Pentium IV имеет всего 8 КБ кэш данных. Команды, поступающие на исполнение процессору, сохраняются в так называемом Trace Cach (кэш-память микрокоманд). Там они хранятся уже в декодированном виде, т. е. в виде последовательности микроопераций, поступающих для выполнения в исполнительные устройства процессора. Емкость этого кэша составляет 12000 микроопераций и по сравнению с обычным L1-кэшем он имеет много преимуществ, направленных на минимизацию простоев процессора при выполнении неправильных предсказаний переходов.
Особенностью новых процессоров Pentium IV является расширение набора команд командами SSE2. К 70-ти командам SSE, работающим с потоковыми данными одинарной точности добавились 144 команды для работы с вещественными числами двойной точности, а также с целыми числами длиной от одного до восьми байт. Дальнейшее расширение – командами SSE3, добавившее еще 13 новых команд. Наконец, заявленное расширение SSE4 еще на несколько десятков команд.
3.2. Программная модель ЦП Pentium
Программная модель ЦП включает три группы регистров данных (рис. 3.3), в каждой из групп по восемь регистров. Первая группа включает 32-разрядные целочисленные регистры, вторая – 80-разрядные регистры и третья – 128-разрядные регистры.
Расширение ММХ использует новые типы упакованных 64-разрядных данных:
- упакованные байты - восемь байт; упакованные слова - четыре 16-разрядных слова; упакованные двойные слова (два 32-разрядных слова); учетверенное слово (одно 64-разрядное слово).
Эти типы данных могут обрабатываться в восьми 64-разрядных регистрах MMX0 - MMX7, которые фактически являются частью регистров АП. В систему команд для поддержки MMX введено 57 дополнительных команд для одновременной обработки нескольких единиц данных. Команды ММХ доступны из любого режима работы процессора. Команды MMX выполняются так же, как и команды с плавающей точкой. Более того, механизм сохранения и восстановления состояния вычислительной среды, принятый для операций с плавающей точкой, применим и при выполнении ММХ-вычислений.

Рис. 3.3. Регистры данных ЦП Pentium IV
SSE-расширение реализовано в виде аппаратно-программного модуля,
который включает регистры третьей группы разрядностью в 128 бит, имеющих обозначение ХММО - ХММ7, и 32-разрядный регистр управления/состояния MXCSR (рис. 3.4). Программная часть SSE-расширения включает в себя набор SSE-команд для работы с данными с плавающей запятой. Содержимое ХММ-регистра может представлять собой:
· четыре 32-разрядных операнда с плавающей запятой в КВФ (рис. 2.1);
· два 64-разрядных операнда с плавающей запятой в ДВФ (рис. 2.1);
· один 128-разрядный операнд, представляющий числа в диапазоне от
2-126 до 2127.
Поскольку аппаратно модуль SSE-расширения реализован независимо от
других модулей, то это позволяет выполнять SSE-комапды параллельно с командами АП и ММХ-командами.


