

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В МПС с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом "почтового ящика". Модель системы с общей памятью очень удобна для программирования и иногда рассматривается как высокоуровневое средство оценки влияния обмена на работу системы, даже если основная система в действительности реализована с применением локальной памяти и принципа передачи сообщений.
В МПС с локальной памятью непосредственное разделение памяти невозможно. Вместо этого процессоры получают доступ к совместно используемым данным посредством передачи сообщений по сети обмена. Эффективность схемы коммуникаций зависит от протоколов обмена, основных сетей обмена и пропускной способности памяти и каналов обмена. В сетях с коммутацией каналов по мере возрастания требований к обмену следует учитывать возможность перегрузки сети. Здесь межпроцессорный обмен связывает сетевые ресурсы: каналы, процессоры, буферы сообщений. Объем передаваемой информации может быть сокращен за счет тщательной функциональной декомпозиции задачи и тщательного диспетчирования выполняемых функций.
Таким образом, существующие МПС распадаются на две основные группы.
К первой группе относятся МПС с общей (разделяемой) основной памятью, объединяющие до нескольких десятков (обычно менее 32) процессоров. Сравнительно небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью одной шины. При наличии у процессоров кэш-памяти достаточного объема высокопроизводительная шина и общая память могут удовлетворить обращения к памяти, поступающие от нескольких процессоров. Поскольку имеется единственная память с одним и тем же временем доступа, эти МПС иногда называют UMA (Uniform Memory Access). Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным. Структура подобной системы представлена на рис. 7.1.
Вторую группу МПС составляют крупномасштабные системы с распределенной памятью. Для того чтобы поддерживать большое количество процессоров приходится распределять основную память между ними, в противном случае полосы пропускания памяти просто может не хватить для удовлетворения запросов, поступающих от очень большого числа процессоров. Естественно при таком подходе также требуется реализовать связь процессоров между собой. На рис. 7.2 показана структура такой системы.
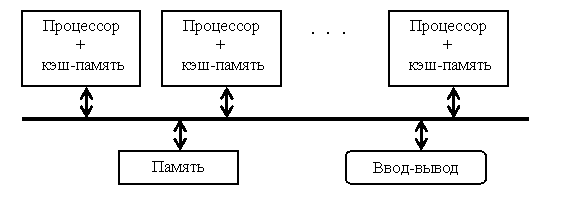

Рис. 7.1. Типовая архитектура МПС с общей памятью
С ростом числа процессоров просто невозможно обойти необходимость реализации модели распределенной памяти с высокоскоростной сетью для связи процессоров.
С быстрым ростом производительности процессоров и связанным с этим ужесточением требования увеличения полосы пропускания памяти, масштаб систем (т. е. число процессоров в системе), для которых требуется организация распределенной памяти, уменьшается, также как и уменьшается число процессоров, которые удается поддерживать на одной разделяемой шине и общей памяти. Распределение памяти между отдельными узлами системы имеет два главных преимущества.
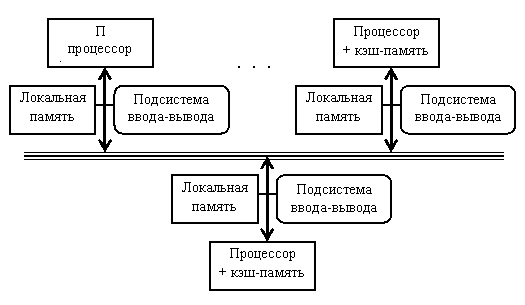

Рис. 7.2. Типовая архитектура МПС с распределенной памятью
Во-первых, это эффективный с точки зрения стоимости способ увеличения полосы пропускания памяти, поскольку большинство обращений могут выполняться параллельно к локальной памяти в каждом узле. Во-вторых, это уменьшает задержку обращения (время доступа) к локальной памяти. Эти два преимущества еще больше сокращают количество процессоров, для которых архитектура с распределенной памятью имеет смысл.
Существующие ВС класса MIMD образуют три технических подкласса:
· симметричные мультипроцессоры;
· системы с массовым параллелизмом;
· кластеры.
