

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Апробация работы
Основные положения работы докладывались и обсуждались на Томском IEEE семинаре "Интеллектуальные системы моделирования, проектирования и управления", на семинарах кафедр АОИ и АСУ ТУСУР, на научных и научно-технических конференциях, в том числе на 3-й Всероссийской конференции молодых ученых, г. Томск, 2006 г., Международной конференции «Workshop on INTAS programmes supporting young scientists, their followup and European dimension of further prospective for young scientists», г. Томск, 2007 г., XLV и XLVI Международных научных конференциях «Студент и научно-технический прогресс», г. Новосибирск, (2007, 2008 гг.), Всероссийской научно-технической конференции «Научная сессия ТУСУР», г. Томск, 2007, 2008, 2009 гг., Всероссийской конференции по вычислительной математике КВМ–2009, г. Новосибирск, 2009 г.
Доклады на конференциях Научная сессия ТУСУР в 2007 и 2008 гг. были награждены дипломами третьей и первой степени соответственно.
Публикации по теме работы
По теме диссертации опубликовано 19 печатных работ, из них две – в периодических изданиях, рекомендованных ВАК России для публикации научных работ, получено два свидетельства об официальной регистрации подсистем разработанного программного комплекса в ОФАП, одно учебно-методическое пособие.
Личный вклад автора
Постановка задачи, а также подготовка материалов к печати велась совместно с научным руководителем. Основные научные результаты получены автором самостоятельно. Автором самостоятельно разработан комплекс программ настройки нечетких моделей.
Структура и объем работы
Диссертационная работа состоит из введения, пяти глав и заключения. Объем работы составляет 180 страниц. Список литературы содержит 108 наименований.
КРАТКОЕ СОДЕРЖАНИЕ РАБОТЫ
Во введении обосновывается актуальность темы исследования, сформулирована цель работы, изложены полученные автором основные результаты проведенных исследований, показана их научная новизна, теоретическая и практическая значимость, отражены основные положения, выносимые на защиту
В первой главе производится обзор проблемы исследования.
Отображение вход-выход в нечеткой модели представлено как множество нечетких «ЕСЛИ-ТО» правил. Каждое правило состоит из двух частей: условной и заключительной. Антецедент (условная часть) содержит утверждение относительно значений входных переменных, в консеквенте (заключительной части) указывается значение, которое принимает выходная переменная.
Правила нечеткой модели типа синглтон имеют следующий вид:
правило i: ЕСЛИ x1 = А1i И x2 = А2i И … И xm = Аmi ТО y = ri,
где Aji – лингвистический терм, которым оценивается переменная xj, а выход y оценивается действительным числом ri.
Модель осуществляет отображение ![]() , заменяя оператор нечеткой конъюнкции произведением, а оператор агрегации нечетких правил – сложением. Отображение F для модели типа синглтон определяется формулой:
, заменяя оператор нечеткой конъюнкции произведением, а оператор агрегации нечетких правил – сложением. Отображение F для модели типа синглтон определяется формулой:
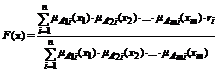 ,
,
где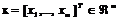 , n – количество правил нечеткой модели, m – количество входных переменных в модели,
, n – количество правил нечеткой модели, m – количество входных переменных в модели, ![]() – функция принадлежности нечеткой области Aji.
– функция принадлежности нечеткой области Aji.
Нечеткое моделирование включает два основных этапа: идентификацию структуры и настройку параметров нечеткой модели. Идентификация структуры – определение таких характеристик нечеткой модели, как число нечетких правил, количество лингвистических термов, на которое разбиты входные и выходные переменные. Настройка параметров – это определение неизвестных параметров антецедентов и консеквентов нечетких правил путем оптимизации работы нечеткой модели по заданному критерию.
Для настройки параметров нечетких моделей используются две группы методов. Первая группа – классические методы оптимизации, основанные на производных: метод наименьших квадратов, градиентный метод, фильтр Калмана. Эти методы обладают высокой скоростью сходимости, но они имеют тенденцию сходиться к локальным оптимумам.
Трудности применения классических методов оптимизации, в частности проблема локального экстремума и «проклятие размерности», заставляют обратиться ко второй группе методов – метаэвристических, таких как алгоритмы муравьиной колонии, роящихся частиц, имитации отжига, генетические алгоритмы. Но это методы грубой настройки, требующие больших временных ресурсов. Кроме того, применение метаэвристик не гарантирует нахождения оптимального решения и, как правило, связано с эмпирической настройкой параметров используемых алгоритмов.
Использование гибридных алгоритмов позволит объединить преимущества метаэвристических методов с преимуществами методов, основанных на производных. Такое объединение повысит качество решений при умеренном количестве ресурсов и за приемлемое время.
