

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Иногда таблицы распределения Стьюдента приводятся для двусторонних критических точек ![]() , определяемых из условия
, определяемых из условия 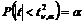 . В силу симметричности распределения Стьюдента эти точки связаны с односторонними критическими точками соотношением
. В силу симметричности распределения Стьюдента эти точки связаны с односторонними критическими точками соотношением ![]() , так как при заданной вероятности а попадания в оба хвоста распределения вероятность попадания в один из хвостов распределения будет в два раза меньше.
, так как при заданной вероятности а попадания в оба хвоста распределения вероятность попадания в один из хвостов распределения будет в два раза меньше.
Кроме того, в некоторых таблицах распределения Стьюдента вместо малых чисел а (вероятностей попадания в хвост распределения) приводятся числа 1–а (вероятности попадания в интервал ![]() для односторонних критических точек и в интервал
для односторонних критических точек и в интервал 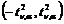 для двусторонних критических точек).
для двусторонних критических точек).
4.4. Распределение Фишера
Это распределение (называемое иногда распределением дисперсионного отношения) имеет случайная величина, равная отношению двух независимых случайных величин: величины ![]() (случайная величина, имеющую распределение c2 с k1 степенями свободы) и
(случайная величина, имеющую распределение c2 с k1 степенями свободы) и ![]() (случайная величина, имеющую распределение c2 с k2 степенями свободы).
(случайная величина, имеющую распределение c2 с k2 степенями свободы).
Величина
![]() (4.6)
(4.6)
имеет распределение Фишера с k1 и k2 степенями свободы.
Квадрат случайной величины, имеющей распределение Стьюдента с k2 степенями свободы, имеет распределение Фишера с (1, k2) степенями свободы.
Критическая точка 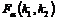 в данном случае имеет следующий смысл:
в данном случае имеет следующий смысл: ![]() . В таблице, как правило, для различных сочетаний чисел степеней свободы k1 и k2 приведены критические точки функции распределения Фишера, соответствующие вероятности а=0,05 (приложение 3).
. В таблице, как правило, для различных сочетаний чисел степеней свободы k1 и k2 приведены критические точки функции распределения Фишера, соответствующие вероятности а=0,05 (приложение 3).
Критические точки распределения Фишера обладают свойством:
![]()
В эконометрике чаще всего используются эти три распределения случайных величин: нормальное распределение, распределение Стьюдента и Фишера.
1. Нормально распределённая случайная величина ![]() задается формулой плотности (4.1). Для нормального распределения имеется, как правило, таблица значений функции распределения. Критические точки обозначаются
задается формулой плотности (4.1). Для нормального распределения имеется, как правило, таблица значений функции распределения. Критические точки обозначаются ![]() .
.
2. Распределение Стьюдента – это композиция случайных величин, имеющих нормальное распределение, при этом функция плотности зависит от двух переменных: значения t и числа степеней свободы n. При увеличении числа степеней свободы данное распределение стремится к нормальному распределению. Как правило, в статистических таблицах задаются значения критических точек ![]() .
.
3. Распределение Фишера – это отношение двух случайных величин, имеющих распределение c2. В таблице заданы критические точки с различными значениями![]() ,
,![]() , и, как правило, с одной вероятностью a =0.05.
, и, как правило, с одной вероятностью a =0.05.
§ 5. Проверка гипотез
5.1. Выбор нулевой и альтернативной гипотезы. Уровень значимости
Начнем с допущения о том, что формулирование гипотезы предшествует эксперименту, и что предполагается наличие некоторой гипотетической связи или зависимости. Например, можно считать, что темпы общей инфляции в экономике (p в процентах) зависят от темпов инфляции, вызванной ростом заработной платы (w в процентах), и что эта зависимость описывается линейным уравнением:
p=a + b ×w + u, (5.1)
где a и b – параметры, а u – случайный член.
