
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]()
![]()
![]()

| 54 | 24 | 5 | 0 | 7 | 32 |
| контроль |
| -2 | 4 | 6 | 5 | 9 | 8 |
| |
| 6 | -8 | -6 | 0 | 9 | 16 |
|
По данным таблицы находим
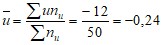
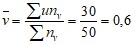
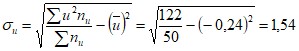
Подставив найденные величины в уравнение прямой регрессии Y на X, получим искомое уравнение
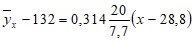
![]()
ПРИМЕР 7. По данным корреляционной таблицы 1 найти условные средние ![]() и
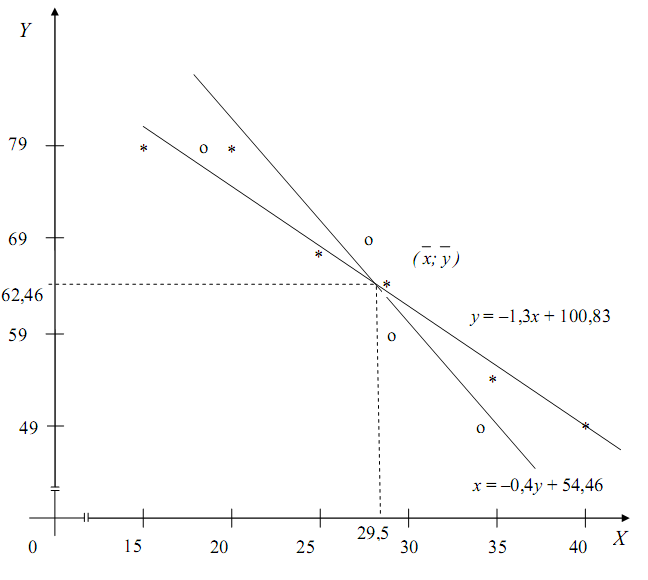
и ![]() . Оценить тесноту линейной связи между признаками Х и Y и составить уравнения линейной регрессии Y по X и X по Y. Cделать чертеж, нанеся на него условные средние и найденные прямые регрессии. Оценить тесноту связи между признаками с помощью корреляционного отношения.
. Оценить тесноту линейной связи между признаками Х и Y и составить уравнения линейной регрессии Y по X и X по Y. Cделать чертеж, нанеся на него условные средние и найденные прямые регрессии. Оценить тесноту связи между признаками с помощью корреляционного отношения.
Таблица 1
X Y | 15 | 20 | 25 | 30 | 35 | 40 |
|
49 | 14 | 14 | 9 | 37 | |||
59 | 7 | 13 | 6 | 26 | |||
69 | 10 | 40 | 2 | 52 | |||
79 | 8 | 4 | 3 | 15 | |||
| 8 | 4 | 20 | 67 | 22 | 9 | 130 |
Решение. В таблице 1 приведены данные выборочных наблюдений за 130 объектами, обладающими признаками X и Y. Каждому объекту соответствует пара значений (x, у), а частота ![]() показывает количество объектов с такой парой значений признаков.
показывает количество объектов с такой парой значений признаков.
Все возможные значения признака X перечислены в верхней горизонтальной строке таблицы 1, а для признака Y – в первом вертикальном столбце. В клетках на пересечении каждой строки и каждого столбца проставлена частота ![]() , с которой наблюдается каждая пара значений.
, с которой наблюдается каждая пара значений.
Например: пара значений (15;79) наблюдалась 8 раз, пара значений (30;69) наблюдалась 40 раз и т. д.
Пустые клетки означают, что соответствующие им пары значений не наблюдались.
В нижней итоговой строке данной таблицы напротив каждого значения признака Х проставляется соответствующая ему частота nx, равная сумме всех частот столбца и указывающая, сколько раз всего наблюдалось данное значение х. Аналогично, в последнем итоговом столбце напротив каждого значения у записывают соответствующую ему частоту ny, равную сумме частот по строке и указывающую, сколько раз всего наблюдалось данное значение у. Очевидно, что суммы всех частот для ![]() и для
и для ![]() должны быть равны между собой и равны объему выборки (количеству наблюдаемых пар):
должны быть равны между собой и равны объему выборки (количеству наблюдаемых пар):
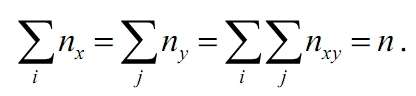
Объем выборки n проставляется в последней клетке таблицы. В данной задаче n = 130.
В таблице 1 каждому значению X соответствует статистическое распределение признака Y.
Например, для x = 30:
Y | 49 | 59 | 69 | 79 |
| 14 | 13 | 40 | - |
Отсюда находим среднее значение y при условии, что x = 30, или условную среднюю:
![]()
Аналогично, каждому значению y соответствует статистическое распределение Х. Например, для y = 49:
Х | 15 | 20 | 25 | 30 | 35 | 40 |
| - | - | - | 14 | 14 | 9 |
Отсюда находим условную среднюю:
![]()
Не выписывая далее статистических распределений, а беря их непосредственно из данной корреляционной таблицы 1, найдем все условные средние по формулам

