

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Оценив регрессионную зависимость производительности от вложенных средств, с учетом категорий, а следовательно, фиктивных переменных, получаем:
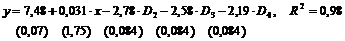
Из этого результата отдельные уравнения для каждой категории будут иметь вид:
1. ![]()
2. ![]()
3. ![]()
4. ![]()
9.3. Фиктивные переменные для коэффициентов наклона
До сих пор мы предполагали, что качественные переменные, введенные в уравнение регрессии, отвечают только за сдвиги в значении постоянного члена в уравнении регрессии, при этом неявно предположили, что наклон линии регрессии одинаков для каждой категории качественных переменных. Это предположение не обязательно верно, и теперь мы рассмотрим, как сделать его менее строгим.
Фиктивную переменную для коэффициента наклона – произведение фиктивной переменной, на нефиктивную переменную (регрессор).
Для объяснения использования фиктивной переменной рассматривалась модель:
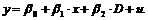
В этой формулировке модели мы предполагаем, что воздействие не меняет наклон линии регрессии. Рассмотрим теперь модель вида:
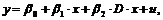 (9.3)
(9.3)
где b2 – коэффициент стоящей перед произведением фиктивной переменной D на нефиктивную переменную x.
Для случая D=0 уравнение принимает вид:
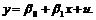 (9.3a)
(9.3a)
Для второго случая при D=1 уравнение принимает вид:
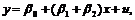 (9.3b)
(9.3b)
то есть в данном случае фиктивная переменная D влияет на наклон линии регрессии, при этом разница в наклонах равна значению b2.
Можно модифицировать данную модель, с тем, чтобы фиктивная переменная влияла бы на угол наклона и на значение свободного члена регрессии, в этом случае модель будет иметь вид:
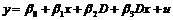 . (9.3)
. (9.3)
Для случая D=0 уравнение принимает вид:
(9.3a)
Для второго случая при D=1 уравнение принимает вид:
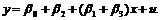 (9.3b)
(9.3b)
То есть, при условии D=1 изменяется наклон линии регрессии с b1 на b1+b3 и значение свободного члена с b0 на b0+b2.
Еще раз подчеркнем, что фиктивная переменная для коэффициента наклона предназначена для установления влияния категории не на свободный член регрессии, а на коэффициент регрессии при нефиктивной переменной.
Может случиться так, что переменная, которую требуется исследовать, является качественной по своему характеру, и принимающей значения 0 или 1, в зависимости произошло какое-либо событие или нет. В этом случае зависимой переменной y является фиктивной, переменной и можно оценить регрессию обычным способом. Тогда спрогнозированное значение y можно интерпретировать как вероятность наступления некоторого события.
§ 10. Гетероскедастичность
10.1. Определение гетероскедастичности
Свойства оценок коэффициентов регрессии зависят от свойств случайного члена в регрессионной модели. До сих пор мы предполагали, что выполняются все условия Гаусса–Маркова.
 Второе условие Гаусса–Маркова указывают, что случайные члены
Второе условие Гаусса–Маркова указывают, что случайные члены ![]() ,
,![]() ,...,
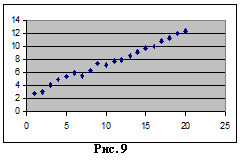
,...,![]() в n наблюдениях имеют одну и ту же дисперсию. Вероятность того, что величина u примет какое-то данное положительное (или отрицательное) значение, будет одинаковой для всех наблюдений. Это условие известно как гомоскедастичность, что означает одинаковый разброс. Пример гомоскедастичности приведен на рисунке 9.
в n наблюдениях имеют одну и ту же дисперсию. Вероятность того, что величина u примет какое-то данное положительное (или отрицательное) значение, будет одинаковой для всех наблюдений. Это условие известно как гомоскедастичность, что означает одинаковый разброс. Пример гомоскедастичности приведен на рисунке 9.