Далее можно построить гипотезу о том, что без учета эффектов, вносимых случайным членом, общая инфляция равна инфляции, вызванной ростом заработной платы. В этих условиях можно сказать, что гипотеза, которую собираетесь проверить, считается нулевой, обозначается Н0, состоит в том, что b = 1, при a=0.
Мы также определяем альтернативную гипотезу, которая обозначается H1 и представляет собой заключение, даваемое в том случае, если экспериментальная проверка указала на ложность Н0. В данном случае эта гипотеза состоит в том, что b¹1. Две гипотезы сформулированы с использованием следующих обозначений:
Н0: b =1,
H1: b¹1.
В этом конкретном случае, если действительно считать, что общая инфляция равна инфляции, вызванной ростом заработной платы, мы делаем попытку защитить нулевую гипотезу Н0, (подвергнув ее максимально строгой проверке) надеясь, что она не будет опровергнута.
Обобщив сказанное, введем определения.
Нулевая гипотеза (Н0) – утверждение о том, что неизвестный параметр модели принадлежит заданному множеству А.
Альтернативная гипотеза (Н1) – утверждение о том, что неизвестный параметр модели принадлежит другому заданному множеству B, при этом пересечение множеств A и B пусто.
Последующее рассмотрение касается модели парной регрессии.
Возьмем общий случай, в котором в нулевой гипотезе утверждается, что b равно некоторому конкретному значению b0, и альтернативная гипотеза состоит в том, что b не равно этому значению.
H0: b =b0,
Н1: b ¹ b0.
Можете предпринять попытку отклонить или подтвердить нулевую гипотезу в зависимости оттого, что вам необходимо в данном случае. Будем предполагать, что четыре условия Гаусса–Маркова выполняются, и остаточный член u имеет нормальное распределение. Если гипотеза Н0 верна, то оценка b параметра b, будет иметь нормальное распределение с математическим ожиданием b0 и стандартным отклонения ![]() .
.
Допустим, что знаем значение стандартного отклонения величины известно ![]() . На практике значение этого отклонения не известно (так же как и неизвестные значения параметров a и b) и подлежит оценке.
. На практике значение этого отклонения не известно (так же как и неизвестные значения параметров a и b) и подлежит оценке.
Предположим, что стандартное отклонение ![]() . Тогда, если нулевая гипотеза Н0:b=1 верна, то оценки коэффициентов регрессии будут находиться между 0,8 и 1,2 с вероятностью 0,95 (правило двух сигма) или между 0,7 и 1,3 с вероятностью 0,9972 (правило трех сигма).
. Тогда, если нулевая гипотеза Н0:b=1 верна, то оценки коэффициентов регрессии будут находиться между 0,8 и 1,2 с вероятностью 0,95 (правило двух сигма) или между 0,7 и 1,3 с вероятностью 0,9972 (правило трех сигма).
Предположим, что мы взяли фактическую выборку из наблюдений общей инфляции и инфляции, вызванной ростом заработной платы, и построили оценку b для параметра b. Если оценка близка 1, то мы можем принять нулевую гипотезу, так как она и результат оценивания для выборки совместимы друг с другом. Но с другой стороны, предположим, что оценка значительно отличается от 1. Допустим, что она равна 0,7. Тогда можно прийти к одному из двух выводов:
1. Можете продолжать считать, что нулевая гипотеза b =1 верна и эксперимент дал случайный результат. Вероятность получения такого значения равна 0,008, но, тем не менее, она имеет место.
2. Можно сделать вывод о том, что гипотеза противоречит результату и наиболее правдоподобным объяснением является то, что величина b не равняется 1. То есть мы принимаем альтернативную гипотезу Н1: b ¹ b0.
Вывод, который мы сделаем зависит от уровня значимости g, который в большинстве случаев берется 5% или 1%.
