


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Для расширения функционала разработанного приложения необходимо добавить возможность каталогизирования Internet-ресурсов. Сложность реализации в том, что в настоящее время не существует единых форматом, позволяющих описать определённый вид документов (в нашем случае научных работ), создаваемых Web-пользователями. Кроме того, следует учесть тот объём информации, который со временем будет занесён в информационную систему и способы проверки данных. Поэтому необходимо предусмотреть возможность валидации (проверки на допустимость) данных как в момент ввода, так и в виде отдельных процедур, запускаемых в момент выбора соответствующего пункта меню.
Литература
1. Грэхем, И. Объектно-ориентированные методы. Принципы и практика. 3-е издание: Пер. с англ. – М.: Издательский дом «Вильямс», 2004. – 880 с.: ил. – Парал. тит. англ.
2. Коннолли, Томас, Бегг, Каролин. Базы данных. Проектирова-ние, реализация и сопровождение. Теория и практика. 3-е издание. : Пер. с англ. − М.: Издательский дом «Вильямс», 2003. − 1440 с. : ил. - Парал. тит. англ.
3. Ambler S. W. Agile Database Techniques−Effective Strategies for the Agile Soft-ware, John Wiley & Sons, 2003, 373p.
4. The fastest way to platform independent business applications, http://www. /Products/NET/Application_Framework/
5. Олейник, метамодели объектной системы в реляционной базе данных // Известия высших учебных заведений. Северо-Кавказский регион. Спецвыпуск «Математическое моделирова-ние и компьютерные технологии» 2005. С. 3-8.
6. Oleynik, P. P. Implementation of the Hierarchy of Atomic Literal Types in an Object System Based of RDBMS // Programming and Computer Software, 2009, Vol. 35, No.4, pp. 235-240.
МОДУЛЬ МОРФОЛОГИЧЕСКОГО АНАЛИЗА СЛОВ РУССКОГО ЯЗЫКА В СИСТЕМЕ ФИЛЬТРАЦИИ
ИНТЕРНЕТ-ТРАФИКА
Бийский технологический институт АлтГТУ им.
В докладе рассмотрены основные способы извлечения значимой информации из HTML-страниц и алгоритмы приведения текстов выборки к виду, пригодному для использования в методах машинного обучения, для их последующего применения в системе ограничения доступа к веб-сайтам определенной тематики, содержащим, например, информацию антисоциальной, экстремистской, террористической и т. п. направленности.
В задаче анализа и фильтрации Интернет-трафика возникает необходимость определять тематику web-страниц для блокирования доступа учащихся и сотрудников организаций к нелегальной информации, принадлежащей к определённым категориям ресурсов, а также для предотвращения нецелевого использования Интернет-ресурсов в рабочее время. Набор категорий фильтрации Интернет-ресурсов определяется, исходя из специфики организации и возможности задания гибких политик фильтрации трафика для различных пользователей и групп пользователей. Категории фильтрации могут пересекаться и иметь иерархическую структуру, при этом классифицируемый объект (web-страница) имеет многотемную природу относительно этого набора категорий. В данной задаче время классификации запрашиваемых пользователями web-страниц является критичным и не должно вносить задержки в интерактивный режим работы конечных пользователей [13].
Практическая значимость исследования заключается в том, чтобы обобщить опыт российских и зарубежных ученых в сфере прикладной лингвистики и перенести его на решение задачи классификации HTML-страниц. В общем случае данную задачу можно представить в виде последовательности подзадач:
1. удаление элементов форматирования;
2. извлечение значимой информации из текста;
3. приведение текстовой информации к виду, пригодному для использования в методах машинного обучения;
4. построение модели классификатора (применение выбранного метода машинного обучения к элементам обучающего множества);
5. классификация страниц тестового множества;
6. оценка результатов классификации и, при необходимости, выработка рекомендаций по улучшению качества классификации.
Рассмотрим более подробно первые три подзадачи.
Подготовка текстовой информации к ее использованию в методах машинного обучения является первым и наиболее ответственным этапом, от качества проведения работ на котором во многом зависит результат классификации.
Большинство описанных в литературе методов автоматической классификации веб-страниц так или иначе основаны на предположении, что тексты каждой тематической рубрики содержат отличительные признаки (слова или словосочетания), наличие или отсутствие которых говорит о принадлежности или не принадлежности исследуемого текста той или иной рубрике. Задача исследователя состоит в том, чтобы наилучшим образом выбрать такие отличительные признаки и сформулировать правила, на основе которых будет приниматься решение об отнесении текста к конкретной рубрике [1].
Особенностью представления документов в сети Интернет является наличие на странице помимо содержательной части элементов форматирования и навигации, которые принято называть «информационным шумом». Часто эти элементы повторяются на большинстве страниц сайта, не имея прямого отношения к теме веб-страницы и поэтому могут отрицательно влиять на качество классифи-кации. Следует также отметить, что этот «шум» может составлять порядка 40 % от объема страницы, что существенно влияет на время обработки документа [3]. Поэтому целесообразно перед применением алгоритма классификации выделить из веб-страницы содержательную часть и произвести над ней некоторые преобразования, такие как удаление лишних пробелов, удаление HTML − разметки, удаление пунктуации, приведение к единому регистру символов, удаление стоп-слов, лемматизация[1]. Перечисленные функции, как правило, реали-зуются в модуле морфологического анализа.
Необходимость использования морфологических анализаторов не раз обсуждалась на ведущих Всероссийских и международных конференциях (например «Диалог») и уже не у кого не вызывает сомнения [4, 11, 15]. Рассмотрим задачи, которые решаются модулями морфологического анализа.
