

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
…
…
V: mov semaphore,1
Разблокирование процессов, ожидающих светофора
![]() …
…
…
…
Если семафор сброшен, вместо повторения цикла ожидания текущий процесс переводится в заблокированное состояние, а ЦП начинает выполнять выбранный процесс, находящийся в состоянии готовности. Аналогично в операторе V после установки семафора в 1 осуществляется пересылка процессов, которые были заблокированы из-за недоступности разделенного ресурса, из списка заблокированных процессов в список процессов, находящихся в состоянии готовности. Первый из этих процессов, который возобновляет выполнение, сможет войти в свою критическую секцию.
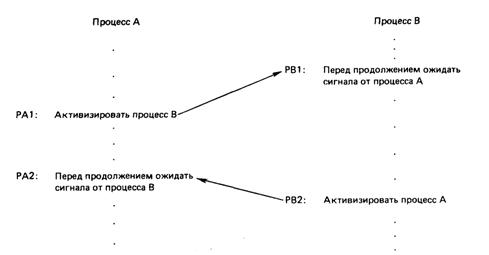
Рис. 7.6. Синхронизация процессов А и В
Рассмотренный метод не только экономит время ЦП, но может применяться для синхронизации двух процессов или для передачи сообщения от одного процесса другому. На рис. 7.6 процессы А и В должны взаимодействовать в определенных точках. Они могут выполняться в режиме с разделением времени до тех пор, пока процесс В не достигает точки РВ1, где он должен ожидать сообщения или обращаться к результатам, полученным процессом А. После точки РА1 оба процесса вновь выполняются в режиме разделения времени до достижения точки РА2. В этой точке процесс А должен получать сообщение от процесса В или синхронизироваться с ним.
7.4. Разделение общих процедур
В мультипрограммной системе желательно, чтобы несколько пользователей могли разделять процедуры. Такими процедурами, называемыми общими, обычно являются библиотечные или системные программы, например драйверы ввода-вывода, процедуры преобразований кодов и т. п. Например, несколько пользователей могут одновременно пожелать редактировать свои программы с помощью редактора текста. Если не разделять код, в память придется загрузить несколько копий редактора. При разделении кода потребуется иметь в памяти только одну копию, что дает значительную экономию объема памяти.
Общую процедуру можно разделять последовательно, как и любой другой разделяемый ресурс. Обычным образом перед вызовом общей процедуры вызывающая процедура должна выполнить оператор Р, а после выхода из нее - оператор V, чтобы сделать разделенную процедуру доступной другим пользователям. При последовательном разделении главное дополнительное требование заключается в том, что все локальные переменные в процедуре должны реинициализироваться, чтобы не использовались их значения от предыдущего вызова. Следовательно, последовательно разделяемая процедура должна инициализировать сама себя в начале каждого вызова.
Применение последовательно разделяемых процедур довольно ограничено, так как требуется более универсальная форма разделения, т. е. форма, в которой процедура разделяется с мультиплексированием во времени (становится параллельно используемой). Эта форма означает: процедура должна быть такой, чтобы ее смог вызвать другой процесс до завершения выполнения процедуры от предыдущего вызова. Такая процедура называется реентерабельной (реентрантной, повторно вызываемой). Реентерабельная процедура должна состоять из кода, называемого чистым, который не модифицирует сам себя. Для удовлетворения этого требования реентерабельная процедура может хранить модифицируемые данные только в ячейках памяти, которые ассоциируются с вызывающим процессом; она не может даже временно хранить такие данные в ячейках, являющихся для нее локальными. Для иллюстрации предположим, что ТЕМР является локальной переменной в реентерабельной процедуре и что она используется для хранения промежуточного результата, и рассмотрим такую последовательность событий:
1. Процесс 1 выполняется и вызывает реентерабельную процедуру.
2. Реентерабельная процедура помещает промежуточный результат в ТНМР.
3. Процесс 2 получает управление процессором.
4. Процесс 2 вызывает реентерабельную процедуру.
5. Реентерабельная процедура вновь помещает промежуточный результат в TEMP.
Очевидно, в этой точке первоначальный промежуточный результат разрушается, следовательно, при возврате в процесс 1 и возобновлении реентерабельной процедуры процесс 1 сформирует неправильный результат.