Вместе с тем, для некоторых выборок возможно более целесообразно предположить, что теоретическое распределение случайного члена является разным для различных наблюдений в выборке. Это не означает, что случайный член обязательно будет иметь особенно большие (положительные или отрицательные) значения в конце выборки, но это значит, что априорная вероятность получения сильно отклоненных величин будет относительно высока. Это пример гетероскедастичности, что означает неодинаковый разброс. Математически гомоскедастичность и гетероскедастичность могут определяться следующим образом:
Гомоскедастичность: 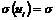 постоянна для всех наблюдений;
постоянна для всех наблюдений;
Гетероскедастичность: 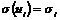 не обязательно одинакова.
не обязательно одинакова.
Таким образом, гетероскедастичность – это нарушение второго условия теоремы Гаусса–Маркова, которое пока не использовалось в доказательстве несмещенности оценок.
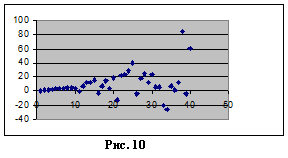
На рисунке 10 показано как будет выглядеть характерная диаграмма рассеяния, если у – возрастающая функция от x и имеется гетероскедастичность. Хотя наблюдения не обязательно все дальше отстоят от линии регрессии  , по мере роста x все же имеется тенденция к увеличению их разброса.
, по мере роста x все же имеется тенденция к увеличению их разброса.
 Понятие гетероскедастичность относится к любому случаю, в котором дисперсия вероятностного определения случайного члена различна для разных наблюдений.
Понятие гетероскедастичность относится к любому случаю, в котором дисперсия вероятностного определения случайного члена различна для разных наблюдений.
Принципиально значение гетероскедастичности объясняется двумя причинами.
Первая касается дисперсии оценок. Желательно, чтобы она была как можно меньше. При отсутствии гетероскедастичности обычные коэффициенты регрессии имеют наиболее низкую дисперсию среди всех несмещенных оценок. Если имеет место гетероскедастичность, то оценки МНК неэффективны. Можно найти другие оценки, которые имеют меньшую дисперсию и, тем не менее, являются несмещенными.
Вторая, не менее важная причина заключается в том, что сделанные оценки стандартных ошибок коэффициентов регрессии будут неверны. Они вычисляются на основе предположения о том, что распределение случайного члена гомоскедастично; если это не так, то их расчет по прежним формулам неточен. Вполне вероятно, что стандартные ошибки будут занижены, а следовательно, t-статистика завышена, и будет получено неправильное представление о точности оценки уравнения регрессии. Возможно, что коэффициент значимо отличается от нуля при данном уровне значимости, тогда как в действительности это не так.
Гетероскедастичность приводит к увеличению дисперсии оценок и получению неэффективных оценок.
Обычный МНК не делает различия между качеством наблюдений, придавая одинаковые веса каждому из них, независимо от того, большая или маленькая дисперсия этого наблюдения. Из этого следует, что, если сможем найти способ придания большего веса наблюдениям с меньшей дисперсией и меньшего наблюдениям с высокой дисперсией, то получим более точные оценки.
Гетероскедастичность становится проблемой, когда значения переменных, входящих в уравнение регрессии, часто значительно различаются в разных наблюдениях. Если истинная зависимость является моделью парной регрессии, причем экономические переменные меняют свой масштаб одновременно, то изменения значений включенных переменных и ошибки измерения, влияя совместно на случайный член, делают его сравнительно малым при малых у и х, и сравнительно большим при больших у и x.
Вначале рассмотрим методы, позволяющие установить наличие гетероскедастичности, а затем попытаемся предложить метод, учитывающий это явление, если оно имеет место. К настоящему времени для такой проверки предложено большое число тестов (и, соответственно, критериев для них).
10.2. Тест ранговой корреляции Спирмена
Ранг наблюдения переменной – номер наблюдения в упорядоченной по возрастанию значения переменной. Для получения ранга надо просто отсортировать наблюдения, по возрастанию некоторой переменой.
Тест ранговой корреляции Спирмена – тест на гетероскедастичность, устанавливающий, что стандартное отклонение остаточного члена регрессии имеет нестрогую линейную зависимость с объясняющей переменной.
