

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Балашовский филиал
Саратовского государственного университета
им
Эконометрика:
Парная и множественная регрессия
(Курс лекций)
Учебно-методическое пособие
для студентов экономического и физико-математического
факультетов
Балашов 2004
Рецензенты:
Кандидат физико-математических наук, доцент
Балашовского филиала
Саратовского Государственного Университета
им.
Кандидат педагогических наук, доцент
Балашовского филиала
Саратовского Государственного
Социально Экономического Университета
Рекомендовано к изданию Учебно-методическим советом
Балашовского филиала
Саратовского государственного университета
им.
В учебном пособии рассматриваются основные разделы эконометрики, а именно множественный и парный регрессионный анализ. Обсуждаются различные аспекты множественной регрессии: мультипликативность, фиктивные переменные и категории, а также проблемы гетесокдедастичности и автококорреляции и возможные методы их учета.
Настоящий курс лекций создан на основе богатого теоретического и практического материала [1–9], с использованием современных методик и информационных технологий.
Пособие рассчитано на студентов экономических и физико-математических специальностей. Оно может быть полезно при самостоятельном изучении эконометрики.
СОДЕРЖАНИЕ
ВВЕДЕНИЕ.. 5
Глава 1. МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ.. 8
§ 1. Основные понятия математической статистики. 8
1.1. Выборка и генеральная совокупность. 8
1.2. Теоретические характеристики случайной величины.. 9
1.3. Оценки как случайные величины.. 15
1.4. Метод Монте-Карло. 22
§ 2. Метод наименьших квадратов. 23
2.1. Модель парной регрессии. 23
2.2. Регрессия по методу наименьших квадратов. 25
2.3. Коэффициент детерминации R2 28
§ 3. Свойства коэффициентов регрессии. 31
3.1. Теорема Гаусса–Маркова. 31
Теорема. 34
3.2. Стандартные отклонения и стандартные ошибки коэффициентов регрессии 36
§ 4. Некоторые распределения. 39
4.1. Функция распределения и плотность распределения. 39
4.2. Нормальное распределение. 40
4.3. Распределение Стьюдента. 44
4.4. Распределение Фишера. 47
§ 5. Проверка гипотез. 48
5.1. Выбор нулевой и альтернативной гипотезы. Уровень значимости 48
5.2. T-тест для коэффициентов регрессии. 51
5.3. F-тест Фишера на состоятельность регрессии и t-тест для выборочного коэффициента корреляции 54
§ 6. Нелинейная регрессия. Простейшие модели. 56
6.1. Корреляционное отношение. 56
6.2. Нелинейность по переменным и по параметрам.. 60
6.3. Случайный член как множитель. 62
6.4. Подбор модели. 63
6.5. Эластичность. 65
Глава 2. МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ.. 67
§ 7. Основные множественной регрессии. 67
7.1. Случай двух независимых переменных. 67
7.2. Коэффициенты для модели множественной регрессии и их статистическая значимость 69
7.3. Коэффициент детерминации. 73
7.4. Проверка адекватности всей модели. 75
7.5. Нелинейные модели. 76
§ 8. Спецификация переменных и проблема мультиколлинеарности. 77
8.1. Проблема мультиколлинеарности. 77
8.2. Отсутствующая переменная. 79
8.3. Лишняя переменная. 80
8.4. Замещающие переменные. 80
§ 9. Фиктивные переменные. 82
9.1. Фиктивные переменные в регрессии. 82
9.2. Эталонная категория и фиктивные переменные. 82
9.3. Фиктивные переменные для коэффициентов наклона. 84
§ 10. Гетероскедастичность и взвешенный метод наименьших квадратов 86
10.1. Неэффективность МНК в случае гетероскедастичности. 86
10.2. Тест ранговой корреляции Спирмена. 88
10.3. Тест Голдфелда-Квандта. 89
10.4. Тест Глейзера. 90
10.5. Взвешенный метод наименьших квадратов (WLS) 91
§ 11. Автокорреляция и обобщенный метод наименьших квадратов. 92
11.1. Типичные графики наблюдений в случае автокорреляции. 92
11.2. Автокорреляция первого порядка. Критерий Дарбина-Уотсона. 94
11.3. Метод Кохрейна-Оркатта устранения автокорреляции. 97
11.4. Обобщенный метод наименьших квадратов. 98
Заключение. 99
Литература. 100
Предметный указатель. 101
Математико-статистические таблицы. 103
ВВЕДЕНИЕ
Эконометрика – раздел экономической науки, занимающийся разработкой и применением математических, и, прежде всего, экономико-статистических методов анализа экономических процессов, обработки статистической экономической информации.
