

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Нелинейность по переменным всегда можно обойти путем использования соответствующих определений. Например, в моделях:
![]() или
или ![]() ,
,
если определить переменную ![]() или
или ![]() , то получим линейные как по переменным, так и по параметрам модели. Следовательно, нелинейность по переменным всегда можно обойти, используя новые обозначения.
, то получим линейные как по переменным, так и по параметрам модели. Следовательно, нелинейность по переменным всегда можно обойти, используя новые обозначения.
В случае гиперболической зависимости, нужно определить z = (1/x). Тогда исходная модель примет вид:
![]() .
.
Для дробно-линейной зависимости необходимо сделать замену ![]() и оценить линейную регрессию вида
и оценить линейную регрессию вида ![]() .
.
Все дополнительно предложенные нами уравнения является нелинейным как по параметрам, так и по переменным, и их нельзя преобразовать только путем замены переменной.
Таким образом, модель нелинейная по переменным в которой возможна замена переменной, приводящая получившуюся модель к линейной; модель нелинейная по параметрам, которую нельзя привести заменами переменных к линейной.
Рассмотрим далее степенную модель, которая являются нелинейной как по параметрам, так и по переменным:
![]() .
.
Если прологарифмировать обе части данного уравнения, то получим:
![]() .
.
Обозначив ![]() ,
, ![]() , можно переписать в виде:
, можно переписать в виде:
![]() .
.
Данная модель является линейной, следовательно, процедура оценивания регрессии будет следующей. Сначала вычислим у' и z для каждого наблюдения. Затем оценим линейную регрессионную зависимость у' от z, которая дает уравнение
![]()
Коэффициент b является оценкой параметра b, а a оценкой ![]() , следовательно, для получения a необходимо вычислить
, следовательно, для получения a необходимо вычислить ![]() .
.
Аналогичным образом посредством логарифмирования можно свести к линейному виду показательную модель (при это будет линейная зависимость![]() ) и логистическую (
) и логистическую (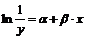 ).
).
6.3. Случайный член как множитель
При осуществлении преобразований уравнений регрессии, необходимо помнить о том, как эти преобразования влияют на случайный член. Основное требование здесь состоит в том, чтобы случайный член в преобразованном уравнении присутствовал в виде слагаемого (+u) и удовлетворял условиям Гаусса–Маркова. В противном случае коэффициенты регрессии, полученные по методу наименьших квадратов, не будут обладать обычными свойствами. Необходимо, чтобы модель, после произвольного преобразования, имела вид:
![]()
и выполнялись условия Гаусса–Маркова.
Для случая полиноминальной, логарифмической и гиперболической модели преобразования не влияют на случай член, следовательно, он должен просто прибавляться в исходной модели, то есть логарифмическая модель должна иметь вид ![]() , гиперболическая –
, гиперболическая –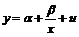 , а полиноминальная –
, а полиноминальная – ![]() .
.
Немного отличается случай дробно-линейной модели, где случайный член должен находиться в знаменатели ![]() .
.
В данных случаях, если в исходной модели условия Гаусса-Маркова выполнены, то это также будет верно и после преобразования.
Что произойдет, если мы используем степенную модель и приведения к линейному виду путем логарифмирования. В этом случае для выполнения условий Гаусса–Маркова модель должна иметь вид:
![]() .
.
Если вернуться к исходной модели (методом экспоненцирования), то получаем:
![]() .
.
где v и и связаны соотношением ln v = и.
Следовательно, для получения аддитивного случайного члена в линейной модели он должны быть мультипликативные в исходном, то есть входить в исходную модель в виде множителя. Заметим, что и =0, если log v = 0, что происходит при v = 1.
Для того чтобы были применимы t - и F-критерии, величина и должна иметь нормальное распределение. Это означает, что ln u должен иметь нормальное распределение, что возможно только при логарифмически нормальном распределении v.