Симметричные мультипроцессоры (SMP – Symmetric Multi Processors) используют принцип разделяемой памяти. В этом случае система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой ячейке памяти с одинаковой скоростью. Процессоры подключены к памяти с помощью общей шины или коммутатора. Аппаратно поддерживается когерентность кэшей. Вся система работает под управлением единой ОС.
Системы с массовым параллелизмом (MPP – Massively Parallel Processing) содержат множество процессоров c индивидуальной памятью, которые связаны через некоторую коммуникационную среду. Как правило, системы MPP благодаря специализированной высокоскоростной системе обмена обеспечивают наивысшее быстродействие.
 Кластерные системы − более дешевый вариант MPP-систем, поскольку они также используют принцип передачи сообщений, но строятся из готовых компонентов. Базовым элементом кластера является локальная сеть. Оказалось, что на многих классах задач и при достаточном числе узлов такие системы дают производительность, сравнимую с суперкомпьютерной.
Кластерные системы − более дешевый вариант MPP-систем, поскольку они также используют принцип передачи сообщений, но строятся из готовых компонентов. Базовым элементом кластера является локальная сеть. Оказалось, что на многих классах задач и при достаточном числе узлов такие системы дают производительность, сравнимую с суперкомпьютерной.
Кластер – параллельный компьютер, все процессоры которого действуют как единое целое для решения одной задачи. Первым кластером на рабочих станциях был Beowulf. Проект Beowulf начался в 1994 г. сборкой в научно-космическом центре NASA 16-процессорного кластера на Ethernet-кабеле. С тех пор кластеры на рабочих станциях обычно называют Beowulf-кластерами. Любой Beowulf-кластер состоит из машин (узлов) и объединяющей их сети (коммутатора). Кроме ОС, необходимо установить и настроить сетевые драйверы, компиляторы, ПО поддержки параллельного программирования и распределения вычислительной нагрузки. В качестве узлов обычно используются однопроцессорные ВМ с быстродействием 1 ГГц и выше или SMP-серверы с небольшим числом процессоров (обычно 2–4).
Для получения хорошей производительности межпроцессорных обменов используют полнодуплексную сеть Fast Ethernet с пропускной способностью 100 Mбит/с. При этом для уменьшения числа коллизий устанавливают несколько «параллельных» сегментов Ethernet или соединяют узлы кластера через коммутатор (switch). В качестве операционных систем обычно используют Linux или Windows NT и ее варианты, а в качестве языка программирования – С++.
Наиболее распространенным интерфейсом параллельного программирования в мод модели передачи сообщений является MPI (Message Passing Interface). Рекомендуемой бесплатной реализацией MPI является пакет MPICH, разработанный в Аргоннской национальной лаборатории США.
Во многих организациях имеются локальные сети компьютеров с соответствующим программным обеспечением. Если такую сеть снабдить пакетом MPICH, то без дополнительных затрат получается Beowulf-кластер, сравнимый по мощности с супер-ЭВМ. Это является причиной широкого распространения таких кластеров.
7.2. Управление процессами
Программная единица, которая выполняет независимую задачу, называется процессом. Если процессы выполняются последовательно, система называется однопрограммной. Обычно в однопрограммных системах в любой момент времени в памяти находится только один процесс, а следующий процесс не загружается для выполнения, пока не завершается текущий процесс. Такая ситуация не подходит для большого числа применений, особенно если в них требуется реакция на события в реальном времени или быстрое и эффективное выполнение многочисленных программ. Предположим, что МПС должна принимать и обрабатывать данные от двух независимых устройств сбора данных. При работе в однопрограммной среде любой процесс может пропустить часть входных данных в то время, когда выполняется другой процесс. Это может случиться, даже когда скорость поступления данных в обоих процессах невелика. Проблема вызывается не недостатком вычислительной мощности или быстродействием интерфейсов, а последовательным характером всего метода обработки
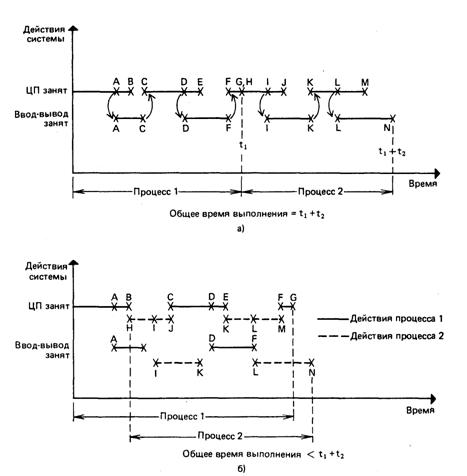
Рис. 7.3. Производительность однопрограммной (а) и мультипрограммной (б) системы
В мультипрограммной среде в памяти одновременно находятся коды двух и более процессов, которые выполняются с мультиплексированием во времени. Если скорость передачи данных имеет приемлемое значение, процессы можно коммутировать с помощью прерываний и успешно выполнять оба процесса.