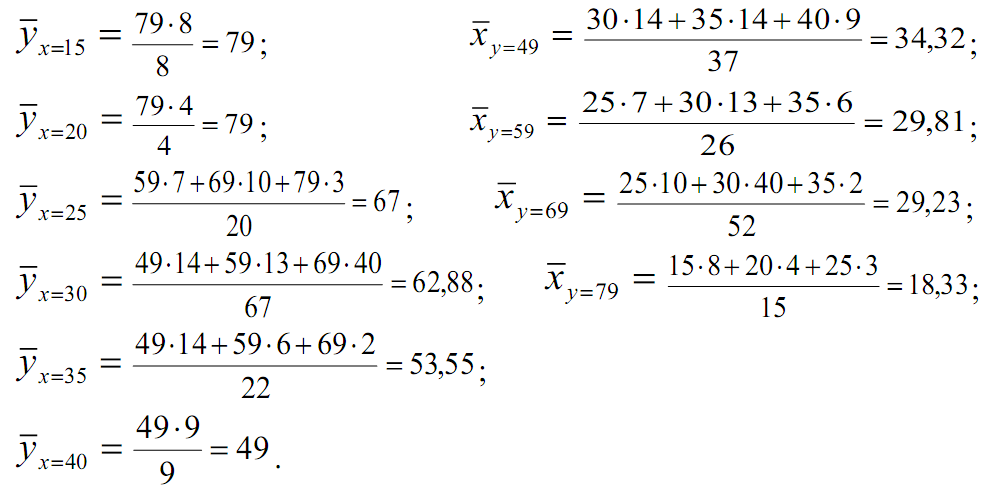
Оценка тесноты линейной связи между признаками Х и Y производится с помощью коэффициента линейной корреляции r:
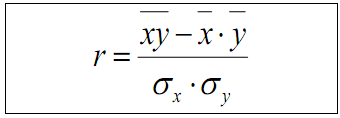
Коэффициент r может принимать значения от –1 до +1, то есть
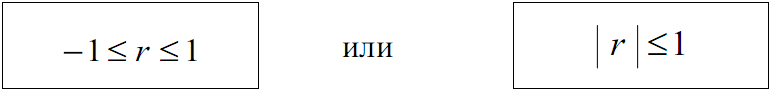
Знак r указывает на направление связи: прямая или обратная. Абсолютная величина![]() указывает на силу (тесноту) связи.
указывает на силу (тесноту) связи.
Оценка тесноты линейной связи (шкала Чаддока)
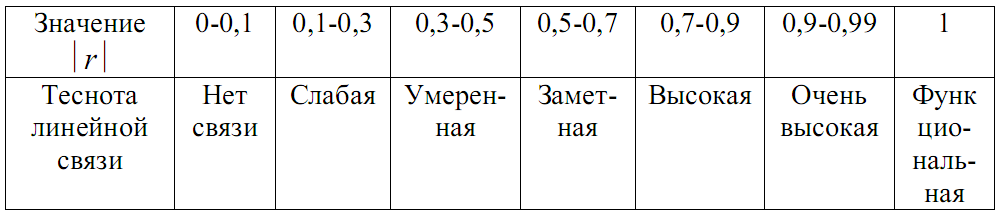
При r > 0 связь прямая, то есть с ростом х растет у.
При r < 0 связь обратная, то есть с ростом х убывает у.
Для нахождения r вычислим указанные общие средние: x, y, xy, а также средние квадратические отклонения σx и σy. Вычисления удобно поместить в таблицы 2 и 3, куда вписываем также найденные ранее условные средние.
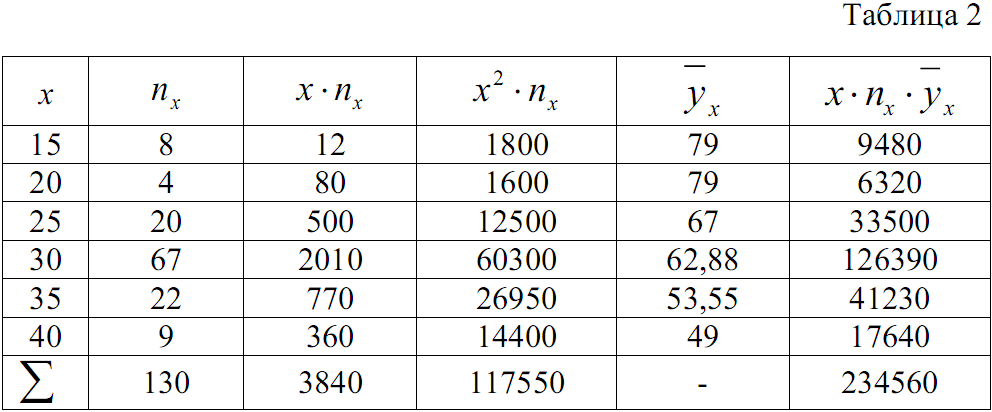