Аналогичным образом можно получить общие виды показательной и логистической моделей, после преобразования которых в линейные, получился бы аддитивный случайный член. А именно показательная модель должна иметь вид ![]() .
.
Данный набор моделей является в некоторой степени стандартным для эконометрических исследований. Однако они ни в коей мере не охватывают всего многообразия экономических взаимодействий. Поэтому одна из задач современной эконометрики заключается в обосновании и доказательстве новых моделей экономического взаимодействия.
6.4. Подбор модели
Возможность построения нелинейных моделей значительно повышает универсальность регрессионного анализа, но и усложняет задачу. Нужно решить вопрос – начинать с линейной зависимости или с нелинейной и если с последней, то с какого типа.
Если ограничиваетесь парным регрессионным анализом, то можете построить график наблюдений у и x, и это поможет выбрать подходящую нелинейную функцию. Часто несколько разных нелинейных функций приблизительно соответствуют наблюдениям, если они лежат вблизи некоторой кривой. Однако в случае множественного регрессионного анализа невозможно построить график.
В качестве критерия модели, наравне с коэффициентом детерминации R2, используется средняя ошибка аппроксимации:
![]() . (6.8)
. (6.8)
Чем меньше значение, тем лучше модель описывает полученные экспериментальные данные.
Чем больше для модели коэффициент корреляции и чем меньше средняя ошибка аппроксимации, тем лучше данная модель описывает имеющиеся данные.
Однако при выборе между логарифмической и линейной зависимостью нельзя просто выбрать ту, у которой больше значение детерминации. Величина R2 безразмерна, однако в двух моделях она относится к разным понятиям. В одном уравнении она измеряет объясненную регрессией долю дисперсии у, а в другом – объясненную регрессией долю дисперсии log у. Если для одной модели коэффициент R2 значительно больше, чем для другой, то вы сможете сделать оправданный выбор без особых раздумий, однако, если значения R2 для двух моделей приблизительно равны, то проблема выбора существенно усложняется.
Если необходимо сравнить линейную и логарифмическую модель, то можно использовать метод Зарембки.
Данный тест предполагает такое преобразование масштаба наблюдений у, при котором обеспечивалась бы возможность непосредственного сравнения объясненной суммы квадратов отклонений (RSS) в линейной и логарифмической моделях.
Метод Зарембки состоит из четырех шагов.
1) Вычисляется среднее геометрическое по выборке.
2) Пересчитываются новые наблюдения ![]()
3) Рассматриваются линейная регрессия с наблюдениями ![]() вместо
вместо ![]() и логарифмическая регрессия с наблюдениями
и логарифмическая регрессия с наблюдениями ![]() вместо
вместо ![]() Находим остаточные суммы квадратов отклонений для полученных вспомогательных регрессий RSS1 и RSS2.
Находим остаточные суммы квадратов отклонений для полученных вспомогательных регрессий RSS1 и RSS2.
4) Составляем статистику 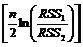
Если это число превышает критическое значение распределения с одной степенью свободы, то выбираем логарифмическую модель, если не превышает – линейную модель.
6.5. Эластичность
При анализе многих экономических закономерностей часто используется эластичность. Эластичность показывает на сколько процентов изменится зависимая переменная, при изменении объясняющей переменной на 1%.
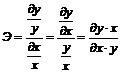 . (6.9)
. (6.9)
Эластичность, также можно определить как отношение предельного значения данной функции к её среднему значению.
Во многих случаях имеются априорные знания о значении эластичности, поэтому выбор нелинейной зависимости должен основываться и на анализе эластичности.
Функция вида 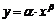 часто встречается в экономике и имеет постоянную эластичность равную b. Общая форма подобных кривых представляет собой спрос на товар, а эластичность имеет вид:
часто встречается в экономике и имеет постоянную эластичность равную b. Общая форма подобных кривых представляет собой спрос на товар, а эластичность имеет вид:
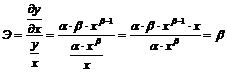 .
