

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
а) установление наличия мультиколлинеарности;
б) определение причин возникновения мультиколлинеарности;
в) разработка мер по ее устранению.
Чтобы устранить мультиколлинеарности, необходимо исключить из модели один или несколько линейно-связанных регрессоров. Вопрос о том, какой из факторов следует отбросить, решается на основе качественного и логического анализов изучаемых явлений.
Таким образом, из-за мультиколлинеарности невозможно отделить влияние отдельной объясняющей переменной от влияния всей совокупности регрессоров. Поэтому параметры модели множественной регрессии b1, b2,…,bm лишь условно показывают степень влияния. Нельзя также разбить коэффициент детерминации R2 на части, соответствующие отдельным регрессорам.
Если точно известно, какие переменные должны быть включены в регрессию, а какие нет, то задача ограничивается подбором соответствующей линейной или нелинейной модели, проверкой значимости всех коэффициентов, а также всей регрессии в целом и проверкой модели на мультиколлинеарность. Рассмотрим подробнее, что произойдет при включении лишней переменной в регрессию или невключении необходимой переменной, для чего введем следующие определения.
Лишняя переменная – объясняющая переменная, включенная в модель множественной регрессии, в то время, как по экономическим причинам ее присутствие в модели не нужно.
Отсутствующая переменная – необходимая по экономическим причинам объясняющая переменная, отсутствующая в модели.
Замещающая переменная – переменная, используемая в регрессии вместо трудноизмеримого, но важного регрессора.
Спецификация переменных – выбор необходимых для регрессии переменных и отбрасывание лишних переменных. Вообще говоря, простейшим методом спецификации переменных является включение всех мыслимых необходимыми объясняющих переменных с дальнейшим отбрасыванием лишних переменных тестами Стьюдента или Фишера. Однако реализовать этот подход на практике в полной общности невозможно.
8.2. Отсутствующая переменная
Предположим, что переменная у зависит от двух переменных х1 и x2, в соответствии с соотношением:
![]() (8.1)
(8.1)
однако не уверены в значимости х2, считая, что модель должна выглядеть как
![]() (8.2)
(8.2)
Оценив парную линейную регрессию, получим следующее уравнение
![]()
в котором ![]() вычисляется по формуле:
вычисляется по формуле:
![]()
По определению, ![]() является несмещенной оценкой величины b1, если
является несмещенной оценкой величины b1, если ![]() . Если опустить х2 в регрессионном соотношении, то переменная х1 будет играть двойную роль: отражать свое прямое влияние и заменять переменную х2 в описании ее влияния.
. Если опустить х2 в регрессионном соотношении, то переменная х1 будет играть двойную роль: отражать свое прямое влияние и заменять переменную х2 в описании ее влияния.
Найдем значение ![]()
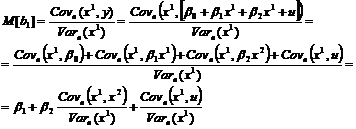
Если выполняются условия Гаусса–Маркова, третье слагаемое будет равно нулю. Следовательно, ![]() смещена на величину, равную
смещена на величину, равную ![]() . Направление смещения будет зависеть от знака величин
. Направление смещения будет зависеть от знака величин ![]() и
и 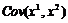 . Например, если
. Например, если ![]() положительна, а также положительна ковариация, то смещение будет положительным, а
положительна, а также положительна ковариация, то смещение будет положительным, а ![]() будет в среднем давать завышенные оценки
будет в среднем давать завышенные оценки ![]() . Есть один случай, когда оценка
. Есть один случай, когда оценка ![]() остается несмещенной, то есть когда выборочная ковариация между x1 и х2 в точности равняется нулю
остается несмещенной, то есть когда выборочная ковариация между x1 и х2 в точности равняется нулю 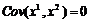 .
.
Другим серьезным следствием невключения переменной, которая на самом деле должна присутствовать в регрессии, является то, что формулы для стандартных ошибок коэффициентов становятся неприменимыми.
8.3. Лишняя переменная
Допустим, что истинная модель представляется в виде:
![]()
а рассматривается модель:
![]()
В целом проблемы смещения здесь нет, поскольку ![]() остается равной
остается равной ![]() . Но оценка будет неэффективной, поскольку у неё будет большая дисперсия. Докажем это, для чего истинную модель запишем в виде:
. Но оценка будет неэффективной, поскольку у неё будет большая дисперсия. Докажем это, для чего истинную модель запишем в виде:
![]()
Таким образом, то ![]() будет являться несмещенной оценкой величины
будет являться несмещенной оценкой величины ![]() , а
, а ![]() будет несмещенной оценкой нуля (при выполнении условий Гаусса–Маркова). Утрата эффективности в связи с включением х2 в случае, когда она не должна была быть включена, зависит от корреляции между х1 и х2.