В рассматриваемой задаче эта сумма в обеих таблицах равна 234560. Равенство может оказаться приближенным, что связано с приближенными вычислениями условных средних ![]() и
и ![]() .
.
С помощью таблиц 2 и 3 находим общие средние, средниеквадратов, среднюю произведения и средние квадратические отклонения:
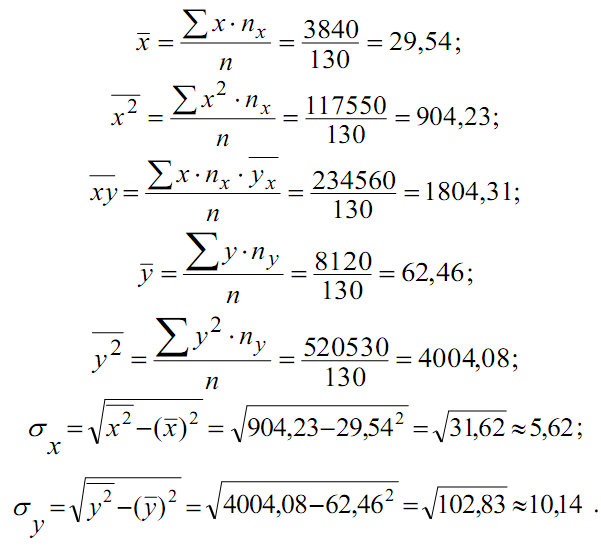

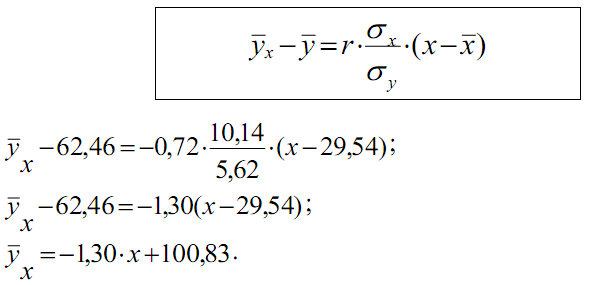










ПРИМЕР 8. Дан интервальный вариационный ряд распределения признака X при уровне значимости ![]() проверить гипотезу о нормальности распределения X в генеральной совокупности по критерию Пирсона.
проверить гипотезу о нормальности распределения X в генеральной совокупности по критерию Пирсона.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