Рис. 3.4. Младшие 16 разрядов регистра управления-состояния MXCSR
В процессе обработки данных команды SSE-расширения могут возбуждать исключительные ситуации, аналогичные тем которые были описаны в разделе 2.2. Эти события фиксируются в регистре MXCSR. Старшие 16 разрядов регистра управления-состояния не используются. Все поля регистра, за исключением FZ, обозначаются и используются аналогично соответствующим полям регистров SR и CR арифметического процессора, описанном в 2.2. Бит FZ используется, если результат операции близок к нулю. При этом ЦП выполняет следующие действия:
• возвращает значение 0 и знак результата;
• устанавливает флаги Р (бит 5) и U (бит 4);
• маскирует биты исключений.
Перед тем как создавать программы, использующие MMX - и SSE-расширения, следует убедиться в том, что данный тип процессора поддерживает эту технологию. В разделе 6.3 приводится пример такой проверки.
3.3. Система команд ММХ-расширения
Любая команда, относящаяся к ММХ-расширению начинается с буквы p. Большинство команд имеют суффикс, который определяет тип данных и используемую арифметику:
• us (unsigned saturation) -беззнаковое насыщение;
• s или ss (signed saturation) -знаковое насыщение;
• b, w, d, q - указывают тип данных (байт, 16-разрядное слово, 32-разрядное слово и 64-разрядное слово, соответственно). Если в суффиксе есть две из этих букв, первая соответствует входному операнду, вторая - выходному;
• если в суффиксе нет ни символа s, ни символов ss, то применяется циклическая арифметика (wraparound). Если в этом случае результат операции выходит за двоичную разрядную сетку используемого типа данных, то «лишние» старшие биты результата отбрасываются.
Система команд может быть представлена в виде 5-ти групп команд: передачи данных, арифметических, логических и команд сдвига, упаковки и распаковки и группы специальных команд.
Команды передачи данных.
В группу команд передачи данных входят две команды movd и movq.
Команда movd позволяет копировать 32-разрядное число:
• из младших разрядов одного ММХ-регистра в младшие разряды другого
(старшие разряды заполняются нулями);
• из переменной в памяти либо из целочисленного регистра в младшие 32
разряда ММХ-регистра (старшие разряды заполняются нулями);
• из младших разрядов ММХ-регистра в ячейку памяти либо в целочисленный регистр.
Команда movq выполняет копирование 64 бит:
• из одного ММХ-регистра в другой;
• из памяти в ММХ-регистр;
• из ММХ-регистра в память.
Среди всех ММХ-команд только movd и movq могут иметь выходной операнд в памяти, a movd - единственная команда, операнд которой может находиться в 32-разрядном регистре процессора.
Арифметические команды включают команды сложения, вычитания, умножения и сравнения.
Команды сложения и вычитания работают с упакованными байтами и словами со знаком и без знака, а также с упакованными двойными словами со знаком. Они могут использовать как циклическую арифметику, так и арифметику с насыщением.
Команды сложения paddb, paddw, paddd (циклическая арифметика), paddsb, paddsw (арифметика со знаковым насыщением) и paddusb, paddusw (арифметика с беззнаковым насыщением) - входной операнд может находиться в ММХ-регистре или в памяти; выходной операнд должен находиться в ММХ-регистре.
Работа команды paddusw ММ0,ММ1 проиллюстрирована на рис. 3.5.
Из рисунка видно, что слово (16 – 31 разряд) содержит значениеПоскольку сумма соответствующих слов превышает предельно допустимое значение для данного типа операндов, в качестве суммы берется граничное значение.


Рис. 3.5. Сложение по команде paddusw MM0,MM1
Команды вычитания psub, psubw, psubd (циклическая арифметика), psubsb, psubsw (арифметика со знаковым насыщением) и psubusb, psubusw (арифметика с беззнаковым насыщением) - входной операнд может находиться в ММХ-регистре или в памяти; выходной операнд должен находиться в ММХ-регистре.
Команды вычитания работают с теми же типами данных и формируют результат точно так же, как и команды сложения.
Команды умножения попарно перемножают 16-разрядные слова и дают результат по правилам циклической арифметики.
Команда pmulhw ( pmullw) - попарное умножение 16-разрядных слов со знаком, находящихся во входном и выходном операндах. Результатом операции являются четыре 32-разрядных произведения, при этом старшие (младшие) разряды произведений сохраняются в 16-разрядных словах выходного операнда, а младшие (старшие) разряды произведений теряются. Входным операндом может выступать ММХ-регистр или ячейка памяти, а выходным операндом должен быть ММХ-регистр. Для получения полного результата умножения с помощью этих команд необходимо выполнить такую
последовательность шагов:
· получить старшие 16 бит произведения, используя команду pmulhw.
· получить младшие 16 бит произведения, используя команду pmullw.
· объединить частичные результаты в одно двойное слово с помощью команд punpckhwd и punpcklwd.
Команда pmaddwd - попарное умножение 16-разрядных слов со знаком, находящихся в двух операндах. После получения в результате четырех 32-разрядных произведений первое произведение складывается со вторым, а третье - с четвертым. Суммы записываются в 32-разрядные слова выходного операнда. Работа команды pmaddwd ММ0,ММ1 проиллюстрирована на рис. 3.5.
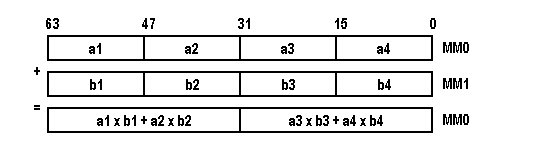