Один из ответов на вопрос, что такое эконометрика, может звучать так: это наука, связанная с эмпирическим выводом экономических законов. То есть на основе данных и “наблюдений” эконометрика получает количественные зависимости для экономических соотношений. Эконометрика также формулирует экономические модели, основываясь на экономической теории или на эмпирических (опытных или статистических) данных, оценивает параметры моделей, делает прогнозы и дает рекомендации по экономической политике.
Таким образом, эконометрический подход к проблеме состоит в построении экономической модели и использовании эконометрических методов исследования экономики, которые позволяют изучать экономические процессы с количественной стороны.
Любые экономические данные представляют собой количественные характеристики каких-либо экономических объектов. Они формируются под действием множества факторов, не все из которых доступны внешнему контролю. Неконтролируемые факторы могут принимать случайные значения из некоторого множества значений и тем самым обусловливать случайность данных, которые они определяют. Стохастическая природа экономических статистических данных определяет необходимость применения специальных адекватных им статистических методов для их обработки. Эконометрический инструментарий базируется на методах и моделях прикладной математической статистики и некоторых элементах алгебры.
Математическая статистика – наука, изучающая методы обработки результатов наблюдений массовых случайных явлений, обладающих статистической устойчивостью, закономерностью, с целью выявления этой закономерности. Выводы о закономерностях, которым подчиняются явления, изучаемые математической статистикой, всегда основываются на ограниченном, выборочном числе наблюдений.
Закономерности в экономике выражаются в виде связей и зависимостей экономических показателей, что позволяет создавать соответствующие математические модели. Такие зависимости и модели могут быть получены только путем обработки реальных статистических данных, с учетом внутренних механизмов связи и случайных факторов. Однако модель может быть получена и на основе соответствующих экономических теорий.
Основным элементом эконометрического исследования являются взаимосвязи экономических переменных. Изучение таких взаимосвязей осложнено тем, что они не имеют строгих функциональных зависимостей, поскольку: во-первых, трудно выявить все основные факторы, влияющие на переменную; во-вторых, многие такие воздействия являются случайными, то есть содержат случайную составляющую; в-третьих, как правило, имеется ограниченный набор данных статистических наблюдений, которые к тому же содержат различного рода ошибки.
Математическая статистика (теория обработки и анализа данных) и ее применение в экономике – эконометрика – позволяют строить экономические модели и оценивать их параметры, проверять гипотезы о свойствах экономических показателей и формах их связи, что, в конечном счете, служит основой для экономического анализа и прогнозирования, создавая возможность для принятия обоснованных экономических решений.
Любое эконометрическое исследование всегда предполагает объединение теории (экономической модели) и практики (статистических данных). Будем использовать теоретические модели для описания и объяснения наблюдаемых процессов на основе собранных статистических данные, с целью построения и обоснования моделей.
Обычно предполагают, что все факторы, не учтенные явно в экономической модели, оказывают на объект некоторое результирующее воздействие, то есть являются величиной, которая неизвестна заранее и может быть описана как случайность. Для ее описания в модель добавляют случайный параметр e, интегрирующий в себе влияние всех, не учтенных явно факторов. Например, можно рассматривать модели спроса вида:
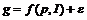 ,
,
где g – количество блага, р – цена, I – доход потребителя. Переменная e учитывает влияние всех прочих факторов (цен на другие товары, изменений моды, погоды и т. д.), не учтенных явно в функции спроса.