Чтобы решить данную задачу, все результаты, включая и содержимое регистров, должны храниться в ячейках, ассоциированных с вызывающим процессом. В приведенном примере два промежуточных результата необходимо поместить в отдельные ячейки, одна из которых ассоциирована с процессом 1, а другая — с процессом 2. Для хранения многих копий промежуточных результатов по принципу LIF0 применялся один и тот же стек, так как рекурсивные вызовы сопровождаются возвратами в обратном порядке. Здесь же информация запоминается в вызывающем процессе.
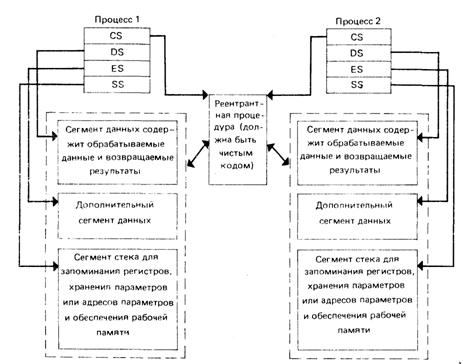
Рис. 7.7. Реентерабельная процедура, разделяемая двумя процессами
В процессорах, имеющих стек, обычный способ хранения промежуточных результатов заключается в том, чтобы ассоциировать стек с каждым процессом. На рис. 7.7 показано, как два процесса обращаются к реентерабельной процедуре. Когда процесс 1 вызывает реентерабельную процедуру, содержимое регистров SS и SP не изменяется и реентерабельная процедура запоминает любые свои результаты в стеке процесса 1. Когда происходит переключение процессов, содержимое SS и Spизменяется с тем, чтобы адресовать вершину стека, ассоциированного с процессом 2. Когда вновь вызывается реентерабельная процедура, она будет запоминать свои результаты в стеке, ассоциированном с процессом 2, а предыдущие результаты не искажаются.
Так как переключение между процедурами модифицирует и содержимое регистров DS и ES, эти регистры также можно использовать для хранения информации вызывающего процесса. По существу, можно реализовать любую приемлемую связь подпрограмм с единственным требованием, что никакие, данные нельзя хранить локально в реентерабельной процедуре.
Чистый код в реентерабельной процедуре должен быть еще и позиционно-независимым, т. е, он может правильно выполняться независимо от его размещения в физической памяти или относительно вызывающих его процессов. Во всех локальных обращениях должна применяться какая-либо разновидность косвенной адресации или код должен корректировать свои локальные адреса в соответствии с текущим размещением. Лучшим методом образования позиционно-независимого кода оказывается относительная адресация, которая в ЦП реализуется с помощью сегментных регистров. Требование позиционной независимости реентерабельных процедур объясняется тем, что они разделяются несколькими процессами и обычно во время выполнения динамически связываются с различными процедурами. Такая связь упрощается, если адреса в реентерабельном коде модифицировать не нужно.
7.5. Управление памятью
Совместный набор программных единиц, которые объединены друг с другом, но не обращаются к единицам вне набора, кроме обращений через внешнюю память, называется заданием (или программой). Чтобы эффективно использовать системные ресурсы и достичь максимальной параллельности работы ЦП и ввода-вывода, желательно хранить в памяти максимальное число заданий. Следовательно, при проектировании мультипрограммной системы важное значение приобретает управление памятью так, чтобы свести к минимуму неиспользуемое пространство памяти.
Простейший способ хранения в памяти нескольких заданий заключается в распределении разделов. В этом способе каждому заданию назначается смежная область памяти. Когда необходимо выполнить задание, загрузчик запрашивает необходимый объем памяти у процедуры управления памятью, которая является частью операционной системы, отвечающей за распределение памяти. Если эта процедура находит свободную смежную область, размер которой больше размера задания, она возвращает загрузчику начальный адрес этой свободной области. После коррекции необходимых относительных адресов, такой, что они превращаются в физические адреса, загрузчик помещает задание в распределенную область. Конечно, начальным состоянием задания является "готовность" и допускается, что задание начинает выполняться не сразу. Если же достаточной смежной области нет, задание должно ожидать до тех пор, когда его будет можно загрузить из внешней памяти.
