

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Определим коэффициент сходства между сортами 1 и 2 (см. таблицу – кодировка объектов).
![]()
Поясним, как было получено выражение в скобках. Производим сравнение двух сортов по всем модальностям. Так при сравнении сорта 1 и 2 по модальности А1 (зеленая) наблюдается несовпадение (А1 у 1-го сорта и а1 у 2-го. Следовательно, записываем «–1», поскольку, всякому несовпадению двух объектов по модальностям приписывается один и тот же вес «– 1». Далее сравниваем модальности А2 (антоциановая). Здесь также обнаруживается несовпадение (а2 у 1-го сорта и А2 у 2-го). Значит, записываем следующее слагаемое тоже «–1». При сравнении сорта 1 и 2 по модальности А3 (пестрая) наблюдается совпадение по отсутствию этой модальности (а3 у 1-го сорта и а3 у 2-го). Следовательно, записываем вес по отсутствию данной модальности, который равен 0,25. Аналогично определяются все слагаемые выражения в скобках.
Подобным образом вычисляют коэффициенты сходства между всеми парами сортов.
Помимо оценки сходства между всеми парами объектов в таксономическом анализе вычисляется для каждого объекта так называемый коэффициент оригинальности. Коэффициент оригинальности представляет собой среднюю сумму весов по присутствию и отсутствию модальностей каждого объекта исследуемой совокупности. Этот коэффициент является мерой оригинальности объекта, то есть, он будет тем больше, чем более редкими модальностями обладает объект. Анализ коэффициентов оригинальности может оказаться очень полезным, например, при оценке той или иной исходной коллекции сортов, линий или гибридов а именно, позволит отобрать образцы, сочетающие комплекс редких модальностей признаков.
Поясним это на примере. Определим коэффициент оригинальности для первого сорта, характеризующий этот сорт по наличию редких модальностей.
![]()
Аналогично вычисляют коэффициенты оригинальности для остальных сортов.
Теперь можно построить матрицу коэффициентов сходства и коэффициентов оригинальности (таблица)
Из полученных данных видно, что сорта 1 и 2 и 1 и 4 наиболее сходны между собой, поскольку у них максимальное значения коэффициента сходства (0,15). Сорта 1 и 3 наиболее сильно отличаются
№ | 1 | 2 | 3 | 4 | 5 |
1 | 0,68 | 0,15 | -0,69 | 0,15 | -0,26 |
2 | 0,15 | 0,68 | -0,16 | -0,38 | -0,26 |
3 | -0,69 | -0,16 | 1,61 | -0,16 | -0,58 |
4 | 0,15 | -0,38 | -0,16 | 0,68 | -0,26 |
5 | -0,26 | -0,26 | -0,58 | -0,26 | 1,41 |
по проанализированным признакам. Их коэффициент сходства самый маленький (-0,69). Из всех сортов наиболее оригинален сорт 3. Его коэффициент оригинальности составляет 1,61, что выше, чем у остальных сортов. Следовательно, этот сорт сочетает больше редких модальностей.
К полученной матрице коэффициентов сходства можно применить кластерный анализ. Этот метод позволяет последовательно объединять сорта сначала с максимальным коэффициентом сходства, а затем и менее сходные между собой. Результат кластерного анализа представляют в виде дендрограммы, характеризующей группировки объектов. Для полученной матрицы дендрограмма кластерного анализа имеет следующий вид
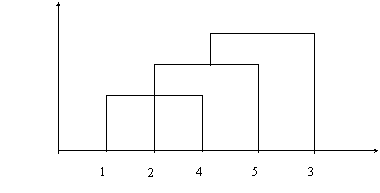
Кластерный анализ позволяет разделить изучаемую выборку объектов (в данном случае сортов) на группы, кластеры по степени сходства комплекса признаков. Результаты кластеризации оказываются полезными при решении многих сложных биологических проблем, в частности: 1) классификации таксонов разного ранга: родов, видов, разновидностей, форм, сортов, гибридов, линий, популяций и т. п.; 2) оценки сходства гибридов с родительскими формами; 3) подбора родительских форм для скрещиваний по степени их фенотипического сходства и др.
Кроме того, для выделения так называемых «плеяд» сходных объектов можно использовать метод максимального корреляционного пути, который будет рассмотрен ниже.
Ранговая шкала.
Наиболее мощным непараметрическим критерием для оценки различий между центральными параметрами (средними, медианами и т. п.) двух выборок является U-критерий Манна-Уитни.
Порядок вычисления этого критерия следующий:
1. Объединение двух групп наблюдений и ранжирование единой выборки. Но, в то же время, для каждого ранга необходимо помнить принадлежность к исходной группе.
2. Разделение единой выборки на две исходные группы, но уже в ранговой шкале.
3. Определение сумм рангов по каждой выборке.
4. Определение критерия для каждой группы по формулам
![]() ;
; ![]() ,
,
где n1 – объем первой выборки; n2 – объем второй выборки; ∑Ri(1) – сумма рангов первой выборки; ∑Ri(2) – сумма рангов второй выборки
Несложно показать, что U1=n1n2 – U2
5. Если найденные значения критерия (U1, U2) входят в интервал для пороговых значений UТ, то выборки не различаются по центральным параметрам.
Этот критерий можно использовать и для сравнения выборок, имеющих разный объем.
Пример. Необходимо сравнить две группы сеянцев вишни по устойчивости к коккомикозу. В таблице представлена сумма баллов поражения за 5 учетов в течение всей вегетации.
Группа 1 | 20 | 18 | 19 | 15 | 14 | 10 | 12 | 17 | 11 | |
Группа 2 | 16 | 11 | 9 | 13 | 13 | 11 | 7 | 13 | 9 | 8 |
n1 = 9
n2 = 10
Объединяем обе группы наблюдений и ранжируем в возрастающем порядке:
Суммарный балл | Ранг | Группа | Суммарный балл | Ранг | Группа |
7 | 1 | 2 | 13 | 11 | 2 |
8 | 2 | 2 | 13 | 11 | 2 |
9 | 3,5 | 2 | 14 | 13 | 1 |
9 | 3,5 | 2 | 15 | 14 | 1 |
10 | 5 | 1 | 16 | 15 | 2 |
11 | 7 | 2 | 17 | 16 | 1 |
11 | 7 | 2 | 18 | 17 | 1 |
11 | 7 | 1 | 19 | 18 | 1 |
12 | 9 | 1 | 20 | 19 | 1 |
13 | 11 | 2 | |||
Сумма | 190 |
Разделяем группы и определяем суммы рангов (жирный шрифт):
Группа 1 | 5 | 7 | 9 | 13 | 14 | 16 | 17 | 18 | 19 | 118 | |
Группа 2 | 1 | 2 | 3,5 | 3,5 | 7 | 7 | 11 | 11 | 11 | 15 | 72 |
U1= 9·10+9·(9+1)/==17
U2= 9·10+10·(10+1)/2 - 72=145 – 72=73

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