.
Рассмотрим линейное регрессионное уравнение:
y=a+bx+u.
В данном случае предельное значение функции ![]() равно b, следовательно, эластичность определяется следующим образом:
равно b, следовательно, эластичность определяется следующим образом:
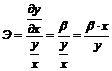
В этом случае значение эластичности в любой точке будет зависеть не только от значения b, но и также и от значений у и x в данной точке. Таким образом, основное достоинство степенной модели состоит в том, что это единственная модель, у которой эластичность постоянная.
Глава 2. МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
§ 7. Основные множественной регрессии
7.1. Случай двух независимых переменных
Множественный регрессионный анализ является развитием парного регрессионного анализа применительно к случаям, когда зависимая переменная связана более чем с одной независимой переменной. Большая часть анализа будет непосредственным расширением парного анализа, поэтому при необходимости будем ссылаться на определения и формулы, полученные нами ранее. Однако появятся и новые проблемы, на которых будем останавливаться подробнее.
Расширим модель спроса на продукт питания следующим образом:
![]()
где y – общая величина расходов на питание, x – располагаемый личный доход (первый регрессор), p – цена продуктов питания (второй регрессор). Это, разумеется, значительное упрощение, как с точки зрения состава независимых переменных, так и с точки зрения математической связи.
Для геометрической иллюстрации этой зависимости необходима трехмерная диаграмма с осями у, x и p. Основание диаграммы содержит оси x и p, и если пренебречь текущим влиянием случайного члена, то плоскость показывает величину у, соответствующую любому сочетанию x и p. Учет случайного члена приводит к тому, что фактическое значение y не будет лежать на данной плоскости, следовательно, получили трехмерный аналог, при этом вместо линии регрессии имеем плоскость регрессии. Уравнение для данной плоскости имеет вид:
![]()
где ![]() ,
,![]() ,
,![]() являются оценками неизвестных параметров
являются оценками неизвестных параметров ![]() ,
,![]() ,
,![]() .
.
Рассмотрим произвольный случай, когда имеются две независимых переменных ![]() и
и ![]() (два регрессора), и будем рассматривать линейную регрессионную модель вида:
(два регрессора), и будем рассматривать линейную регрессионную модель вида:
![]() , (7.1)
, (7.1)
для которой попытаемся построить уравнение регрессии:
![]() . (7.2)
. (7.2)
В этом случае для каждого наблюдения должны быть известны значения каждого регрессора ![]() ,
,![]() и значения зависимой переменной y. Следовательно, множество значений регрессоров будет представлять матрицу с двумя столбцами и n строками, при этом нижний индекс изменяться от 1 до n и определять номер измерения, а верхний индекс принимает два значения 1 или 2, в зависимости от номера регрессора. В этом случае матрица значений будет:
и значения зависимой переменной y. Следовательно, множество значений регрессоров будет представлять матрицу с двумя столбцами и n строками, при этом нижний индекс изменяться от 1 до n и определять номер измерения, а верхний индекс принимает два значения 1 или 2, в зависимости от номера регрессора. В этом случае матрица значений будет:
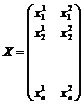 .
.
Аналогичным образом значения переменной y будут задаваться вектором-столбцом:
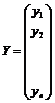 .
.
Обозначим через ![]() прогнозируемое значение по уравнению регрессии
прогнозируемое значение по уравнению регрессии
, ![]() ,
,
а остаток в i-м наблюдении будет:
, ![]() .
.
Как и для случая парной регрессии будем минимизировать сумму квадратов остатков:
![]()
Необходимые условия первого порядка для минимума есть равенство всех частных производных по всем параметрам регрессии нулю ![]()
Данные условия имеют следующий вид:
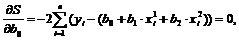
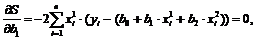
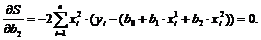
Эти уравнения также называются нормальными уравнениями для коэффициентов регрессии, и в данном случае имеется три уравнения с три неизвестными значениями b0, b1 и b2.