будет несмещенной оценкой нуля (при выполнении условий Гаусса–Маркова). Утрата эффективности в связи с включением х2 в случае, когда она не должна была быть включена, зависит от корреляции между х1 и х2.
Поскольку дисперсия в случае парной регрессии
в случае двух регрессоров
Дисперсия окажется большей при множественной регрессии, и разница будет тем большей, чем ближе коэффициент корреляции по модулю к единице. Единственным исключением является вариант, когда коэффициент корреляции точно равен нулю. В этом случае дисперсии ![]() для множественной регрессии совпадает со случаем парной регрессии.
для множественной регрессии совпадает со случаем парной регрессии.
8.4. Замещающие переменные
Часто бывает, что нельзя найти данных по переменной, которую хотелось бы включить в уравнение регрессии. Некоторые переменные, относящиеся к социально-экономическому положению или к качеству образования, имеют такое расплывчатое определение, что их в принципе даже невозможно измерить. Другие могут поддаваться измерению, но на практике их приходится отбрасывать.
В этом случае используется замещающая переменная – регрессор, используемая в регрессии вместо трудноизмеримого, но важного регрессора. Замещающие переменные часто используются для замены таких экономических факторов, как научно-технический прогресс, реальный доход, уровень коррупции.
В качестве показателя общего социально-экономического положения используют его заменитель – показатель дохода. В качестве показателя качества образования можно использовать отношение числа преподавателей и сотрудников к числу студентов или расходы на одного студента.
Предположим, что истинной моделью является
![]() (8.3)
(8.3)
и допустим, что мы не имеем данных по переменной х1, но другая переменная z может выступать заменителем, поскольку имеется строгая линейная связь
![]() (8.4)
(8.4)
где l и m являются постоянными, но неизвестными величинами.
Если бы l и m были известными, то мы могли бы вычислить х1 по величине z и тогда не было бы необходимости использовать z в качестве замещающей переменной для нее. Заметьте также, что мы не можем оценить величины l и m посредством регрессионного анализа, поскольку нет данных по величине х1.
Используя замещающую переменную, регрессионная модель будет иметь вид
![]() (8.5)
(8.5)
Если построим регрессию
![]() (8.6)
(8.6)
то оценки величин ![]() , их стандартные ошибки и коэффициент R2 будут такими же, какими они были бы при наличии возможности построения регрессии с использованием x1. Однако величина
, их стандартные ошибки и коэффициент R2 будут такими же, какими они были бы при наличии возможности построения регрессии с использованием x1. Однако величина ![]() является оценкой значения
является оценкой значения ![]() , а не
, а не ![]() . Коэффициент с будет оценкой величины
. Коэффициент с будет оценкой величины ![]() . Для того, чтобы получить оценку
. Для того, чтобы получить оценку ![]() , нужно разделить величину с на m. Зачастую можем не иметь представления о величине m, но иногда можно сделать о ней субъективное предположение, что позволит в некоторой степени оценить значение
, нужно разделить величину с на m. Зачастую можем не иметь представления о величине m, но иногда можно сделать о ней субъективное предположение, что позволит в некоторой степени оценить значение ![]() .
.
§ 9. Фиктивные переменные
9.1. Фиктивные переменные в регрессии
Часто случается так, что отдельные факторы, которые хотелось бы ввести в регрессионную модель, являются качественными по своей природе и, следовательно, не измеряются в числовой шкале. Например, исследуется зависимость между продолжительностью полученного образования и доходом, и в выборке представлены лица как мужского, так и женского пола. Нужно выяснить, обусловливает ли пол различие в результатах.
Возможных решений было бы оценивание отдельных регрессий для каждого случая с последующим выяснением, различаются ли полученные коэффициенты. Другой возможный подход к решению состоит в оценивании единой регрессии с использованием всей совокупности наблюдений измерением степени влияния качественного фактора посредством введения так называемой фиктивной переменной – переменной, принимающей в каждом наблюдении только два значения: да или нет.
Математически влияние данного дискретного фактора на значение переменной y может заключаться в введении в уравнение фиктивной переменной D, принимая ее значения равными нулю для одного случая и единице – для другого.
Тогда общая модель регрессии может иметь вид:
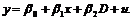 (9.1)
(9.1)
Для случая D=0 уравнение принимает вид:
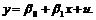 (9.1a)
(9.1a)
Для второго случая при D=1 уравнение принимает вид:
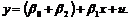 (9.1b)
(9.1b)
Следует отметить, дисперсия фиктивной переменной очень мала и это сказывается на достоверности оценок. В модели с фиктивными переменными коэффициент R2 часто бывает очень малым, а значения t-статистики незначимо отличаются от 0 для фиктивных переменных. Это не является поводом для выбрасывания фиктивных переменных из модели, ибо чаще всего они описывают небольшие, но важные поправки к главной (нефиктивной) объясняющей переменной.