Способ распределения разделов требует организации в процедуре управления памятью так называемой таблицы карты памяти. Возможная реализация этой таблицы заключается в том, чтобы каждому разделу соответствовал элемент таблицы. Каждый элемент таблицы должен содержать состояние, размер и начальный адрес раздела; раздел может быть в таких состояниях:
Распределен. Раздел в данное время распределен заданию.
Свободен. Раздел доступен для использования.
Не используется. Элемент не ассоциирован с разделом.
Третье состояние может возникнуть в том случае, когда два соседних свободных раздела объединены в один.
Получив запрос на распределение памяти, процедура управления памятью проверяет размер каждого свободного раздела, начиная с верха таблицы. Если обнаруживается свободный раздел, размер которого равен или больше запрошенного раздела, его состояние изменяется на "распределен" и возвращется его начальный адрес. В том случае, если запрошенный объем памяти меньше объема раздела, для учета лишнего пространства в таблицу добавляется новый свободный раздел. Данный алгоритм выбора свободного раздела называется алгоритмом первого соответствия. В другом алгоритме — алгоритме наилучшего соответствия — просматривается вся таблица для нахождения наименьшего свободного раздела, удовлетворяющего запросу.
Когда задание завершено, занятая им область возвращается в систему. Процедура управления памятью модифицирует таблицу карты памяти, чтобы отразить возможное слияние соседних свободных разделов, появляющихся при освобождении памяти. Две возможные ситуации, вызывающие слияние, представлены на рис. 7.8. В случае 1 освобожденный раздел оказывается соседним с имеющейся свободной областью. После слияния два свободных раздела объединены в один большой раздел, начальный адрес которого равен меньшему из двух первоначальных свободных адресов. В случае 2 две имеющиеся свободные области разделены освобожденным разделом. В результате слияния три раздела объединяются в один. Слияние необходимо для того, чтобы иметь максимальные размеры свободных разделов.
Основные достоинства способа распределения разделами — простота и отсутствие специальных аппаратных средств. Однако по мере завершения заданий и загрузки новых заданий начинают появляться все меньшие и меньшие области памяти — возникает проблема фрагментации (рис. 7.9, а) . При большом числе таких небольших свободных областей система не сможет загрузить задание, даже если общий объем доступного пространства достаточно велик; иначе говоря, значительная часть памяти не используется.
Один из способов решения проблемы фрагментации заключается в том, чтобы объединить все свободные области в одну, "сжимая" или "уплотняя" находящиеся в памяти задания. как показано на рис. 7.9, б. Так реализуется способ распределения разделов с перемещением. Но для его применения компьютер должен иметь возможность корректировать каждое задание так, чтобы после его перемещения из одной области в другую можно было правильно возобновить выполнение задания.
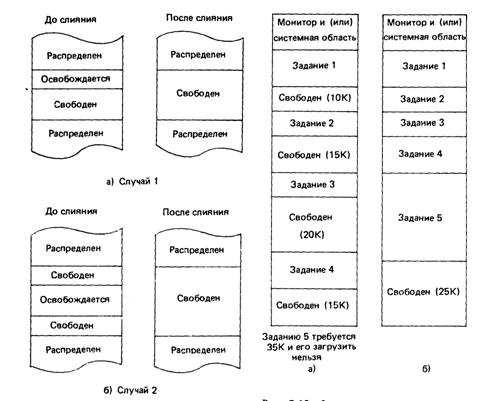
Рис. 7.8. Слияние свободных разделов Рис. 7.9. Фрагментация памяти (а)
и загрузка задания (б)
В ЦП все физические адреса формируются сложением эффективных и сегментных адресов, умноженных на 16. причем сегментные адреса берутся из сегментных регистров. Такой способ позволяет легко преобразовать программу в позиционно-независимый код и пересылать ее из одной области памяти в другую без модификации машинного кода. При выполнении перемещения монитор должен скорректировать сегментные адреса (т. е. содержимое сегментных регистров).