Рис. 3.5. Умножение по команде ppaddwd MM0,MM1
Команды сравнения попарно сравнивают элементы данных (байты, 16- или 32-разрядные слова) входного и выходного операндов и в зависимости от результата сравнения соответствующий элемент данных выходного операнда заполняется нулями либо единицами. Входным операндом могут выступать ММХ-регистр или ячейка памяти, а выходной операнд должен находиться в ММХ-регистре.
Команды pcmpeqb, pcmpeqw, pcmpeqd заполняют элемент данных выходного операнда единицами, если соответствующие элементы равны и нулями, в противном случае.
Команды pcmpgtb, pcmpgtw, pcmpgtd заполняют элемент данных выходного операнда единицами, если соответствующий элемент данных выходного операнда больше соответствующего входного элемента и нулями, в противном случае.
Сдвиги и логические команды.
Команды сдвига выполняют сдвиг каждого элемента данных (16-, 32- или 64-разрядного слова) в выходном операнде на величину, задаваемую входным операндом. Входной операнд может быть непосредственным операндом либо находиться в ММХ-регистре или в памяти. Выходной операнд должен находиться в ММХ-регистре.
Команды psllw, pslld, psllq выполняют логический сдвиг влево, а команды psrlw, psrld, psrlq – вправо.
Команды psraw, psrad осуществляют арифметический сдвиг вправо для 16- и 32-разрядных слов.
Логические команды выполняют поразрядные логические операции над всеми 64 битами своих операндов. Они реализуют логические операции И, ИЛИ, И-НЕ, исключающего ИЛИ. Входной операнд может быть ММХ-регистром или операндом в памяти. Выходной операнд должен находиться в ММХ-регистре.
Команда pand (логическое И) - вычисляет поразрядное И своих операндов.
Команда pandn (логическое И-НЕ) - вычисляет поразрядное НЕ вы -
выходного операнда, а затем поразрядное И между входным операндом и инвертированным значением выходного операнда.
Команда роr (логическое ИЛИ) - вычисляет поразрядное ИЛИ своих операндов.
Команда рхоr(исключающее ИЛИ) - вычисляет поразрядное исключающее ИЛИ своих операндов.
Команды упаковки преобразуют длинные элементы данных (16- и 32-разрядные слова) в более короткие. Если исходное значение «не помещается» в коротком элементе данных, то происходит «насыщение» - результатом считается граничное значение допустимого диапазона выходного типа данных. Команды распаковки попарно объединяют элементы данных из обоих операндов в более длинные элементы выходного операнда. Этими командами можно пользоваться для увеличения числа значащих разрядов при вычислениях. Входным операндом может выступать ММХ-регистр или ячейка памяти, выходной операнд должен находиться в ММХ-регистре;
Команды упаковки и упаковки.
Команды упаковки packsswb, packssdw - преобразуют длинные элементы данных (16- и 32-разрядные слова со знаком) в более короткие (байты или 16-разрядные слова со знаком). На рис. 3.6 иллюстрируется выполнение команды packssdw MM0,MM1.
Команда упаковки packuswb - выполняет преобразование 16-разрядных слов со знаком из обоих операндов в байты без знака и записывает их в выходной операнд. Если исходное слово со знаком было больше FFh, результатом преобразования считается FFh. Если исходное слово со знаком отрицательно, результатом преобразования считается 0h.
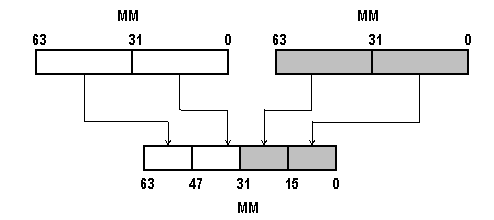

Рис. 3.6. Выполнение команды упаковки packssdw MM0,ММ1.
Команды распаковки punpckhbw, punpckhwd, punpckhdq - попарно объединяют исходные элементы данных (байтов, 16- или 32-разрядных слов), находящиеся в старших 32 разрядах обоих операндов. Полученные в результате длинные элементы записываются в выходной операнд. Исходные значения младших разрядов операндов на результат не влияют.


Рис. 3.7. Выполнение команды распаковки punpckhbw MM0,MM1.
На рис. 3.7 проиллюстрирован механизм работы команды punpckhbw. Суть работы команд punpckhwd и punpckhdq аналогична, с той лишь разницей, что punpckhwd распаковывает старшие два слова обоих регистров, а punpckhdq старшие двойные слова.
Команды распаковки punpcklbw, punpcklwd, punpckldq - попарно объединяют исходные элементы данных (байтов, 16- или 32-разрядных слов), находящиеся в младших 32 разрядах обоих операндов. Полученные в результате длинные элементы данных записываются в выходной операнд. Исходные значения старших разрядов операндов на результат не влияют.
Механизм работы команды распаковки punpcklwd проиллюстрирован на рис. 3.8.