Во второй главе приводятся разработанные алгоритмы настройки нечетких моделей.
В работе предлагается следующий алгоритм настройки нечетких моделей:
Алгоритм настройки нечетких моделей
Шаг 1. Задание количества термов лингвистических переменных.
Шаг 2. Инициализация параметров нечеткой модели.
Подшаг 2.1 Задание параметров антецедентов правил с помощью субъективного разделения данных.
Подшаг 2.2 Инициализация консеквентов правил на основе модифицированной процедуры диффузии.
Шаг 3. Настройка параметров нечеткой модели одним из метаэвристических, основанных на производных или гибридных алгоритмов.
Шаг 4. Если среднеквадратичная ошибка нечеткой модели больше заданной, то увеличение количества термов, переход на шаг 2, иначе выход из алгоритма.
Инициализация параметров модели производится на основе субъективного разделения данных и процедуры диффузии. Нечеткие правила и функции принадлежности должны покрывать весь универсум, на котором они определены. Переход от одной функции принадлежности к другой не содержит разрывов, иначе поверхность вывода также будет содержать разрывы. В общем случае алгоритм настройки параметров состоит из следующей последовательности шагов.
Алгоритм настройки параметров нечеткой модели
Шаг 1. Задание начальных параметров нечеткой модели и параметров выбранного алгоритма.
Шаг 2. Генерация решения выбранным алгоритмом настройки.
Шаг 3. Оценка решения с помощью нечеткой модели.
Шаг 4. Проверка условия останова. Если условие выполняется, то переход на шаг 5, иначе переход на шаг 2.
Шаг 5. Вывод решения – набора параметров нечеткой модели, выход из алгоритма.
В работе были использованы следующие методы: основанные на производных — градиентный метод, фильтр Калмана, метод наименьших квадратов, и метаэвристические — генетический алгоритм и алгоритм имитации отжига.
Генетический алгоритм работает с популяцией особей, каждая особь соответствует отдельному решению задачи. В случае настройки параметров антецедентов правил каждый ген хромосомы кодирует один параметр нечеткой модели. В качестве целевой функции выступает ошибка нечеткой модели. Предложено несколько способов формирования текущей популяции: полная замена старой популяции новой, полученной в результате применения операторов скрещивания и мутации; частичная замена, когда формируется «расширенная» популяция, в которую помещаются хромосомы как нового, так и старого поколения; помещение в новую популяцию лучших хромосом из старого поколения и лучших хромосом из нового поколения в отношении 3:7; помещение в новую популяцию лучших хромосом из старого поколения и худших хромосом из нового поколения в отношении 3:7. Описаны условия включения особи в популяцию в зависимости от вида функций принадлежности, параметры которых необходимо настраивать. Определен специфичный оператор мутации.
Алгоритм имитации отжига использует упорядоченный случайный поиск, основываясь на аналогии с процессом охлаждения металла. Параметры функций принадлежности, полученные в результате субъективного разделения данных, формируют текущее решение, которое, при его изменении случайным образом, переходит в рабочее. Рабочее решение может опять вернуться в текущее, либо перейти в лучшее при условии уменьшения ошибки нечеткой модели. Рабочее решение может быть принято в качестве текущего, даже если его ошибка превышает ошибку текущего, в том случае, когда выполняется критерий допуска.![]() При высокой температуре плохие решения принимаются чаще, чем отбрасываются. При снижении температуры вероятность принятия худшего решения уменьшается.
При высокой температуре плохие решения принимаются чаще, чем отбрасываются. При снижении температуры вероятность принятия худшего решения уменьшается.
Градиентный метод в практике обучения нечетких правил используется давно. Суть метода заключается в том, что последующее приближение функции получается из предыдущего движением в направлении, противоположном направлению градиента целевой функции. При настройке параметров нечетких моделей целевой функцией является среднеквадратичная ошибка, а вектор параметров определен на множестве параметров антецедентов и консеквентов правил.
Постановка задачи настройки параметров нечетких моделей на основе фильтра Калмана приведена ниже. Состояние системы задается вектором значений параметров функций принадлежности. Вычисляемой переменной, определенным образом связанной с состоянием системы, является выход нечеткой модели. Два последовательно определенных вектора состояния связаны рекуррентным уравнением (модель процесса). Определенным уравнением связаны вектор измерений и вектор состояний (модель измерения). Процессом для системы является движение по пространству решений задачи, шумы процесса и измерения определяются неточностью в определении нахождения решения в пространстве и неточностью в измерении координат решения, соответственно. Сходимость алгоритма и точность определения параметров нечеткой модели зависят от выбора значений матриц ковариаций шума процесса и шума измерения.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
