

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Смещение – разность между математическим ожиданием оценки и истинным значением оцениваемого параметра, а несмещенная оценка – оценка, имеющая нулевое смещение.
Проверим, будут ли введенные нами оценки смещенными. Начнем с выборочного среднего ![]() . Является ли оно несмещенной оценкой математического ожидания? Верно ли, что
. Является ли оно несмещенной оценкой математического ожидания? Верно ли, что ![]() ?
?
Еще раз подчеркнем, что m – математическое ожидание для всей генеральной совокупности, а следовательно, фиксированное число, хотя, как правило, неизвестное, ![]() – оценка данной характеристики, построенная по определенному правилу на основании выборки. Величина
– оценка данной характеристики, построенная по определенному правилу на основании выборки. Величина ![]() включает две составляющие m и
включает две составляющие m и ![]() . Из (1.5) следует, что
. Из (1.5) следует, что ![]() , а следовательно,
, а следовательно, ![]() .
.
Тогда
![]() . (1.12)
. (1.12)
Таким образом, выборочное среднее ![]() построенное по данным выборки (х1,х2,...,хn), является несмещенной оценкой математического ожидания m..
построенное по данным выборки (х1,х2,...,хn), является несмещенной оценкой математического ожидания m..
Аналогично, используя свойства математического ожидания, можно доказать, что оценка ![]() также является несмещенной оценкой математического ожидания.
также является несмещенной оценкой математического ожидания.
Рассмотрим величину s2. Можно показать, что математическое ожидание s2 равно s2, если наблюдения в выборке независимы. Причем несмещенность этой оценки обеспечивается коэффициентом 1/(n-1).
Однако вначале рассмотрим выборочную дисперсию ![]() , построенную по аналогии с оценкой математического ожидания. Для выборки (х1,х2,...,хn) выборочная дисперсия определяется следующим образом:
, построенную по аналогии с оценкой математического ожидания. Для выборки (х1,х2,...,хn) выборочная дисперсия определяется следующим образом:
![]() . (1.13)
. (1.13)
Проверим, является ли эта выборочная оценка дисперсии несмещенной. Однако сначала найдем дисперсию оценки среднего ![]() при условии, что элементы выборки независимых и одинаково распределенных случайные величины с дисперсией
при условии, что элементы выборки независимых и одинаково распределенных случайные величины с дисперсией ![]() .
.
. (1.14)
Данное равенство непосредственно вытекает из правил вычисления дисперсии. В этом случае среднеквадратичное отклонение будет иметь вид ![]() .
.
Будем считать случайную величину x нормально распределенной, следовательно, все элементы выборки также нормально распределены.
Замечание
Понятие нормально распределенной случайной довольно подробно изучается в курсе теории вероятностей. Однако, поскольку данное распределение имеет огромное значение, его, а также все основные распределения, которые используются в эконометрике, и свойства данных распределений нами будут рассматриваться позже.
В этом случае можно показать, что ![]() также имеет нормальное распределение, то есть
также имеет нормальное распределение, то есть ![]() , так же как и x, симметрично относительно m. Величина
, так же как и x, симметрично относительно m. Величина ![]() , вероятно, должна быть ближе к m, чем значение единичного наблюдения x, поскольку ее случайная составляющая
, вероятно, должна быть ближе к m, чем значение единичного наблюдения x, поскольку ее случайная составляющая ![]() есть среднее от случайных составляющих в выборке, которые, по-видимому, “гасят” друг друга при расчете среднего. Именно это и следует из формулы (1.14), которая говорит о том, что дисперсия величины
есть среднее от случайных составляющих в выборке, которые, по-видимому, “гасят” друг друга при расчете среднего. Именно это и следует из формулы (1.14), которая говорит о том, что дисперсия величины ![]() меньше, чем дисперсия x. Тогда
меньше, чем дисперсия x. Тогда
Следовательно, данная оценка является смещенной, причем смещение отрицательное и равно ![]() . Однако если взять множитель
. Однако если взять множитель ![]() , то оценка
, то оценка ![]() будет несмещенной, поскольку
будет несмещенной, поскольку
.
Итак, можно сделать следующие выводы:
1. Случайная величина x в генеральной совокупности имеет некоторое фиксированное математическое ожидание m и дисперсию s2. Данные значения, как правило, неизвестны и их необходимо оценивать.
2. Оценка является несмещаемой оценкой дисперсии.