Производительность системы часто измеряется числом заданий, выполненных за временной интервал; эта величина называется пропускной способностью системы. Чтобы показать, каким образом совмещение обработки и ввода-вывода в режиме ПДП может улучшить пропускную способность системы, рассмотрим два процесса. Типичные действия однопрограммной системы показаны на рис. 7.3,а. Процесс 1 начинается и продолжается до точки А, где ему потребовался ввод-вывод. Здесь инициируется ввод-вывод, а обработка продолжается параллельно с ним до тех пор, пока для обработки не потребовались входные данные (точка В); ЦП должен ожидать завершения ввода-вывода. Обработка возобновляется, когда ввод-вывод закончен (точка С). Аналогичная ситуация возникает в точках D, Е и F. По окончании процесса 1 начинается процесс 2; он выполняется также, как и процесс 1. Кроме "перемешивания" нескольких действий ввода-вывода, мультипрограммная система может одновременно обслуживать нескольких пользователей. Пользователи поочередно управляют ЦП, когда каждому из них выделяется временной квант — получается система с разделением времени.
В памяти однопроцессорной мультипрограммной системы одновременно находятся несколько процессов, которые разделяют ЦП, хотя сам ЦП в любой момент времени может выполнять только один процесс. В простой мультипрограммной системе процессы могут находиться в трех состояниях, причем каждый процесс в любой момент времени находится только в одном из этих состояний. Указанными состояниями являются:
1. Выполнение процесса. Процесс выполняется центральным процессором.
2. Блокировка. Выполнение процесса продолжать невозможно, так как он ожидает появления некоторого события, например завершения операции ввода-вывода.
3. Готовность. Выполнение процесса можно возобновить в любой момент времени. Например, ввод-вывод, завершения которого ожидал процесс, закончен и обработку можно продолжить.
Смена состояний каждого процесса во времени показана на рис. 7.4. При запуске процесс помещается в очередь процессов, находящихся в состоянии готовности. Если текущий выполняемый процесс переходит из состояния выполнения в состояние блокировки из-за необходимости ожидания ввода-вывода, ЦП освобождается и планировщик процессов выбирает из очереди процесс и изменяет его состояние готовности на состояние выполнения. До тех пор, пока процесс находится в состоянии блокировки, его выполнение приостанавливается. После завершения ввода-вывода процесс переходит в состояние готовности и помещается в соответствующую очередь.
В наиболее простом механизме мультипрограммирования процесс выполняется до своего завершения или необходимости ожидать ввода-вывода. Однако для предотвращения монопольного использования процессора одним процессом систему можно спроектировать так, чтобы выполняемый процесс переходил в состояние готовности по истечении определенного временного интервала, что обеспечивает другим процессам шансы на выполнение. Такими системами с разделением времени управляют внешние программируемые устройства синхронизации, называемые часами (тиймерами) реального времени (см. $ 9.3). В системе с разделением времени время измеряется от момента перехода процесса в состояние выполнения; часы реального времени формируют прерывание, когда отведенное процессу время (т. е. временной квант) исчерпано. После этого процедура прерывания, являющаяся частью резидентного монитора, инициирует изменения состояний процессов.