Введение случайного компонента в экономическую модели приводит к тому, что взаимосвязь остальных ее переменных перестает быть строго функциональной (детерминированной) и становится стохастической. Это делает модель доступной для проверки на основе статистических данных. Если проверка показала адекватность модели, то удается оценить параметры функционирования конкретного экономического объекта и сформулировать рекомендации для принятия практических решений. Работа с эконометрическими моделями требует использования инструментария оценивания и статистической проверки модели (”наука” моделирования), а также решения проблем выбора типа модели, набора объясняющих переменных и вида связей между ними (”искусство” моделирования).
Статистические данные в эконометрике являются основой для выявления и обоснования эмпирических закономерностей. Без конкретных количественных данных, характеризующих функционирование исследуемого экономического объекта, нельзя рассматривать эконометрическую модель.
Экономические данные обычно делят на два вида: перекрестные данные (cross-section data) и временные ряды (time series). Перекрестные данные – это данные по какому-либо экономическому показателю, полученные для разных однотипных объектов (фирм, регионов), относящихся к одному и тому же моменту времени. Временные ряды – это данные, характеризующие один и тот же объект, но в различные моменты времени. К первому типу, например, относятся данные бюджетных обследований населения в определенный момент времени; ко второму - данные о динамике уровня инфляции за определенный период. Данные временных рядов характеризуются определенными зависимостями. Например, могут быть связаны между собой последовательные отклонения от общей тенденции развития. В связях этих экономических показателей могут присутствовать задержки (временные лаги). Это обусловливает необходимость специальных методов обработки и анализа временных рядов по сравнению с данными перекрестных выборок.
В данном учебно-методическом пособии излагается основной теоретический материал, посвященный обработке перекрестных данных, а именно модель парной регрессии (глава 1) и модель множественной регрессии (глава 2). В первой главе имеется несколько дополнительных параграфов, которые не являются обязательными, но содержат много дополнительной, необходимой для последующего изучения, информации (параграфы 1 и 4).
Несмотря на то, что учебный предмет “Эконометрика” совсем недавно стал обязательным для преподавания в вузах, уже появилось достаточно большое количество учебной литературы [1-9], которая разнится по стилю изложения и содержанию, требует различной подготовки студентов для понимания и может использоваться студентами в качестве дополнительной литературы.
Данное пособие написано на основании одноименного курса, который неоднократно читался автором на третьем курсе экономического факультета БФСГУ.
Глава 1. МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
§ 1. Основные понятия математической статистики
1.1. Выборка и генеральная совокупность
Фундаментальными понятиями статистического анализа являются следующие: случайное событие, случайная величина (переменная), вероятность.
Под вероятностью некоторого случайного события понимается отношение числа исходов, благоприятствующих данному событию, к общему числу возможных равновероятных исходов.
Случайной величиной называется переменная, которая под воздействием случайных факторов может с определенными вероятностями принимать те или иные значения из некоторого множества. Это переменная, которой (даже при фиксированных обстоятельствах) нельзя приписать определенное значение. Случайная величина определяется законом распределения, который может быть представлен в форме таблицы, формулы или графика. Например, закон распределения числа очков при бросании игрального кубика может быть представлен в виде таблицы 1.
Таблица 1
Число очков | 1 | 2 | 3 | 4 | 5 | 6 |
Вероятность | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 |
Очевидно, что сумма всех этих вероятностей должна равняться единице, поскольку считаем, что с вероятностью “единица” переменная принимает хоть какое-нибудь из этих значений. Обычная (неслучайная, или детерминированная) переменная является предельным случаем случайной переменной, принимая единственное (при фиксированных обстоятельствах) значение с вероятностью “единица”.