3. Выборочная дисперсия ![]() является смещенной оценкой дисперсии генеральной совокупности, при этом данная оценка занижает значение истинной дисперсии.
является смещенной оценкой дисперсии генеральной совокупности, при этом данная оценка занижает значение истинной дисперсии.
4. Данные две оценки между собой связаны следующим соотношением ![]() , то есть множитель
, то есть множитель ![]() делает из выборочной дисперсии несмещаемую оценку. При бесконечном увеличении числа элементов в выборке n эти две оценки дисперсии совпадают между собой.
делает из выборочной дисперсии несмещаемую оценку. При бесконечном увеличении числа элементов в выборке n эти две оценки дисперсии совпадают между собой.
Правила, которые рассматривались ранее, и предназначались для вычисления теоретической дисперсии в равной степени можно использовать и для выборочной дисперсии.
Коэффициенты ковариации и корреляции тоже, как правило, являются фиксированными, но неизвестными значениями, которые также необходимо оценивать. Выборочная ковариация 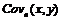 при наличии выборки размером n из двух генеральных совокупностей (х1,х2,...,хn) и (y1,y2,...,yn) задается формулой:
при наличии выборки размером n из двух генеральных совокупностей (х1,х2,...,хn) и (y1,y2,...,yn) задается формулой:
![]() . (1.15)
. (1.15)
К сожалению, оценка будет иметь отрицательное смещение, так как
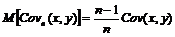 ,
,
где ![]() – корреляция между двумя случайными величинами x и y во всей генеральной совокупности. Данное утверждение легко доказать самостоятельно.
– корреляция между двумя случайными величинами x и y во всей генеральной совокупности. Данное утверждение легко доказать самостоятельно.
Выборочный коэффициент корреляции rxy определяется путем замены теоретических дисперсий и ковариации в выражении на их несмещенные оценки. Мы показали, что такие оценки могут быть получены умножением выборочных дисперсий и ковариации на n/(n –1). Следовательно,
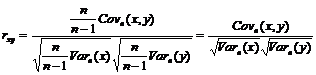 . (1.16)
. (1.16)
Несмещенность — желательное, но не единственное свойство оценок. Еще одна важная их сторона — это надежность. Хотелось бы, чтобы наша оценка с максимально возможной вероятностью давала бы близкое значение к теоретической характеристике, что означает желание получить оценку со сколь возможно малой дисперсией.
 Эффективная оценка – это оценка, имеющая наименьшую дисперсию среди всех оценок. Даже хотя оценка более эффективна, это не означает, что она всегда дает более точное значение. Для оценки желательна несмещенность и эффективность. Эти критерии различны, и иногда они могут противоречить друг другу.
Эффективная оценка – это оценка, имеющая наименьшую дисперсию среди всех оценок. Даже хотя оценка более эффективна, это не означает, что она всегда дает более точное значение. Для оценки желательна несмещенность и эффективность. Эти критерии различны, и иногда они могут противоречить друг другу.
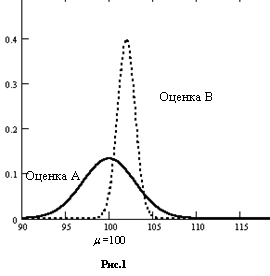
Может случиться так, что имеются две оценки теоретической характеристики, одна из которых является несмещенной А (рис. 1), другая же смещена, но имеет меньшую дисперсию В. Оценка А хороша своей несмещенностью, но преимущество оценки B в том, что её практические значения всегда близки к истинному значению. Какую из них вы бы выбрали?
Данный выбор зависит от обстоятельств. Если возможные ошибки не очень тревожат при условии, что за длительный период они “погасят” друг друга, то, по-видимому, лучше выбрать А. С другой стороны, если приемлемы малые ошибки, но неприемлемы большие, то следует выбрать оценку B.
Будем по-прежнему предполагать, что мы исследуем случайную переменную x с неизвестным математическим ожиданием m и теоретической дисперсией s2 и что для оценивания m используется ![]() . Каким образом точность оценки
. Каким образом точность оценки ![]() зависит от числа наблюдений n?
зависит от числа наблюдений n?