Применяя обозначения для средних значений, подобные парной регрессии, из первого уравнение можно легко выразить значение величины b0 через b1 и b2, тогда
![]() . (7.3)
. (7.3)
Используя это выражение и два других уравнения, путем преобразований можно получить следующее выражение для других элементов регрессии:
![]() , (7.3’)
, (7.3’)
![]() .
.
Подчеркнем два основных момента.
Во-первых, принципы, лежащие в основе вычисления коэффициентов регрессии, в случаях множественной и парной регрессии не различаются.
Во-вторых, используемые при этом формулы будут разными, поэтому в общем случае не следует пытаться использовать выражения, выведенные для парной регрессии, в случае множественной регрессии. Однако имеется одно исключение, когда регрессоры независимы, то есть 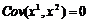 , и в этом случае формулы совпадают.
, и в этом случае формулы совпадают.
7.2. Коэффициенты для модели множественной регрессии и их статистическая значимость
Модель множественной линейной регрессии – это линейная модель зависимости между переменными, содержащая более двух независимых переменных (регрессоров):
(7.4)
Хотя случай парной регрессии, а также случай двух независимых переменных довольно подробно рассматривался нами ранее, они является частным случаем множественной регрессии, а следовательно, все результаты, которые будут получены нами далее распространятся и на эти частные случаи.
В модели множественной регрессии за изменение зависимой переменной регрессии y отвечают некоторый экономические факторы – объясняющие переменные (регрессоры) ![]() ,
,![]() ,…,
,…,![]() . Параметры множественной регрессии показывают степень влияния на зависимую переменную экономических факторов, обозначенных соответствующими регрессорами. Как и в случае парной линейной регрессии, основная задача заключается в оценке неизвестные значения, то есть получении , при этом уравнение регрессии будет иметь вид:
. Параметры множественной регрессии показывают степень влияния на зависимую переменную экономических факторов, обозначенных соответствующими регрессорами. Как и в случае парной линейной регрессии, основная задача заключается в оценке неизвестные значения, то есть получении , при этом уравнение регрессии будет иметь вид:
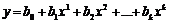 . (7.5)
. (7.5)
В общем случае, если имеется k различных регрессоров, то матрица наблюдений будет иметь вид:
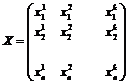 ,
,
где ![]() ,
, ![]() ,
,![]() – значение j-го регрессора в i-м испытании.
– значение j-го регрессора в i-м испытании.
Множество полученных значений зависимой переменной также как и для случая двух независимых переменных можно записать в виде вектора-столбца.
Оценим уравнение для данного множества наблюдений по методу наименьших квадратов. Это вновь означает минимизацию суммы квадратов отклонений в наблюдении, которые в данном случае имеют вид:
![]()
Данное выражение в векторном виде будет:
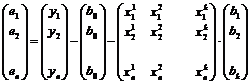 .
.
Если добавить в матрице X столбец, состоящий из единиц, тем самым, расширив её до размера n ´ k+1
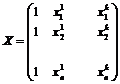 ,
,
то значения остатков в векторном будут:
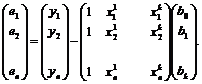
Последнее выражение можно записать в матричном виде:
![]() , (7.6)
, (7.6)
Сумма квадратов отклонений может быть записана в матричном виде, как произведение вектора строки ![]() на вектор столбец e
на вектор столбец e
![]() . (7.7)
. (7.7)
Используя известные правила матричных операций, значение суммы будет
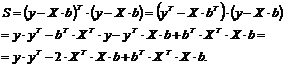
Теперь, чтобы минимизировать сумму квадратов отклонений, необходимо найти все частные производные и приравнять их нулю, то есть решить систему уравнений
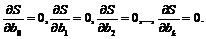
Можно легко показать, что первое из этих уравнений позволяет получить аналог для уравнения, относящегося к случаю с двумя независимыми переменными:
![]() .