При выполнении теста ранговой корреляции Спирмена предполагается, что дисперсия случайного члена будет либо увеличиваться, либо уменьшаться по мере увеличения x, и поэтому в регрессии, оцениваемой с помощью МНК, абсолютные величины остатков ei и значения xi будут коррелированны.
Коэффициент ранговой корреляции для теста ранговой корреляции Спирмена вычисляется по формуле:
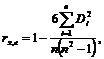 (10.1)
(10.1)
где x – одна из объясняющих переменных, с которой по предположению коррелирует остаточный член регрессии u, ![]() разность между рангом i-го наблюдения x и рангом модуля остатка в i-ом наблюдении.
разность между рангом i-го наблюдения x и рангом модуля остатка в i-ом наблюдении.
Если предположить, что соответствующий коэффициент корреляции для генеральной совокупности равен нулю, т. е. гетероскедастичность отсутствует, то коэффициент ранговой корреляции имеет нормальное распределение с математическим ожиданием 0 и дисперсией 1/(n – 1) в больших выборках. Следовательно, соответствующая тестовая статистика равна
![]() , (10.2)
, (10.2)
и при использовании двустороннего критерия нулевая гипотеза об отсутствии гетероскедастичности будет отклонена при уровне значимости в 5%, если она превысит 1,96; и при уровне значимости в 1%, если она превысит 2,58. Если в модели регрессии имеется более одной объясняющей переменной, то проверка гипотезы может выполняться с использованием каждой из них.
10.3. Тест Голдфелда–Квандта
Наиболее популярным формальным критерием является критерий, предложенный С. Голдфелдом и Р. Квандтом. При проведении проверки по этому критерию предполагается, что стандартное отклонение ![]() пропорционально значению x в этом наблюдении. Предполагается также, что случайный член распределен нормально и не подвержен автокорреляции.
пропорционально значению x в этом наблюдении. Предполагается также, что случайный член распределен нормально и не подвержен автокорреляции.
Тест Голдфелда–Квандта – тест на гетероскедастичность, устанавливающий, что стандартное отклонение остаточного члена регрессии растет, когда растет объясняющая переменная.
Все наблюдений в выборке упорядочиваются по величине x, после чего оцениваются отдельные регрессии для первых n’ и для последних n’ наблюдений; средние (n – 2n’) наблюдений отбрасываются. Если предположение, что имеется гетероскедастичности, то дисперсия в последних n’ наблюдениях будет больше, чем в первых n’, и это будет отражено в сумме квадратов остатков в двух указанных частных регрессиях. Обозначая суммы квадратов остатков в регрессиях для первых n’ и последних n’ наблюдений соответственно через ![]() и
и ![]() рассчитаем отношение
рассчитаем отношение ![]() , которое имеет распределение c (n’-k–1) и (n’–k–1) степенями свободы, где k — число объясняющих переменных в регрессионном уравнении. Если данное значение превышает критическое значение F(n’, n’), то нулевая гипотеза об отсутствии гетероскедастичности отклоняется.
, которое имеет распределение c (n’-k–1) и (n’–k–1) степенями свободы, где k — число объясняющих переменных в регрессионном уравнении. Если данное значение превышает критическое значение F(n’, n’), то нулевая гипотеза об отсутствии гетероскедастичности отклоняется.
Таким образом, тест Голдфелда–Квандта состоит из трех этапов:
1) Все наблюдения в выборке упорядочиваются по возрастанию x;
2) Берутся первые и последние n’ наблюдений (треть от общего числа), оцениваются две различные регрессии и находятся ![]() и
и ![]() ;
;
3) Для отношения ![]() проводят тест Фишера с верхними и нижними степенями свободы (n’–k–1), где k – количество объясняющих переменных в регрессиях.
проводят тест Фишера с верхними и нижними степенями свободы (n’–k–1), где k – количество объясняющих переменных в регрессиях.