Проверку любой гипотезы начинают с вычисления некоторой статистики. В данном случае это статистика z, которая имеет вид:
![]() (5.1)
(5.1)
Нулевая гипотеза не будет отвергнута при уровне значимости g, если выполнится неравенство
![]() ,
,
где ![]() – двусторонняя критическая точка нормального распределения.
– двусторонняя критическая точка нормального распределения.
Это условие можно записать в виде:
![]() (5.2)
(5.2)
Умножив все части неравенства на![]() и перенеся значения b0, можно получить следующее неравенство:
и перенеся значения b0, можно получить следующее неравенство:
![]()
Данное неравенство задает множество значений для величины b, которые не приводят к отказу от конкретной нулевой гипотезы о том, что b =b0. Это множество значений получило название области принятия гипотезы для b при уровне значимости g.
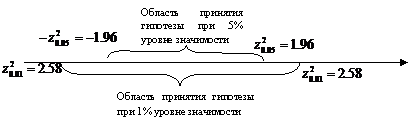 Поскольку
Поскольку ![]() , то при проверке гипотезы с уровнем значимости 5% данное условие будет иметь вид –1,96<z<1,96; а при проверке с уровнем значимости 1% (
, то при проверке гипотезы с уровнем значимости 5% данное условие будет иметь вид –1,96<z<1,96; а при проверке с уровнем значимости 1% (![]() ) данное условие будет иметь вид –2,58<z<2,58.
) данное условие будет иметь вид –2,58<z<2,58.
То есть, при уменьшении уровня значимости, увеличивается область принятия гипотезы.
Если проверяется нулевая гипотеза Н0:b=1, и известно, что ![]() , то можно принять гипотезу при уровне значимости в 5%, если величина
, то можно принять гипотезу при уровне значимости в 5%, если величина
![]() ,
,
![]() ,
,
и уровне значимости 1%, если
![]() ,
,
![]() .
.
Соответственно, если коэффициенты не попадают в данные интервалы, то нулевая гипотеза отвергается, при соответствующем уровне значимости.
Почему недостаточно ограничиться только одним уровнем? Причина заключается в том, что обычно делается попытка найти баланс между риском допущения ошибок I и II рода.
Ошибка I рода – ситуация, нулевая гипотеза была отвергнута, а она была истинной (оценка параметра не попала в область принятия нулевой гипотезы),
Ошибка II рода – ситуация, когда не отвергнута ложная гипотеза (оценка параметра попала в область принятия нулевой гипотезы).
Вполне очевидно, что чем ниже уровень значимости, тем больше область принятия гипотезы и тем меньше риск получения ошибок I рода. Если используется уровень значимости, равный 5%, то отвергается истинная гипотеза в 5% случаев. Если уровень значимости составляет 1%, вы ошибка I рода совершается в 1% случаев. Таким образом, в этом отношении однопроцентный уровень значимость более надежен. В то же время если нулевая гипотеза ложна, то чем ниже уровень значимости, тем шире область принятия гипотезы, и тем выше риск допущения ошибки II.
Таким образом, если выбрать высокий уровень значимости, то имеется высокий риск допущения ошибки II рода, когда гипотеза ложна. Если выбираете низкий уровень значимости, то относительно высоким риском допущения ошибки I рода, если гипотеза истинна.
На самом деле часто нет необходимости использовать оба уровня значимости. Так, если гипотеза отвергается при 1%-м уровне значимости, то из этого автоматически следует, что она будет отклонена при уровне значимости в 5%. Если же не отвергаете гипотезу при уровне значимости в 5%, то не отвергнете ее и при 1%-м уровне значимости. Только в одном случае вы должны представить оба результата: если гипотеза отвергается на 5%-м, но не на 1%-м уровне значимости.
5.2. T-тест для коэффициентов регрессии
До сих пор мы считали, что стандартное отклонение величины b известно. Однако на практике это допущение нереально. Это приводит к изменению процедуры проверки гипотез. Во-первых, величина z определяется на основе использования стандартной ошибки ![]() вместо стандартного отклонения
вместо стандартного отклонения ![]() . Во-вторых, критические уровни определяются величиной, имеющей t-распределение Стьюдента вместо нормального распределения.