Удаление лишних пробелов, HTML-разметки и знаков пунктуа-ции. Как правило, реализация данного этапа подготовки исходных данных не является сложной задачей и решается стандартными средствами большинства современных языков программирования. Обработав таким образом веб-страницу на выходе получаем текстовый документ. Однако, следует подчеркнуть одну важную деталь, что удалив HTML-разметку, мы полностью теряем не только форматиро-вание, но и те места в тексте, на которых автор хотел акцентировать внимание читателя. Это могут быть заголовки различных уровней, слова, выделенные другим шрифтом (цветом, начертанием, подчерки-ванием, капитализацией и т. д.), которые, определенно, несут большую смысловую нагрузку и важны для определения темы веб-страницы. Эту деталь очень важно учитывать при разработке модуля морфологического анализа, например путем построения модели с весами слов и деления веб-страницы на блоки (фрагменты) [12], в которой выделенным словам будет присваиваться больший вес.
Далее встает вопрос о выборе модели представления текстового документа. Наибольшее распространение в последнее время получила модель «множества слов», в которой используется сжатое представление теста в виде вектора признаков. Мерой близости двух документов считается расстояние между векторами их признаков, иными слова, эти документы имеют близкие распределения относительных частот слов, входящих в текст.
Размерность пространства признаков равна числу терминов, содержащихся в документах обучающей выборки. Большая размер-ность пространства признаков не всегда положительно сказывается на показателях качества классификации, приводя к «переобучению» классификатора и снижению полноты и точности. Кроме того, исполь-зование большого пространства признаков приводит к увеличению времени обучения классификатора и самой классификации, что крайне нежелательно, т. к. время загрузки страницы является одним из ключевых факторов производительности системы анализа и фильтра-ции Интернет-трафика. Поэтому необходимо стараться уменьшить размерность пространства признаков, оставив только наиболее значимые (ключевые) из них. Одними из самых распространенных подходов к уменьшению размерности пространства признаков являются стемминг (см. лемматизация), алгоритмы, основанные на правилах словообразования, а также их комбинации.
В большинстве естественных языков наблюдается такое явление, как морфологическая изменяемость слов. Данное явление сильно выра-жено в русском языке, который относится к группе флективных язы-ков. Сложность естественного языка приводит к тому, что ни один из описанных выше подходов не может «охватить» его целиком. В рус-ском языке по различным оценкам насчитывается свыше 1000 правил словообразования с множеством исключений, что делает создание полного набора правил крайне сложным, а реализацию алгоритма трудоемкой. Кроме того, перебор такого количества правил сделает логику работы приложения достаточно сложной и отрицательно скажется на производительности системы. Постоянное развитие языков и большой размер словарей также делает невозможным использование одних только словарей. Задача осложняется еще и тем, что в тексте может содержаться сленг, грамматические ошибки и намеренное искажение написания слов (напр., транслитерация) [4, 5].
В настоящее время существует несколько разработок, которые можно использовать для морфологической обработки текстов. Далее в статье приводится краткое описание некоммерческих средств морфологической обработки.
Проект Snowball [7] в котором реализован алгоритм М. Портера. При определении основы слова используется набор аффиксов русского языка. Последовательно применяя встроенные правила словообразо-вания алгоритм возвращает вероятную основу слова. Стеммер представлен в виде исходных текстов на языках C и Java. Среди достоинств алгоритма можно выделить высокую скорость, простоту и переносимость (за счет Java-реализации). К недостаткам алгоритма можно отнести то, что он базируется на обобщенных правилах и не может корректно обрабатывать слова-исключения.
Библиотека морфологического анализа Stemka, разработанная и реализованная А. Коваленко [8]. Алгоритм стемминга представлен в виде таблицы переходов конечного автомата. Для представления автоматических правил усечения слов используется модель хранения возможного окончания с двумя предшествующими буквами неизменяемой части слова. Кроме того, в алгоритм заложено правило, суть которого состоит в том, что формальная основа слова должна содержать хотя бы одну гласную.
Пакет АОТ, разрабатываемый одноименной рабочей группой специалистов в области программного обеспечения для автоматичес-кой обработки текстов. В системе используется морфологический словарь (на основе словаря [14]), который может содержать информацию о словах и возможных аффиксах (приставках, суффиксах и ударениях). Стоит отметить одну важную деталь, реализованную в данном пакете − это механизм морфологического предсказания. Если слово не найдено в словаре, то делается попытка найти словоформу, которая совпадает с максимально длинной правой частью анализируемого слова и если это удается, то слово предсказы-вается по найденной правой части. В случае, если попытка предска-зания по правой части оказалась неудачной, производится предска-зание по окончаниям, в результате которого выводится список вариантов слов разных частей речи, которые могут быть продуктив-ными с наиболее похожими окончаниями. При этом выбираются наиболее высокочастотные из них.
Оценка качества морфологического анализа проводится на основании подхода, учитывающего количество форм слов, непра-вильно отнесенных к леммам [5, 6, 9]. Выделяют два вида ошибок лемматизации:
1) морфологические формы одного слова отнесены к разным леммам;
2) разные слова ошибочно отнесены к одной лемме.
Оценка этих характеристик на практике достаточно затрудни-тельна, т. к. требует наличия некоего «эталонного» лемматизатора (или экспертной группы, не обладающей субъективизмом оценки), обеспечивающего идеальное разбиение. Очевидно, что такого «образцового» разбиения для русского языка получить не удастся.
В качестве другой характеристики [5], которую значительно проще оценить, предлагается использовать среднее количество слов, отнесенных к одной лемме данным лемматизатором.