Рис. 3.8. Выполнение команды распаковки punpcklwd MM0,MM1.
Суть работы команд punpcklbw и punpckldq аналогична, с той разницей, что punpcklbw распаковывает младшие четыре байта, а punpckldq – младшие двойные слова.
Специальные команды не имеют специфики какой-либо из рассмотренных выше групп.
Команды pavgb, pavdw - вычисляют среднее значение двух чисел, представленных байтами или словами. Значения операндов рассматриваются как беззнаковые целые числа. В качестве входного операнда может выступать ММХ-регистр или 64-разрядная ячейка памяти, выходным операндом служит один из ММХ-регистров.
Команда pextrw - извлекает одно из четырех упакованных слов входного операнда и имеет три аргумента: входной операнд, выходной операнд и маска. Младшие два бита маски задают во входном операнде номер упакованного слова, подлежащего извлечению. Извлеченное слово сохраняется в младшем слове выходного операнда. Выходным операндом этой команды может выступать один из 32-разрядных регистров общего назначения. Старшее слово выходного операнда обнуляется.
Команда pinsrw - вставляет слово в одно из четырех упакованных слов выходного операнда. Выходным операндом является один из ММХ-регистров, а входным операндом может выступать один из 32-разрядных регистров общего назначения, младшее слово которого будет вставлено в выходной операнд. Номер позиции, куда помещается операнд, определяется младшими двумя битами маски.
Команды pmaxusb, pmaxsw, (pminusb, pminsw) - извлекают максимальное (минимальное) значение из каждой пары упакованных элементов в выходном и входном операндах. В качестве выходного операнда может выступать ММХ-регистр, а в качестве входного - ММХ-регистр или 64-разрядная ячейка памяти.
Команда pmovmskb - формирует байт, содержащий знаковые биты восьми байтов, содержащихся во входном операнде, в качестве которого может выступать один из ММХ-регистров. Выходным операндом является 32-разрядный регистр общего назначения, младший байт которого будет содержать результат.
Команда psadbw - вычисляет суммарную разность значений беззнаковых байтов входного и выходного операндов. Входным операндом может выступать ММХ-регистр или 64-разрядная ячейка памяти, а выходным - один из ММХ-регистров.
3.4. Система команд SSE-расширения
Набор SSE-расширения включает 70 команд. Их подробное описание можно найти в фирменном руководстве Intel. Арифметические команды могут выполняться в двух контекстах: скалярном и параллельном. Параллельные арифметические операции обрабатывают одновременно 4 двойных слова и имеют в своей мнемонике суффикс ps, а скалярные - обрабатывают только младшие 32-разрядные двойные слова упакованных операндов, не затрагивая при этом три старших двойных слова. Исключение составляют некоторые команды скалярной пересылки данных. Мнемоническое обозначение этих команд включает суффикс ss.
Набор команд SSE-расширения можно разделить на пять групп: команды передачи данных, арифметические команды, логические команды, команды преобразования и специальные команды.
Команды передачи данных.
Включают восемь команд, позволяющих выполнять операции над 128-, 64- и 32-разрядными операндами.
Команды movaps (movups) - пересылка выровненных (невыровненных) по 16-байтовой границе 128-разрядных операндов. В качестве входного операнда могут выступать ХММ-регистр или 128-разрядная ячейка памяти, выходным операндом может служить один из ХММ-регистров. Если адрес ячейки памяти не будет выровнен по 16-байтовой границе, то по команде movaps произойдет исключение общей защиты.
Команда movhps - пересылка невыровненных 64 бит из входного операнда в выходной. Один из операндов обязательно должен быть ХММ-регистром, в качестве второго может выступать 64-разрядная ячейка памяти. Пересылаются только старшие 64 бит входных операндов. Младшие 64 бит обоих операндов не изменяются. Если данные передаются из ХММ-регистра, то пересылке подлежат только старшие 64 бит. Команда не требует выравнивания по 16-байтовой границе адреса ячейки памяти.
Команды movhlps (movlhps) - пересылка невыровненных 64 бит из входного операнда в выходной. Оба операнда должны находиться в ХММ-регистрах. Пересылаются только старшие (младшие) 64 бит входных операндов. В результате выполнения этой команды изменяются младшие (старшие) 64 бит регистра-приемника. Схема выполнения команд показана на рис. 3.9.
ХММ1 63 127 0 ХММ0 63 127 0

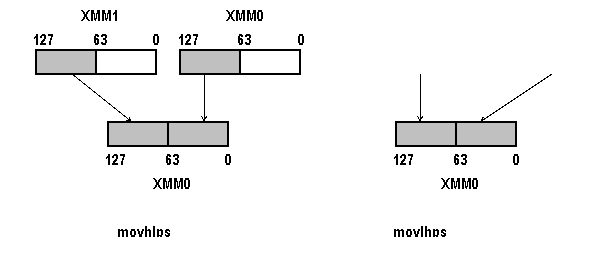


|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