Различают дискретные и непрерывные случайные величины. Случайная величина дискретна, если результаты наблюдений представляют собой конечный или счетный набор возможных чисел. Случайная величина непрерывна, если ее значения могут лежать в некотором континууме возможных значений. (Это предполагает, что их нельзя пересчитать, ставя в соответствие им натуральные числа 1,2,...) Значения непрерывной случайной величины могут лежать на отрезке, интервале, луче и т. д.
В основе математической статистики лежат понятия: генеральная совокупность и выборка. Под генеральной совокупностью подразумеваем все возможные наблюдения интересующего показателя, все исходы случайного испытания или всю совокупность реализаций случайной величины x. Пример генеральной совокупности – данные о доходах всех жителей какой-либо страны, о результатах голосования населения по какому-либо вопросу и т. д. Однако в большинстве случаев доступна только часть возможных наблюдений, взятых из генеральной совокупности, и называем это множество (точнее подмножество) значений выборкой. Таким образом, выборка – это множество наблюдений, составляющих лишь часть генеральной совокупности. Выборка объема n – это результат наблюдения случайной величины в генеральной совокупности, который повторяется n раз в одних и тех же условиях.
Мы обычно говорим о генеральной совокупности, когда используем определенные теоретические модели, но на практике в нашем распоряжении имеются лишь выборочные данные, и поэтому можем строить оценки теоретических характеристик, основываясь лишь на данных выборочных наблюдений. Целью математической статистики является получение выводов о параметрах, виде распределения и других свойствах случайных величин в генеральной совокупности по конечным наблюдениям – выборке.
Выборку называют репрезентативной (представительной), если она достаточно полно представляет изучаемые признаки и параметры генеральной совокупности. Для обеспечения репрезентативности (от фр. выборки применяют следующие способы отбора: простой отбор (последовательно отбирается первый случайно попавшийся объект), типический отбор (объекты отбираются пропорционально представительству различных типов объектов в генеральной совокупности), случайный отбор (например, с помощью таблицы случайных чисел) и т. п.
В эконометрике всегда известна только выборка из некоторого количества наблюдений случайной величины, и по данным выборки можно рассчитать только выборочные, а не теоретические характеристики этой случайной величины.
1.2. Теоретические характеристики случайной величины
Каждая случайная величина, значение которой определенно во всей генеральной совокупности имеет некоторые теоретические характеристики. Рассмотрим основные из них.
Математическое ожидание дискретной случайной величины — это взвешенное среднее всех ее возможных значений, причем в качестве весового коэффициента берется вероятность. Можно рассчитать его, перемножив все возможные значения случайной величины на их вероятности и просуммировав полученные произведения. Математически, если случайная величина обозначена как x, то ее математическое ожидание обозначается как М[x].
Предположим, что x может принимать n конкретных значений (х1,х2,...,хn) и что вероятность получения xi, равна pi. Тогда:
. (1.1)
Рассмотрим пример, в котором случайной переменной является число очков, выпадающее при бросании одной игральной кости. Закон распределения данной случайной величины задан в таблице 1. Тогда математическое ожидание будет равно:
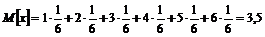 .
.
В данном случае математическим ожиданием является числом, которое не может принять случайная величина.
Если случайная величина x является непрерывной, то есть принимает значения из некоторого интервала, и известна её функция плотности распределения f(x), то математическое ожидание непрерывной случайной величины будет:
. (1.2)
Для случайной величины x математическое ожидание во всей генеральной совокупности часто обозначается как mx, и если понятно, о какой случайной величине идет речь, то нижний индекс опускают.
Как правило, в генеральной совокупности так много элементов и значение функции плотности неизвестно, что вычислить значения среднего по формулам (1.1) или (1.2) невозможно. Поэтому данный параметр в дальнейшем нами будет оцениваться.