. Во-вторых, критические уровни определяются величиной, имеющей t-распределение Стьюдента вместо нормального распределения.
Для испытания нулевой гипотезы H0: b=b0 статистика (t-статистика) имеет вид:
![]() (5.3)
(5.3)
t-тест (тест Стьюдента) – проверка гипотезы значении коэффициента b с помощью распределения Стьюдента.
Чаще всего проверяют гипотезу H0: b=0. Если данную гипотезу удается отвергнуть, то коэффициент b считается значимым, а, следовательно, данная переменная влияет на зависимую переменную. В противном случае найденный коэффициент считается незначимым, и можно сделать вывод, что экономические показатели не оказывают влияния друг на друга.
Если в тесте Стьюдента значение t-статистики попало между критическими значениями распределения Стьюдента, соответствующими уровню значимости g, и числу степеней свободы (n–2), то нулевая гипотеза не отвергается. В противном случае нулевая гипотеза отвергается с вероятностью допущения ошибки рода в g%. Таким образом, условие того, что оценка регрессии не должна приводить к отказу от нулевой гипотезы b = b0, будет следующим:
![]() , (5.4)
, (5.4)
при уровне значимости g и числом степеней свободы n.
Рассмотрим пример. Пусть имеется выборка из 25 элементов, при анализе которой было получено следующее уравнение регрессии
у = 55,3 + 0,093х
(2,4) (0,003)
Цифры, указанные в скобках, являются стандартными ошибками. Формулируем нулевую гипотезу о том, что b=0, и затем пытаемся опровергнуть ее. Соответствующая t-статистика будет:
![]() .
.
Поскольку в выборку включено 25 наблюдений, и оценили два параметра, то число степеней свободы составляет 23. Критическое значение для t при 5%-м уровне значимости с 23 степенями свободы равняется 2,069. Причем t=31, не лежит между значениями в интервале [-2,069,2.069], то можно отказаться от нулевой гипотезы, а следовательно регрессор считается значимым. Критическое значение t при 1%-м уровне значимости с 23 степенями свободы составляет 2,807. Следовательно, можно отказаться от нулевой гипотезы также и при этом уровне значимости.
Нулевая гипотеза о том, что b=0, используется очень часто. Поэтому большая часть программ для обработки регрессии, автоматически выводят t-статистику для этого специального случая. Если, однако, нулевая гипотеза определяет некоторое ненулевое значение величины b, то необходимо использовать более общее выражение, а t-статистика вычисляется вручную.
До сих пор мы предполагали, что гипотеза предшествует эмпирическим исследованиям. Однако это необязательно. Очень часто гипотеза и эксперимент взаимодействуют. В этом случае необходимо знать, какие гипотезы совместимы с результатом оценивания регрессии. Коэффициент регрессии b и гипотетическое значение b будут совместимыми, если выполняются условия:
![]() .
.
Отсюда следует, что гипотетическое значение b является совместимым с результатом оценивания регрессии, если величина b удовлетворяет неравенству:
![]() . (5.5)
. (5.5)
Любое гипотетическое значение b, которое удовлетворяет соотношению, будет автоматически совместимо с оценкой b. Множество всех значений называется доверительный интервал для величины b. Посредине доверительного интервала лежит сама величина b.
Аналогичным образом можно проверить на значимость коэффициент a. В этом случае проверяют гипотезу H0: a=0, для чего находится t-статистика в виде:
![]() .
.
и если значение данной статистики лежит в интервале от ![]() до
до ![]() , то принимается нулевая гипотеза, а параметр a считается незначимым. В противном случае нулевая гипотеза отклоняется, и параметр считается значимым.