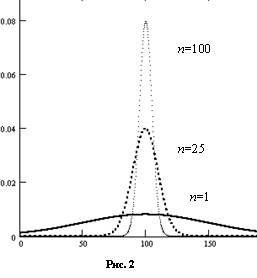 При увеличении n оценка
При увеличении n оценка ![]() , становится более точной. Поскольку дисперсия
, становится более точной. Поскольку дисперсия ![]() выражается формулой (1.13), она тем меньше, чем больше размер выборки и, значит, тем сильнее “сжата” функция плотности вероятности для
выражается формулой (1.13), она тем меньше, чем больше размер выборки и, значит, тем сильнее “сжата” функция плотности вероятности для ![]() .
.
Предполагаем, что x нормально распределена со средним 100 и стандартным отклонением 50. Если размер выборки равен 25, то стандартное отклонение величины ![]() равное
равное 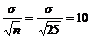 . Если размер выборки равен 100, то это стандартное отклонение равно 5. Чем больше размер выборки, тем уже и выше будет график функции плотности вероятности для
. Если размер выборки равен 100, то это стандартное отклонение равно 5. Чем больше размер выборки, тем уже и выше будет график функции плотности вероятности для ![]() . Если n становится большим, то график функции плотности вероятности будет неотличим от вертикальной прямой, соответствующей
. Если n становится большим, то график функции плотности вероятности будет неотличим от вертикальной прямой, соответствующей ![]() . Для такой выборки случайная составляющая х становится очень малой, и поэтому
. Для такой выборки случайная составляющая х становится очень малой, и поэтому ![]() обязательно будет очень близкой к m. Три функции плотности изображены на рисунке 2, соответственно для трех возможных значений n.
обязательно будет очень близкой к m. Три функции плотности изображены на рисунке 2, соответственно для трех возможных значений n.
В пределе, при стремлении n к бесконечности, ![]() стремится к нулю и
стремится к нулю и ![]() стремится к m. Это можно записать математически:
стремится к m. Это можно записать математически: ![]() .
.
Эквивалентный и более распространенный способ описания этого факта предлагает использование термина plim, где plim означает предел по вероятности и подчеркивает, что предел достигается в вероятностном смысле: ![]() .
.
Состоятельной называется такая оценка, которая дает точное значение для большой выборки независимо от входящих в нее конкретных наблюдений. Состоятельная оценка – оценка, у которой дисперсия стремится к 0, при увеличении объема выборки. То, что в конечном счете она превращается в единственную точку истинного значения, говорит о состоятельности оценки.
Данные свойства оценок весьма важны в регрессионном анализе. Иногда невозможно найти оценку, несмещенную на малых выборках. Если при этом можно найти хотя бы состоятельную оценку, это может быть лучше, чем не иметь никакой оценки. Иногда состоятельная оценка может на малых выборках работать хуже, чем несостоятельная (например, иметь большую среднеквадратичную ошибку), и поэтому требуется осторожность. Подобно тому, как можно предпочесть смещенную оценку несмещенной, если ее дисперсия меньше, можно предпочесть состоятельную, но смещенную оценку несмещенной или несостоятельную оценку им обеим (также в случае меньшей дисперсии).
1.4. Метод Монте-Карло
Для решения вероятностных задач, в которых не удается установить формальную зависимость конечного результата от исходных данных, используется метод Монте-Карло (метод статистических испытаний). При оценивании параметров генеральной совокупности проблема заключается в том, что никогда не знаем истинных значений этих параметров и поэтому не можем сказать, хорошие или плохие оценки дает наш метод. Эксперимент по методу Монте-Карло дает нам такую возможность.
Эксперимент по методу Монте-Карло – искусственный, контролируемый эксперимент, проводимый для проверки и сравнения эффективности различных статистических методов.
Эксперимент по методу Монте-Карло заключается в следующем. Чтобы узнать, насколько близкие к истине ответы дает та или иная оценка исследователь сам задает все параметры модели, с помощью датчика случайных чисел моделирует наблюдения и к получившейся выборке применяет оценку. Такой эксперимент проводится много раз с различными значениями случайных чисел, после этого полученные результаты сравниваются с заданными и делается вывод о качестве оценки.
Метод статистических испытаний применяют для решения не только тех задач, в которых в явном виде имеются случайные явления, но также и для решения многих математических задач, не содержащих таких явлений. В этом случае искусственно подбирается такое случайное явление, характеристики которого связаны с результатом решения исходной задачи. Для определения числовых значений этих характеристик используется метод статистических испытаний.