Мощность критерия зависит от выбора n’ по отношению к n. Основываясь на результатах некоторых экспериментов можно утверждать, что n’ должно составлять порядка 11, когда n = 30, и порядка 22, когда n = 60. Если в модели имеется более одной объясняющей переменной, то наблюдения должны упорядочиваться по той из них, которая, как предполагается, связана с u и n’ должно быть больше, чем k + 1 (где k — число объясняющих переменных).
Метод Голдфелда–Квандта может также использоваться для проверки на гетероскедастичность при предположении, что ![]() обратно пропорционально x. При этом используется та же процедура, что и описанная выше, но тестовой статистикой теперь является показатель
обратно пропорционально x. При этом используется та же процедура, что и описанная выше, но тестовой статистикой теперь является показатель ![]() , который вновь имеет F-распределение с (n’–k–1) и (n’–k–1) степенями свободы.
, который вновь имеет F-распределение с (n’–k–1) и (n’–k–1) степенями свободы.
Если значение ![]() попадает в область принятия нулевой гипотезы, принимается решение о наличии гетероскедастичности.
попадает в область принятия нулевой гипотезы, принимается решение о наличии гетероскедастичности.
10.4. Тест Глейзера
Тест Глейзера – наиболее тонкий тест на гетероскедастичность, улавливающий нелинейную связь между стандартным отклонением остаточного члена регрессии и объясняющей переменной. Пусть ![]() зависит не линейно от x, и хотим проверить, может ли быть более подходящей какая-либо функция, например:
зависит не линейно от x, и хотим проверить, может ли быть более подходящей какая-либо функция, например:
![]() (11.4)
(11.4)
Чтобы использовать данный метод, следует оценить регрессионную зависимость у от x с помощью МНК, а затем вычислить абсолютные величины остатков, оценив их регрессию на ![]() для данного значения у. Можно оценить несколько таких уравнений регрессии, изменяя значение g. В каждом случае нулевая гипотеза об отсутствии гетероскедастичности будет отклонена, если оценка b значимо отличается от нуля. Если при оценивании более чем одной функции получается значимая оценка b, то при определении характера гетероскедастичности может служить наилучшая из них.
для данного значения у. Можно оценить несколько таких уравнений регрессии, изменяя значение g. В каждом случае нулевая гипотеза об отсутствии гетероскедастичности будет отклонена, если оценка b значимо отличается от нуля. Если при оценивании более чем одной функции получается значимая оценка b, то при определении характера гетероскедастичности может служить наилучшая из них.
10.5. Взвешенный метод наименьших квадратов (WLS)
Предположим, что нарушается второе условие Гаусса–Маркова. В этом случае ковариационную матрицу можно представить в виде:
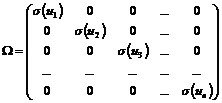
где  ,
,  . Если величины
. Если величины ![]() известны, то можно применить взвешенный метод наименьших квадратов, используя в качестве весов
известны, то можно применить взвешенный метод наименьших квадратов, используя в качестве весов ![]() и минимизировать следующую сумму:
и минимизировать следующую сумму:
![]()
При использовании взвешенного метода наименьших квадратов получается не только несмещенные оценки параметров, как при использовании обычного метода наименьших квадратов, но и более эффективными, то есть имеющими меньшую дисперсию.
Проблема, как и ранее, заключается в том, что значения ![]() заранее неизвестны. Поэтому на первом этапе используют обычный МНК, с тем, чтобы оценить дисперсии остатков
заранее неизвестны. Поэтому на первом этапе используют обычный МНК, с тем, чтобы оценить дисперсии остатков ![]() . Использование взвешенного метода позволяет регулировать вклад тех или иных данных в построение модели.
. Использование взвешенного метода позволяет регулировать вклад тех или иных данных в построение модели.
В качестве весов обычно используются числа от 0 до 100, при этом по умолчанию в МНК эти веса равны 1. При указании веса меньше 1, мы снижаем вклад этих данных. При задании веса больше 1 увеличиваем вклад этих данных. Итак, ключевым моментом в данном методе является выбор весов. В первом приближении веса можно установить пропорционально ошибкам случайного члена.