Чтобы обеспечить позиционную независимость, сегментными регистрами должна управлять только процедура управления памятью, а программа не должна их модифицировать. Кроме того, все вызовы процедур и переходы должны иметь тип near. В противном случае, если CS был запомнен вызовом до перемещения, а возврат осуществляется после перемещения, CS будет содержать старый сегментный адрес и программа возвратится в неправильное место. Так как переместимой программе не разрешается модифицировать сегментные регистры, задание может иметь максимум четыре сегмента (кода, данных, дополнительных данных и стека) и максимальный размер задания ограничен 4 х 64К= 256K.
Так как при уплотнении операционная система должна пересылать задания из одной области памяти в другую, на уплотнение расходуется много времени и без необходимости его выполнять не следует. В способе распределения разделов с перемещением обычным образом процедура управления памятью распределяет пространство и организует таблицу карты памяти, как и в способе распределения разделов. Однако, если нельзя найти одну свободную область больше запрошенного размера, операционная система должна определить, достаточно ли всего свободного объема памяти. Если это так, инициируется процесс уплотнения, в котором корректируются базовые адреса всех заданий (они определяются запомненным содержимым сегментных регистров) и соответственно модифицируется таблица карты памяти.
Контрольные вопросы
1. Назовите и опишите классы МПС по Флинну.
2. Что такое МПС с общей памятью?
3. Что такое МПС с индивидуальной памятью?
4. Что вызывает некорректность вычислений в ВМ с общей памятью?
5. Каковы достоинства и недостатки ВМ с передачей сообщений?
6. Что такое кластер?
7. В чем состоит принципиальное отличие кластеров от систем MPP?
8. В чем заключается основное назначение мультипроцессорных систем?
9. Объясните различия в SIMD и MIMD технологиях.
10. Что такое кластер? Где используются кластеры?
11. Какие языки программирования следует использовать для ВС типа MSIMD?
12. В чем заключаются основные свойства мультипрограммной среды?
13. Что такое пропускная способность МПС?
14. Что такое процесс и в каких состояниях он может находиться?
15. Как и для чего используются семафоры?
16. Поясните работу семафорных операторов.
17. Какими свойствами должна обладать реентерабельная процедура?
18. В чем состоит проблема фрагментации?
19. Как реализуется способ распределения разделов с перемещением?
8.1. Процессор ввода-вывода
Для организации обмена данными в вычислительных системах обычно используются различные контроллеры, позволяющие согласовывать работу того или иного ВУ с работой системы. Примерами могут служить контроллеры ПКП и ПДП. В функции контроллеров входит анализ сигналов от ВУ, дешифрация адреса ВУ, адресация памяти (для ПДП), синхронизация обмена, согласование форматов данных, выдача управляющих сигналов и т. д. Чем шире многообразие ВУ, тем большее число различных контроллеров необходимо для их обслуживания. Специфика ВС состоит, в частности, в использовании большого числа специализированных ВУ, что заставляет каждый раз проектировать соответствующий контроллер. Кроме того, помимо функций управления ВУ и передачей данных на эти контроллеры возлагают дополнительные функции по предварительной обработке передаваемых данных (например, кодирование, декодирование, анализ условий окончания передачи).
Для снижения трудоемкости проектирования и повышения эффективности системы ввода-вывода в ВС, создаваемых на основе ЦП Intel 8086, удобно использовать специализированный процессор ввода-вывода Intel 8089. Этот процессор сочетает в себе свойства универсальноro контроллера ПДП со свойствами специализированного процессора, который позволяет осуществлять различные преобразования данных во время пересылок.
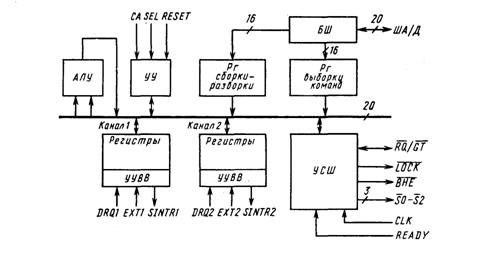
Рис. 8.1. Архитектура процессора ввода-вывода Intel 8089
Процессор ввода-вывода (ПВВ) имеет два канала ввода-вывода, каждый из которых может осуществлять высокоскоростные пересылки в режиме ПДП с одновременным преобразованием пересылаемых данных. ПВВ удобно рассматривать как два независимых канала, каждый из которых может находиться в одном из трех основных режимов работы: простаивать (пассивное состояние), выполнять программу канала и осуществлять пересылку в режиме ПДП.
