

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
· al = 0 – если MMX и SSE не поддерживаются;
· al = 1 – поддерживается только MMX;
· al = 2 – поддерживается только SSE;
· al = 3 – поддерживается MMX и SSE.
6.4. Директивы языка ассемблера ASM-89
При составлении программ для ПВВ используется язык ASM-89. Этот язык также включает операторы двух типов: команды и директивы. На рис. 6.3 приведены примеры форматов команд и директив.
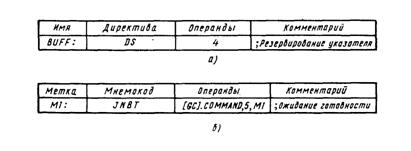
Рис. 6.3. Поля операторов языка ASM-89: a - директив; б - мнемокодов команд
Для определения типов переменных, используемых в программе, предназначены директивы DB и DD, аналогичные директивам АSМ-86. Наряду с ними для резервирования области ОЗУ применяется директива DS, позволяющая только резервировать (без задания начальных значений) произвольное число байтов. Особенности написания мнемокодов команд ПВВ, в зависимости от способов адресации приведены в табл. 6.1.
В программах для ПВВ часто встречаются структуры данных, приведенные на рис. 6.4,а, для организации которых предусмотрена специальная директива STRUC, позволяющая присваивать имена и относительные адреса набору связанных друг с другом переменных, которые называют элементами структуры.
Таблица 6.1
№ п/п | Способ адресации | Примеры мнемокода команды |
1 | По базе | ADD GC, [GB] |
ADDBI [PP], 12 | ||
2 | Со смещением | ADDB IX, [GB].5 |
ADDB ВС, [GC].COUNT | ||
3 | Индексная | ADD [GC+ IX], BC |
4 | Индексная с автоинкрементом | ADDI [GC+IX+],5 |
Задание структуры, показанной на рис. 6.4,а, с помощью директивы STRUC имеет вид:
PARMBLOCK STRUCT
TP: DS 4
COMMAND: DS 1
RESULT: DS 1
BUFFER1: DS 4
BUFFER2: DS 2
PARMBLOCK ENDS
Данной структуре присвоено имя РАRМВLОСК и она является блоком параметров, который включает указатель задания TP размерностью 4 байта, параметр COMMAND (1 байт), параметр RESULT (1 байт), два параметра BUFFER1 (4 байта) и BUFFER2 (2 байта). Имя структуры указывается перед директивой STRUC и перед директивой ENDS, определяющей конец структуры.
|
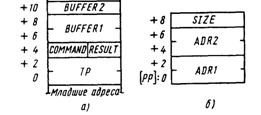
Рис. 6.4. Размещение параметров структуры в памяти
Важно отметить, что задание структуры. не распределяет конкретные адреса памяти, а лишь определяет взаимное расположение ее элементов. Программа-ассемблер использует имена элементов структуры для определения величины смещения адреса соответствующего элемента от начального адреса структуры. Так, если начальный адрес структуры находится в регистре-указателе параметров РР, то обращение к элементам структуры в программе на языке ассемблера будет иметь вид:
LPD GA, [PP].BUFFERl
MOVBI [РР].RESULT, 0
\
Здесь первая команда загружает содержимое элемента структуры BUFFERl в регистр GA, а вторая команда обнуляет элемент структуры RESULT. Эти же операции можно выполнить и с помощью команд
LPD GA, [PP] . 6
MOVBI [РР]. 5,0
соответственно. Однако организация структуры, позволяющей обращаться к ее элементам по их именам, делает программу более понятной и облегчает ее написание и отладку.
Программа, написанная на языке ASM-89, может включать обращения к программам с помощью команды САLL (или LCALL). Первый операнд этих команд всегда задает адрес памяти, по которому должно быть сохранено значение регистра перед передачей управления вызываемой подпрограмме. Второй операнд этих команд содержит имя подпрограммы, определяющее ее начальный адрес. Возврат из подпрограммы осуществляется, как правило, с помощью команды MOVP, восстанавливающей содержимое регистра ТР из области сохранения. Ниже представлен фрагмент программы, которая использует команду вызова подпрограммы:
SAVE: DS 3 ; задание области сохранения
LPDI GC,SAVE ; загрузка адреса в GC
LCALL [GC],Donna ; вызов подпрограммы Donna
. . . ; тело программы
HLT ; завершение программы
Donna: . . . ; вход в подпрограмму Donna
. . . ; тело подпрограммы
MOVP TP,[GC] ; возврат из подпрограммы
Следует отметить, что подпрограмма Donna не должна изменять содержимое регистра GC, поскольку оно указывает на адрес возврата.