Следует отметить, что все рассмотренные выше лемматизаторы в тестах показывают сравнимые результаты. Выделить какой-либо из них в качестве лучшего не представляется возможный, т. к. каждый обладает достоинствами и недостатками и с успехом используется в научных исследованиях.
Кратко рассмотрим следующую задачу − это построение классификатора на основе набора векторов признаков и соответствующих им меток целевых классов. Классификатор – это некоторый алгоритм, принимающий на вход вектор признаков и выдающий метку класса, к которому следует отнести данный вектор. В [1] описаны наиболее известные алгоритмы построения классификаторов (классификация на основе линейной регрессии, деревья решений, алгоритм «ближайших соседей», «наивный байесовский» (Naïve Bayes) классификатор, SVM, классификатор «случайный лес»). На основании анализа нескольких независимых публикаций можно сделать вывод о преимуществе SVM над остальными методами машинного обучения. Поэтому принято решение использовать SVM в качестве отправной точки при проведении исследований.
В целом можно отметить, что важнейшим фактором, определяющим качество рубрикации, является умение правильно выбрать ключевые признаки, на основании которых будет строиться классификатор. Также необходимо уделить особое внимание стадии подготовки исходных данных и выбору алгоритма лемматизации (стемминга). Стоит отметить, что при выборе алгоритма классификации в первую очередь необходимо руководствоваться такими показателями, как точность, полнота и производительность. Соотношение этих показателей должно быть таким, чтобы влияние работы алгоритма на скорость загрузки веб-страницы было приемлемым при максимальной точности (процент неверно рубрицированных веб-страниц должен быть минимальным).
Литература
1. Дунаев, Е. В., Шелестов, рубрикация web-страниц в интернет-каталоге с иерархической структурой. // «Интернет-математика 2005». − М.: , 2005.
2. Кузнецов, значимой информации из web-страниц с использованием предложений. // Сборник тезисов постерных докладов восьмой всероссийской конференции RCDL’2006. - Санкт-Петербург: НУ ЦСИ, 2006. − 274 с.
3. Киселев, процедуры автоматического пополнения веб-каталога. // «Интернет-математика 2005». − М.: , 2005.
4. Коваленко, А. Вероятностный морфологический анализатор русского и украинского языков. «Системный администратор» № 1, октябрь 2002.
5. Губин, М. В., Морозов, морфологического анализа на качество информационного поиска, Труды RCDL-2006, стр. 224-228, 2006.
6. Автоматическая Обработка Текста [Электронный ресурс]. − Режим доступа: http://www. *****, свободный.
7. Стеммер Snowball [Электронный ресурс]. − Режим доступа: http://snowball. tartarus. org/algorithms/russian/stemmer. html, свободный.
8. Морфологический анализатор Stemka [Электронный ресурс]. − Режим доступа: www. *****/stemka/stemka. html, свободный.
9. Paice C. D. Method for Evaluation of stemming algorithms based on error counting.//JASIS, 47(8). − Р. 632-649.
10. Шевелев, автоматической классификации текстов на естественном языке: Учеб. Пособие. − Томск: ТМЛ-Пресс, 2007. − 144 с.
11. Васильев, технология автоматической классификации текстов // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной Международной компьютерной конференции «Диалог» (Бекасово, 4-8 июня 2008 г.). − Вып. 7(14). − М.:РГГУ, 2008. − С. 83-91.
12. Васильев, классификаторов на основе выделения фрагментов // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной Международной конференции «Диалог» (Бекасово, 26-30 мая 2010 г.). Вып− М.: Изд-во РГГУ, 2010.
13. Глазкова, и разработка методов построения программных средств классификации многотемных гипертекстовых документов: диссертация кандидата физико-математических наук: 05.13.11 / ; [Место защиты: Моск. гос. ун-т им. ]. − Москва, 2008. − 103 с.: ил. РГБ ОД,/668.
14. Зализняк, А. А.: Грамматический словарь русского языка. Словоизменение. Около 100000 слов. − М.: Русский язык, 1977. − 880 с.
15. Аношкина, процессор русского языка // Бюллетень машинного фонда русского языка / Отв. Редактор . − М.,1996. − Вып. 3. − С. 53-57.
ОРГАНИЗАЦИЯ СИСТЕМЫ ВНУТРЕННЕГО КОНТРОЛЯ
НА ПРОМЫШЛЕННОМ ПРЕДПРИЯТИИ
С ИСПОЛЬЗОВАНИЕМ ИНФОРМАЦИОННЫХ СИСТЕМ
,
Бийский технологический институт АлтГТУ им.
Эффективность системы внутреннего контроля во многом зависит от степени использования информационных технологий. Для современных условий развития информационных технологий характерно все более широкое использование высокоэффективных автоматизированных информационных систем, позволяющих существенно повышать уровень управления экономическими объектами. Современные информационные системы предоставляют возможность осуществлять сбор и хранение информации, оперативно и точно передавать ее по назначению, осуществлять ее обработку, выявлять отклонения от намеченных показателей, производить анализ данных. На этой основе появляется возможность совершенствовать систему внутреннего контроля, осуществляя систематическое наблюдение за всеми участками деятельности организации. Данные внутреннего контроля помогают руководству предприятия и иному управленческому персоналу получать оперативную информацию об отклонениях от нормальных условий совершения хозяйственных операций [1]. Кроме того, координировать и своевременно вносить соответствующие коррективы, отслеживая изменение условий внешней среды. Применение современных информационных систем создает предпосылки для усиления централизации и оперативности контроля, перенесения на высший уровень руководства контрольных функций за деятельностью подразделений организации.