По способу «общения» ЦП с ПВВ различают два режима взаимодействия: начальная инициализация и управление.
Общее устройство управления УУ обеспечивает начальную инициализацию ПВВ. По включении питания или сигналу начальной установки RESET центральный процессор подготавливает в памяти ряд связанных друг с другом блоков (рис. 8.2) с сообщениями для ПВВ. После этого ЦП выдает сигналы СА (готовность канала) и SEL (выбор канала), запрашивающие готовность каналов. По сигналу СА сопроцессор прекращает какие-либо действия и анализирует сигнал SEL, указывающий номер канала (1 или 2), которому предназначается сообщение. Когда канал выбран, ПВВ исследует слово управления каналом CCW, которое задает режим работы канала (простаивание, программа канала, пересылка с ПДП). Если управляющее слово требует запуск выполнения программы, то ПВВ загружает адреса блока параметров и блока заданий во внутренние регистры соответствующего канала, устанавливает флаг занятости BUSY и переходит к выполнению программы канала.
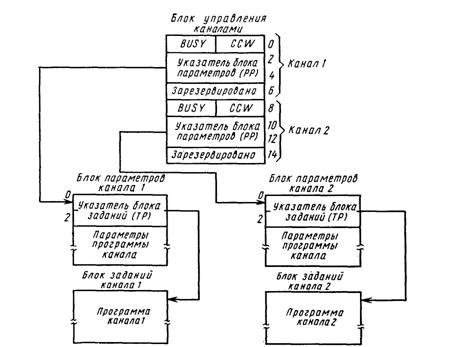
Рис. 8.2. Структура блоков сообщений при начальной инициализации ПВВ
Центральный процессор после выдачи сигнала СА освобождается для выполнения другой работы. После окончания выполнения программы канал сбрасывает флаг занятости BUSY в блоке управления. Таким образом, взаимодействие ЦП и ПВВ строится по схеме, показанной на рис. 8.3. При необходимости ПВВ может выдать запрос прерывания в ЦП.
По способу организации ВС, включающей ЦП и ПВВ, различают два вида конфигурации системы: местную и удаленную. Местная конфигурация характеризуется тем, что ЦП и ПВВ совместно используют системные шины, в то время как при удаленной конфигурации шина ввода-вывода «удалена» от ЦП и ПВВ может обращаться к ВУ, не используя общую системную шину. Таким образом, удаленная конфигурация повышает степень параллельности работы ЦП и ПВВ и увеличивает производительность ВС.
ПВВ может обращаться к элементам памяти, расположенным в двух различных пространствах адресов. Системное пространство, совпадающее с пространством памяти ЦП, может содержать до 220 = 1048676 байт. Пространство ввода-вывода, которое также может совпадать с пространством ввода-вывода ЦП или быть принадлежностью только ПВВ, содержит до 216 =байт. Когда пространства ввода-вывода ЦП и ПВВ не совпадают, говорят, что ВС имеет удаленную конфигурацию.
Поскольку ВУ можно кодировать как адреса памяти, то в обоих пространствах могут размещаться как устройства памяти, так и ВУ. Причем ВУ, расположенные в системном пространстве, являются отображенными на память, а память, расположенная в пространстве ввода-вывода, оказывается отображенной на ввод-вывод. С точки зрения программирования оба пространства памяти ПВВ организованы как несегментированные массивы, состоящие из индивидуально адресуемых байтов. Команды и данные могут размещаться в любых адресах без выравнивания, т. е. без предпочтительного размещения младшего байта по четному адресу. ПВВ «рассматривает» системное пространство иначе, чем ЦП, с которым он совместно использует это пространство. Центральный процессор, как было ранее показано, делает различие между логическим адресом памяти, состоящим из 16-разрядного начального адреса сегмента и 16-разрядного смещения в сегменте, и ее физическим 20-разрядным адресом. ПВВ игнорирует логическую сегментированную структуру пространства памяти и пользуется только 20-разрядным физическим адресом. Память, расположенная в пространстве ввода-вывода ПВВ, рассматривается аналогично, за исключением того, что для обращения к любой ячейке требуется только 16 разрядов адреса.