В качестве примера рассмотрим две программы на языке ASM-89. Первая программа предназначена для пересылки блока информации из области памяти с начальным адресом ADR1 в область памяти с начальным адресом АDR2. Число пересылаемых байтов (до 64К байт) задается параметром SIZE. Исходные данные размещаются в памяти в виде простой структуры, представленной на рис. 6.4,б, с начальным адресом, указанным в регистре-указателе PP. Программа имеет вид
1 MEMTRANS SEGMENT
2 PB STRUCT
3 TPRESERV: DS 4
4 ADR1: DS 4
5 ADR2: DS 4
6 SIZE: DS 2
7 PB ENDS
8 LPD GA,[PP].ADR1
9 LPD GB,[PP].ADR2
10 MOV BC,[PP].SIZE
11 MOV CC,0C208h
12 XFER
13 WID 16,16
14 HLT
15 MEMTRANS ENDS
16 END
В строке 1 используется директива SEGMENT, которая указывает на начало программы и присваивает ей имя MEMTRANS. В строках 2 - 7 описывается структура исходных данных, соответствующая рис. 6.4, б. В строках 8, 9 начальные адреса ADRI и ADR2 областей памяти, между которыми осуществляется пересылка данных, загружаются в регистры GA и GB, соответственно. В строке 10 в счетчик байтов ВС загружается число пересылаемых байтов. Для указанных загрузок используется адресация со смещением. Далее, в строке 11, в регистр управления каналом СС загружается константа, которая задает требуемый режим пересылки.
6.5. Модели программ, компиляция и отладка
На практике различают несколько моделей, используемых при написании программ. Существенное отличие моделей состоит в том, что каждая из них предполагает наличие различного числа сегментов и способов группирования программных сегментов и сегментов данных. Ниже перечислены используемые модели и даны их краткие характеристики (код – означает программный сегмент):
TINY - код и данные в одной группе (com - файлы );
SMALL - код – один сегмент, данные в одной группе;
MEDIUM - код – несколько сегментов, данные в одной группе;
COMPACT - код один сегмент, ссылка на данные – типа far;
LARGE - код – несколько сегментов, данные - типа far;
FLAT - код и данные в одном сегменте (плоская модель).
Для получения исполняемого файла программы составленной на ассемблере надо реализовать, по крайней мере, два этапа – осуществить трансляцию программы и получить объектный модуль с расширением obj, а затем скомпоновать объектные модули в исполняемую программу, с расширением exe (или com). Реализация первого этапа осуществляется с помощью программы MASM (или TASM), а второго – с помощью LINK (или TLINK). В ряде случаев, особенно при разработке сложных программ, состоящих из большого числа модулей, бывает не обойтись без специальных средств отладки, типа турбодебагера td.
Пусть текст исходной программы хранится в файле с именем SIMPLE. ASM. Трансляцию можно осуществить вызовом турбо ассемблера TASM. EXE с помощью, например, следующей команды DOS:
tasm /z/zi/n simple, simple, simple
Ключ /z разрешает вывод на экран строк исходного текста программы, в которых ассемблер обнаружил ошибки (без этого ключа поиск ошибок пришлось бы проводить по листингу трансляции).
Ключ /zi управляет включением в объектный файл информации, не требуемой при выполнении программы, но используемой отладчиком.
Ключ /n подавляет вывод в листинг перечня символических обозначений в программе, от чего несколько уменьшается информативность листинга, но сокращается его размер.
Стоящие далее параметры определяют имена файлов: исходного (SIMPLE. ASM), объектного (SIMPLE. OBJ) и листинга (SIMPLE. LST). При желании можно в строке вызова транслятора указать полные имена файлов с их расширениями, однако необходимости в этом нет, так как по умолчанию транслятор использует именно указанные выше расширения.
Важную роль при отладке программы на стадии трансляции играют ключи, которые управляют как процессом ассемблирования, так и полнотой листинга – файла с расширением LST, существенно облегчающего отладку программы.
Контрольные вопросы
1. Может ли регистр использоваться в фактическом параметре макровызова?
2. Чем отличается команда от директивы?
3. Придумайте, как программисты на ассемблере могут определить синонимы для мнемокодов команд. Как это можно реализовать?
4. Перечислите модели ассемблерных программ и укажите их особенности и основные отличия.
5. Перечислите все директивы определения данных и дайте примеры их использования.
6. Объясните назначение вспомогательной директивы DUP и приведите пример ее использования.
7. Какая директива определения данных используется под вещественные числа в формате ДВФ?
8. Приведите примеры использования директивы EQU.
9. Укажите все возможные способы передачи параметров процедуре.
10. Как расширились возможности регистров данных в процессоре Pentium, для целей адресации?
11. Расширилось ли число способов адресации в процессоре Pentium по отношению к Intel 8086 и на сколько?
12. Для чего используются директивы определения данных?
13. Какие директивы используются для определения данных в формате ВВФ?
14. Как осуществляется передача параметров в макросах?