При этом система внутреннего контроля нацелена на решение задач, стоящих перед организацией в трех сферах: ведения бизнеса (обеспечение эффективности и результативности операций), составления финансовой отчетности (обеспечение точности сведений), существования компании в рамках, установленных нормативно-правовыми актами, правилами и стандартами (соблюдение соответствующих требований). Эта система включает в себя пять элементов: создание контрольной среды, оценку рисков, осуществление контрольных действий, обмен информацией, мониторинг [2].
В настоящее время можно выделить три наиболее важных направления, в рамках которых разрабатываются инструменты, используемые руководством организации в области внутреннего контроля. К ним относятся управление рисками (risk management), управление обеспечением информационной безопасности (information security management), управление выполнением требований законодательных и регулирующих органов (compliance management).
Крупнейшие производители компьютеров и программного обеспечения учреждают консорциумы по выпуску наиболее сложных, комплексных систем управления рисками. Такой альянс образовали, например, три американские корпорации: IBM (мощности для создания и хранения баз данных), PeopleSoft (программы для составления отчетности), Algorithmics (программы для анализа данных). В процессе поиска партнеров находятся компании Fair Isaac, Protiviti, Providus Software, SAS Institute [3].
Но все указанные информационные технологии обращены исключительно к финансовым институтам и крупным организациям, средний и малый бизнес приобрести программные продукты практически не может, так как они достаточно дорогие и их приобретение экономически не оправданно.
В организациях среднего и малого бизнеса в системе внутрен-него контроля используются внутренние и внешние стандартные информационные системы. Рассмотрим использование информа-ционных технологий в системе внутреннего контроля на примере функционирования организации среднего бизнеса, обеспечивающей реализацию строительных металлических изделий, а так же выполнение строительно-монтажных работ. Организация -Профиль» специализируется на производстве и реализации металлочерепицы и металлосайдинга, осуществляет весь комплекс услуг, связанных с облицовкой стен зданий и строительством кровель, включая проведение замеров, проектно-сметных работ, производство элементов конструкции и монтажных работ. Система информационного обеспечения внутреннего контроля в -Профиль» представлена на рисунке 1.
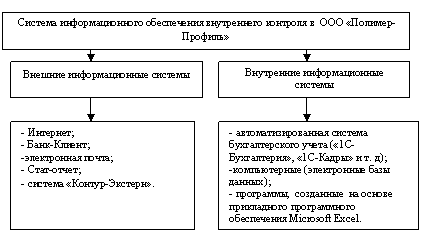

Рисунок 1 – Система информационного обеспечения внутреннего контроля в -Профиль»
Основой действующей системы внутреннего контроля в организации является бухгалтерский учет. В системе внутреннего контроля организацией используются следующие внутренние информационные источники: программный продукт «1С-Бухгалтерия», программа «Клиент», программы, созданные на основе прикладного программного обеспечения Microsoft Excel, а так же внешние информационные источники: «Банк-Клиент», система «Контур-Экстерн», программное обеспечение «Стат-отчет», Интернет и т. д. Программа «Клиент» была введена в действие в июле 2010 года в связи с необходимостью оперативного обмена информацией между структурными подразделениями.
С целью оптимизации работы организации авторами разработана программа оценки системы внутреннего контроля по центрам контроля при помощи прикладного программного обеспечения Microsoft Excel. Особенностью данной программы является то, что она позволяет оперативно выявлять проблемные участки в деятельности организации. Программа помогает группировать информацию, автоматически производит расчет и анализ введенных данных. За каждым центром контроля закреплен перечень вопросов, подлежащих оценке, который не является регламентированным. Программа позволяет добавлять и удалять тесты в зависимости от желаемого уровня раскрытия анализируемого центра контроля.
Каждый центр контроля анализируется разработанной системой тестов. Оценка тестов осуществляется по бальной шкале, и результат фиксируется в соответствующей графе.
В зависимости от того, в какой диапазон попадает общее количество баллов, автоматически присваивается определенный уровень внутреннего контроля: очень низкий (0-20), низкий (21-40), средний (41-60), высокий (61-80), очень высокий (81-100).
Программа содержит 8 аналитических разделов, которые посвящены оценки внутреннего контроля организации по объектам контроля, представленным в таблице 1.
Таблица 1 – Результаты оценки системы внутреннего контроля -Профиль» по центрам контроля
|
Центры контроля |
Варианты ответа в баллах |
Итого баллов | ||||
|
очень плохо |
плохо |
удовлет-воритель-но |
хорошо |
отлично | ||
|
Управление организацией |
3,6 |
1,2 |
1,8 |
1,6 |
24 |
32,2 |
|
Операции по труду и его оплате |
3,8 |
0,4 |
1,8 |
2,4 |
2 |
10,4 |
|
Операции с материально-производственными запасами |
4 |
0,4 |
3,6 |
0 |
23 |
31 |
|
Операции с основными средствами |
1,2 |
0,4 |
0,6 |
5,3 |
0,8 |
8,3 |
|
Кассовые операции |
2 |
0 |
0,6 |
2,4 |
61 |
66 |
|
Расходы и доходы организации |
1,4 |
0 |
0 |
0,8 |
40 |
52,2 |
|
Кредиты и займы |
1,6 |
0,4 |
0 |
0,8 |
54 |
56,8 |
|
Расчеты с подотчетными лицами |
1 |
0,4 |
0,6 |
0,8 |
59 |
61,8 |
По результатам проведенного тестирования составлен рейтинг уровней контроля по центрам контроля предприятия, который позво-лил выявить проблемные участки системы внутреннего контроля.
Руководству организации представлена информация по выявленным проблемным центрам контроля (очень низкий и низкий), таким как операции с основными средствами, операции с материально–производственными затратами, операции по управлению организацией предприятия, операции по заработной плате.