§ 2. Метод наименьших квадратов
2.1. Модель парной регрессии
Коэффициент корреляции показывает, что две случайные величины связаны друг с другом, однако он не дает представления о том, каким образом они связаны. Рассмотрим более подробно те случаи, когда одна переменная зависит от другой.
Не следует ожидать получения точного соотношения между какими-либо двумя экономическими показателями, однако факт неточности соотношения признается путем явного включения в модель случайного фактора.
При этом модель понимается как совокупность переменных и связей между ними в форме уравнений, описывающих зависимость между наблюдаемыми переменными.
Начнем с рассмотрения модели парной линейной регрессии зависимости между двумя переменными:
у=a+b×х + u (2.1)
В модели парной регрессии рассматриваются три переменные.
Зависимая переменная регрессии – переменная величина в модели парной регрессии, которую считают (по экономическим соображениям) зависящей от другой переменной. В модели зависимая переменная y.
Объясняющая переменная регрессии (регрессор) – переменная величина в модели парной регрессии, от которой зависит (по экономическим соображениям) зависимая переменная. В модели объясняющая переменная x.
Случайный член регрессии – слагаемое u в модели, которое описывает воздействие случайных факторов.
Задача регрессионного анализа состоит в получении оценок a и b. Очевидно, что чем меньше значения u, тем легче эта задача.
Рассмотрим пример. Будем полагать, что некоторому значению цены (обозначим её через x) соответствует некоторое значение спроса (y). На основании экономической теории можно предполагать, что данные значения связаны между собой некоторым линейным законом. Поскольку x и y некоторые случайные величины, для которых в качестве генеральной совокупности выступает произвольное значение цены и спроса, попытаемся установить вид данной зависимости на основе выборочных данных (х1,х2,...,хn) и (y1,y2,...,yn). Далее для упрощения записи подобного рода выборки будем обозначить как 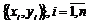 .
.
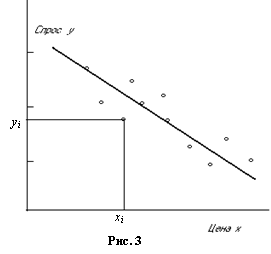 Элементы данной выборки можно представить графически. Каждому элементу выборки соответствует точка плоскости (рис. 3).
Элементы данной выборки можно представить графически. Каждому элементу выборки соответствует точка плоскости (рис. 3).
Если бы соотношение между ценой и спросом задавалось линейным законом, то все наблюдения принадлежали бы одной прямой. На самом деле точки лежат рядом с прямой. И отклонение зависит от значения случайного члена. Если бы случайный член отсутствовал вовсе, то точки принадлежали бы прямой и точно показали бы её положение. В этом случае достаточно было бы просто построить эту прямую и определить значения a и b.
Почему же существует случайный член? Имеется несколько причин
1. Невключение объясняющих переменных. Соотношение между у и x почти наверняка является очень большим упрощением. В действительности существуют другие факторы, влияющие на у, которые не учтены в модели (2.1). Влияние этих факторов приводит к тому, что наблюдаемые точки лежат вне прямой. Возможно, что существуют также другие факторы, которые оказывают такое слабое влияние, что их не стоит учитывать (в данном примере это может быть значение дохода или цены на другие продукты). Кроме того, могут быть факторы, которые являются существенными, но почему-то таковыми не считаем. Если бы точно знали, какие переменные присутствуют и имели возможность точно их измерить, то могли бы включить их в уравнение. Проблема состоит в том, что мы никогда не можем быть уверены, какие факторы влияют, а какие нет. Проблема включения или невключения новых регрессоров в модель будет рассмотрена нами позже, при изучении множественной регрессии.
2. Неправильное описание структуры модели. Структура модели может быть описана неправильно или не вполне правильно. Например, можно пытаться строить модель линейной связи, хотя на самом деле переменные зависят друг от друга по другому закону (показательному, логарифмическому или степенному). Данная проблема будет изучена при рассмотрении нелинейной регрессионной модели.
3. Ошибки измерения. Если в измерении одной или более взаимосвязанных переменных имеются ошибки, то наблюдаемые значения не будут соответствовать точному соотношению, и существующее расхождение будет вносить вклад в случайный член.
Остаточный член является суммарным проявлением всех этих факторов. Иногда остаточный член u описывают как шум.
2.2. Регрессия по методу наименьших квадратов
Уравнение линейной регрессии – уравнение у=а+b×x, где а и b – оценки параметров a и b, полученные в результате оценивания модели по данным выборки 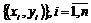 .