§ 11. Автокорреляция
11.1. Определение автокорреляции
До сих пор мы предполагали, что значение случайного члена и в любом наблюдении определяется независимо от его значений во всех других наблюдениях, т. е. предполагалось, что удовлетворено третье условие Гаусса–Маркова.
Автокорреляция – нарушение третьего условия Гаусса–Маркова, которое заключается в том, что случайные члены регрессии в разных наблюдениях являются зависимыми .
Последствия автокорреляции в некоторой степени сходны с последствиями гетероскедастичности. Коэффициенты регрессии остаются несмещенными, но становятся неэффективными, и их стандартные ошибки оцениваются неправильно (чаще всего они смещаются вниз, т. е. занижаются).
Автокорреляция обычно встречается только в регрессионном анализе при использовании данных временных рядов. Случайный член u в уравнении регрессии подвергается воздействию тех переменных, влияющих на зависимую переменную, которые не включены в уравнение регрессии. Если значение u в любом наблюдении должно быть независимым от его значения в предыдущем наблюдении, то и значение любой переменной, скрытой в u, должно быть некоррелированным с ее значением в предыдущем наблюдении.
Положительная автокорреляция – ситуация, когда случайный член регрессии в следующем наблюдении ожидается того же знака, что и в настоящем наблюдении, то есть
![]() или
или ![]() .
.![]()
Постоянная направленность воздействия не включенных в уравнение переменных является наиболее частой причиной положительной автокорреляции.
Предположим, что оцениваете уравнение спроса на мороженое, и состояние погоды является единственным важным фактором, “скрытым” в u. Пусть имеется несколько последовательных наблюдений, когда теплая погода способствует увеличению спроса на мороженое и, таким образом, u положительно, и несколько последовательных наблюдений, когда погода холодная, а следовательно u отрицательно. Фактические наблюдения будут в основном сначала находиться выше линии регрессии, затем ниже ее и затем опять выше (рис. 11).
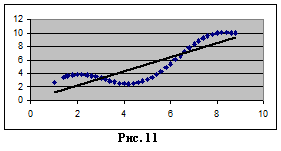 Важно отметить, что автокорреляция в целом представляет тем более существенную проблему, чем меньше интервал между наблюдениями. Очевидно, что чем больше этот интервал, тем менее правдоподобно, что при переходе от одного наблюдения к другому характер влияния неучтенных переменных будет сохраняться. Если в примере с мороженым наблюдения проводятся не ежемесячно, а ежегодно, то автокорреляции, вероятно, вообще не будет.
Важно отметить, что автокорреляция в целом представляет тем более существенную проблему, чем меньше интервал между наблюдениями. Очевидно, что чем больше этот интервал, тем менее правдоподобно, что при переходе от одного наблюдения к другому характер влияния неучтенных переменных будет сохраняться. Если в примере с мороженым наблюдения проводятся не ежемесячно, а ежегодно, то автокорреляции, вероятно, вообще не будет.
Автокорреляция может также быть отрицательной.
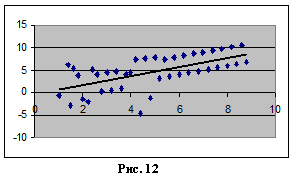
Отрицательная автокорреляция – ситуация, когда ожидается знак случайного члена в следующем наблюдении, противоположен знаку случайного члена в предыдущем наблюдении, то есть
![]() или
или ![]()
Это означает, что корреляция между последовательными значениями случайного члена отрицательна. В этом случае, скорее всего, за положительным значением в одном наблюдении идет отрицательное значение в следующем, и наоборот. Диаграмма рассеяния при этом выглядит так, как показано на рис. 12. В экономике отрицательная автокорреляция встречается относительно редко. Но иногда она появляется при преобразовании первоначальной спецификации модели в форму, подходящую для регрессионного анализа.