Предполагается апробация разработанной программы оценки системы внутреннего контроля на предприятиях строительного профиля.
Литература
1. Шеремет, : Учебник / , . – 5-е изд., перераб. и доп. – М.: ИНФРА-М, 2008. – 448 с.
2. Управление рисками организации. Интегрированная модель (COSO) – Режим доступа: http://www. law-tax.biz , свободный /
3. Щербаков, информационного обеспечения внутреннего контроля в коммерческом банке. – Режим доступа: http://www. *****, свободный.
Расчет кривых движения перспективного городского электротранспорта
А.-*, **
*Петербургский государственный университет путей сообщения,
г. Санкт-Петербург
**Бийский технологический институт АлтГТУ им.
В последние годы, в связи с повышением требований к качеству предоставляемых услуг по пассажирским перевозкам и снижению удельного расхода электроэнергии, наметилась тенденция использования на подвижном составе городского и пригородного электротранспорта асинхронных тяговых двигателей, в том числе отдельно вращающихся колёс вместо традиционной жесткой колесной пары. Изучение зарубежного и отечественного опыта позволило сформулировать основные особенности конструктивного исполнения новых тяговых двигателей (так называемых электромотор-колёс) для индивидуального привода колёс. При проектировании подвижного состава городского, пригородного, а также и скоростного междугороднего электротранспорта переход от традиционных коллекторных тяговых двигателей на бесколлекторные асинхронные позволяет повысить надежность и экономичность электротранспорта за счет следующих факторов:
- снижение механического сопротивления движению;
- применение практически полностью бесконтактной силовой электросхемы, за исключением защитных (аварийных) контактных разъединителей;
- отказ от механической трансмиссии между валом тягового электродвигателя и непосредственно колесной парой (колесом).
Расчет и построение кривых движения основан на интегрировании уравнений движения поезда [1]. В таблице 1 приведены исходные данные для расчета кривых движения перспективного трамвая.
Тяговый привод электропоездов и городского электротранспорта работает в повторно-кратковременном режиме, близком в соответствии с классификацией ГОСТ183 к режиму S5. Вместо приближенных методов выявления основных параметров кривой движения (средние величины тяговых усилий, ускорения, сопротивления движению), можно с помощью компьютерной математики с достаточной точностью решить дифференциальные уравнения движения поезда единичной эквивалентной массы и на этой основе получить интегральные параметры, необходимые для расчета эквивалентной тепловой мощности тяговых двигателей.
Таблица 1 – Исходные данные
|
Количество осей/моторных |
4/4 |
|
Количество тяговых двигателей |
8 |
|
Тип тягового двигателя |
электромотор-колесо |
|
Диаметр колеса, м |
0,71 |
|
Ширина колеи, м |
1,524 |
|
Длина кузова, м |
22,5 |
|
Тип кузова |
с двумя сочленениями |
|
Мест для сидения |
48 |
|
Номинальная вместимость, пасс |
206 |
|
Максимальная вместимость, пасс |
293 |
|
Масса тары, кг |
20000 |
|
Скорость максимальная, км/ч (м/с) |
60 (16,67) |
|
Напряжение контактной сети, В |
550 |
|
Скорость выхода на автоматическую характеристику, км/ч (м/с) |
25 (6,94) |
|
Пусковое ускорение, м/с2 |
1,3 |
|
Тормозное замедление, м/с2 |
1,3 |
|
Вращение колёс |
Независимое |
|
Коэффициент инерции вращающихся масс |
1,02 |
|
Формула удельного сопротивления |
w = 0,005 + 0,000487v2 |
На рисунке 1 приведены кривые движения трамвая для максимального разгона 60 км/ч на участке 350 м, полученные на основе расчета, выполненного в среде MathCAD 14.
Анализ кривых движения при различных значениях максимальной скорости позволяет сделать вывод о целесообразной скорости движения трамвая, вычислить эквивалентную расчетную мощность одного мотор-колеса, эффективную систему охлаждения тягового двигателя.
Расчет мощности по среднеквадратичному току требует предварительного задания коэффициентов полезного действия, мощности, использования сцепной массы и числа обмоторенных осей, величины номинального напряжения.
а) 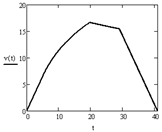 б)
б)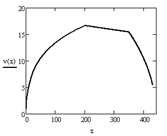
в)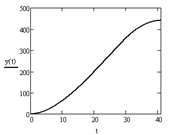
Рисунок 1 – Зависимости: скорости от времени (а), скорости от пройденного пути (б), пройденного пути от времени
Были рассмотрены также другие методы определения эквивалентной тепловой мощности, а именно, по среднеквадратичным величинам удельного тягового усилия или тяговой мощности [2]. Разработчик привода может выбрать любой из рассмотренных методов.
Дальнейшая проверка выбранных параметров поезда на совместимость с кривой ограничения по сцеплению позволяет оценить и при необходимости скорректировать принятые технические решения.
Литература
1. Байрыева, тяга: Городской наземный транспорт // , . [Текст] – М.: Транспорт, 1986. – 206 с.
2. Пармас, А.- асинхронного тягового привода // -Я. Ю., [Электронный ресурс] / − Режим доступа: http://www. *****/educat/systemat/parmas/index. asp.
О КОЛИЧЕСТВЕ ВСЕХ ПИФАГОРОВЫХ ТРОЕК
*, **
*Тверской филиал МГЭИ, г. Тверь,
**Бийский технологический институт АлтГТУ им.
Информационные технологии поддержки математических вычислений продолжают играть ключевую роль в научных исследованиях. Мощь современных вычислительных средств помогает анализировать особенности решения как новых, так и широко известных задач, одна из которых [1] рассматривается в настоящей работе.