Имеется несколько достаточно простых правил для вычисления математического ожидания, которые нам пригодятся в будущем.
Правило математического ожидания 1
Если у=c – константа, то M[y]=c;
Правило математического ожидания 2
Если c – константа, то M[с·y]=c·M[y];
Правило математического ожидания 3
Если x и у – две независимые случайные величины, то математическое ожидания их суммы равно сумме их математических ожиданий: M[x+y]= M[x]+M[y];
Правило математического ожидания 4
Если x и у – две независимые случайные величины, то математическое ожидание их произведения равно произведению их математических ожиданий: M[x·y]= M[x]·M[y];
Правило математического ожидания 5
Если x и у – две независимые случайные величины, a и b – константы, то математическое ожидание линейной свертки будет иметь вид M[a·x+b·y]= a·M[x]+b·M[y].
Второй важнейшей характеристикой случайной величины x является дисперсия, которая характеризует меру разброса. Она определяется как математическое ожидание квадрата разности между величиной x и ее средним, т. е. величины 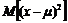 . Дисперсия обычно обозначается как
. Дисперсия обычно обозначается как ![]() или D[x], и если ясно, о какой переменной идет речь, то нижний индекс может быть опущен. В этом случае формула для вычисления дисперсии будет иметь вид:
или D[x], и если ясно, о какой переменной идет речь, то нижний индекс может быть опущен. В этом случае формула для вычисления дисперсии будет иметь вид:
![]() . (1.3)
. (1.3)
Рассмотрим более подробно данную формулу
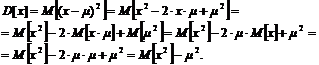
При выводе данной формулы использовался тот факт, что математическое ожидание в генеральной совокупности m является фиксированным значением, следовательно, может быть вынесено за знак математического ожидания. Это вторая формула для вычисления теоретической дисперсии. Наряду с дисперсией мерой разброса может служить и среднеквадратичное отклонение, которое определяется как корень квадратный из дисперсии ![]() . Во многих случаях среднеквадратичное использовать выгоднее, поскольку она имеет размерность соответствующую размерности x.
. Во многих случаях среднеквадратичное использовать выгоднее, поскольку она имеет размерность соответствующую размерности x.
Аналогично математическому ожиданию для дисперсии имеется несколько полезных правил.
Правило дисперсии 1
Если у=c – константа, то D[y]=0;
Правило дисперсии 2
Если c – константа, то D[с·y]=c2·D[y];
Правило дисперсии 3
Если x и у – две независимые случайные величины, то дисперсия их суммы равна сумме дисперсий: D[x+y]= D[y]+D[y];
Правило дисперсии 4
Если x и у – две независимые случайные величины, то дисперсия их разности равна сумме дисперсий: D[x–y]= D[y]+D[y].
Правила 3 и 4 утверждают, что для любых операций сложения и вычитания независимых случайных величин дисперсии всегда складываются, то есть разброс в любом случае будет увеличиваться.
Часто вместо рассмотрения случайной величины x, как единого целого, удобно разбить ее на постоянную и случайную составляющие, где постоянная составляющая всегда есть ее математическое ожидание. Если x – случайная переменная а m – ее математическое ожидание, то декомпозиция случайной величины записывается следующим образом:
x=m+u. (1.4)
где u – случайная составляющая (в регрессионном анализе она обычно представлена случайным членом).
Из определения и правил вычисления математического ожидания следует, что математическое ожидание величины случайного члена равно нулю, поскольку
M[u]=M[x–m]=M[x]– M[m]=m–m=0. (1.5)
Так как весь разброс случайной величины x обусловлен u, то теоретическая дисперсия данных случайных величин совпадает:
![]() . (1.5’)
. (1.5’)
![]() .
.
Таким образом, s2 может быть эквивалентно определена как дисперсия x или u.