.
Мы никогда не сможем рассчитать истинные a. и b, но можно получить оценки. Иногда оценки могут быть абсолютно точными, но это возможно лишь в результате случайного совпадения, и даже в этом случае не будет способа узнать, что оценки абсолютно точны. Возникает вопрос: существует ли способ достаточно точной оценки a и b?
Вначале дадим определение остатка для каждого наблюдения.
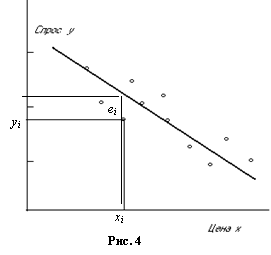 Остаток в i-ом наблюдении –
Остаток в i-ом наблюдении – ![]() разность между истинным значением переменной
разность между истинным значением переменной ![]() в i-ом наблюдении и значением
в i-ом наблюдении и значением ![]() , полученным подстановкой наблюдения xi в уравнение линейной регрессии (рис. 4). За исключением случаев чистого совпадения, остаток в наблюдении будет отличен от нуля. Если ввести обозначение
, полученным подстановкой наблюдения xi в уравнение линейной регрессии (рис. 4). За исключением случаев чистого совпадения, остаток в наблюдении будет отличен от нуля. Если ввести обозначение 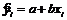 , то точка с координатами
, то точка с координатами ![]() будет лежать на линии регрессии. Величина
будет лежать на линии регрессии. Величина ![]() – расчетное значение у в i-ом наблюдении (точечный прогноз). Это значение, которое имел бы у при условии, что уравнение регрессии было правильным и отсутствовал случайный фактор.
– расчетное значение у в i-ом наблюдении (точечный прогноз). Это значение, которое имел бы у при условии, что уравнение регрессии было правильным и отсутствовал случайный фактор.
Используя математическую запись, остатки в каждом наблюдении представим в следующем виде:
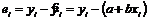 .
.
Необходимо выбрать какой-то критерий, который будет одновременно учитывать величину всех остатков. Существует целый ряд возможных критериев.
Например, можно минимизировать сумму остатков:
![]() .
.
Однако данная сумма будет автоматически равна нулю, если сделаете a равным среднему значению ![]() , a b равным нулю, получив горизонтальную линию
, a b равным нулю, получив горизонтальную линию ![]() . В этом случае положительные остатки точно уравновесят отрицательные и общая сумма будет равна нулю.
. В этом случае положительные остатки точно уравновесят отрицательные и общая сумма будет равна нулю.
Можно минимизировать сумму модулей остатков:
![]() .
.
Однако в данном случае ![]() не будет дифференцируемой, что значительно усложнит дальнейшие математические выкладки.
не будет дифференцируемой, что значительно усложнит дальнейшие математические выкладки.
Как привило, минимизируют суммы квадратов остатков:
![]() . (2.2)
. (2.2)
Величина S, будет зависеть от выбора а и b, так как они определяют положение линии регрессии. В соответствии с этим критерием, чем меньше S, тем строже соответствие. Если S = 0, то получено абсолютно точное соответствие, так как это означает, что все остатки равны нулю. В этом случае линия регрессии будет проходить через все точки, однако, вообще говоря, это невозможно из-за наличия случайного члена.
Метод наименьших квадратов (МНК) (OLS – Ordinary Least Squares) – метод нахождения оценок параметров регрессии, основанный на минимизации суммы квадратов остатков всех наблюдений. При выполнении определенных условий метод наименьших квадратов дает несмещенные и эффективные оценки для a и b.
Заметим, что данное выражение S является квадратичной. Если предположить, что значение выборки зафиксировано, то влиять на величину S можно, изменяя значения a и b, следовательно, S является функцией a и b. Для того чтобы величина S была минимальной, необходимо, чтобы частные производные равнялись нулю, то есть
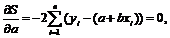 (2.3)
(2.3)
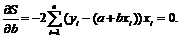
Эти уравнения известны как нормальные уравнения для коэффициентов регрессии. Используя обозначение для средних значений эти уравнения можно переписать в виде:
![]()
Решая полученные уравнения относительно a и b, можно получить следующую систему уравнений:
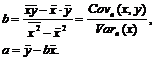 (2.4)
(2.4)
Нетрудно видеть, что если значение a и b задаются уравнениями (2.4), то данная прямая проходит через точку ![]() , которая называется центром рассеивания.