Согласно последней теореме Ферма, не существует натуральных чисел x, y и z удовлетворяющих при d > 2 соотношению
xd + yd = zd . (1)
Анализ этого соотношения затруднён тем, что в нём присутствуют три неизвестных натуральных числа, а также целочисленный параметр d, который по известным соображениям может принимать значения 2, 3, 5, 7, 11,…
В случае d=2 из (1) следует формулировка теоремы Пифагора:
x2 + y2 = z2.
Набор трёх натуральных чисел удовлетворяющих этой теореме обычно называют пифагоровой тройкой чисел или просто пифагоровой тройкой. По так называемым формулам индусов основные (базовые) пифагоровы тройки чисел {x, y, z} определяются двухпараметрическим и зависимостями:
x = k ×l, y = (1/2)(k2 - l2), z = (1/2)(k2 + l2), (2)
где k, l − натуральные взаимно простые нечётные числа (k > l), k = 3, 5, 7... , l = 1, 3, 5, ...
Откажемся от взаимной простоты параметров k и l, тогда формулы (2) описывают множество всех наборов пифагоровых троек. В каждом таком наборе (подмножестве) троек чисел значение параметра k фиксировано, а величина параметра l пробегает значения от 1 до k-2. Таким образом, зависимость максимального значения числа z в наборе троек от параметра k выражается уравнением:
zmax= (1/2)[k2 + (k - 2)2].
Для минимального значения соответственно будем иметь:
zmin= (1/2)(k2 + 1).
После несложных преобразований получим уравнения
k2 - 2k + 2 = zmax., (3)
k2 + 1 = 2 zmin. (4)
Зависимости (3), (4) и обратные к ним k(zmax) и k(zmin) являются квадратичными и однозначными.
В настоящей работе получены зависимости общего числа троек N от значений zmax и zmin (рисунок 1). Этот результат позволяет оценить как количество всех пифагоровых троек при заданном z так и получить различные целочисленные функции распределения таких троек чисел.

Рисунок 1 – Точечные графики N(zmax), N(zmin) и их аппроксимации линейной зависимостью
Ранее [2] для случая d=1 была получена аналогичная зависимость N(z), где z наибольшее число в произвольной тройке. Эта зависимость для нечётных значений z имеет вид
N(z)=(1/4)(z-1)2.
На рисунке 2 она сопоставляется с полученными в данной работе точными зависимостями N(zmax) и N(zmin) для случая d=2.
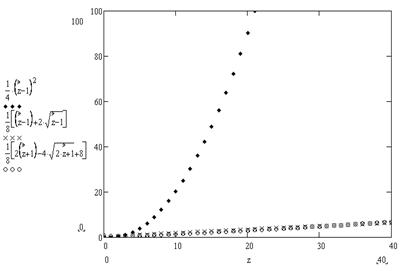
Рисунок 2 – Сравнение зависимости N(z) для случая d=1 (¨) с точными зависимостями N(zmax) (´) и N(zmin) (·) для случая d=2
Сравнение показывает, что отношение количества троек чисел при d = 1 к количеству пифагоровых троек чисел при d = 2 пропорционально числу 2(zmax - 1) и (zmax -3). Например, при величине числа z = 101 это отношение составляет 200 и 98 соответственно.
Визуальное сравнение этих зависимостей показывает, что возрастание количества пифагоровых троек чисел при d = 2 существенно ниже, чем возрастание количества троек чисел при d = 1.
На основе полученных результатов предположим, что структура зависимости количества троек от величины z сохраняется при возрастании величины параметра d. Тогда в линейном приближении коэффициент должен измениться в меньшую сторону и его величина может быть оценена как 1/16 (1/4 ® 1/8 ® 1/16). Показатель степени также должен уменьшиться до значения 0 (2 ® 1 ® 0). Следовательно, для d = 3 получим:
N(z) = 1/16 (z - 1)0 = 1/16.
Но 1/16 < 1, а значения целочисленной функции N(z) должны быть больше или равны единице. Поэтому получается, что для случая d = 3 вовсе нет троек чисел, которые удовлетворяли бы соотношению Ферма. Таким образом, подтверждается справедливость теоремы Ферма для случая d = 3.
Литература
1. Клейн, Ф. Элементарная математика с точки зрения высшей. Арифметика, алгебра, анализ / Ф. Клейн. – М.: Наука, 1987. – 432 с.
2. Спиридонов, из аспектов Большой теоремы Ферма / , // Инновационные технологии: производство, экономика, образование: Материалы Всероссийской научно-практической конференции 24 сентября 2009 года. – Бийск, Изд-во АлтГТУ, 2009. – С. 98-99 – С. 127-129.
К ВОПРОСУ АВТОМАТИЗАЦИИ БИБЛИОТЕЧНОЙ ДЕЯТЕЛЬНОСТИ БИЙСКОГО ТЕХНОЛОГИЧЕСКОГО ИНСТИТУТА
, ,
Бийский технологический институт АлтГТУ им.
Особое место в успешной организации научно-исследовательской работы и образовательного процесса в ВУЗе занимают автоматизированные библиотечные информационные системы. В этой связи Бийским технологическим институтом (БТИ) в 2008 году была приобретена автоматизированная библиотечная система (АБИС) «ИРБИС-64», которая обеспечивает управление процессом формирования библиотечного фонда, оперативный доступ пользователям к библиографическим описаниям книг, хранящихся в базах данных (БД), электронную книговыдачу учебных и научных изданий, а также формирование необходимых форм отчётных документов. В состав приобретенной системы входят серверные программные модули, автоматизированные рабочие места (АРМ «Администратор», АРМ «Каталогизатор», АРМ «Комплектатор», АРМ «Книговыдача», АРМ «Книгообеспеченность»), а также шлюзы для доступа к базам данных через Интернет − Web-«ИРБИС» и Z-«ИРБИС», работающий по протоколу Z39.50.