, то принимается нулевая гипотеза, а параметр a считается незначимым. В противном случае нулевая гипотеза отклоняется, и параметр считается значимым.
Для величины a можно аналогичным образом ввести доверительный интервал:
![]() . (5.6)
. (5.6)
Кроме данных тестов, которые называются двусторонними можно рассматривать и односторонние тесты. Односторонний тест – тест на проверку гипотезы, в котором область принятия гипотезы имеет только одно критическое значение. Как правило, односторонний тест применяется в том случае, когда имеется информация о том, куда отклоняется данный параметр. В этом случае используются односторонние критические точки.
5.3. F-тест Фишера на состоятельность регрессии и t-тест для выборочного коэффициента корреляции
Напомним, что R2 – коэффициент детерминации, определяемый из условия ![]() , где TSS – общая сумма квадратов отклонений, RSS – объясненной суммой квадратов, ESS – необъясненной суммой квадратов отклонений, при этом выполняется равенство TSS=ESS+RSS.
, где TSS – общая сумма квадратов отклонений, RSS – объясненной суммой квадратов, ESS – необъясненной суммой квадратов отклонений, при этом выполняется равенство TSS=ESS+RSS.
Как узнать, действительно ли полученное при оценке регрессии значение коэффициента R2 отражает истинную зависимость или оно появилось случайно? Традиционно процедура состоит в использовании косвенного подхода и выполнении так называемого F-теста, основанного на анализе дисперсии.
F-тест (тест Фишера) – проверка гипотезы H0: R2=0 (значимость всей регрессии), который имеет два числа степеней свободы – верхнее p (количество объясняющих переменных) и нижнее q (количество наблюдений в выборке минус количество оцениваемых коэффициентов).
Общая формула для F-статистики имеет вид:
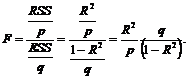 (5.7)
(5.7)
В случае парной регрессии верхнее число степеней свободы будет равно p=1, а нижнее q=n –2, следовательно, значение F-статистики будет иметь вид:
![]() (5.8)
(5.8)
Если F-статистика Фишера превысит критическое значение, то есть выполняется неравенство ![]() с некоторым уровнем значимости g, то нулевая гипотеза отвергается, и регрессия считается значимой. В противном случае нулевая гипотеза не отвергается и все полученное уравнение регрессии считается незначимым, следовательно, данный набор наблюдений не отвечает линейной модели. Как правило, данную гипотезу проверяют с двумя уровнями значимости.
с некоторым уровнем значимости g, то нулевая гипотеза отвергается, и регрессия считается значимой. В противном случае нулевая гипотеза не отвергается и все полученное уравнение регрессии считается незначимым, следовательно, данный набор наблюдений не отвечает линейной модели. Как правило, данную гипотезу проверяют с двумя уровнями значимости.
Рассмотрим проверку ещё одной гипотезы, а именно гипотезы о значимости коэффициента корреляции. Будет формулирование нулевой гипотезы о том, что зависимости нет 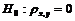 , а затем попытаемся ее опровергнуть.
, а затем попытаемся ее опровергнуть.
Проверку данной гипотезы можно осуществить только на основании выборочного коэффициента, который вычисляется следующим образом:
![]() .
.
и как выяснили ранее, равняется коэффициенту детерминации R2 .
Вычисляется t-статистика, которая имеет распределение Стьюдента с (n–2) степенями свободы и имеет следующий вид:
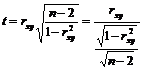 (5.9)
(5.9)
Выбрав уровень значимости g, находите критическое значение с (n–2) степенями свободы, и если величина t превышает это критическое значение (в положительную или отрицательную сторону, то есть ![]() ), нулевая гипотеза о том, что
), нулевая гипотеза о том, что ![]() отклоняется, и можно заключить, что линейная зависимость имеет место.
отклоняется, и можно заключить, что линейная зависимость имеет место.