15. В чем отличие в использовании макросов и процедур?
16. Приведите пример использования макросов – блоков повторения.
17. Для чего используются директивы условного ассемблирования?
18. Дайте сравнительную характеристику моделей программ.
19. Как можно узнать о том, выполняет ли ЦП команды ММХ и SSE?
20. В каких случаях используется директива PURGE?
21. Назовите отладчики, которые Вы знаете? Чем они отличаются?
22. Зачем нужен файл с расширением LST (листинг)?
23. Какую модель программы Вы использовали при выполнении лабораторных работ и почему?
24. Для чего служит программа debug.exe?
25. На каком этапе осуществляется «вставка» библиотечных процедур?
26. Существуют ли, какие-либо особенности использования команд ММХ и SSE в программах на ассемблере?
7.1. Мультипроцессорные системы
В мультипроцессорных системах (МПС) имеется несколько процессоров, каждый из которых может относительно независимо от остальных выполнять свою программу. В МПС существует общая для всех процессоров операционная система, которая оперативно распределяет вычислительную нагрузку между процессорами. Важным свойством МПС является отказоустойчивость, то есть способность к продолжению работы при отказах некоторых элементов, например процессоров или блоков памяти. При этом производительность, естественно, снижается, но не до нуля, как в обычных системах, в которых отсутствует избыточность.
Любая вычислительная система достигает своей наивысшей производительности благодаря использованию высокоскоростных процессорных элементов (ПЭ) и параллельному выполнению большого числа операций.
Параллельные ВМ часто подразделяются по классификации Флинна на машины типа SIMD (Single Instruction Multiple Data - с одним потоком команд при множественном потоке данных) и MIMD (Multiple Instruction Multiple Data - с множественным потоком команд при множественном потоке данных). Можно выделить четыре основных типа архитектуры систем параллельной обработки:
Конвейерная и векторная обработка. Основу конвейерной обработки составляет раздельное выполнение операций в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько операций. Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых операндов соответствует максимальной производительности конвейера. Если происходит задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Идеальную возможность полной загрузки вычислительного конвейера обеспечивают векторные операции.
Машины типа SIMD. Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все ПЭ в такой машине выполняют одну и ту же программу. Очевидно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных. Модели вычислений на векторных и матричных ВМ настолько схожи, что эти ВМ часто рассматриваются как эквивалентные.
Машины типа MIMD. Термин "мультипроцессор" покрывает большинство машин типа MIMD и (подобно тому, как термин "матричный процессор" применяется к машинам типа SIMD) часто используется в качестве синонима для машин типа MIMD. В МПС каждый процессорный элемент выполняет свою программу независимо от других ПЭ. Процессорные элементы, конечно, должны как-то связываться друг с другом, и в МПС с общей памятью (сильносвязанных) имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ связываются с помощью общей шины или сети обмена. В противоположность этому варианту в слабосвязанных МПС (машинах с локальной памятью) вся память делится между ПЭ и каждый блок памяти доступен только связанному с ним процессору. Сеть обмена связывает процессорные элементы друг с другом.
МПС с SIMD-процессорами. Многие современные ВС представляют собой многопроцессорные системы, в которых в качестве процессоров используются векторные процессоры или процессоры типа SIMD. Такие машины относятся к машинам класса MSIMD.
Языки программирования и соответствующие компиляторы для машин типа MSIMD обычно обеспечивают языковые конструкции, которые позволяют программисту описывать параллелизм. В пределах каждой задачи компилятор автоматически векторизует подходящие циклы.
Основной характеристикой параллельных МПС является ускорение R, определяемое выражением
R = T1 / Tn ,
где T1 – время выполнения задачи на однопроцессорной ВМ; Tn – время выполнения той же задачи на n-процессорной ВМ.
Многопроцессорные системы за годы развития вычислительной техники претерпели ряд этапов своего развития. Исторически первой стала осваиваться технология SIMD. Однако в настоящее время наметился устойчивый интерес к архитектурам MIMD. Этот интерес главным образом определяется двумя факторами:
1. Архитектура MIMD дает большую гибкость: при наличии адекватной поддержки со стороны аппаратных средств и программного обеспечения. MIMD может работать как однопользовательская система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, как многопрограммная машина, выполняющая множество задач параллельно, и как некоторая комбинация этих возможностей.
2. Архитектура MIMD может использовать все преимущества современной МПС технологии на основе учета соотношения стоимость/производительность. В действительности практически все современные МПС строятся на тех же микропроцессорах, которые можно найти в персональных компьютерах, рабочих станциях и небольших однопроцессорных серверах.
Одной из отличительных особенностей МПС является сеть обмена, с помощью которой процессоры соединяются друг с другом или с памятью. Модель обмена настолько важна для МПС, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, соответствующим решаемым задачам. Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