Для успешного внедрения АБИС «ИРБИС-64» в БТИ АлтГТУ были решены первоочередные задачи:
- разработан пакет документов для сотрудников библиотеки (инструкции по выполнению отдельных технологических процессов в системе «ИРБИС», регламенты, памятки и т. д.) и проведен обучаю-щий семинар;
- приобретено компьютерное оборудование для работы с автома-тизированной системой «ИРБИС» (сканеры штрих-кодов, специализи-рованные принтеры, аппликатор этикеток);
- конвертированы библиографические описания книг (более 18 тыс.) из уже существующего электронного каталога в БД «ИРБИС» и введены сведения о новых изданиях;
- присвоены штрих-коды экземплярам книг библиотечного фонда;
- введены сведения о студентах, аспирантах, преподавателях и сотрудниках института в базу данных читателей АБИС «ИРБИС»;
- сформированы программными средствами АБИС «ИРБИС» читательские билеты;
- установлено и настроено программное обеспечение Web-«ИРБИС» [1];
- разработан библиотечный портал для доступа к информационным ресурсам ВУЗа (http://irbis. bti. *****/irbis64r_72 ).
В этом году библиотека БТИ АлтГТУ заключила договор об участии в проекте «Сводная база данных статей г. Барнаул». Сводный каталог ведется с 2005 года библиотеками Алтайского края, где расписываются статьи из 139 журналов общественного и гуманитарного направлений.
Библиотека Алтайского государственного технического университета имеет доступ к базе данных МАРС (Межрегиональной Аналитической Росписи Статей) на платной основе. Данный проект существует уже с 2001 года и в настоящее время объединяет 187 библиотек различных систем и ведомств, которые общими усилиями создают сводную базу данных, содержащую полную аналитическую роспись 1648 журналов. Являясь филиалом АлтГТУ, читателям нашего института также предоставляется доступ к БД МАРС, но лишь в авторизированном режиме.
В целом комплекс проведенных работ по решению поставленных задач позволил в кратчайшие сроки запустить в эксплуатацию электронную книговыдачу для студентов ВУЗа, обеспечить доступ пользователей к БД электронного библиотечного каталога через Web-интерфейс [1].
В настоящее время ведутся работы по наполнению БД электронного каталога новыми библиографическими описаниями книг, внедряется программный модуль АРМа «Книгообеспеченность», устанавливается взаимодействие с Алтайской корпоративной информационно-библиотечной системой на основе протокола Z39.50.
Литература
1. Плотникова, Л. С., Ануфриева, Н. Ю., Суханова, -зация библиотечной деятельности Бийского технологического института [Текст] // Инновационные технологии: производство, экономика, образование: материалы Всероссийской научно-практи-ческой конференции 24 сентября 2009 года / под ред. ; Алт. гос. техн. ун-т, БТИ. – Бийск: Изд-во Алт. гос. техн. ун-та, 2009. – с. 39-40.
ИСПОЛЬЗОВАНИЕ СРЕДЫ «STRATUM 2000» ДЛЯ ОБУЧЕНИЯ ШКОЛЬНИКОВ ОСНОВАМ КОМПЬЮТЕРНОГО МОДЕЛИРОВАНИЯ
И. А. Cычев
Алтайская государственная академия образования
им. , г. Бийск
Содержательная линия «Моделирование и формализация» имеет особое значение в курсе «Информатика и ИКТ» общеобразовательной школы. Эта линия ориентирована на формирование системного мышления школьников, актуализацию межпредметных связей. Учебные программы школьного курса информатики конца 80-х начала 90-х годов XX века опирались на математическое моделирование посредством алгоритмических языков (Basic, Pascal). Действительно, разработка простейших математических моделей в среде Turbo-Pascal, по оценкам многих педагогов, часто обладает существенным развивающим потенциалом [1, 2]. Вместе с тем, разработка сложных и объёмных проектов в подобных средах требует значительных затрат времени на программирование ввода-вывода, оформление интерфейса программы, отладку.
Другим средством для обучения компьютерному моделированию являются электронные таблицы, которые позволяют решать широкий круг задач и, в то же время, просты в освоении и использовании. Одним из достоинств электронных таблиц является то, что некоторые дополнительные компоненты (например, «Поиск решения» в Microsoft Excel) скрывают от школьников сложные вычислительные процедуры, предоставляя возможности для моделирования из разных предметных областей. В некоторых учебных пособиях моделирование в среде электронных таблиц рассматривается как альтернатива «классическому» программированию () [3].
Наряду с языками программирования и электронными таблицами существует еще одна категория программного обеспечения, значение и место которой в школьном курсе информатики пока еще не оценено в полной мере – это среды визуального моделирования. Среда визуального моделирования «Stratum 2000» – программное средство для моделирования систем и процессов из различных областей знаний (физика, биология, астрономия, экология, экономика и др.), которое имеет интуитивно понятный пользовательский интерфейс и позволяет наглядно решать сложные задачи, математическое описание которых может выходить за пределы школьной программы.
Среда «Stratum 2000» была разработана в Пермском государственном техническом университете группой программистов под руководством (http://stratum. pstu. *****). Среда не требовательна к ресурсам, существует бесплатная версия программы. В бесплатной версии ограничен размер проекта, который могут разрабатывать учащиеся, вместе с тем она является вполне пригодной для знакомства школьников с основами компьютерного моделирования.