, которая называется центром рассеивания.
При интерпретации уравнения регрессии чрезвычайно важно помнить о следующем:
во-первых, a является лишь оценкой a, а b – оценкой b. Поэтому вся интерпретация в действительности представляет собой лишь оценку;
во-вторых, уравнение регрессии отражает только общую тенденцию для выборки. При этом каждое отдельное наблюдение подвержено воздействию случайностей.
”Наилучшая” по МНК прямая линия всегда существует, но даже наилучшая не всегда является достаточно хорошей. Если в действительности зависимость y=f(x) является, например, квадратичной, то ее не сможет адекватно описать никакая линейная функция, хотя среди всех таких функций обязательно найдется наилучшая. Если величины x и у вообще не связаны, то всегда сможем найти наилучшую линейную функцию для данной выборки. Но в этом случае конкретные значения а и b являются случайными переменными, и сами будут очень сильно меняться для различных выборок.
2.3. Коэффициент детерминации R2
Разброс значений y в любой выборке можно суммарно описать с помощью выборочной дисперсии, то есть вычислить значение:
![]() .
.
Цель регрессионного анализа состоит в объяснении поведения переменной у. В парном регрессионном анализе пытаемся объяснить поведение y путем определения регрессионной зависимости у от независимой x.
На основании формулы (2.2) можно разложить выборочную дисперсию y на составляющие:
![]() .
.
Поскольку ![]() построено по соответствующим значениям x и не зависит от e, то
построено по соответствующим значениям x и не зависит от e, то ![]() должна быть равна нулю.
должна быть равна нулю.
Следовательно:
![]() (2.5)
(2.5)
Это означает, что мы можем разложить дисперсию y на две части: ![]() – часть, которая объясняется уравнением регрессии, и
– часть, которая объясняется уравнением регрессии, и ![]() – необъясненная часть.
– необъясненная часть.
Другими словами,
объясненная дисперсия зависимой переменной – выборочная дисперсия расчетных значений величины у:
![]() ;
;
необъясненная дисперсия зависимой переменной – выборочная дисперсия остатков e в наблюдениях 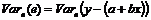 .
.
Отношение 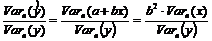 – часть дисперсии у, которая может быть объяснена уравнением регрессии. Это отношение называется коэффициент детерминации и обозначается R2:
– часть дисперсии у, которая может быть объяснена уравнением регрессии. Это отношение называется коэффициент детерминации и обозначается R2:
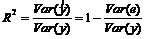 (2.6)
(2.6)
Таким образом, коэффициент детерминации R2 - доля объясненной дисперсии зависимой переменной во всей выборочной дисперсии у. C увеличением объясненной дисперсии коэффициент R2 приближается к единице.
Кроме различного рода выборочных дисперсий также широко используются суммы квадратов отклонений.
Общая сумма квадратов отклонений (TSS) – сумма квадратов отклонений величины у от своего выборочного среднего ![]() :
:
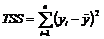 .
.
Объясненная сумма квадратов отклонений (RSS) – сумма квадратов отклонений величины ![]() от своего выборочного среднего
от своего выборочного среднего ![]() :
:
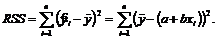
Необъясненная (остаточная) сумма квадратов отклонений (ESS) – сумма квадратов остатков всех наблюдений.
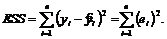
Отметим, что общая сумма квадратов отклонений равна: объясненная сумма квадратов отклонений плюс необъясненная сумма квадратов отклонений: TSS = RSS +ESS
Замечание.
В некоторой литературе для объясненной и необъясненной суммы квадратов отклонений используются другие обозначения. Например, USS – для необъясненной и ESS – для объясненной.
Используя данные определения, значение коэффициента детерминации будет:
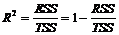 (2.6’)
(2.6’)
Покажем, что R2 равен квадрату выборочного коэффициента корреляции между у и x, при условии, что коэффициенты регрессии рассчитываются по методу наименьших квадратов и имеют вид (2.4), тогда
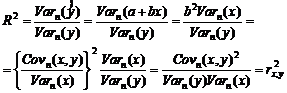
Коэффициент детерминации R2 для модели парной регрессии равен 1, если все наблюдения лежат на одной прямой – линии регрессии.