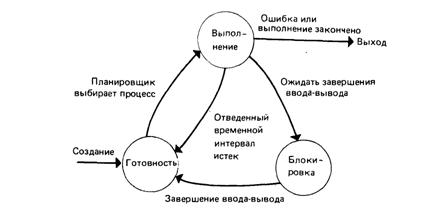
Рис. 7.4. Смена состояний процесса во времени
Реализация очереди процессов, находящихся в состоянии готовности, зависит от стратегии планирования. Простейшая стратегия «первый пришел, первый вышел» (FIFO) назначает всем процессам одинаковые приоритеты и всегда выбирает для выполнения процесс, который находится в очереди дольше всех. Структура списка готовности, опирающаяся на планирование FIFO и связанный список, представлена на рис. 7.5. Указатель первого элемента показывает, какой процесс находится в вершине очереди, а указатель последнего элемента — процесс в низу очереди. Указатель последнего элемента необходим для того, чтобы в очередь можно было помещать новые процессы без просмотра всего списка. В примере предполагается, что каждый процесс имеет ID (идентификатор), который совпадает с позицией в массиве, содержащем связанный список. Предполагается также, что очередь состоит из процессов 3, 6, 2, 8 и 5 (именно в таком порядке). Следовательно, указатель первого элемента содержит 3, указатель последнего элемента содержит 5, а процессы 2, 3, 5, 6 и 8 находятся в состоянии готовности. Остальные элементы в таблице процессов либо заняты выполняемыми или заблокированными процессами, либо в данное время не используются. Если число 0 применяется для указания конца списка, его нельзя употреблять в качестве ID процесса. Если ID процессов представлены одним байтом и не может быть процесса 0, то максимальное число процессов, которые могут находиться в системе одновременно, равно 255.
Каждый элемент в списке содержит прямой указатель очереди (fqp), который указывает на следующий элемент в списке, и указатель управляющего блока процесса для локализации блока памяти, который хранит информацию, относящуюся к процессу. Управляющий блок процесса служит областью запоминания процесса для хранения состояния машины, а также ID процесса, состояния процесса, кода, показывающего, как и почему процесс переведен в текущее состояние, и т. д.
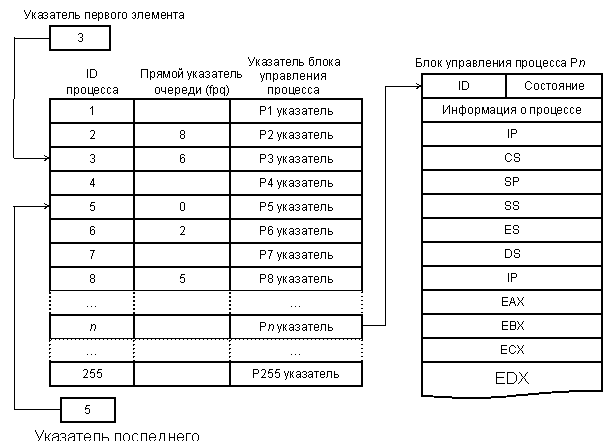

Рис. 7.5. Структура очереди процессов
Когда ЦП переключается с одного выполняющегося процесса на другой, монитор должен:
1. Запомнить машинное состояние выполняемого процесса в управляющем блоке процесса.
2. Модифицировать остальную часть блока управления процесса.
3. Взять ID следующего выполняемого процесса из указателя первого элемента.
4. Удалить процесс, только что переведенный в состояние выполнения, посредством установки указателя первого элемента равным fqp удаляемого элемента. Если текущая выполняемая программа должна быть в очереди процессов, находящихся в состоянии готовности, ее необходимо поместить в низ очереди и модифицировать указатель последнего элемента.
5. Изменить состояние процесса, только что выбранного из списка готовности, на состояние выполнения и восстановить машинное состояние данного процесса.
В результате шага 5 новый выбранный процесс будет продолжаться с той точки, в которой он был приостановлен. Процесс, находящийся в системе, можно поместить в список готовности, реализуя следующие действия:
1. Сохранить ID этого процесса в ftp текущего последнего элемента (элемента, адресуемого указателем последнего элемента) и в указатель последнего элемента.
2. Сбросить fqp в элементе таблицы данного процесса.
3. Модифицировать управляющий блок этого процесса.
Очень часто, особенно при обработке данных в реальном времени, необходимо назначать различным процессам приоритеты, причем процессу, требующему самого быстрого обслуживания, назначается наивысший приоритет. Нескольким процессам можно назначить один и тот же приоритет и на каждом приоритетном уровне использовать стратегию FIFO. При этом в системе потребуется приоритетная таблица. Как показано на рис. 7.4, каждый элемент в этой таблице представляет собой приоритетный уровень и имеет два поля, одно из которых содержит указатель первого элемента приоритетного уровня, а другое — последнего. При изменении приоритета процесс необходимо удалить из его приоритетной цепочки и добавить в низ цепочки, имеющей его новый приоритет. Данное действие упрощается при наличии обратного указателя очереди (bqp), который ускоряет изменения приоритетов.