В случае парного регрессионного анализа (и только парного регрессионного анализа) t-критерий для гипотезы ![]() , F-тест для коэффициента R2 и t-критерий для гипотезы b=0 эквивалентны.
, F-тест для коэффициента R2 и t-критерий для гипотезы b=0 эквивалентны.
Начнем с определения зависимости между первыми двумя тестами.
I-г |
Поскольку ![]() , F-статистика для коэффициента R2 (5.8) является в точности квадратом t-статистики для
, F-статистика для коэффициента R2 (5.8) является в точности квадратом t-статистики для ![]() (5.9). Как и следовало ожидать, критическое значение F будет равно квадрату критического значения t-статистики, при любом уровне значимости, и эти два теста всегда дают один и тот же результат, поскольку переменная, имеющая распределение Фишера, при условии, что первое число степеней свободы равно 1, имеет распределение квадрата Стьюдента.
(5.9). Как и следовало ожидать, критическое значение F будет равно квадрату критического значения t-статистики, при любом уровне значимости, и эти два теста всегда дают один и тот же результат, поскольку переменная, имеющая распределение Фишера, при условии, что первое число степеней свободы равно 1, имеет распределение квадрата Стьюдента.
Более того, можно показать, что величина b будет значимо отличаться от нуля при использовании t-теста, если и только если F-тест значим. Используя тот факт, что 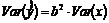 , можем переписать выражение для стандартной ошибки величины b:
, можем переписать выражение для стандартной ошибки величины b:
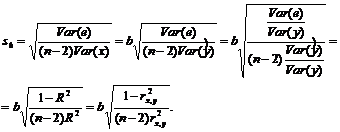
Следовательно,
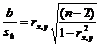 ,
,
то есть t-статистика для проверки гипотезы b =0 такая же, как и t-статистика для проверки гипотезы ![]() , а поскольку данные тесты используют одно и тоже распределение, то они будут давать одинаковый результат.
, а поскольку данные тесты используют одно и тоже распределение, то они будут давать одинаковый результат.
Таким образом, в случае парной регрессии проверка нулевой гипотезы H0:b=0 тестом Стьюдента и проверка нулевой гипотезы H0:R2=0 тестом Фишера дают одинаковые результаты. Эквивалентный результат дает тест Стьюдента для гипотезы . Это утверждение справедливо при наличии только одной независимой переменной и линейной модели.
§ 6. Нелинейная регрессия. Простейшие модели
6.1. Корреляционное отношение
Коэффициент корреляции достаточно точно оценивает степень тесноты связи лишь в случае линейной зависимости. При наличии криволинейной зависимости коэффициент корреляции может быть близок 0. Потому в таких случаях рекомендуется использовать в качестве показателя степени тесноты корреляционное отношение h – характеристику тесноты связи зависимой переменной y и объясняющей переменной (регрессора) x при их криволинейной зависимости. Как и ранее будем предполагать, что имеется некоторая выборка наблюдений ![]() .
.