.
Однако конечные формулы для остальных элементов регрессии найти нельзя. Будем использовать матричную запись, в которой уравнения примут следующий вид:
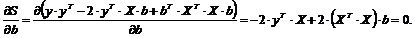 Следовательно,
Следовательно,
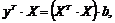
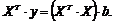
Откуда
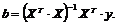 (7.8)
(7.8)
здесь матрица ![]() обратная к матрице
обратная к матрице ![]() .
.
Именно формула (7.8) служит для нахождения коэффициентов b множественной регрессии.
Если все условия теоремы Гаусса–Маркова
1)  , для любого i;
, для любого i;
2) ![]() не зависит от номера наблюдения i;
не зависит от номера наблюдения i;
3) 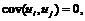 если i¹j;
если i¹j;
4) значение регрессоров является неслучайной или ![]() для любого i и k
для любого i и k
верны, то полученные оценки параметра модели множественной регрессии является несмещенными, эффективными и состоятельными оценками. Поскольку нами рассматривается модель множественной регрессии, то последнему из условий должна удовлетворять каждая объясняющая переменная.
Как и для случая парной регрессии, коэффициенты b являются случайными величинами, поэтому нами были введены два различных понятия для определения их разброса, это стандартное отклонение (3.3) и (3.4), которые являются фиксированными, но теоретическими характеристиками, нуждающимися в оценивании посредством стандартных ошибок (3.5) и (3.6). Поскольку множественная регрессия является развитием парной регрессии, то мы определим эти два понятия для данного случая.
Стандартное отклонение коэффициентов регрессии имеет вид
![]() (7.9)
(7.9)
и определяется сразу для всего вектора b. Так же как и в парном регрессионном анализе, величина ![]() является неизвестной и нуждается в оценке, посредством дисперсии остатков , то можно доказать, что математическое ожидание , если имеется k независимых переменных, будет
является неизвестной и нуждается в оценке, посредством дисперсии остатков , то можно доказать, что математическое ожидание , если имеется k независимых переменных, будет
А следовательно, стандартных ошибок коэффициентов будут
, (7.10)
где ![]() – диагональный элемент матрицы
– диагональный элемент матрицы ![]() .
.
Для проверки нулевой гипотезы на значимость каждого из коэффициентов ![]() , то есть гипотезы вида
, то есть гипотезы вида 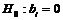 , как и в случае парной регрессии, вычисляется t - статистика:
, как и в случае парной регрессии, вычисляется t - статистика:
![]() , (7.11)
, (7.11)
которая имеет распределение Стьюдента с (n–k–1) степенью свободы. Далее, как и для парного случая, вычисляется критическое значение ![]() , с уровнем достоверности g. Если значение t-статистики превышает критический уровень, то нулевая гипотеза отвергается, и коэффициент множественной регрессии признается статистически значимым. Подобным образом могут быть проверены все коэффициенты регрессионной модели.
, с уровнем достоверности g. Если значение t-статистики превышает критический уровень, то нулевая гипотеза отвергается, и коэффициент множественной регрессии признается статистически значимым. Подобным образом могут быть проверены все коэффициенты регрессионной модели.
7.3. Коэффициент детерминации
Коэффициент детерминации R2 (множественный коэффициент корреляции), также как и для парной регрессии, являющийся характеристикой тесноты связи между y и несколькими регрессорами x, и определяется по формуле:
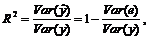
где Var(y) – общая дисперсия зависимой переменной y, Var (e) – остаточная дисперсия, ![]() – объясненная дисперсия.
– объясненная дисперсия.