11.2. Автокорреляция первого порядка. Критерий Дарбина–Уотсона
Автокорреляция первого порядка – ситуация, когда коррелируют случайные члены регрессии в последовательных наблюдениях:
![]()
Авторегрессионная схема первого порядка – частный случай автокорреляции первого порядка, когда зависимость между последовательными случайными членами описывается формулой
![]() (11.1)
(11.1)
где p – константа, которая характеризует новую регрессионную модель а ![]() – новый случайный член.
– новый случайный член.
Это означает, что величина случайного члена в любом наблюдении зависит от значения в предшествующем наблюдении. Данная схема называется авторегрессионной, поскольку u определяется значениями этой же самой величины с запаздыванием, и схемой первого порядка, потому что в этом простом случае максимальное запаздывание равно единице. Предполагается, что значение ![]() в каждом наблюдении не зависит от его значений во всех других наблюдениях. Если p положительно, то автокорреляция положительная; если p отрицательно, то автокорреляция отрицательная. Если p=0, то автокорреляции нет, и третье условие Гаусса–Маркова выполняется.
в каждом наблюдении не зависит от его значений во всех других наблюдениях. Если p положительно, то автокорреляция положительная; если p отрицательно, то автокорреляция отрицательная. Если p=0, то автокорреляции нет, и третье условие Гаусса–Маркова выполняется.
Критерий Дарбина–Уотсона – метод обнаружения автокорреляции первого порядка с помощью статистики Дарбина–Уотсона.
Статистика критерия Дарбина–Уотсона вычисляется на основании остатков по формуле:
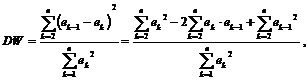 (11.2)
(11.2)
где ![]() остатки в наблюдениях.
остатки в наблюдениях.
Считая, что 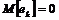 , найдем значение корреляции между
, найдем значение корреляции между ![]() и
и ![]() , которое будет иметь вид
, которое будет иметь вид
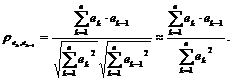
Тогда значение для статистики Дарбина–Уотсона можно переписать в виде:
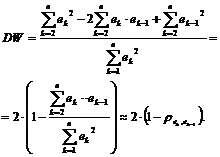 (11.3)
(11.3)
Значение статистики Дарбина–Уотсона будем обозначать также через d.
Критерий Дарбина–Уотсона обнаруживает только ярко выраженную автокорреляцию первого порядка и лишь при отсутствии лаговых переменных в регрессии. Если автокорреляция отсутствует, то p = 0, и поэтому величина d должна быть близкой к двум. При наличии положительной автокорреляции величина, вообще говоря, будет меньше двух; при отрицательной автокорреляции она должна превышать 2. Так как p должно находиться между значениями 1 и –1, то d должно лежать между 0 и 4.
Критическое значение d при любом данном уровне значимости зависит, как можно предполагать, от числа объясняющих переменных в уравнении регрессии и от количества наблюдений в выборке. К сожалению, оно также зависит от конкретных значений, принимаемых объясняющими переменными. Поэтому невозможно составить таблицу с указанием точных критических значений для всех возможных выборок, как это можно сделать для t - и F-статистик; но можно вычислить верхнюю и нижнюю границы для критического значения d. Для положительной автокорреляции они обычно обозначаются, как ![]() и
и ![]() .
.
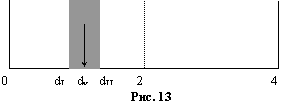 На рисунке 13 данная ситуация представлена в виде схемы; стрелка указывает критический уровень
На рисунке 13 данная ситуация представлена в виде схемы; стрелка указывает критический уровень ![]() . Если бы знали значение
. Если бы знали значение ![]() , то могли бы сравнить с ним значение d, рассчитанное для нашей регрессии. Если оказалось, что
, то могли бы сравнить с ним значение d, рассчитанное для нашей регрессии. Если оказалось, что ![]() , то можно отклонить нулевую гипотезу об отсутствии автокорреляции. В случае
, то можно отклонить нулевую гипотезу об отсутствии автокорреляции. В случае ![]() нулевая гипотеза не отклоняется и делается вывод о наличии положительной автокорреляции.