Обобщая, можно утверждать, что если x — случайная переменная, определенная по формуле (1.4), где m — заданное число, u – случайный член с нулевым математическим ожиданием и дисперсией ![]() , то x имеет математическое ожидание равное m и дисперсию
, то x имеет математическое ожидание равное m и дисперсию ![]() .
.
Рассмотрим теперь случай, когда имеется не одна, а две случайные величины x и y, и необходимо оценить меру влияния одной неизвестной на другую.
Если x и у — случайные величины, то ковариация является мерой взаимосвязи между двумя величинами и определяется как математическое ожидание произведения отклонений этих величин от их средних значений:
, (1.6)
где mx и my – теоретические средние значения x и y соответственно.
Если x и у независимы, то их теоретическая ковариация равна нулю, поскольку из 4-го правила вычисления математического ожидания следует
Заметим, что дисперсия переменной может рассматриваться как ковариация между двумя величинами x
. (1.6’)
Для вычисления ковариации существуют правила подобные правилам для вычисления дисперсии и математического ожидания.
Правило ковариации 1
Если у=c – константа, то Сov(x, у) =0;
Правило ковариации 2
Если x и у – две случайные величины, то Cov(x, у) = Cov(y,x);
Правило ковариации 3
Если x и у – две независимые случайные величины, c – константа, то Cov (с·x, у) = с· Cov(x,y);
Правило ковариации 4
Если x и у – две случайные величины, a и b – константы, то добавление констант не влияет на значение ковариации между случайными величинами: Cov (x+a, у+b)=Cov(x, y).
Как уже отмечалось раннее, дисперсия суммы и разности двух случайных независимых величин равна сумме дисперсий. В случае, когда случайные величины произвольные данное правило будет иметь несколько другой вид.
Правило ковариации 5
Если x и у – случайные величины, то
![]() .
.
Если случайны величины независимые, а, следовательно, коэффициент корреляции равен нулю, то данное правило становится уже знакомым нам правилом по вычислению дисперсии.
Ковариационной матрицей двух случайных величин x и y называется матрица вида:
![]() . (1.7)
. (1.7)
Эта матрица симметрична и положительно определена. Её определитель называют обобщенной дисперсией для случайных величин x и y.
Ковариация весьма удобна с математической точки зрения, но не является особенно хорошим измерителем взаимосвязи между величинами, поскольку имеет размерность. Более точной мерой зависимости является коэффициент корреляции, который получается из коэффициента ковариации путем деления на среднеквадратичное отклонение каждой величины.
Теоретический коэффициент корреляции для переменных x и у традиционно обозначается греческой буквой rxy и определяется следующим образом:
![]() . (1.8)
. (1.8)
Если x и y независимы, то rxy равно нулю, так как равна нулю теоретическая ковариация. Если между переменными существует положительная зависимость, то cov(x,y), а, следовательно, и rxy, будут положительными. Если существует строгая положительная линейная зависимость, то rxy примет максимальное значение, равное 1. Аналогичным образом при отрицательной зависимости rxy будет отрицательным с минимальным значением – 1.
Корреляционной матрицей двух случайных величин x и y называется матрица вида:
![]() . (1.9)
. (1.9)
Все свойства, которые выполняются для ковариационной матрицы W, выполняются и для данной матрицы K.
В случае если имеется более двух случайных величин ковариационная и корреляционная матрица определяется подобным образом. А определители данных матриц будут обобщенной ковариацией и корреляцией данной совокупности случайных величин.
Характеристиками случайной величины также являются некоторые показатели, такие как асимметрия и эксцесс, однако нам будет достаточно данных: математическое ожидание, дисперсия, ковариация и корреляция.