Схема сопроцессора (рис. 8.1) подразделена на ряд функциональных узлов, которые соединяются между собой 20-разрядной шиной, обеспечивающей максимальную скорость внутренних пересылок.
Общее устройство управления. Устройство управления (УУ) координирует работу сопроцессора, определяя приоритеты каналов, синхронизируя циклы выполнения команд, пересылки с ПДП, ответы на запросы готовности канала. В частности, под управлением общего УУ выполняется начальная инициализация сопроцессор а.
Арифметико-логическое устройство (АЛУ). Может выполнять арифметические операции над 8- и 16-разрядными двоичными числами, причем длина результата может доходить до 20 разрядов. Имеются арифметические команды сложения, увеличения и уменьшения на единицу, а также логические операции И, ИЛИ и НЕ.
Регистры сборки-разборки. Служат для выполнения пересылки данных за минимально возможное число циклов работы с шиной, когда данные пересылаются между шинами разной разрядности. Например, при пересылке с ПДП данных от 8-разрядного ВУ в 16-разрядную память сопроцессор выполняет два цикла работы с шиной, принимая 8 разрядов за каждый цикл, собирает 16-разрядное слово, а затем пересылает это слово в память за один цикл.
Регистр выборки команд. Служит для хранения команд, выбираемых из памяти для работающего канала. Команды поступают по 16-разрядной шине данных через буфер шины (БШ) и запоминаются в этом регистре в виде очереди из байтов команд. Каждый канал имеет свою собственную очередь, и работа одного канала не влияет на очередь другого канала. Преимущества использования внутренней очереди из байтов команд были показаны для ЦП.
Устройство сопряжения с шиной (УСШ). Управляет всеми циклами работы с ША/Д, пересылая команды и данные между сопроцессором и памятью или ВУ. Устройство сопряжения с шиной выдает сигналы управления S2, Sl и S0, которые затем декодируются системным контроллером Intel 8288. При работе с сопроцессором контроллер вырабатывает управляющие сигналы, аналогичные тем, которые формируются при работе с ЦП. Кроме пересылок УСШ осуществляет управление совместным использованием шин СП и ЦП путем формирования и анализа сигнала RQ/GT - запроса и предоставления шины. В функции УСШ входит также формирование сигналов LOCK - захват шины и ВНЕ - разрешение старшего байта.
Рассмотрим особенности организации каналов сопроцессора.
Устройство управления вводом - выводом (УУВВ) . Имеется в каждом канале, выполняет следующие функции:
· если пересылка синхронная, то УУВВ ожидает поступления сигнала по
входу DRQ (запрос ПДП) перед выполнением очередного цикла чтения - записи;
· если пересылка должна заканчиваться при получении внешнего
сигнала, то УУВВ наблюдает за поступлением сигнала по входу ЕХТ (внешнее окончание);
· между циклами чтения и записи, когда данные находятся в ПВВ, канал
может подсчитать, перекодировать и проанализировать данные, причем УУВВ может прекратить пересылку на основании результатов этих операций;
· УУВВ имеет выход SINTR (системное прерывание), который может
быть активизирован программно для передачи запроса прерывания в ЦП.
8.2. Программная модель процессора ввода-вывода
Как известно, к программной модели любого процессора относят те узлы, которые доступны для использования из программы. В первую очередь такими узлами являются регистры.
Регистры канала. На рис. 8.3 представлены программно доступные регистры канала и указано их стандартное назначение. Использование каждого из этих регистров при выполнении каналом программы или пересылок в режиме ПДП указано в табл. 8.1.
Регистры GA, GB и GC могут использоваться программой в качестве регистров общего назначения или регистров базы. При организации ПДП до начала пересылки регистр GA (GB) должен быть загружен адресом источника или приемника данных. Регистры GA и GB функционально взаимозаменяемы. Если при ПДП регистр GA указывает на источник, то регистр GB указывает на приемник и наоборот. Регистр GC при ПДП применяется в том случае, когда пересылаемая информация должна быть перекодирована. Для этого регистр GC до начала пересылки должен быть загружен начальным адресом таблицы перекодировки.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