Если в выборке отсутствует видимая связь между у и x, то коэффициент R2 будет близок к нулю. При прочих равных условиях желательно, чтобы коэффициент R2 был как можно больше. В частности, мы заинтересованы в таком выборе коэффициентов a и b, чтобы максимизировать R2. Не противоречит ли это нашему критерию, в соответствии c которым a и b должны быть выбраны таким образом, чтобы минимизировать сумму квадратов остатков?
Нет, легко показать, что эти критерии эквиваленты. Отметим сначала, что
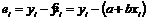 ,
,
откуда, взяв среднее значение ![]() по выборке, получим:
по выборке, получим:
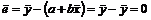 .
.
Следовательно,
![]() .
.
Отсюда следует, что принцип минимизации суммы квадратов остатков эквивалентен минимизации дисперсии остатков. Если мы минимизируем ![]() , то при этом в соответствии с определением детерминации автоматически максимизируем коэффициент R2. Тем самым МНК автоматически дает максимальное возможное для данной выборки значение коэффициента детерминации R2.
, то при этом в соответствии с определением детерминации автоматически максимизируем коэффициент R2. Тем самым МНК автоматически дает максимальное возможное для данной выборки значение коэффициента детерминации R2.
Поскольку коэффициент детерминации равен доле объясненной дисперсии в общей дисперсии, то данное значение можно интерпретировать как объясненный разброс. Например, значение R2=0.838 говорит о том, что 83.8% разброса зависимой переменной y объясняется регрессионной моделью и значениями регрессора x.
§ 3. Свойства коэффициентов регрессии
3.1. Теорема Гаусса–Маркова
Коэффициенты регрессии, вычисленные методом наименьших квадратов – это особая форма случайной величины, свойства которой зависят от свойств остаточного члена в уравнении.
В ходе рассмотрения постоянно будем иметь дело с моделью парной регрессии, в которой у связан с x следующей зависимостью:
у=a+b×х + u,
и на основе выборочных наблюдений ![]() будем оценивать уравнение регрессии:
будем оценивать уравнение регрессии:
у=а+b×x,
где а и b – оценки параметров a и b.
Будем предполагать, что x — это неслучайная (экзогенная) переменная, то есть ее значения во всех наблюдениях можно считать заранее заданными и никак не связанными с исследуемой зависимостью. Величина y состоит из двух составляющих. Она включает неслучайную составляющую (a+b×х), которая не имеет ничего общего с законами вероятности (a и b могут быть неизвестными, но тем не менее это постоянные величины), и случайную составляющую u.
Отсюда следует, что, используя метод наименьших квадратов, b вычисляется по формуле:
![]() ,
,
содержит случайную составляющую ![]() , зависит от значений у, а у зависит от значений u.
, зависит от значений у, а у зависит от значений u.
Если случайная составляющая принимает разные значения в n наблюдениях, то получаем различные значения у, и, следовательно, разные значения величин и b. Теоретически можем разложить b на случайную и неслучайную составляющие. Воспользовавшись соотношением, а также правилом расчета ковариации, получим:
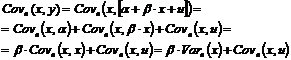
и, таким образом,
![]() . (3.1)
. (3.1)
Итак, коэффициент регрессии b, полученный по любой выборке, представляется в виде суммы двух слагаемых: постоянной величины, равной истинному значению коэффициента b и случайной составляющей, зависящий от ![]() , которой обусловлены отклонения коэффициента b от константы b. Аналогичным образом можно показать, что а имеет постоянную составляющую, равную истинному значению a, плюс случайную составляющую, которая также зависит от случайного фактора u.
, которой обусловлены отклонения коэффициента b от константы b. Аналогичным образом можно показать, что а имеет постоянную составляющую, равную истинному значению a, плюс случайную составляющую, которая также зависит от случайного фактора u.
Следует заметить, что на практике нельзя разложить коэффициенты регрессии на составляющие, так как не знаем истинных значений a и b и фактических значений u в выборке. Однако при определенных предположениях можно получить некоторую информацию об их теоретических свойствах.
Очевидно, что свойства коэффициентов регрессии существенным образом зависят от свойств случайной составляющей. В самом деле, для того, чтобы метод наименьших квадратов, давал наилучшие из всех возможных результаты, случайный член должен удовлетворять четырем условиям, известным как условия Гаусса–Маркова.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