Для выбора следующего выполняемого процесса планировщик должен просматривать приоритетную таблицу, начиная с наивысшего приоритета, до обнаружения ненулевого указателя первого элемента, а затем удалить этот процесс из очереди готовности. Преимущество использования bpq заключается в возможности динамического изменения приоритета данного процесса. Предположим, что приоритет процесса x необходимо изменить на приоритет y. Сначала процесс x удаляется из его текуoей приоритетной цепочки с помощью следующих операций:
fqp(bqp(x)) <- fqp(x),
bqp(fqp(x)) <- bpq(x)
Конечно, если процесс x является верхним или нижним элементом в его текущей приоритетной цепочке, потребуется дополнительная коррекция приоритетной таблицы. Затем процесс x добавляется в низ цепочки, соответствующей приоритетному уровню y. Это сопровождается модификацией указателя последнего элемента (а также указателя первого элемента, если цепочка была пустой) fqp текущего последнего элемента в цепочке, а также fqp и bqp добавляемого элемента.
Некоторые мультипрограммные операционные системы оказываются более сложными, чем показанная на рис. 7.4, и допускают более трех основных состояний процессов. Обычно в этом случае дополнительные состояния представляют собой другие формы заблокированного состояния.
7.3. Семафорные операции
В мультипрограммных системах процессам разрешается разделять общие программные, аппаратные и информационные ресурсы. Во многих ситуациях одновременно обращаться к общему ресурсу и модифицировать его может только один процесс, а другие процессы должны ожидать завершения его операций. Такой ресурс, обычно называемый последовательно используемым, должен быть защищен от одновременного доступа и модификации двумя или более процессами. Ресурсом этого типа может быть аппаратный ресурс (принтер, сканер, сетевая плата), файл данных или разделенная область памяти.
Рассмотрим, например, файл персонала, который разделяется процессами 1 и 2. Предположим, что процесс 1 выполняет введения, удаления и изменения, а процесс 2 упорядочивает файл в алфавитном порядке по фамилиям. При последовательном доступе файл либо модифицируется процессом 1, а затем сортируется процессом 2, либо наоборот, Однако, если разрешить обоим процессам одновременный доступ к файлу, результаты окажутся непредсказуемыми и почти наверняка неправильными. Решение данной задачи заключается в том, чтобы разрешить одновременно только одному процессу выполнять его критическую секцию кода, т. е. секцию кода, которая осуществляет доступ к последовательно используемому ресурсу.
Предотвращение ситуации, когда два и более процессов одновременно выполняют свои критические секции при доступе к разделенному ресурсу, называется взаимным исключением. Один из способов реализации взаимного исключения — использовать флажки.
Флажок, используемый для резервирования разделенного ресурса, называется семафором, а операции запроса и освобождения ресурса обычно называются семафорными операторами Р и V:
P: xor al, al
Check: xchg al, semaphore
test al, al
jz Check
Критическая секция
![]() …
…
…
…
V: mov semaphore,1
Если semaphore = 1 при выполнении команды xchg, он сбрасывается, а в al оказывается 1. Даже если система переключает процессы после команды xchg, новый процесс не сможет войти в свою критическую секцию, так как semaphore уже сброшен. Такое решение стало возможным благодаря загрузке и установке операнда одной командой (именно командой xchg) и может быть применено к любому числу процессов.
Как видно из приведенного примера, оператор Р легко реализуется командами xor, xchg, test и jz, а оператор V — командой mov. Однако, при такой реализации, когда один процесс находится в критической секции, другие процессы, претендующие на тот же самый ресурс, будут простаивать в циклах ожидания операторов Р, что приводит к значительным потерям времени.
Для лучшего использования времени ЦП операторы Р и V следует модифицировать следующим образом:
P: xor al, al
xchg al, semaphore
test al, al
jnz Use
Перевод текущего процесса в заблокированное состояние
![]() …
…
…
…
jmp P
Критическая секция
![]() Use: …
Use: …

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