нулевая гипотеза не отклоняется и делается вывод о наличии положительной автокорреляции.
Вместе с тем мы не знаем ![]() , а знаем, что оно находится где-то между
, а знаем, что оно находится где-то между ![]() и
и ![]() . Это предполагает наличие трех возможностей.
. Это предполагает наличие трех возможностей.
1. Величина d меньше, чем ![]() . В этом случае она будет также меньше, чем
. В этом случае она будет также меньше, чем ![]() , и поэтому делаем вывод о наличии положительной автокорреляции.
, и поэтому делаем вывод о наличии положительной автокорреляции.
2. Величина d больше, чем ![]() . В этом случае она также больше критического уровня, и поэтому сможем отклонить нулевую гипотезу.
. В этом случае она также больше критического уровня, и поэтому сможем отклонить нулевую гипотезу.
3. Величина d находится между ![]() и
и ![]() . В этом случае она может быть больше или меньше критического уровня. Поскольку нельзя определить, которая из двух возможностей реализована, не можем ни отклонить, ни принять нулевую гипотезу.
. В этом случае она может быть больше или меньше критического уровня. Поскольку нельзя определить, которая из двух возможностей реализована, не можем ни отклонить, ни принять нулевую гипотезу.
В случаях 1 и 2 тест Дарбина–Уотсона дает определенный ответ, но случай 3 относится к зоне невозможности принятия решения относительно автокорреляции.
Таким образом, зона неопределенности критерия Дарбина–Уотсона – промежуток значений статистики Дарбина–Уотсона, при попадании в который критерий не дает определенного ответа о наличии или отсутствии автокорреляции первого порядка.
В приложении 4 даны значения ![]() и
и ![]() , стоящие на пересечении строк и столбцов, соответствующих количеству наблюдений n и числу объясняющих переменных k для уровней значимости в 5%. В таблице показаны критические значения в случае положительной автокорреляции. Можно видеть, что чем больше число наблюдений, тем уже зона неопределенности.
, стоящие на пересечении строк и столбцов, соответствующих количеству наблюдений n и числу объясняющих переменных k для уровней значимости в 5%. В таблице показаны критические значения в случае положительной автокорреляции. Можно видеть, что чем больше число наблюдений, тем уже зона неопределенности.
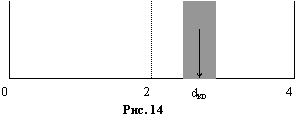 Проверка на отрицательную автокорреляцию проводится по аналогичной схеме, причем зона, содержащая критический уровень, расположена симметрично справа от 2. Так как отрицательная автокорреляция встречается относительно редко, границы зоны можно вычислить на основе соответствующих значений для положительной автокорреляции при данном числе наблюдений и объясняющих переменных. Величина
Проверка на отрицательную автокорреляцию проводится по аналогичной схеме, причем зона, содержащая критический уровень, расположена симметрично справа от 2. Так как отрицательная автокорреляция встречается относительно редко, границы зоны можно вычислить на основе соответствующих значений для положительной автокорреляции при данном числе наблюдений и объясняющих переменных. Величина ![]() есть нижний предел, ниже которого признается отсутствие автокорреляции, а
есть нижний предел, ниже которого признается отсутствие автокорреляции, а ![]() – верхний предел, выше которого делается вывод о наличии отрицательной автокорреляции.
– верхний предел, выше которого делается вывод о наличии отрицательной автокорреляции.
11.3. Метод Кохрейна–Оркатта устранения автокорреляции
Наилучший (но не всегда возможный) способ устранения автокорреляции – установление ответственного за нее фактора и включение соответствующей объясняющей переменной в регрессию.
В других случаях процедура, которую следует принять для устранения автокорреляции, будет зависеть от характера зависимости между значениями случайного члена. Рассмотрим авторегрессионную схему первого порядка (11.1).