Если ввести определения общей суммы квадратов отклонений (TSS), объясненной суммы квадратов отклонений (RSS) и необъясненной суммы квадратов отклонений (ЕSS), коэффициент детерминации будет
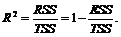
Как и для случая парной регрессии множественный коэффициент корреляции изменяется в пределах от 0 до 1. Приближение R2 к единице свидетельствует о сильной зависимости. Если R2 незначительно по величине, то можно утверждать, что либо не все важнейшие факторы взаимосвязи учтены, либо выбрана неподходящая форма уравнения.
В случае парной регрессионной зависимости нами было доказано, что коэффициент детерминации совпадает с квадратом выборочного коэффициента корреляции. В случае множественной регрессии коэффициент детерминации R2 может быть определен по значениям парных коэффициентов корреляции следующим образом:
(7.12)
где rij – парные коэффициенты корреляции между регрессорами ![]() и
и ![]() , a ri0 – парные коэффициенты корреляции между регрессором
, a ri0 – парные коэффициенты корреляции между регрессором ![]() и y. В числители данной формулы находится обобщенный коэффициент корреляции, для всей системы переменных, а в знаменателе обобщенный коэффициент корреляции регрессоров.
и y. В числители данной формулы находится обобщенный коэффициент корреляции, для всей системы переменных, а в знаменателе обобщенный коэффициент корреляции регрессоров.
Рассмотрим частные случаи данной формулы. В случае парной зависимости формула имеет вид
что совпадает, с формулой, полученной нами ранее.
Для случая зависимости результативного признака от двух факторных признаков формула коэффициента множественной корреляции имеет вид:
![]()
Коэффициенты R2 показывают абсолютный размер влияния регрессоров на зависимую переменную. При увеличении числа объясняющих переменных значение R2 возрастает, поэтому данный показатель становится ненадежным. Скорректированный (нормированный) коэффициент детерминации накладывает штраф за увеличение числа независимых переменных. Этот коэффициент определяется следующим образом:
![]() (7.13)
(7.13)
Добавление новой переменной к регрессии приведет к увеличению ![]() , если и только если этого регрессор значим, в отличии от обычного коэффициента детерминации R2, значение которого будет возрастать в любом случае.
, если и только если этого регрессор значим, в отличии от обычного коэффициента детерминации R2, значение которого будет возрастать в любом случае.
7.4. Проверка адекватности всей модели
Проверка адекватности всей модели, как и в случае парной регрессии, осуществляется с помощью расчета F-критерия Фишера. Общий вид F-статистики нами рассматривался ранее и определялся формулой (5.7):
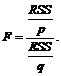
В случае множественной регрессии верхнее число степеней свобод p=k, а нижнее число степеней свобод q=n–k–1, тогда F-статистика будет
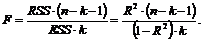 (7.14)
(7.14)
При осуществлении F-теста для уравнения в целом проверяется, превышает ли коэффициент R2 то значение, которое может быть получено случайно. Для этого нужно найти критическое значение ![]() , с некоторым уровнем значимости g. Если F-статистика превышает критическое значение, то нулевая гипотеза отвергается и вся регрессия считается значимой. Данный тест для этого может быть описан как проверка нулевой гипотезы:
, с некоторым уровнем значимости g. Если F-статистика превышает критическое значение, то нулевая гипотеза отвергается и вся регрессия считается значимой. Данный тест для этого может быть описан как проверка нулевой гипотезы:![]() , который дополняет t-тесты, проверки значимости каждого из коэффициентов
, который дополняет t-тесты, проверки значимости каждого из коэффициентов ![]() , то есть гипотез вида
, то есть гипотез вида ![]() .
.
Помимо проверки уравнения в целом F-тест можно использовать для определения значимости совместного вклада группы регрессоров. Предположим, что сначала оцениваете регрессию с k независимыми переменными, и объясненная сумма квадратов составляет ![]() . Затем добавляете еще несколько переменных, доведя их общее число до m, и объясненная сумма квадратов возрастает до
. Затем добавляете еще несколько переменных, доведя их общее число до m, и объясненная сумма квадратов возрастает до ![]() .