9.2. Эталонная категория и фиктивные переменные
Введем следующие понятия:
Категория – событие, про которое для каждого наблюдения можно определенно сказать, произошло оно в этом наблюдении или нет.
Набор категорий – конечный набор взаимоисключающих событий, полностью исчерпывающий все возможности.
Совокупность фиктивных переменных – некоторое количество фиктивных переменных, предназначенное для описания набора категорий.
Эталонная категория – категория, с которой сравниваются другие категории. Чаще всего в эталонной категории все фиктивные переменные из совокупности равны 0.
Рассмотрим пример использования категорий. При исследовании производительности, в зависимости от вложенных средств, могут попытаться ввести в модель в неявном виде собственника производства. Будем предполагать, что в нашем исследовании рассматривались следующие виды предприятий: государственные, муниципальные, частные, предприятия со смешанным капиталом. Поскольку в каждом наблюдении можно однозначно сказать о каком виде предприятия идет речь, то данный список собственников определяет набор категорий.
Любой набор категорий, и этот в том числе, можно описать некоторой совокупностью фиктивных переменных. При этом по набору значений фиктивных переменных категория определяется однозначно. Выбираем одну из этих категорий как эталонную и определяем фиктивные переменные для остальных. Как правило, естественно для эталонной категории использовать 0, для которой все фиктивные переменные будут равны 0 и определяем фиктивные переменные D1, D2 и D3 для других категорий следующим образом:
Государственные. Категория 0 (эталонная) D1 =0; D2 =0; D3 = 0;
Муниципальные. Категория 1 D1 = 1; D2 =0; D3 = 0;
Частные. Категория 2 D1 = 0; D2 =1; D3 = 0;
Смешанный капитал. Категория 3 D1 = 0; D2 =0; D3 = 1.
Запишем нашу модель в следующем виде:
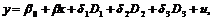 (9.2)
(9.2)
где![]() – коэффициенты при фиктивных переменных. Причем
– коэффициенты при фиктивных переменных. Причем ![]() – разность между значениями зависимой переменной y, при переходе от категории 0 к категории 1, при сохранении значения регрессора x на прежнем уровне. Коэффициенты
– разность между значениями зависимой переменной y, при переходе от категории 0 к категории 1, при сохранении значения регрессора x на прежнем уровне. Коэффициенты ![]() и
и ![]() имеют аналогичный смысл разности при переходе к другой категории. Рассмотрим некоторые данные по предприятиям, значения которых заданы в таблице 2.
имеют аналогичный смысл разности при переходе к другой категории. Рассмотрим некоторые данные по предприятиям, значения которых заданы в таблице 2.
Таблица 2
Наблюдение | Категория | x | y | D1 | D2 | D3 | Наблюдение | Категория | x | y | D1 | D2 | D3 |
1 | 1 | 195,85 | 7,955 | 1 | 0 | 0 | 11 | 0 | 135,56 | 8,128 | 0 | 0 | 0 |
2 | 2 | 138,20 | 7,824 | 0 | 1 | 0 | 12 | 0 | 101,71 | 7,124 | 0 | 0 | 0 |
3 | 0 | 110,07 | 7,169 | 0 | 0 | 0 | 13 | 3 | 128,50 | 8,967 | 0 | 0 | 1 |
4 | 1 | 159,65 | 8,275 | 1 | 0 | 0 | 14 | 0 | 134,31 | 7,804 | 0 | 0 | 0 |
5 | 3 | 189,91 | 7,312 | 0 | 0 | 1 | 15 | 0 | 155,36 | 7,904 | 0 | 0 | 0 |
6 | 2 | 188,46 | 8,796 | 0 | 1 | 0 | 16 | 1 | 135,74 | 7,646 | 1 | 0 | 0 |
7 | 0 | 195,85 | 8,582 | 0 | 0 | 0 | 17 | 0 | 137,18 | 7,680 | 0 | 0 | 0 |
8 | 1 | 101,45 | 7,442 | 1 | 0 | 0 | 18 | 0 | 135,56 | 8,629 | 0 | 0 | 0 |
9 | 0 | 140,74 | 8,409 | 0 | 0 | 0 | 19 | 0 | 191,03 | 7,139 | 0 | 0 | 0 |
10 | 1 | 186,32 | 7,264 | 1 | 0 | 0 | 20 | 1 | 146,60 | 7,014 | 1 | 0 | 0 |
Отметим, что дополнительно не вводится четвертая фиктивная переменная, иначе выполнялось бы тождество D1 + D2 + D3 + D4 = 1, что означало линейную зависимость объясняющих переменных и, как следствие, полную коллинеарности. Такая ситуация называется ловушкой dummy trap.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