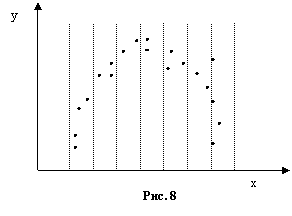
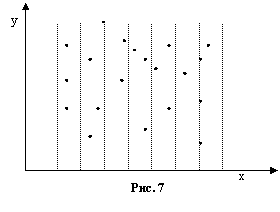 Рассмотрим два различных варианта расположения точек на графике, при этом на рисунке 7 представлен случай, когда зависимости не наблюдается, а на рисунке 8 можно предположить наличие квадратичной зависимости. В обоих случаях коэффициент корреляции будет близок к нулю. Используя известные нам правила, можно вычислить среднее значение по y и дисперсии
Рассмотрим два различных варианта расположения точек на графике, при этом на рисунке 7 представлен случай, когда зависимости не наблюдается, а на рисунке 8 можно предположить наличие квадратичной зависимости. В обоих случаях коэффициент корреляции будет близок к нулю. Используя известные нам правила, можно вычислить среднее значение по y и дисперсии ![]() для обоих случаев. Эти параметры могут совпадать между собой. Попробуем теперь произвести группировку данных по значениям x. Выделенные группы на рисунках обозначены штриховыми вертикальными линиями. Анализируя положение точек, при группировке можно прийти к очевидному выводу: если не просматривается никакой зависимости, то дисперсия, вычисленная отдельно для каждой группы будет приблизительно совпадать с общей дисперсией
для обоих случаев. Эти параметры могут совпадать между собой. Попробуем теперь произвести группировку данных по значениям x. Выделенные группы на рисунках обозначены штриховыми вертикальными линиями. Анализируя положение точек, при группировке можно прийти к очевидному выводу: если не просматривается никакой зависимости, то дисперсия, вычисленная отдельно для каждой группы будет приблизительно совпадать с общей дисперсией ![]() . Однако, если имеется некоторая зависимость, то разброс в каждой группе будет минимальным. Теперь перейдем к формальному определению корреляционного отношения.
. Однако, если имеется некоторая зависимость, то разброс в каждой группе будет минимальным. Теперь перейдем к формальному определению корреляционного отношения.
 При этом количество групп будем обозначать через k, величину интервала hx и границы для каждой группы
При этом количество групп будем обозначать через k, величину интервала hx и границы для каждой группы ![]() и
и ![]() ,
, ![]() .
.
Как правило, число групп определяется формулой Стэрджесса, которая имеет следующий вид:
k = 1 + 3,322×lg(n), (6.1)
где n – общее число наблюдений.
Например, если имеется 20 различных данных, то общее число групп будет k=1+3,322×lg20»5, а если число наблюдение равно 100, то k=1+3,322×lg100 = 1+3,322×2»8.
Далее определяем размах вариации R как разность между максимальным и минимальным значениями зависимой переменной x:
![]() . (6.2)
. (6.2)
Для определения интервала необходимо размах разделить на число групп k ,
т. е. ![]() . (6.3)
. (6.3)
После того, как определено количество групп и интервал необходимо установить границы для каждой группы, при этом пользуются следующим правилом. За началом первой группы берут минимальное значение x, уменьшенное на половину интервала, то есть ![]() , а за конечное значение в первой группе берут значение
, а за конечное значение в первой группе берут значение 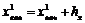 . За начальное значение второй группы берут конечное значение в первой группе и так далее. Нетрудно заметить, что конечное значение в последней k-й группе будет
. За начальное значение второй группы берут конечное значение в первой группе и так далее. Нетрудно заметить, что конечное значение в последней k-й группе будет ![]() .
.
После того, как подсчитаны границы каждой группы, можно подсчитать количество элементов попавших в каждую группу, которое обозначается через nj, при этом должно выполняться равенство:
![]() .
.
В каждой группе имеется некоторое количество наблюдений, а следовательно, для каждой группы можно найти среднее, которое будем обозначать через ![]() и внутригрупповую дисперсию
и внутригрупповую дисперсию ![]() . Общая дисперсия
. Общая дисперсия ![]() может быть разложена на две составляющие. Первая составляющая – межгрупповая дисперсия d2, характеризующая те изменения y, которая складывается под влиянием изменения регрессора x
может быть разложена на две составляющие. Первая составляющая – межгрупповая дисперсия d2, характеризующая те изменения y, которая складывается под влиянием изменения регрессора x
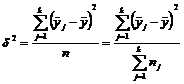 (6.4)
(6.4)
где ![]() – среднее значение в соответствующей группе;
– среднее значение в соответствующей группе; ![]() – среднее значение для всей выборки.
– среднее значение для всей выборки.