1.3. Оценки как случайные величины
До сих пор мы предполагали, что имеется точная информация о рассматриваемой случайной величины, в частности – об ее законе распределения. С помощью этой информации можно рассчитать все теоретическое характеристики, такие как математическое ожидание, дисперсию и т. д. Однако на практике, за исключением искусственно простых случайных величин, мы не знаем точного вероятностного распределения или плотности распределения. Тем не менее, необходимо оценить теоретические характеристики для всей генеральной совокупности, на основании данных выборки произвольного размера n. При этом сами элементы выборки (х1,х2,...,хn) являются не фиксированными значениями, как предполагалось ранее, а также случайными величинами.
Процедура оценивания всегда одинакова. Берется выборка из n наблюдений, и с помощью подходящей формулы рассчитывается оценка нужной характеристики. В данном случае приходится иметь дело с двумя различными терминами это оценка, как формула оценивания и рассчитанным по ней для данной выборки числом, являющимся значением оценки.
Оценка, способ оценивания (estimator) – общее правило, формула для получения приближенного численного значения, какого-либо параметра по данным выборки, а следовательно, является случайной величиной и значение оценки (estimation) – число, полученное в результате применения оценки к конкретной выборке.
Приведем формулы оценивания для двух важнейших характеристик генеральной совокупности.
Выборочное среднее ![]() обычно дает оценку для математического ожидания m,
обычно дает оценку для математического ожидания m,
. (1.10)
и величина s2 , которая служит оценкой дисперсии s2.
. (1.11)
Отметим, что это обычные формулы оценки математического ожидания и дисперсии генеральной совокупности, однако не единственные.
Например, для оценки математического ожидания можно использовать значение ![]() .
.
Конечно, не все формулы оценки, которые можно представить, одинаково хороши. Причина, по которой используются эти оценки, в том, что они в наилучшей степени соответствует двум очень важным критериям – несмещенности и эффективности. Эти критерии будут рассмотрены ниже.
Получаемая оценка представляет частный случай случайной переменной, поскольку каждое значение хi из выборки является случайной величиной, а следовательно, и любая функция также будет случайной величиной.
Возьмем, например, выборочное среднее ![]() , которое является оценкой математического ожидания. Величина хi в i-м наблюдении может быть разложена на две составляющие: постоянную часть m и случайную составляющую ui, то есть хi=m+ ui.
, которое является оценкой математического ожидания. Величина хi в i-м наблюдении может быть разложена на две составляющие: постоянную часть m и случайную составляющую ui, то есть хi=m+ ui.
Следовательно,
,
где ![]() – выборочное среднее величин u.
– выборочное среднее величин u.
Отсюда можно видеть, что ![]() , подобно x имеет как фиксированную, так и случайную составляющие. Её фиксированная составляющая – математическое ожидание m, а ее случайная составляющая
, подобно x имеет как фиксированную, так и случайную составляющие. Её фиксированная составляющая – математическое ожидание m, а ее случайная составляющая ![]() есть среднее значение случайной составляющей в выборке.
есть среднее значение случайной составляющей в выборке.
Величина s2 – оценка дисперсии s2 является так же случайной переменной.
Поскольку 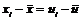 ,
,
то .
Таким образом, оценки s2 и ![]() зависят только от случайной составляющей ui в элементах выборки. Поскольку эти составляющие меняются от выборки к выборке, также от выборки к выборке меняется и значение оценок s2 и
зависят только от случайной составляющей ui в элементах выборки. Поскольку эти составляющие меняются от выборки к выборке, также от выборки к выборке меняется и значение оценок s2 и ![]() .
.
Так как оценки являются случайными переменными, их значения лишь по случайному совпадению могут в точности равняться характеристикам генеральной совокупности. Обычно в них будет присутствовать определенная ошибка, которая может быть большой или малой, положительной или отрицательной, в зависимости от случайных составляющих u в выборке.
Желательно, тем не менее, чтобы оценка в среднем была аккуратной, то есть, чтобы математическое ожидание оценки равнялось соответствующей характеристике для всей генеральной совокупности. Если это так, то оценка называется несмещенной. Если это не так, то оценка называется смещенной.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