.
Таким образом, объяснили дополнительную величину ![]() , использовав для этого дополнительные (m – k) степеней свободы, и требуется выяснить насколько значимо это увеличение объясненной суммы квадратов отклонений. Вновь используется F-тест, и соответствующая F-статистика может быть описана следующим образом:
, использовав для этого дополнительные (m – k) степеней свободы, и требуется выяснить насколько значимо это увеличение объясненной суммы квадратов отклонений. Вновь используется F-тест, и соответствующая F-статистика может быть описана следующим образом:
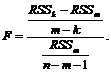 (7.15)
(7.15)
В соответствии с нулевой гипотезой о том, что дополнительные регрессоры не увеличивают возможности уравнения, то есть гипотезы вида: ![]() , статистика распределена с (m–k) и (n–k–1 ) степенями свободы. Если данное значение превышает критическое
, статистика распределена с (m–k) и (n–k–1 ) степенями свободы. Если данное значение превышает критическое ![]() , то нулевая гипотеза отвергается и, следовательно, все дополнительные регрессоры признаются значимыми.
, то нулевая гипотеза отвергается и, следовательно, все дополнительные регрессоры признаются значимыми.
7.5. Нелинейные модели
Так же, как и парном регрессионной анализе, рассмотрение только линейных моделей не исчерпывают всех возможных моделей, которые имеют место на практике. Наряду с линейными моделями наиболее часто используются модели следующих видов:
Логарифмическая ;
Гиперболическая ;
Дробно-линейная ;
Показательная ;
Обработка данных моделей аналогично парному случаю, и приведение к линейной форме производится либо заменой переменных, либо логарифмированием. Выбор наиболее адекватной модели осуществляется на основании скорректированного коэффициента детерминации.
Подбор модели можно также осуществлять и на основании эластичностей. Эластичность функции хi показывает на сколько процентов изменится значение y, при изменении хi на один процент, при условии, что значение остальных регрессоров фиксированном, и рассчитываются по формуле:
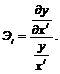 (7.16)
(7.16)
Долю каждого из регрессоров в изменении значения y можно кроме эластичностей результирующего фактора по каждому признаку также определять с помощью B-коэффициентов и D-коэффициентов. B-коэффициенты показывают, на какую часть среднеквадратического отклонения sY изменится y с изменением xi на величину своего среднеквадратического отклонения sк. Этот коэффициент позволяет сравнивать влияние различных факторов на изменение y и определяется формулой:
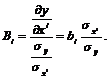 (7.17)
(7.17)
С помощью D-коэффициентов можно оценить долю вклада xi в суммарное влияние всех факторов, включенных в уравнение регрессии. Рассчитываются D-коэффициенты по формуле:
![]() (7.18)
(7.18)
§ 8. Спецификация переменных и проблема мультиколлинеарности
8.1. Проблема мультиколлинеарности
Важным этапом построения уже выбранного уравнения множественной регрессии являются отбор и последующее включение регрессоров. Сложность множественной регрессии заключается в том, что почти все регрессоры находятся в зависимости один от другого.
Введем следующие понятие. Строгая линейная зависимость между переменными – ситуация, когда выборочная корреляция двух переменных равна 1 или –1. Мультиколлинеарность – явление, когда имеется линейная зависимость в модели множественной регрессии, что приводит к получению ненадежных оценок регрессии. Мультиколлинеарность есть в каждой модели множественной регрессии, но проявляется в разной степени.
Одним из индикаторов определения наличия мультиколлинеарности между признаками является превышение парным коэффициентом корреляции величины 0,8.
В случае мультиколлинеарности совсем необязательно будут неудовлетворительные оценки. Если число наблюдений и выборочные дисперсии регрессоров велики, а дисперсия случайного члена мала, то можно получить хорошие оценки. В решении проблемы мультиколлинеарности можно выделить несколько этапов:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