Если исходное уравнение было правильной спецификацией для измерения величины случайного члена, то можно полностью устранить автокорреляцию, зная величину p. Предположим, что истинная модель имеет вид:
![]() (11.4)
(11.4)
![]() (11.5)
(11.5)
Теперь вычтем из уравнения (11.4) соотношение (11.5), умноженное на p и получим:
![]() (11.6)
(11.6)
Обозначим 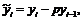
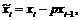
тогда формулу (11.6) можно переписать в виде
![]()
Вместе с тем из уравнения (11.1) имеем ![]() .
.
Таким образом, формула (11.6) принимает вид:
![]() (11.7)
(11.7)
Мы предположили, что p известно. Тогда можно вычислить величины ![]() ,
,![]() для наблюдений, включающих от 2 до Т исходных данных. Если теперь оценить регрессию между
для наблюдений, включающих от 2 до Т исходных данных. Если теперь оценить регрессию между ![]() и
и![]() , то будут получены оценки, не связанные с проблемой автокорреляции, поскольку, согласно предположению, значения
, то будут получены оценки, не связанные с проблемой автокорреляции, поскольку, согласно предположению, значения ![]() не зависят друг от друга.
не зависят друг от друга.
Остается, однако, небольшая проблема. Если в выборке нет данных, предшествующих первому наблюдению, то мы не сможем вычислить ![]() и
и ![]() и потеряем первое наблюдение. Число степеней свободы уменьшается на единицу, и это вызовет потерю эффективности, которая может в небольших выборках перевесить повышение эффективности от устранения автокорреляции.
и потеряем первое наблюдение. Число степеней свободы уменьшается на единицу, и это вызовет потерю эффективности, которая может в небольших выборках перевесить повышение эффективности от устранения автокорреляции.
11.4. Обобщенный метод наименьших квадратов
Метод Кохрейна–Оркатта является простейшим методом устранения автокорреляции, причем только первого порядка. Рассмотрим метод, который во многом является развитием взвешенного метода наименьших квадратов, и позволяет найти несмещенные оценки для произвольного случая. Будем предполагать, что нарушается второе и третье условие Гаусса-Маркова, то есть дисперсии случайных остатков изменяются от опыта к опыту, и в то же время данные остатки коррелируют между собой, то есть одновременно необходимо учесть гетероскедастичность и автокорреляцию. В этом случае можно определить корреляционную матрицу случайных составляющих u, в виде:
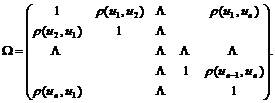 (11.2)
(11.2)
Для данного случая будем минимизировать не сумму квадратов остатков, как в методе наименьших квадратов, 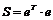 , а значение суммы в виде:
, а значение суммы в виде: ![]() .
.
Поступая так же, как и в обычном метод наименьших квадратов, а именно находя частные производные, а затем приравнивая их нулю, получить следующую, несмещаемую оценку для коэффициентов регрессии:
![]() (13.3)
(13.3)
Проблема, как и ранее, как и во всей эконометрике, заключается в том, что мы не знаем и никогда не узнаем значение элементов ковариационной матрицы. Однако данные элементы можно попытаться оценивать посредством остатков, что и делается на практике.
Заключение
Прогнозирование имеет огромное значение для любой сферы деятельности человека. Особенно актуально умение предсказывать будущее развитие событий для экономики, где, в отличии от любой другой естественно-научной дисциплины, нет строгих функциональных зависимостей. Эконометрика – это наука “прогнозирования”. Но прогнозирование должно основываться на некоторых моделях, которые в свою очередь создаются на основании наблюдений. Эконометрика – это наука наблюдать, с тем, чтобы потом предсказать будущее. Ну а как всякая прикладная наука, главная задача эконометрики – обосновать правильность принятия некоторое экономического решения.
Прочитав данное пособие, вы только приоткрыли завесу, которая скрывает огромный труд целых отделов и институтов планирования развития экономики, предсказателей будущей жизни. Можно надеяться, что все эти громоздкие формулы, не отобьет желания изучать, а только послужат стимулом к дальнейшему совершенствованию всех, решивших изучать эту науку – ЭКОНОМЕТРИКУ.
Более подробно с различными аспектами теории можно ознакомиться у авторов , и д. р.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