В среде «Stratum 2000» учащиеся могут не просто быстро и легко разрабатывать модели из различных предметных областей, но и «оживлять» и «озвучивать» свои разработки. Среда предоставляет возможность не только анимировать созданные модели (например, вращение Земли вокруг Солнца), но включать в проекты видеофрагменты. Графические возможности «Stratum 2000» позволяют моделировать карты, планы, чертежи, макеты различных конструкций. Для проверки знаний учащихся в среде «Stratum 2000» возможна разработка тестов и кроссвордов.
В состав «Stratum 2000» входит текстовый редактор, графический двухмерный и трехмерный редактор, база данных, база моделей, математический решатель, звуковой и видео проигрыватели и другие средства. Любая модель в «Stratum 2000» разрабатывается в удобной визуальной среде конструирования как совокупность объектов – «имиджей» и связей между ними. Каждый имидж, помимо пиктограммы на экране, имеет определенный набор свойств. Поведение имиджа описывает «текст» – математические выражения или алгоритмы. Имиджи хранятся в библиотеках. Схема, составленная из имиджей, обладает интегративными свойствами, обусловленными связями имиджей.
Эффективность применения среды «Stratum 2000» в обучении школьников компьютерному моделированию достигается за счет сведения к минимуму ручного программирования и лёгкой модификации построенной модели. Уже на ранних стадиях разработки учащийся может видеть результаты работы системы, анализировать и оценивать решение, при этом многие математические проблемы, связанные с численными методами оказываются скрытыми от учащихся. Учащийся может выполнить в любой момент времени расчет модели в пошаговом режиме. «Stratum 2000» позволяет изменять параметры модели даже во время выполнения – доступны просмотр и изменение значения любых переменных. При конструировании сложных моделей возможно использование графики, звука или видео, что существенно повышает наглядность разрабатываемых моделей. Редактор трёхмерной графики позволяет работать с объёмными изображениями, встраивая их в создаваемую модель.
Таким образом, все вышеперечисленные достоинства «Stratum 2000» позволяют выделить это средство как достаточно эффективный инструмент для обучения школьников основам компьютерного моделирования в курсе «Информатика и ИКТ».
Литература
1. Бешенков, и формализация [Текст] : Методическое пособие / , . – М.: Лаборатория Базовых Знаний, 2002. – 336 с.
2. Казиев, математического и инфологического моделирования в примерах [Текст] / , // Информатика и образование. – 2004. – № 1. – C. 39-46.
3. Макарова, и ИКТ: Задачник по моделированию: 9‑11 класс: Базовый уровень [Текст]: Учебное пособие / , , ; Под ред. – СПб.: Питер, 2007. – 192 с.
РАЗРАБОТКА HR-СИСТЕМЫ ПОРТАЛЬНОГО ТИПА. ИССЛЕДОВАНИЕ МЕТОДОВ ПОВЫШЕНИЯ ПРОИЗВОДИТЕЛЬНОСТИ
НГУ, г. Новосибирск
Значительная часть проблем предприятия связана с управлением человеческими ресурсами. Человеческий ресурс – главный актив компании, который влияет на ее развитие, позиционирование на рынке, финансовые результаты и т. д. И одновременно этот ресурс в силу своей уникальности может стать и самым дорогим ресурсом предприятия в плане издержек и финансовых потерь.
Первоочередными задачами, связанными с персоналом, которые необходимо решать любой компании, можно считать следующие: выработка политики по персоналу, планирование развития персонала (включая карьерный рост и формирование кадрового резерва), подбор, обучение, аттестация, учет трудозатрат и оплата труда, поддержание дисциплины труда, разработка мотивационных схем и компенсационных пакетов, планирование и реализация социальной политики.
Для эффективного решения этих задач можно либо значительно расширить штат квалифицированных специалистов в сфере HR-управления, либо же принять на вооружение автоматизированную информационную систему, которая сможет учитывать все процессы, встроенные в замкнутый цикл управления. Только при таких условиях предприятие способно в полном объеме решать основную задачу управления персоналом: распределять количество и качество сотрудников таким образом, чтобы в каждый момент времени они соответствовали возложенным на них функциям и обязанностям. Выбор именно информационной системы управления персоналом, на мой взгляд, дело времени. Раньше или позже, но большая часть компаний, ориентированных длительно работать на рынке, отдадут свое предпочтение HR-системам. Разработке именно такой системы посвящена данная работа.
Первоначально был проделан обзор современного рынка автоматизированных систем управления персоналом. Был рассмотрен ряд отечественных и зарубежных систем управления персоналом (такие как SAP Human Resources Management System, Oracle Human Resources Analyzer, БОСС-Кадровик, TRIM-Персонал и др.) На основе проведенного анализа выделены функциональные и архитектурные требования, предъявляемые к системам данного типа, а также основные тенденции в развитии рынка HR-систем. В силу направленности современных предприятий на использование корпоративных порталов и постепенное смещение интересов бизнеса в Интернет, было принято решение о реализации системы в виде портального решения.
Далее было проведено исследование портальных платформ – были рассмотрены следующие решения: IBM WebSphere Portal, Oracle AS Portal 10G, SAP Enterprise Portal, Microsoft Office Sharepoint Server. Исходя из инструментария, предлагаемого рассматриваемыми платформами, и тенденций развития рынка портальных решений было принято решение об использовании платформы Microsoft Office Sharepoint Server.

|
Из за большого объема эта статья размещена на нескольких страницах:
1 2 3 4 5 6 7 |