Вторая составляющая – средняя из внутригрупповых дисперсий ![]() , оценивающая ту часть разброса y, которая обусловлена действием других причин:
, оценивающая ту часть разброса y, которая обусловлена действием других причин:
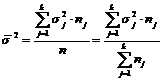 , (6.5)
, (6.5)
где ![]() – дисперсия y в соответствующей группе.
– дисперсия y в соответствующей группе.
Общая дисперсия равна:
![]() (6.6)
(6.6)
Зная общую и межгрупповую дисперсии, можно оценить ту долю, которую составляет вариация под действием фактора x в общей дисперсии y, т. е. найти отношение ![]() .
.
Извлекая квадратный корень из этого отношения, получаем корреляционное отношение:
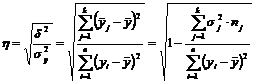 . (6.7)
. (6.7)
В тех случаях, когда среднее в каждой группе практически не отличается от среднего значения для всей выборки, числитель будет близок к нулю, а следовательно, и все корреляционное отношение будет близко к нулю. В тех случаях, когда средняя из внутригрупповых дисперсий близка к нулю, величина корреляционного отношения близка к 1, т. е. практически вся дисперсия y обусловлена действием регрессора x.
Корреляционное отношение изменяется в пределах от 0 до 1, и анализ тесноты связи полностью соответствует линейному коэффициенту корреляции. Вычисление корреляционного отношения возможно лишь при наличии достаточно большого числа данных, ибо в противном случае будет большое количество групп с небольшим количеством наблюдений в каждой, и вычисления будут лишены смысла.
Когда связь между переменными уклоняется от линейной формы, то h (корреляционное отношение) и r (коэффициент корреляции) несколько отличаются, причем h всегда больше r по абсолютной величине. При проверке возможности использования линейной модели в качестве формы уравнения определяют разность квадратов h2 – r2 , и если эта разность менее 0,1, то считается возможным применять линейной модели корреляции. Однако, если эта разность больше 0,1 и коэффициент корреляции мал, а корреляционное отношение велико, то зависимость может иметь любой другой, нелинейный вид.
6.2. Нелинейность по переменным и по параметрам
Одним из недостатков линейного регрессионного анализа является то, что он может быть применен только к линейным моделям вида:
y=a+b×x+u,
Однако во многих случаях из теоретических предпосылок можно получить, что связь между данными не является линейной, следовательно, необходимо строить нелинейные модели, а затем пытаться их оценивать. Для характеристик связей экономических явлений широко применяются следующие модели:
Полиноминальная (степени p) ![]()
Логарифмическая ![]()
Гиперболическая ![]()
Дробно-линейная ![]()
Показательная ![]()
Степенная ![]()
Логистическая ![]() .
.
Пока ни в одну из этих моделей не включен случайный член u. Это не означает, что его вовсе нет, поскольку он всегда присутствует в любой экономической модели. Однако его вид и способ включения в модель будет нами рассмотрен позже, при анализе выполнения условий Гаусса–Маркова.
Рассмотрим отдельно каждую модель.
В случае если мы пытаемся построить полином некоторой степени p (при этом p должно быть меньше n–1), то необходимо минимизировать сумму квадратов остатков, которая имеет вид:
![]()
Необходимые условия оптимальности будут:
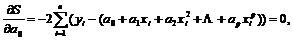
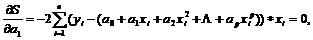
………………………………………………………….
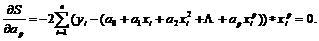
Следовательно, при построении полинома p-й степени, необходимо решить систему p+1 уравнений с таким же количеством переменных. Частным случаем и довольно широко используемым случаем полинома является квадратичная зависимость (парабола).
Рассмотрим другие модели, для чего отметим, что линейная регрессии являются линейной в двух смыслах. Во-первых, она линейна по переменным, поскольку состоит из взвешенной суммы переменных, а параметры являются весами. Во-вторых, она также является линейной по параметрам, так как состоит из взвешенной суммы параметров а, переменные x в данном случае являются весами.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
